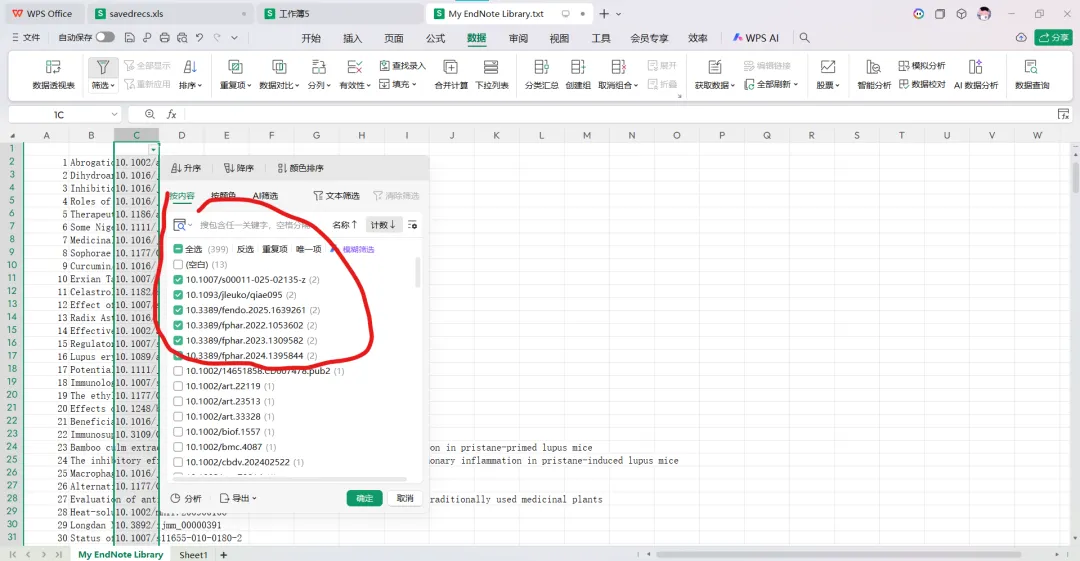
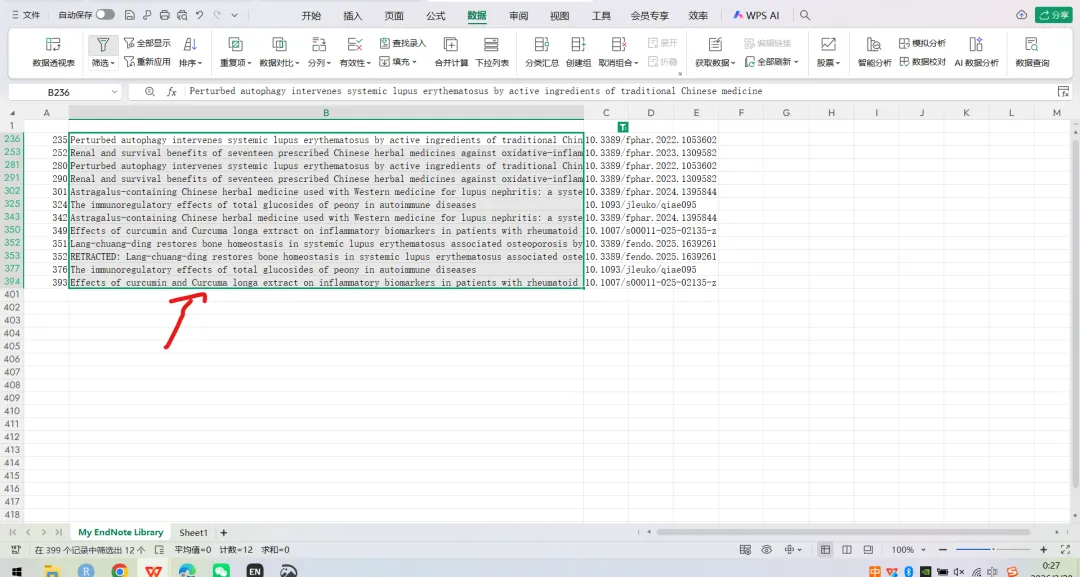
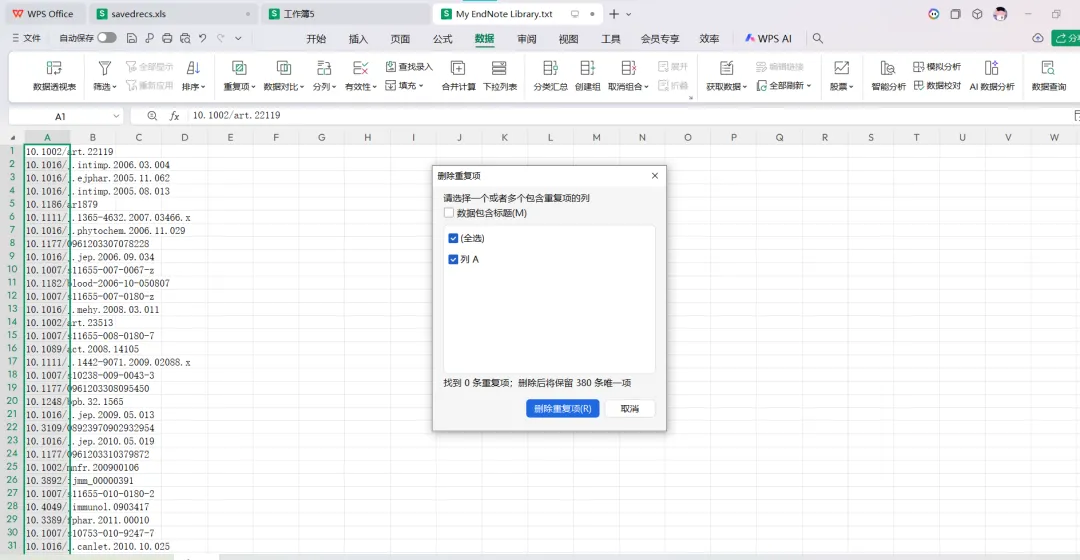
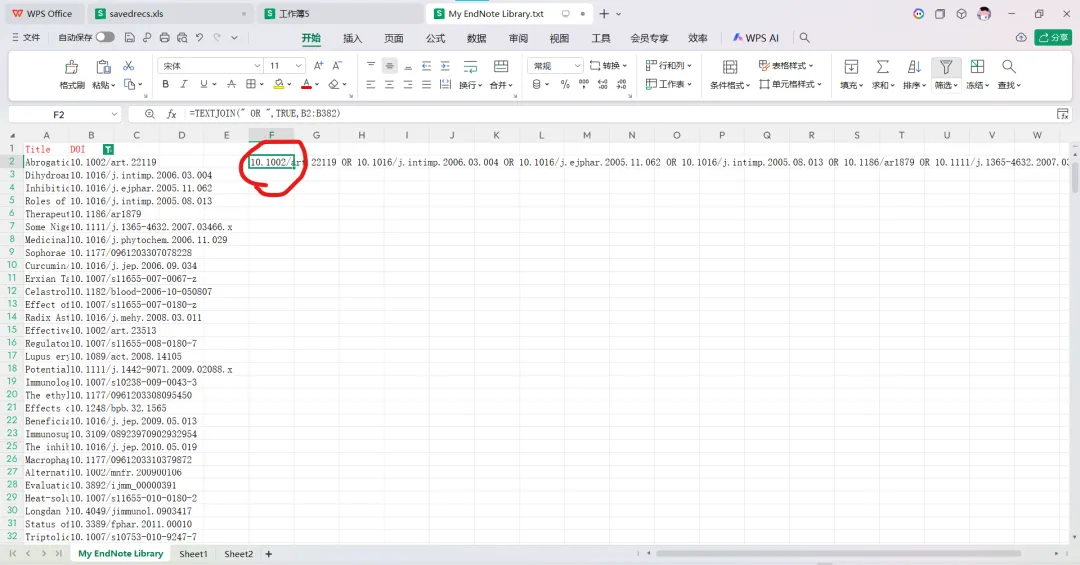
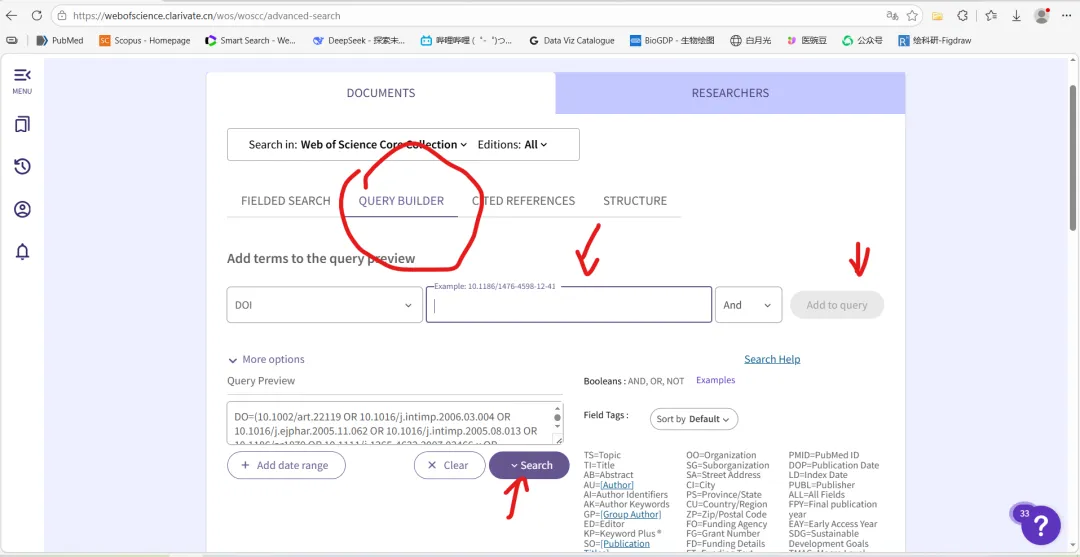
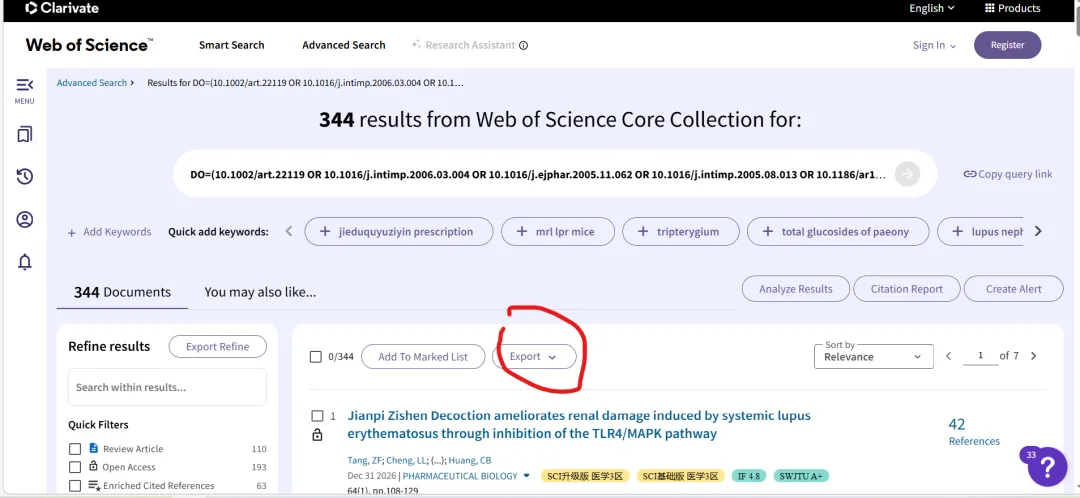
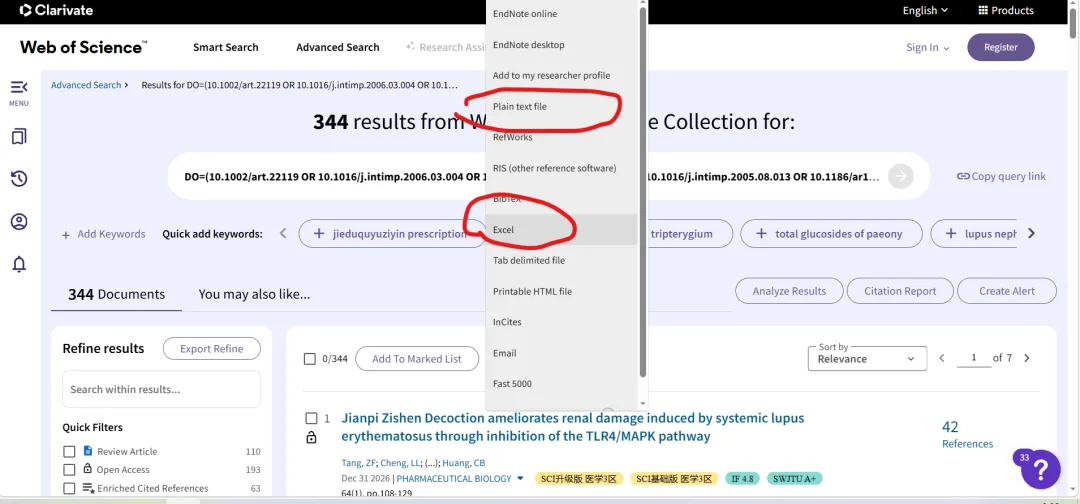
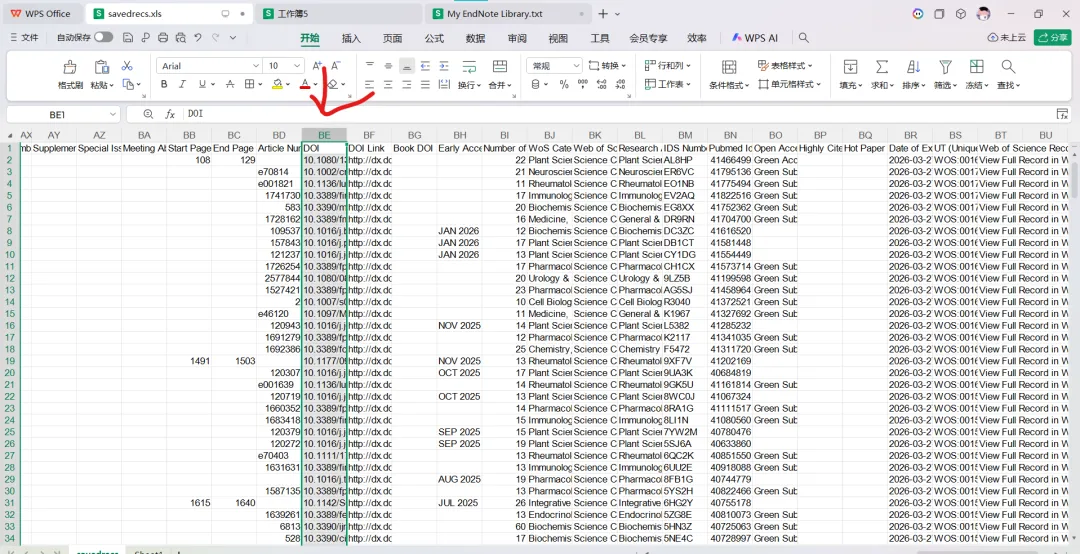
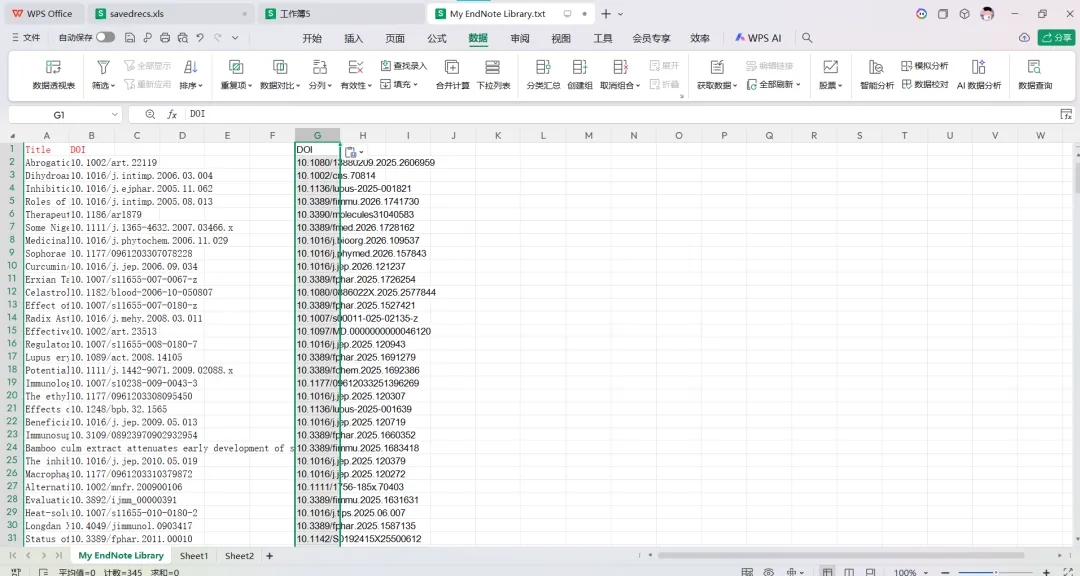
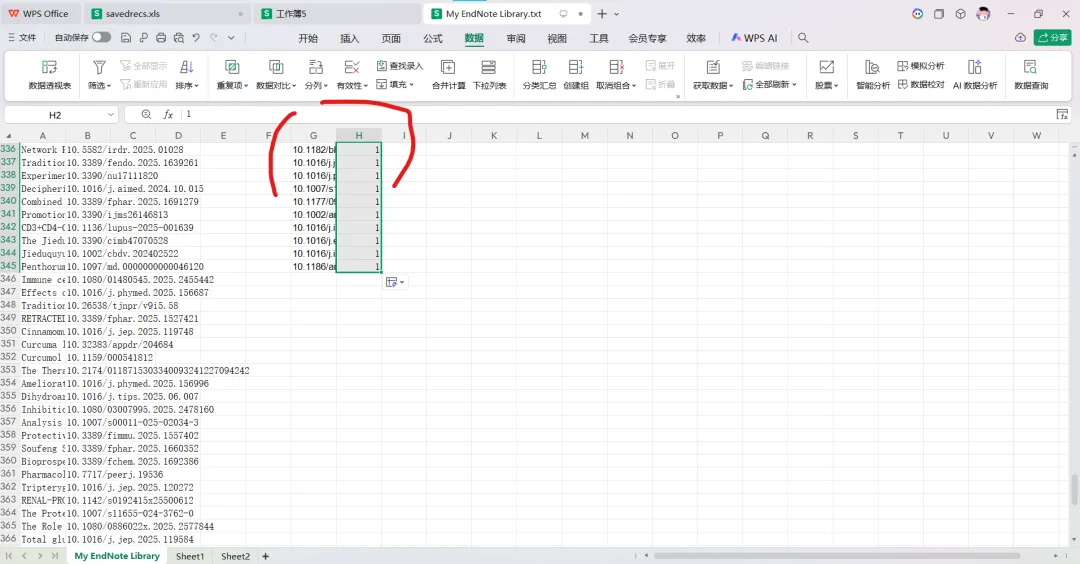
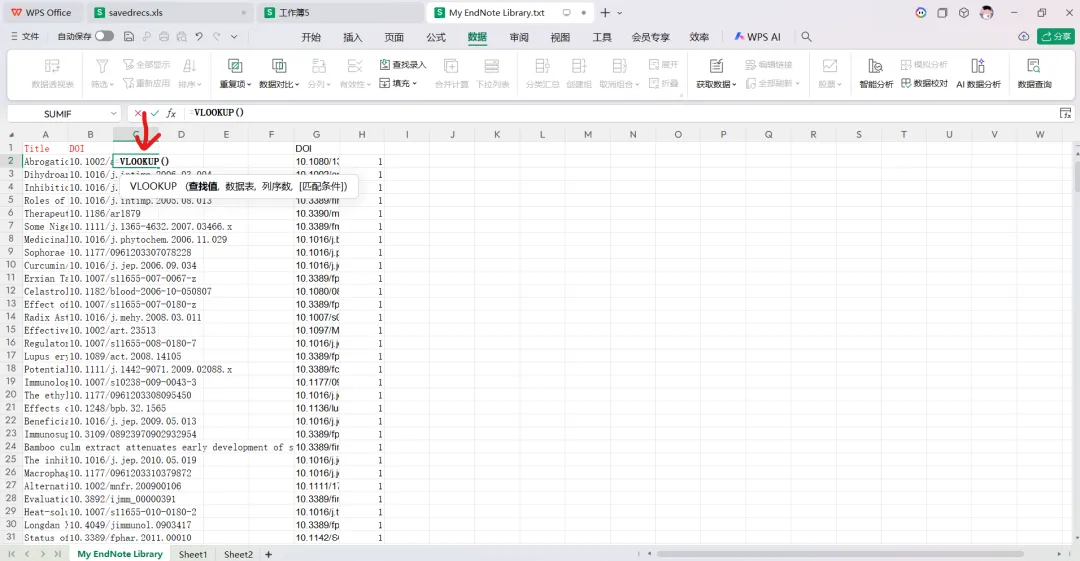
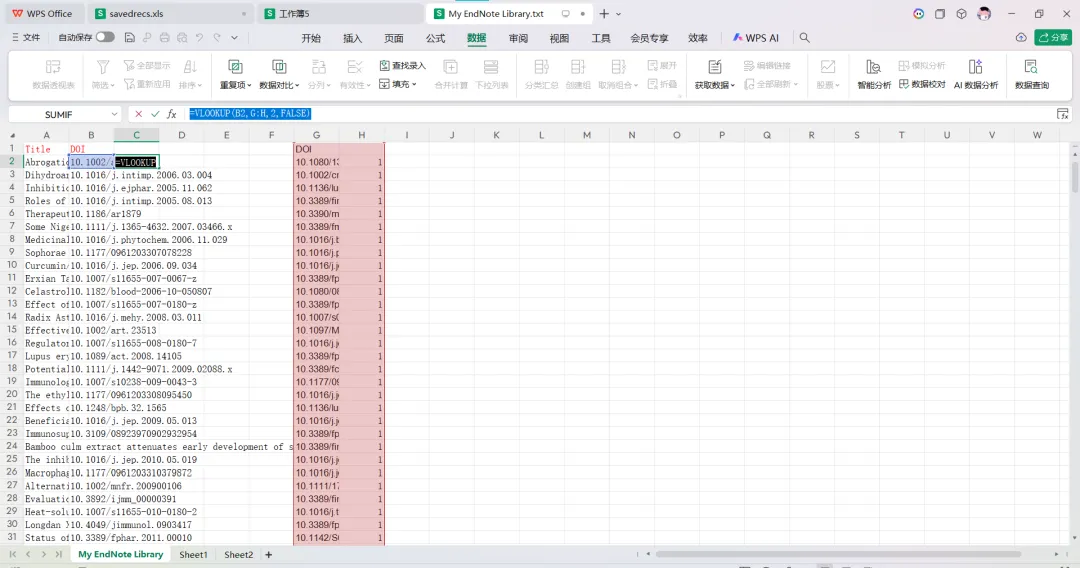
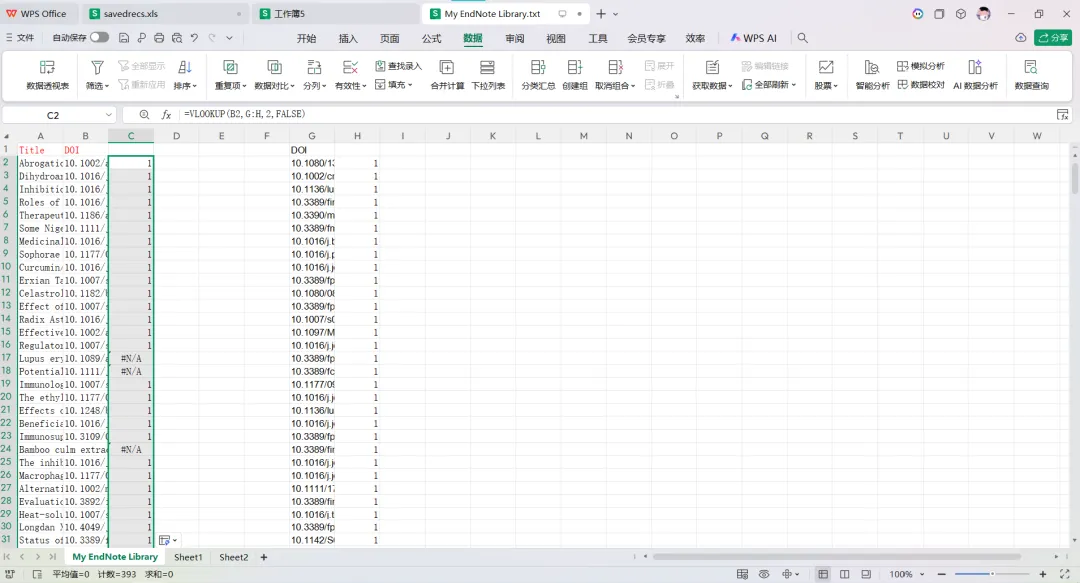
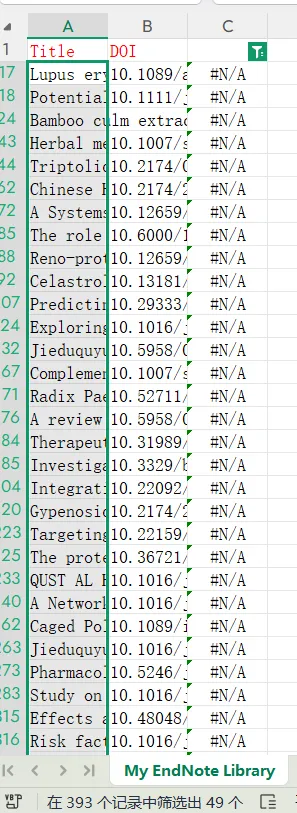
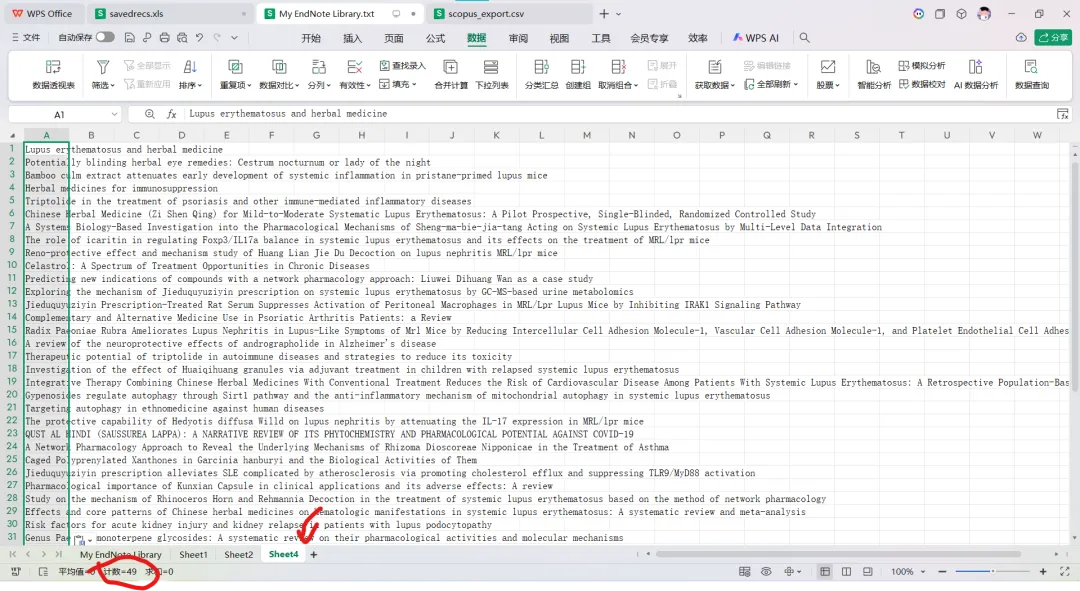
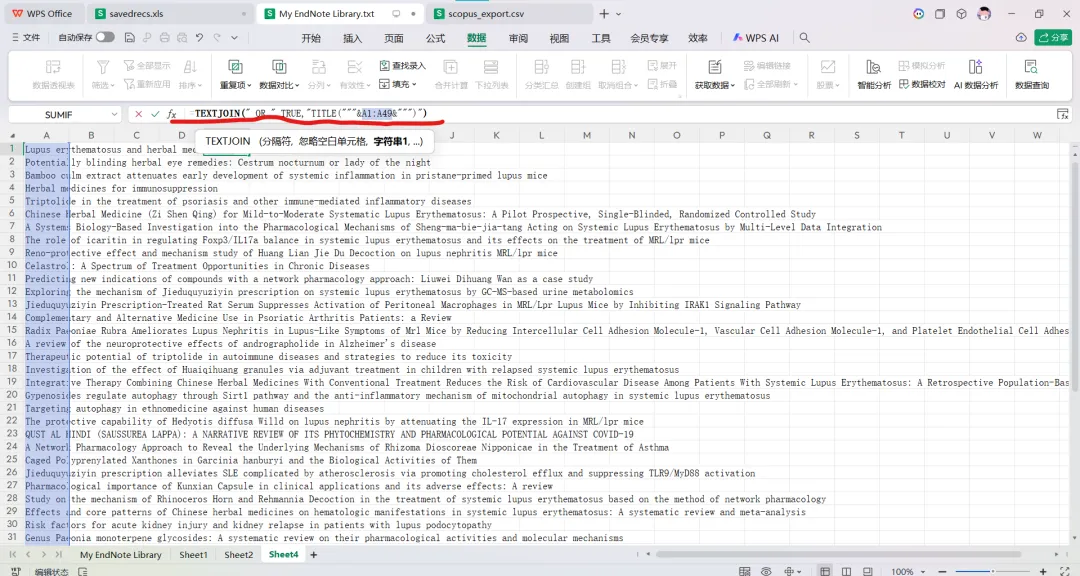
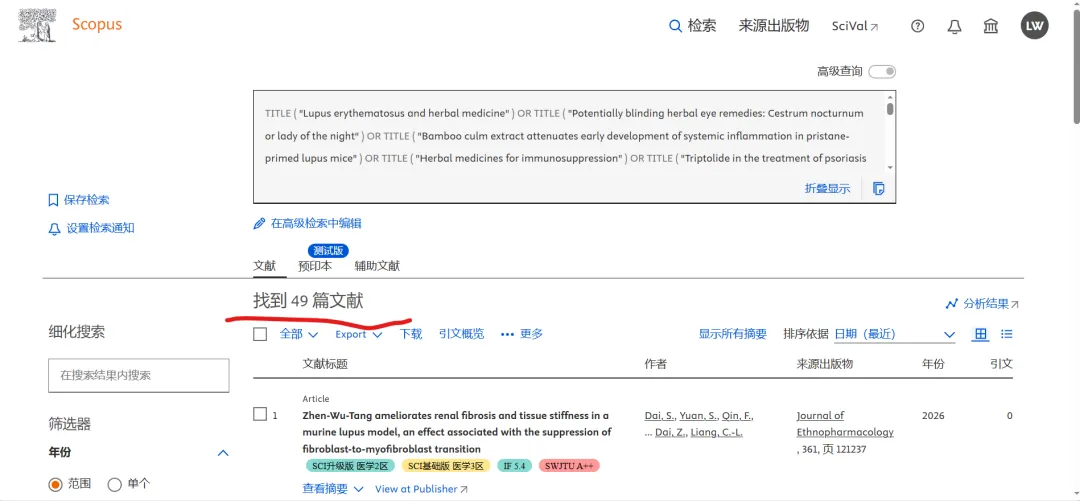
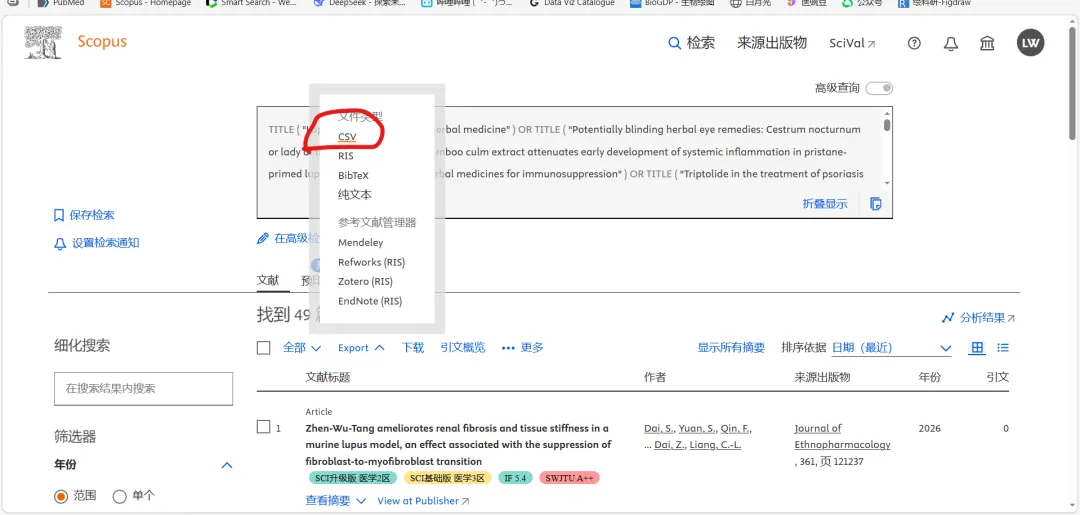
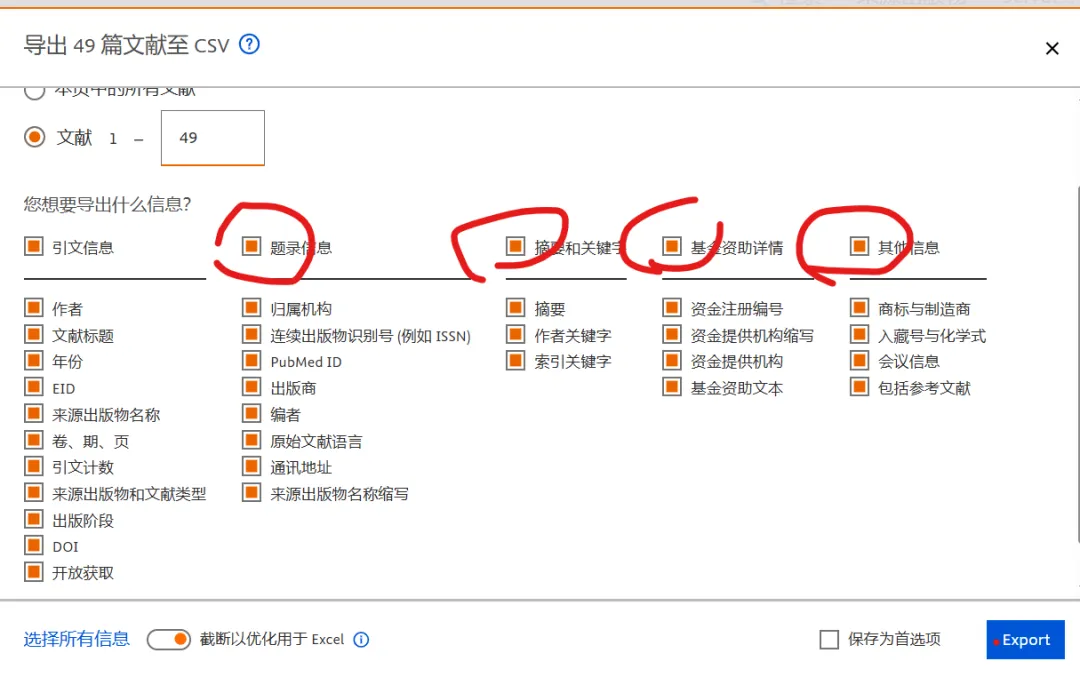
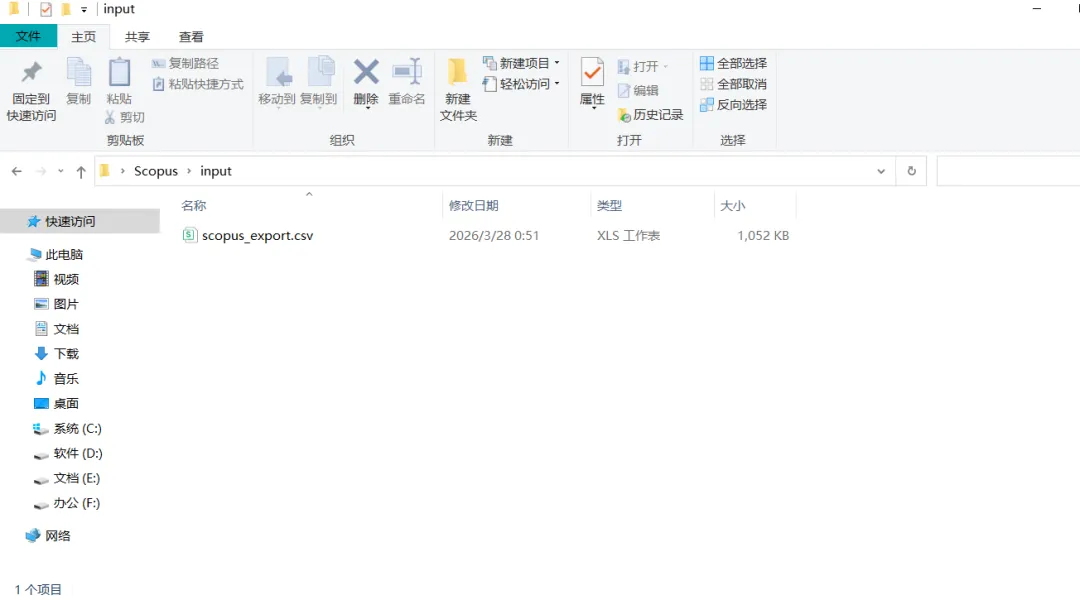
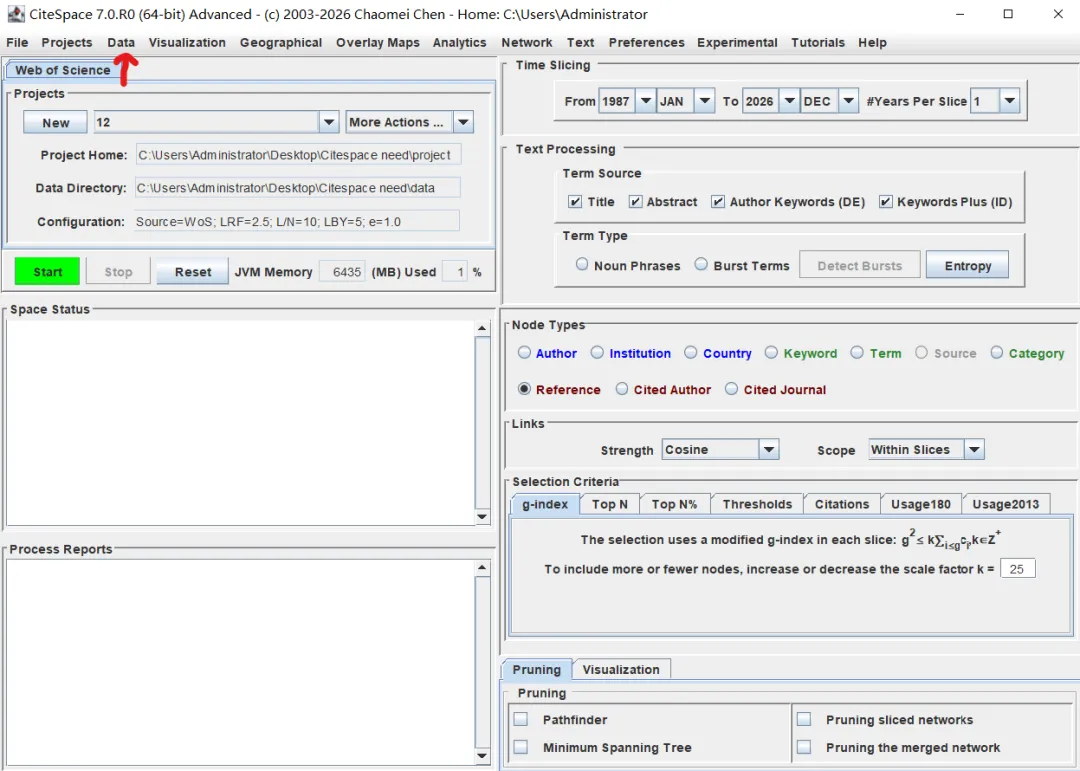
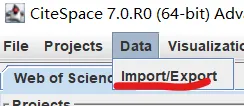
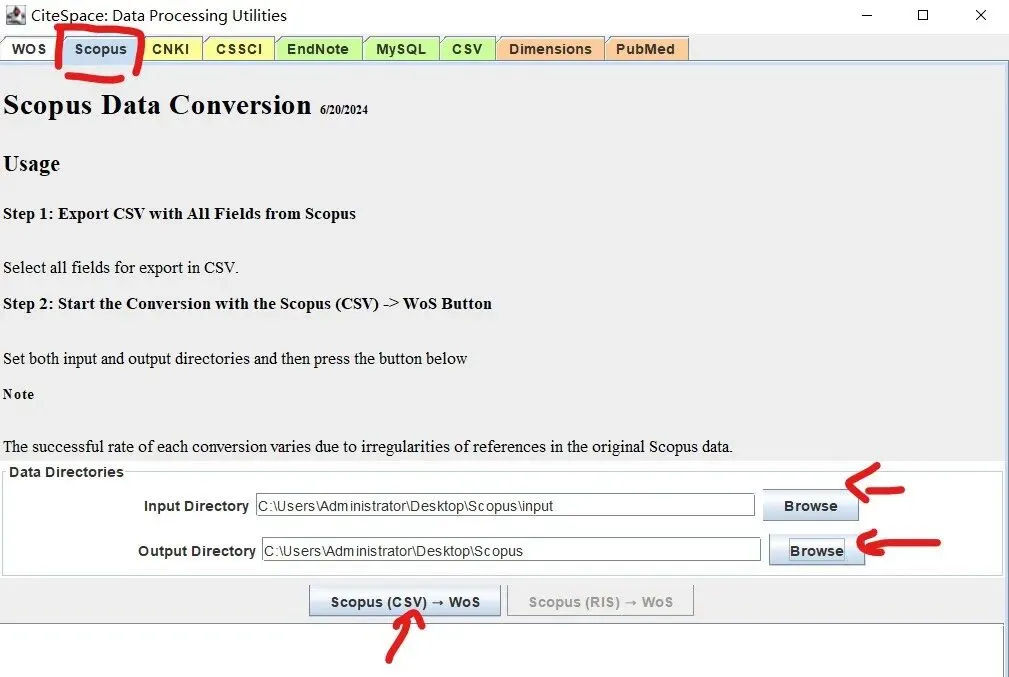
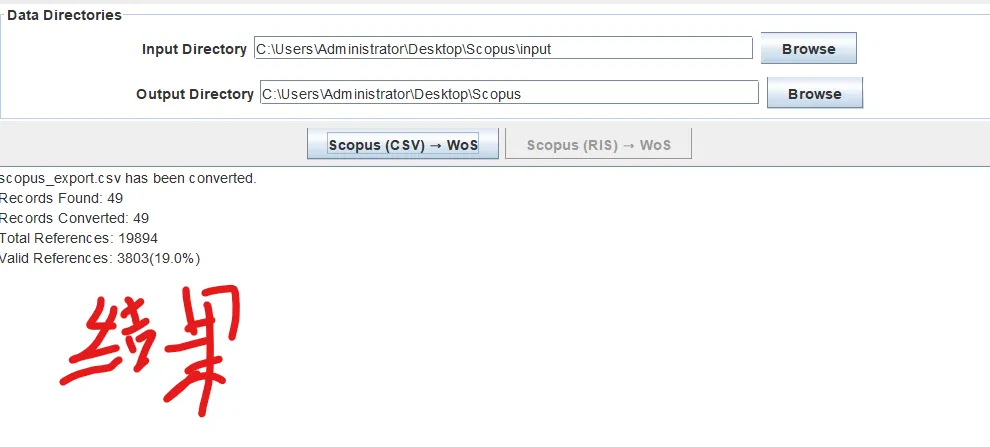
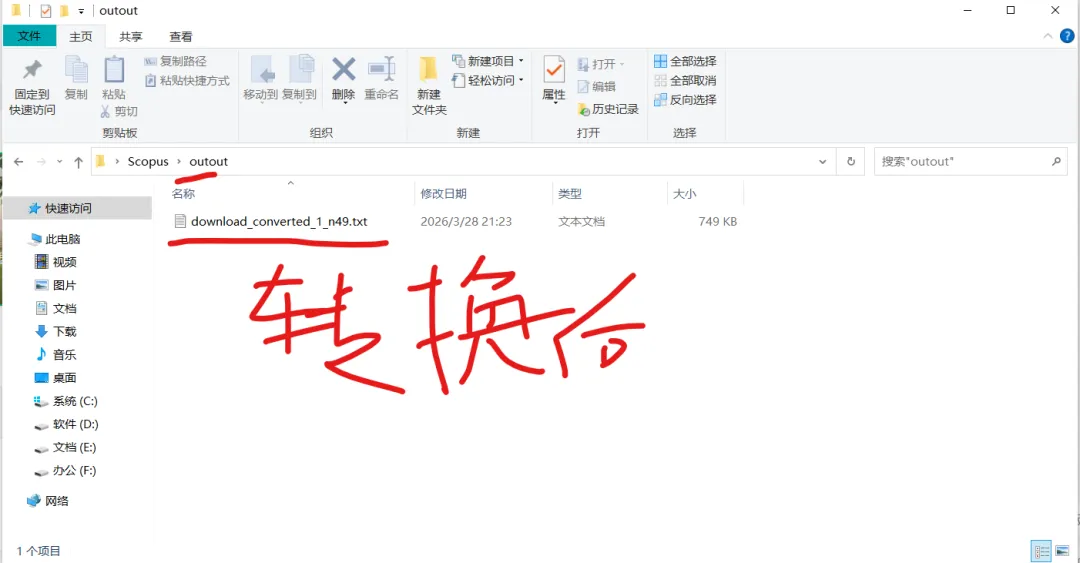
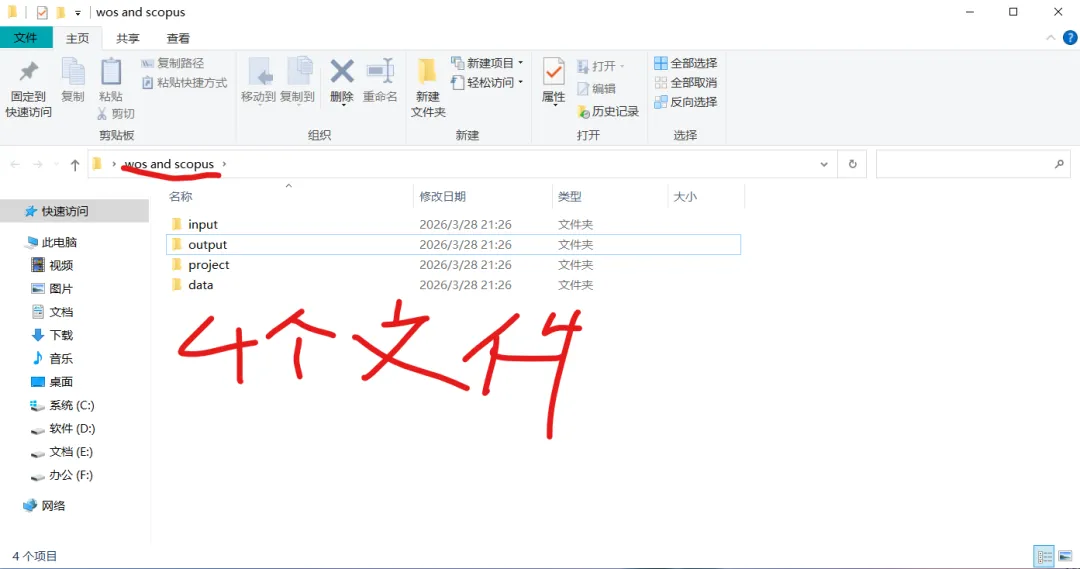
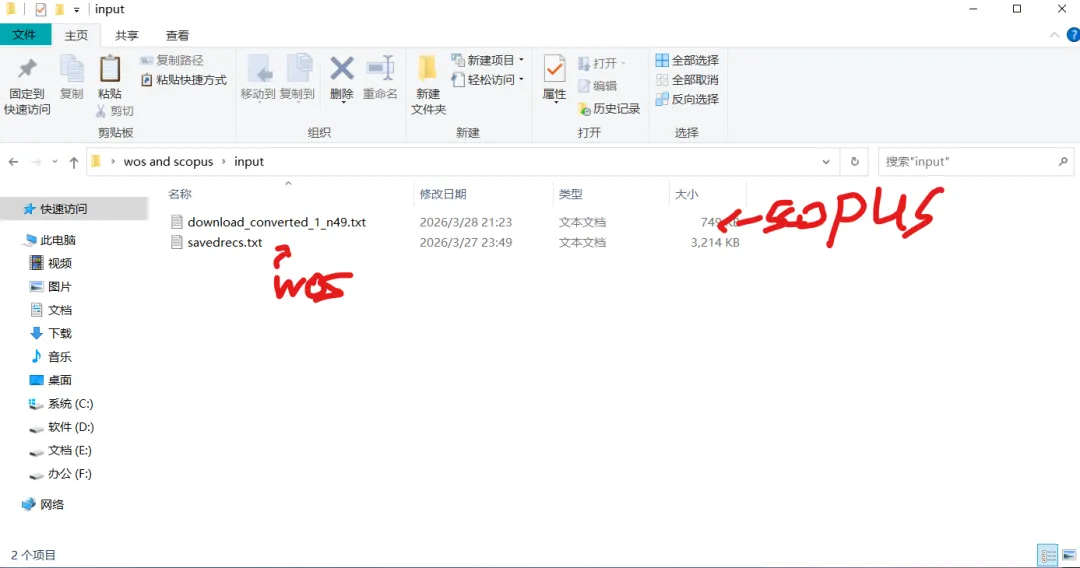
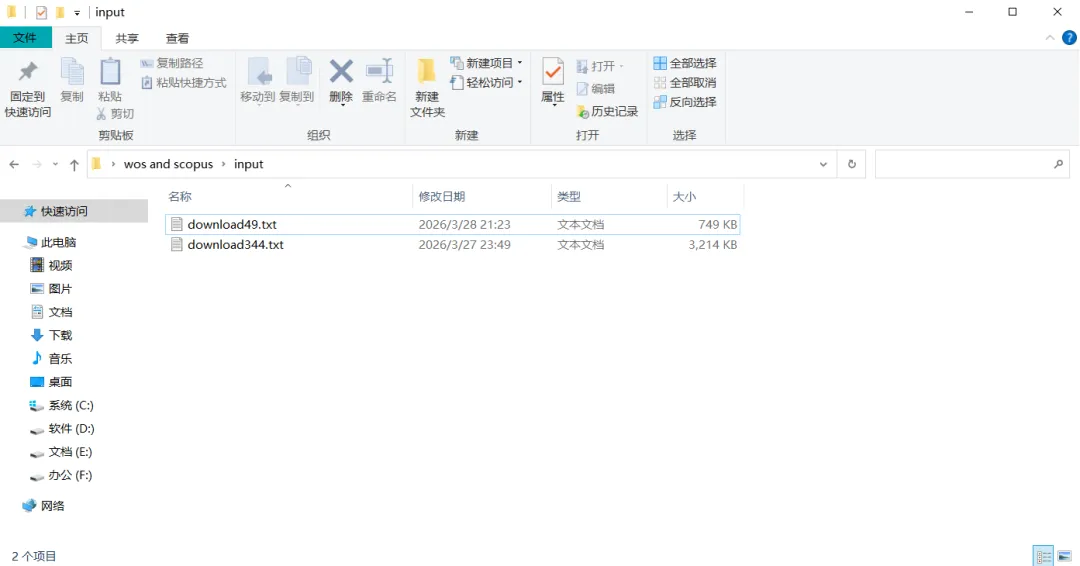
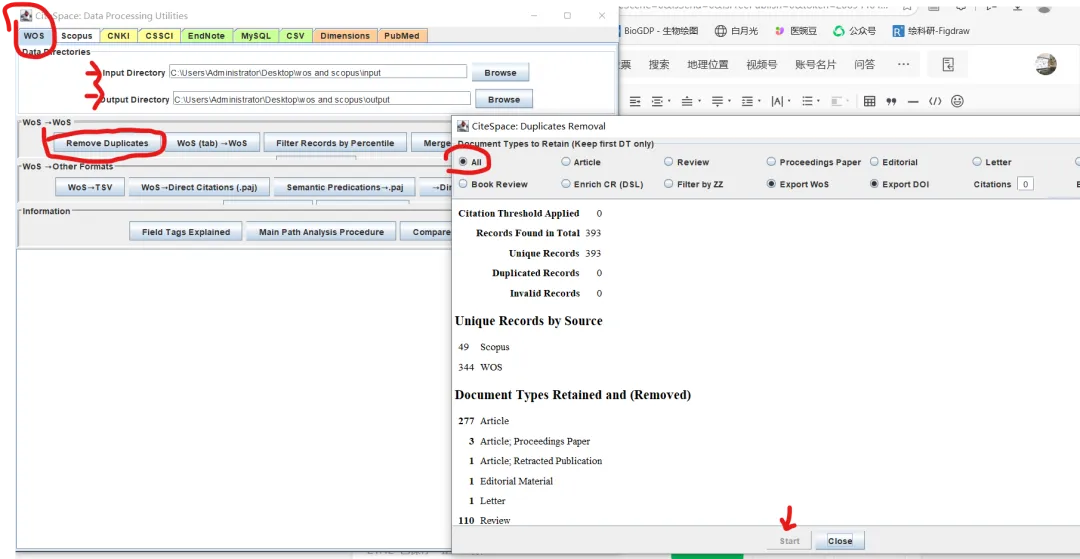
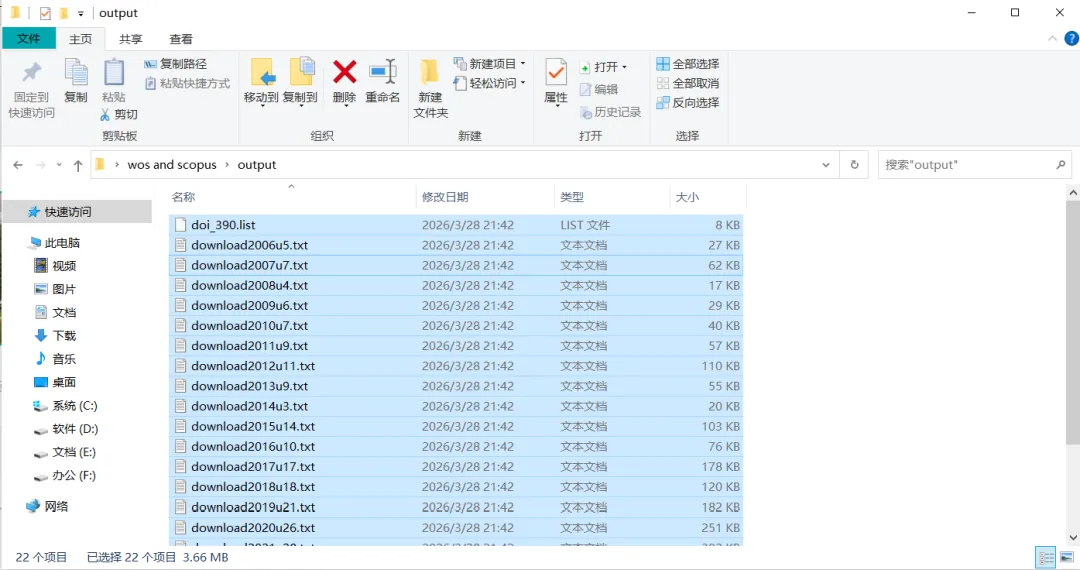
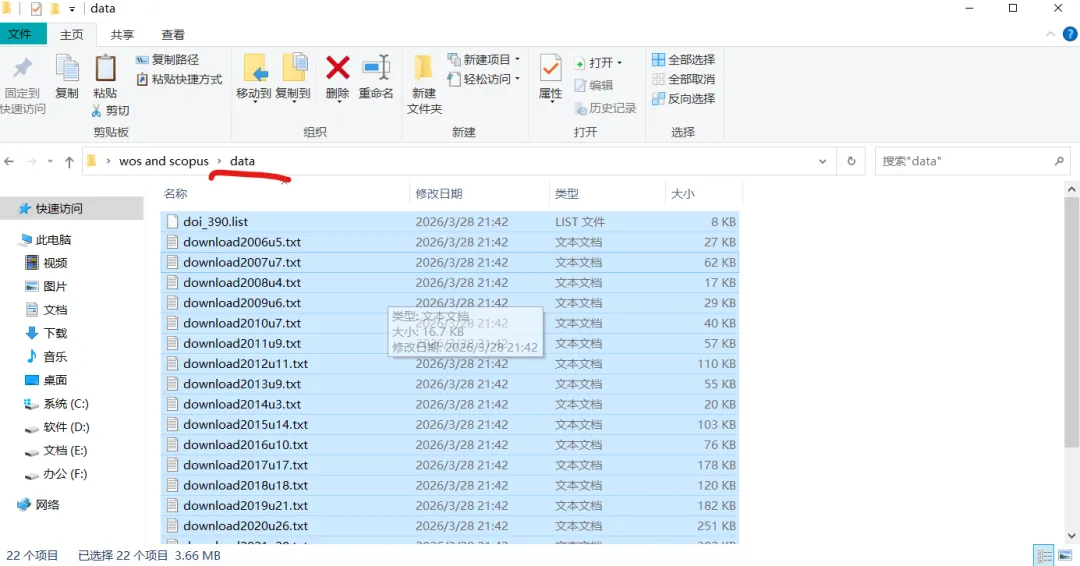
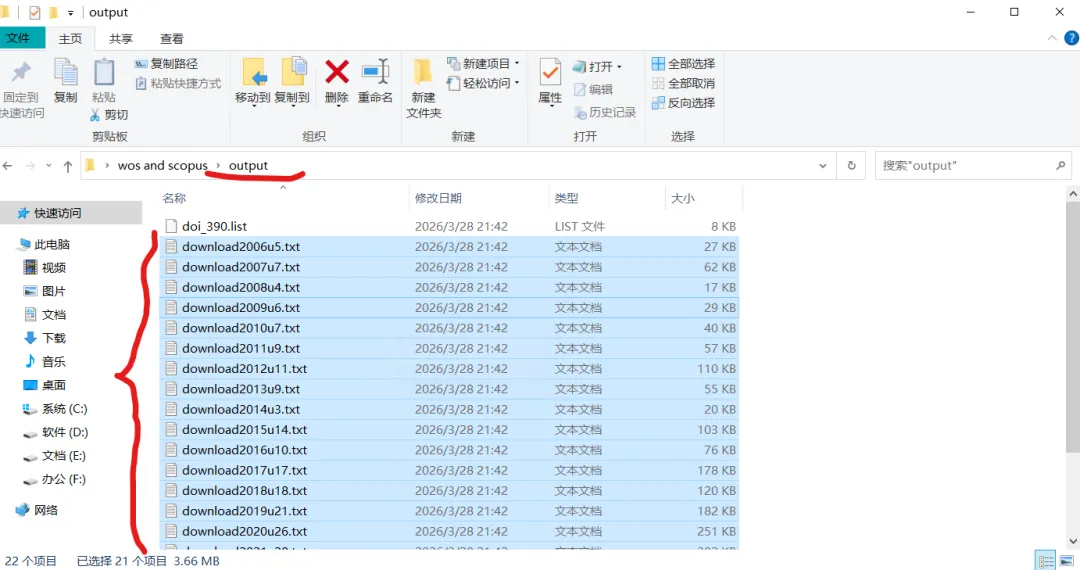
先将DOI与标题从EndNote导出[导出步骤参考文献记量学用DOI批量检索文献],用筛选功能找出有重复的DOI,然后根据其标题去EndNote中将筛选时漏掉的重复文章删除然后再从EndNote导出DOI与标题,可以将新导出的DOI复制到另一个文件夹则看见无重复了然后用公式“=TEXTJOIN(” OR “,TRUE,B2:B你的最后一个位置)”,将结果复制到WOS,然后检索(这里即使有的标题无DOI号也没关系的,没有DOI的公式是不会算进来的)可以看见检索到344篇,我们本来有393篇,所以少了49篇导出两个文件:①一个是纯文本包含所有信息的txt(用于后面citespace导入)②另一个是Excel文件(用来查找缺失的DOI号)打开下载的Excel文件,选中DOI列复制粘贴到我们刚刚EndNote导出的那个表格里(示例中的G列 )然后在H列填满1在Endnote导出的DOI列旁边那一列输入公式=VLOOKUP(B2,G:H,2,FALSE),查看结果,#N/A则代表是缺失的DOI号,我们筛选出#N/A对应的标题可以看见经筛选后查找到49篇与前面我们说的缺失49对应上了,再将这些缺失的文章的标题复制到新的文件中在任意一个空格输入公式=TEXTJOIN(” OR “,TRUE,”TITLE(“””&A你的第一个:A你的最后一个&”””)”),并将结果复制到Scopus检索可以看见Scopus检索到49篇没有缺失了,如果你检索到还是有缺失,则在导出的CSV中复制标题与刚刚你检索的标题再重复一次查找缺失的标题去Pubmed检索导出就好。接下来是Citespace分析,先建立一个文件夹命名Scopus,在里面设置四个文件夹分别是input和output;data和project,将你下载的CSV放在input中。打开citespace,跟着图片步骤接着打开output文件即使转换为WOS格式的文件了我们重新建一个文件夹,命名为wos and scopus,同样在里面新建四个文件夹,①将转换后的文件复制到input文件夹里②还有把刚刚在wos下载的344篇的纯文本txt也复制到input由于citespace分析要文件命名为download开头,像我这样改文件名打开output文件夹可以看见导出的结果,ctrl+A全选所有结果复制到data文件夹后面的两个软件分析具体操作就参考文献计量学:以Web of Science为例VOSviewer和Citespace操作步骤,注意VOSviewer导入的文件是我们在Citespace导出的.txt文件如图,我们可以将这些导入到一个新的文件夹里用于VOSviewer分析此外,如果想要用R包分析则要将这些txt文件压缩为一个压缩包。R包的调用程序:
 夜雨聆风
夜雨聆风