 夜雨聆风
夜雨聆风





苏大&百度提出VISOR:让AI视觉长文档问答不再“迷路”

LightZebra,AI前沿速递
论文信息Paper Information
标题:VISOR: Agentic Visual Retrieval-Augmented Generation via Iterative Search and Over-horizon Reasoning
作者:Yucheng Shen, Jiulong Wu, Jizhou Huang, Dawei Yin, Lingyong Yan, Min Cao
作者单位:苏州大学;百度公司
论文发表时间:2026年04月10日 17:25
URL:https://arxiv.org/pdf/2604.09508v1
中文摘要:视觉检索增强生成(VRAG)使视觉语言模型能够检索和推理视觉丰富的文档。为了处理需要多步推理的复杂查询,智能体化的VRAG系统将推理与迭代检索交错进行。然而,现有的智能体化VRAG面临两个关键瓶颈:(1) 视觉证据稀疏性:关键证据分散在不同页面却孤立处理,阻碍跨页面推理;此外,图像内部的细粒度证据通常需要精确的视觉操作,其误用会降低检索质量。(2) 长程搜索漂移:跨检索页面的视觉token累积会稀释上下文并导致认知过载,使智能体偏离其搜索目标。为应对这些挑战,我们提出了VISOR(通过迭代搜索与超视界推理的视觉检索增强生成),一个统一的单智能体框架。VISOR具有一个用于渐进式跨页面推理的结构化证据空间,以及一个管理视觉操作的视觉动作评估与校正机制。此外,我们引入了带有滑动窗口和意图注入的动态轨迹来缓解搜索漂移。它们锚定证据空间,同时丢弃早期的原始交互,防止上下文被视觉token淹没。我们使用基于组相对策略优化的强化学习(GRPO-based RL)流程,配合为动态上下文重构量身定制的状态掩码和信用分配来训练VISOR。在ViDoSeek、SlideVQA和MMLongBench上的大量实验表明,VISOR在长程视觉推理任务上实现了最先进的性能,并具有卓越的效率。
研究背景Research Background
随着大语言模型和视觉语言模型的快速发展,它们在多种任务上展现出强大能力,但仍受限于固定的训练数据,容易出现幻觉和知识缺口。检索增强生成(RAG)通过将模型输出建立在外部检索证据之上,缓解了这些问题。然而,现实世界文档常包含丰富的视觉内容(如图表、表格),传统文本提取无法完整保留这些信息。为此,视觉检索增强生成(VRAG)将RAG扩展到视觉领域,使模型能够直接检索和推理文档页面图像。对于需要多步推理的复杂问题,智能体化的VRAG系统应运而生,它们通过交替进行推理和迭代检索来动态收集证据。
这篇论文旨在解决智能体化VRAG在应对复杂视觉文档问答时面临的两个核心瓶颈:视觉证据稀疏性和长程搜索漂移。具体来说,前者指关键证据零散分布在多个页面或图像内的微小区域,且现有系统缺乏有效的跨页面证据整合与细粒度视觉动作评估机制;后者指在多轮交互中,不断累积的视觉token会淹没上下文,导致智能体忘记早期发现并偏离原始查询目标。
这两个问题严重制约了智能体化VRAG处理真实世界复杂视觉文档(如研究报告、幻灯片)的能力。视觉证据的碎片化使得模型难以进行连贯的多步推理,而长程交互中的信息过载和注意力漂移则直接导致检索失败或答案错误。解决这些问题对于构建能够像人类一样,通过反复查阅、比对、聚焦细节来理解和回答复杂视觉问题的AI助手至关重要,是迈向更可靠、更智能的多模态文档理解的关键一步。
现有的研究在实现这一目标上存在以下不足:
1. 证据处理孤立:现有系统通常独立处理每个检索到的页面,缺乏跨页面证据积累和联合推理的机制,导致碎片化的观察无法支撑连贯推理。
2. 视觉动作缺乏引导:对于需要精细查看的图像区域(如表格单元格),模型可以执行“裁剪放大”等动作,但缺乏有效的评估机制来指导这些动作,容易导致裁剪无关区域或进行冗余操作,浪费交互轮次并引入噪声。
3. 上下文管理低效:在多轮交互中,所有检索到的原始页面图像(包含大量视觉token)都被简单追加到上下文,导致上下文窗口迅速饱和,早期关键证据被“淹没”,并引发模型注意力的“搜索漂移”,偏离原始查询意图。
4. 架构复杂度与效率权衡:一些工作尝试通过分解任务到多个专门智能体(如规划、检索、回答)来应对挑战,但这牺牲了端到端优化的可能性,且可能引入效率开销,无法根据问题复杂度灵活调整。
核心思路Method
VISOR的核心思路在于设计一个统一的单智能体框架,通过结构化证据管理、视觉动作引导和动态上下文重建,系统性解决视觉证据稀疏性和长程搜索漂移两大瓶颈。下面我们详细拆解其工作原理。
整体流程与动机
面对复杂视觉文档问答,现有智能体常常在两个环节受挫:一是证据分散(见 图1 顶部),答案线索可能零散分布在多个页面,或仅存在于单页的某个小区域(如表格的特定单元格);二是注意力漂移(见 图1 底部),随着交互轮次增加,不断累积的原始视觉token(每个页面图像可能包含上千个token)会淹没上下文,导致智能体忘记早期发现,甚至偏离原始问题。VISOR的整体框架和工作流程见 图2。
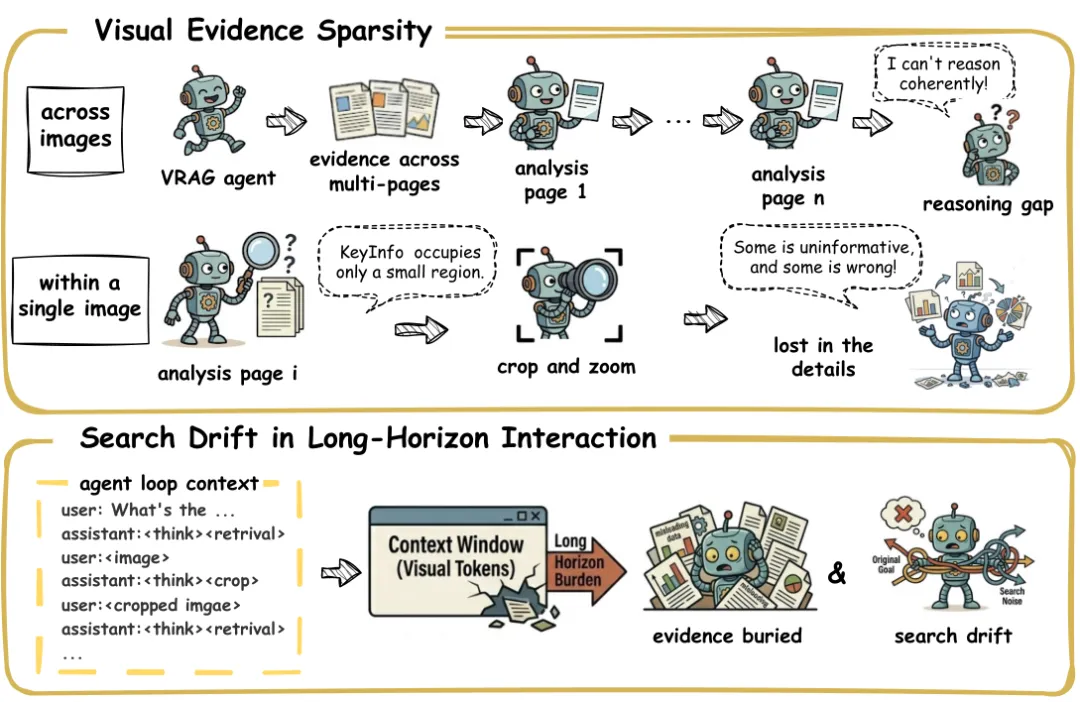
图1:智能体化VRAG中的两个关键瓶颈:(上)视觉证据稀疏性,相关线索分散在多页或局限于单幅图像的小区域内;(下)长程交互中的搜索漂移,累积的视觉token淹没上下文,掩盖早期证据,导致智能体偏离原始目标。
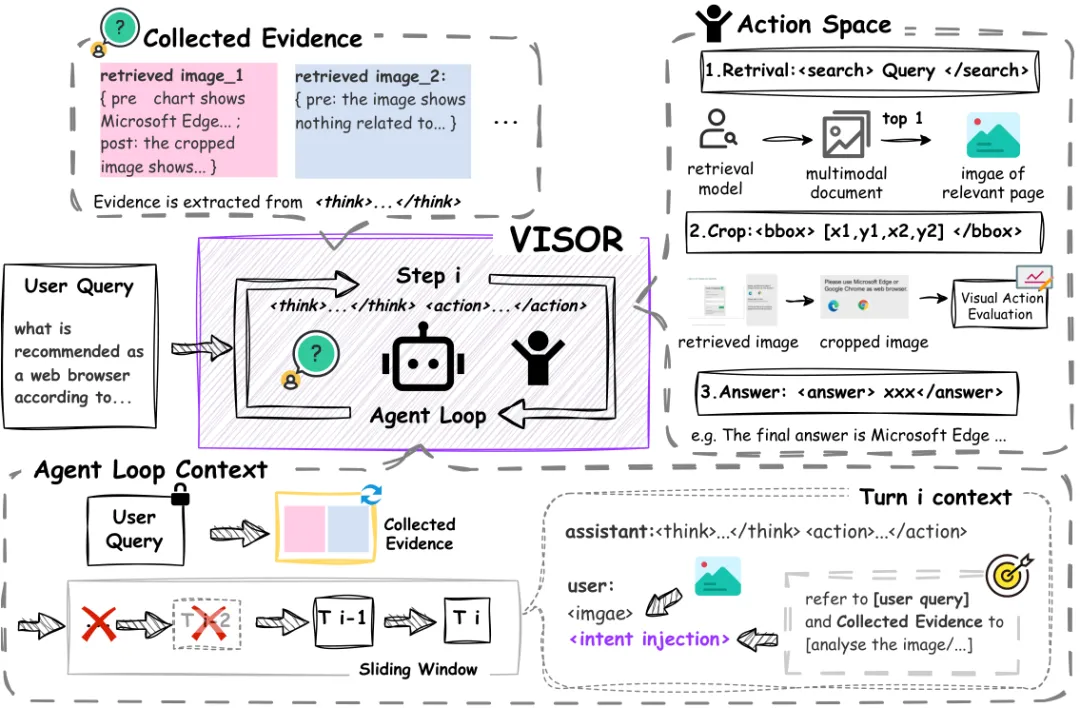
图2:VISOR概览。在每一步i,智能体生成思考动作响应。从推理轨迹中提取的证据累积在结构化证据收集空间E中。动作空间包含三种操作:搜索、裁剪和回答。智能体循环上下文在每轮重建:用户查询和E始终置顶,而原始交互仅通过滑动窗口保留最近W轮;每轮观察还包含意图注入提示以重新锚定智能体注意力。
1. 结构化证据空间:实现跨页面渐进式推理
为了整合分散的证据,VISOR引入了一个持久化的、结构化的证据空间 `E`。其核心思想是:不让智能体读完一个页面就丢一个,而是要求它从每一轮的“思考 (think)”中,提取出对当前页面(在全图尺度)和可能经过裁剪放大的局部区域的关键观察,并将这些文本摘要以结构化的形式记录下来。具体地,证据空间 `E` 是一个映射集合,记录了每个被访问过的页面图像 `Ik` 及其对应的两个文本摘要:初次观察全页的摘要 `ek^pre` 和局部裁剪后的摘要 `ek^post` 。公式上可以表示为:`E = Ik 映射到 (ek^pre, ek^post) | k 属于所有被检索的页面 `。
在每一轮交互中,智能体都能看到这个不断更新的证据空间 `E`,从而可以基于之前所有页面的“精华”内容进行下一次搜索或最终推理,实现了真正的跨页面、渐进式证据积累。这使得VISOR能够处理例如“先找到年份数据,再根据该年份查找销售额”这类多跳问题。
2. 视觉动作评估与校正:精准使用裁剪工具
针对细粒度证据提取需求,VISOR的智能体有三个核心动作:`search` (检索新页面)、`crop` (在当前页裁剪放大部分区域)、`answer` (生成最终答案)。为了防止模型滥用或误用 `crop` 操作(如裁剪无关区域或在清晰区域仍进行裁剪),VISOR引入了视觉动作评估与校正机制。
评估:在智能体收到一个新检索的页面图像后,系统会提示它评估该页面全局内容是否足以支撑判断。如果需要查看更清晰的细节(如小字图表),才建议执行 `crop`。
校正:如果发出的 `crop` 动作返回的图像没有提供有用信息,系统会通过特定提示,将智能体的注意力重定向回执行裁剪前的推理状态,阻止无效的视觉内容污染证据空间。表2 的消融实验(w/o ES)表明,缺少此证据空间和动作管理机制会导致性能大幅下降。
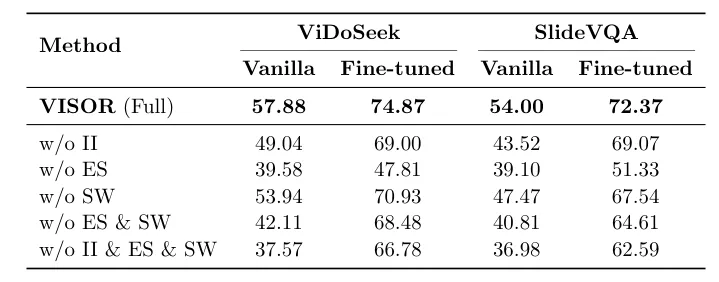
表2:在Qwen2.5-VL-7B上对VISOR在SlideVQA和ViDoSeek上的消融研究。我们报告总体准确率(%)。II = 意图注入,ES = 具备视觉动作评估与校正的证据空间,SW = 滑动窗口。
3. 动态轨迹重建:用滑动窗口和意图注入对抗搜索漂移
为解决长程交互下的上下文膨胀和注意力漂移,VISOR没有采用传统的“不断追加”的对话历史管理方式,而是每轮都动态重构智能体的输入上下文 `Ct` 。其重构公式为:`Ct = [ 初始提示 P; 当前证据空间 Et; (最近W轮原始交互) ]`。
这个机制包含两个关键设计:
固定顶部:原始查询 `P` 和结构化的证据空间 `Et` 被始终固定在上下文顶部,确保核心目标和所有历史发现的精华部分永远不会被挤出去。
滑动窗口:只有最近 `W` 轮 (论文设定 W=2) 的原始交互(即思考-动作-观察的原始记录)被保留在窗口中。这严格限制了上下文中的原始视觉token数量,防止其无限增长拖慢推理、淹没信息。
意图注入:此外,每次系统返回检索结果或裁剪图像给智能体时,都会附带一个提示,重申原始查询,并引导智能体参考证据空间 `E` 。这就像不断提醒代理“不要跑题,结合你之前看到的来思考”,有效对抗了搜索漂移。
表2 消融结果显示,移除滑动窗口(w/o SW)或意图注入(w/o II)均会损害性能,证实了这些组件在长程推理中的必要性。特别有趣的是,当证据空间(ES)被移除后,再移除滑动窗口(w/o ES & SW)反而让性能部分回升,这说明了证据空间和滑动窗口是耦合工作的:滑动窗口负责压缩原始轨迹,证据空间则确保压缩过程中丢失的语义重要信息被提炼保留。
4. 两阶段训练:从模仿到强化学习优化策略
为让模型掌握上述复杂的智能体行为,VISOR采用了“监督微调 + 强化学习”的两阶段训练管道。
监督微调:首先从如SlideVQA等数据集中,用高质量轨迹(来源于大型教师模型)进行监督学习,让模型学会基础的格式化输出(思考-动作)和行为模式,例如在最终作答前进行一次验证性的搜索。
强化学习:为了进一步优化关键决策(如“什么时候停止检索?”),VISOR使用基于组相对策略优化的强化学习。其设计的奖励函数 `r` 综合了答案正确性、检索质量和格式合规性。总奖励计算公式为:`r = (rans + rret) * (1 – Iformat) – 1 * Iformat`。
答案奖励 `rans`:若检索到所有必须的证据页面,则由大型语言模型评判最终答案是否正确(给0或1分);若检索不完全,则鼓励模型诚实承认信息不足而非乱猜(给0或0.2分)。
检索奖励 `rret`:明确鼓励“一次验证”的搜索策略。设 `Δ = 总搜索轮次 – 首次检索完所有必要证据页的轮次`,则奖励规则为:`Δ=0`(无验证)扣0.5分;`Δ=1`(恰好一次验证)得0分(不奖不惩,为最优);`Δ≥2`(过度搜索)则按 `-0.1 * Δ` 惩罚。
格式惩罚 `Iformat`:整个轨迹格式若非法(如未检索就作答),则直接给-1的惩罚。
这种奖励塑造引导模型学会既全面又高效的检索策略。 表4 的训练效果分析显示,经过强化学习后,模型的无效动作率显著降低,任务完成率和准确率大幅提升。
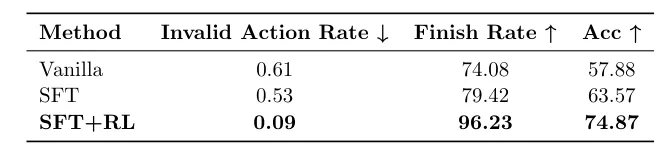
表4:训练阶段对模型的影响。
综上所述,VISOR通过证据空间管理跨页面信息,通过视觉动作评估确保精细操作精度,再通过动态轨迹重建(固定顶部+滑动窗口+意图注入)高效管理上下文与维持注意力,最后通过精心设计的强化学习优化检索和终止策略,形成了一套完整的、端到端可优化的视觉RAG智能体解决方案。
模型表现Results
VISOR在多个基准测试中均表现出色,实现了先进的性能,并且效率很高。首先,根据表1展示的主要结果,VISOR在三个主要基准测试——SlideVQA、ViDoSeek和MMLongBench上,无论使用7B还是3B规模的Qwen2.5-VL模型,都取得了领先的准确率。尤其是在需要跨页面推理的复杂任务中,优势更为明显:在SlideVQA数据集的多跳问题上,VISOR-7B达到了53.62%的准确率,显著超越了此前表现最好的VRAG-RL (43.10%) 和 EVisRAG (42.32%)。这直接验证了其结构化证据空间在整合分散证据方面的有效性。
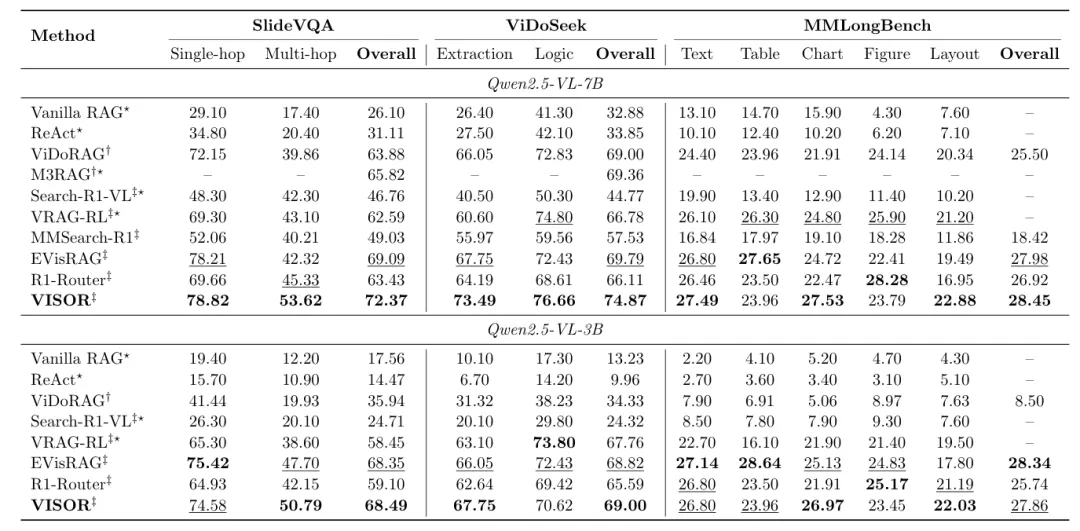
表1:在SlideVQA、ViDoSeek和MMLongBench上的主要结果。我们报告准确率(%)。*表示多智能体架构。†表示微调模型。‡表示在相同或可比实验设置下从已发表论文中取得的结果。每列最佳结果以粗体标出,次佳结果以下划线标出。
其次,VISOR的设计避免了引入不必要的计算开销。如表3所示,VISOR在保证高达84.2%的检索完整性的同时,平均每轮查询仅检索约2.34张图像,远低于ViDoRAG等基线模型检索多达10张图像的做法。这种高效性得益于其动态上下文管理机制,具体体现在图4的时间效率分析中:尽管VISOR采用了需要多轮交互的智能体架构,但其单样本推理延迟仍显著快于多智能体架构的ViDoRAG,并与VRAG-RL等单智能体方法处于竞争水平。这种效率源于其滑动窗口机制有效限制了上下文中原始视觉token的增长,以及视觉动作评估机制减少了不必要的裁剪操作。
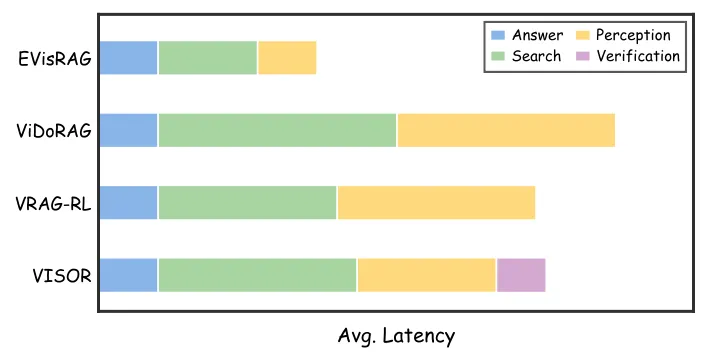
图4:ViDoSeek上平均单样本推理延迟的分解。VISOR引入了验证步骤,但仍比多智能体基线ViDoRAG更快,并与VRAG-RL保持竞争力。

表3:SlideVQA(2,215个样本)上的检索完整度(%)及每轨迹平均检索图像数。完整度 = 所有真实证据页面均被检索到的问题比例。
第三,表2的消融研究结果清晰揭示了VISOR各核心组件的关键作用和协同效应。移除证据空间导致性能最大幅度的下降,这表明参数优化本身无法替代结构化的证据管理能力。移除滑动窗口或意图注入也会导致性能下降。最有趣的发现是,当证据空间被移除后,进一步移除滑动窗口反而让部分性能有所恢复。这说明滑动窗口的压缩能力必须与证据空间的信息提炼能力协同工作:滑动窗口丢弃原始历史,证据空间则保留被提炼的精华。三者共同作用,系统性解决了证据稀疏和搜索漂移问题。
此外,训练过程对模型行为有明显优化。表4显示,经过监督微调,模型的无效动作率和任务完成率得到改善;再经过强化学习训练,模型不仅无效动作率降至极低,任务完成率和最终准确率都得到了最高提升。这得益于论文设计的RL奖励函数,该函数鼓励了“恰好一次”的验证性搜索(即 Δ=1 时惩罚最小),引导智能体学会了何时停止检索。
最后,失败案例分析揭示了当前的瓶颈所在。如图8所示,一个典型失败案例中,VISOR成功检索到了解答问题所需的全部页面,但却在理解饼图的图例时出错,混淆了iOS 8和iOS 9的数据。这说明,即便检索和证据管理机制完美无缺,视觉语言模型本身的细粒度视觉理解能力仍然是影响最终答案准确性的关键因素。而图7展示的成功案例则充分体现了VISOR在多跳、跨文档、渐进式推理场景下的强大能力。

图8:VISOR在多跳MMLongBench问题上的失败案例。两个参考页面均被正确检索,但模型误读饼图图例,将iOS 8扇区(灰色,41%)混淆为iOS 9(蓝色,51%),导致检索成功但最终答案错误。

图7:VISOR在多跳SlideVQA问题上的成功案例。出于布局考虑,检索到的页面图像显示在顶部;对应推理步骤展示于下方。步骤1从不同文档检索到无关页面。步骤2从亚马逊履约中心增长图表中识别出2010年。步骤3检索提供上下文的品类演变幻灯片。步骤4定位到“媒体vs.其他”销售额细分图表并读取答案。最终验证搜索(步骤5)返回了来自不同文档的无关图表页面,但VISOR仍能基于累积证据给出正确答案。
研究局限Limitations
1. 视觉理解瓶颈:尽管VISOR的检索和证据管理机制有效,但模型最终的答案准确率仍受限于视觉语言模型(VLM)本身的细粒度视觉理解能力。如图8的失败案例所示,当面对复杂的视觉结构(如颜色相近的图表图例、密集的表格)时,模型可能产生误读,导致答案错误。
2. 训练数据的依赖与规模:论文指出,在MMLongBench基准上,VISOR-3B模型的性能略低于EVisRAG-3B,原因在于后者在大规模多图像理解数据上进行了微调。这表明VISOR的性能优势在一定程度上依赖于针对性的监督微调数据质量。同时,强化学习阶段采用的基于模型评判(LLM-as-Judge)的奖励函数,其可靠性也依赖于评判模型的准确性。
3. 对固定规模语料库的假设:VISOR的实验设置假设了一个混合的、无文档边界的大规模图像语料库。虽然这符合通用检索场景,但并未专门探索在具有明确结构化层级(如章节、文档)的语料库中,如何利用这些元信息来进一步提升检索效率和推理精度。
未来方向Future Work
1. 提升基础视觉感知能力:未来的工作可以与更强的基础视觉语言模型结合,或者设计专门的训练目标,以增强模型对复杂图表、微小文字、密集布局等视觉元素的精确理解和推理能力。这是从根本上提升视觉RAG系统最终性能的关键。
2. 探索层次化证据管理与检索:可以研究如何结合文档的固有结构信息(如章节、层级),构建更丰富的证据表示,并设计相应的检索策略。这可能使智能体在探索证据空间时更加高效和有方向性,避免在无关文档间盲目搜索。
3. 扩展动作空间与多模态交互:VISOR目前的核心动作是“检索”和“裁剪”。未来可以探索引入更丰富的工具调用,例如执行图表数据提取、表格计算、文本总结等,形成一个更强大的多模态工具使用智能体,以处理更广泛的真实世界文档理解任务。
其他图示
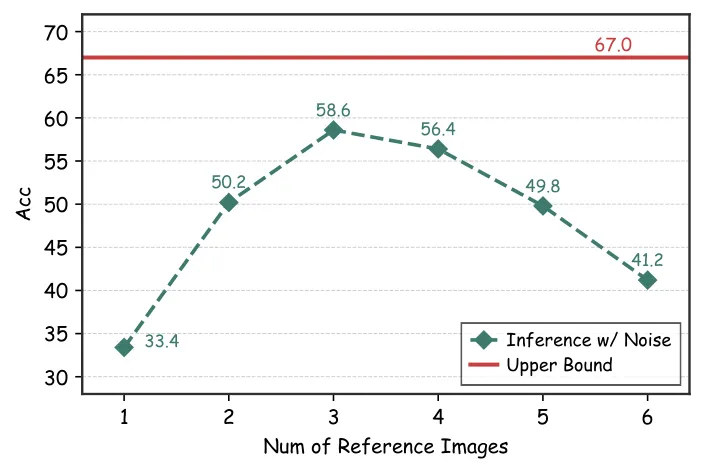
图3:Qwen2.5-VL-7B在SlideVQA(500样本)上的准确率随检索参考图像数量的变化。上限(67.0%)为直接向模型提供正确参考图像时的准确率。

图5:用于LLM-as-Judge评估的提示模板。
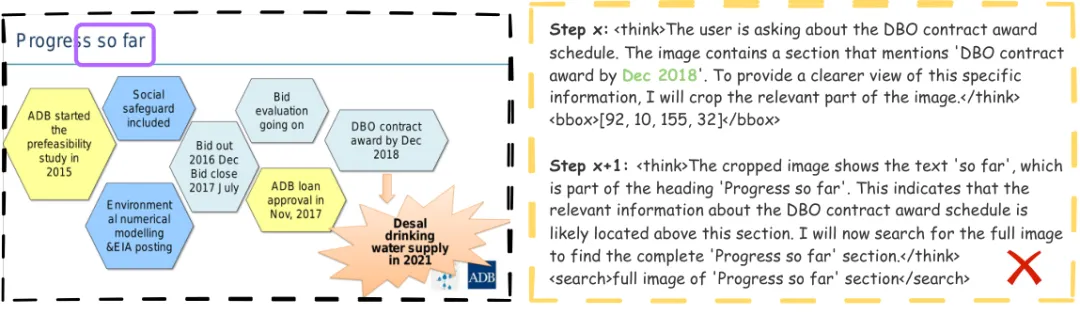
图6:展示VRAG-RL中冗余裁剪操作的典型案例。

图9:VISOR中使用的所有提示模板。每个模板对应智能体循环中不同的交互事件。
其他表格Tables
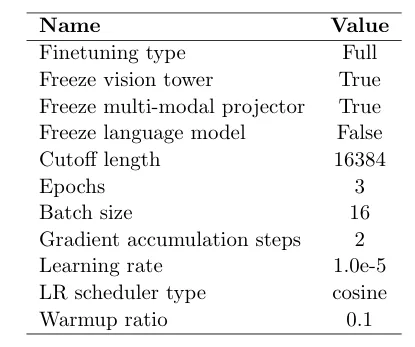
表5:SFT关键超参数。
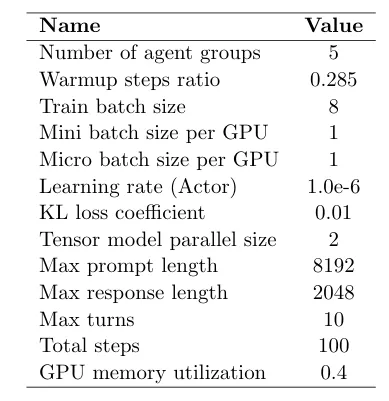
表6:RL关键超参数。
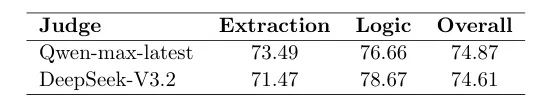
表7:两种评判模型下ViDoSeek评估分数对比。
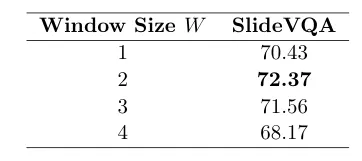
表8:微调模型(SlideVQA)上VISOR对滑动窗口大小W的敏感性。我们报告总体准确率(%)。
LightZebra
AI前沿速递

推文撰写:Kai | 推文审核:Shaw
注:以上总结仅代表个人对论文的理解,仅供研究参考所用,不用于商业用途。若上述理解内容有误,请以论文原文为主。