夜雨聆风
夜雨聆风





OpenClaw部署架构详解:从桌面到数据中心的AI Agent服务器选型指南

赋能科技 智创未来
OpenClaw部署架构详解
桌面到数据中心Agent服务器选型指南



Agent基础设施的范式转移
今年年初,OpenClaw的爆发让桌面级Agent快速走入开发者视野。从Mac Mini到本地工作站,越来越多团队开始在个人设备上构建Agent系统,通过本地工具链完成自动化流程编排。这种“桌面优先”的模式大幅降低了AI应用的试错门槛。
但当Agent从个人实验工具演变为业务关键系统时,问题开始显现:安全策略难以统一执行、网络稳定性不可控、设备管理分散、数据与算力无法池化。这些问题的本质,不在于软件,而在于基础设施仍停留在“单机阶段”。
从行业实践来看,Agent系统正在经历一条清晰的演进路径:
从“工位级部署”走向“数据中心级部署”,从单节点运行走向资源解耦与集群化调度。
在这一过程中,一个关键认知正在被不断验证:
● OpenClaw并非单一负载,而是CPU与GPU协同的双层系统;
● 单机部署适用于验证,生产环境需要分层或集群架构;
● 服务器选型的核心取决于并发规模、模型尺寸与延迟要求。
本文将围绕这一演进路径,系统梳理OpenClaw的架构特性,并给出面向企业场景的服务器选型与部署建议。

PART.01
理解OpenClaw的双层架构

OpenClaw并不是一个简单的应用,而是由两类完全不同的计算负载组成。这种架构分离,是所有部署决策的基础。

Agent编排层:CPU驱动的调度系统
OpenClaw实例承担的是Agent的核心逻辑,包括:
● 工具调用与执行(Tool Calling)
● 工作流状态管理与上下文维护
● API集成与外部系统编排
● 多Agent协同与任务拆解
● 会话记忆与数据处理
这类负载本质上是一个高并发I/O驱动的调度系统,不仅包含传统计算,还涉及轻量模型调用(如embedding、rerank)与异步任务编排。
其性能特征主要体现在:
● 对单核性能敏感(影响响应延迟)
● 对多核心扩展敏感(影响并发能力)
● 对内存带宽与访问效率依赖较高
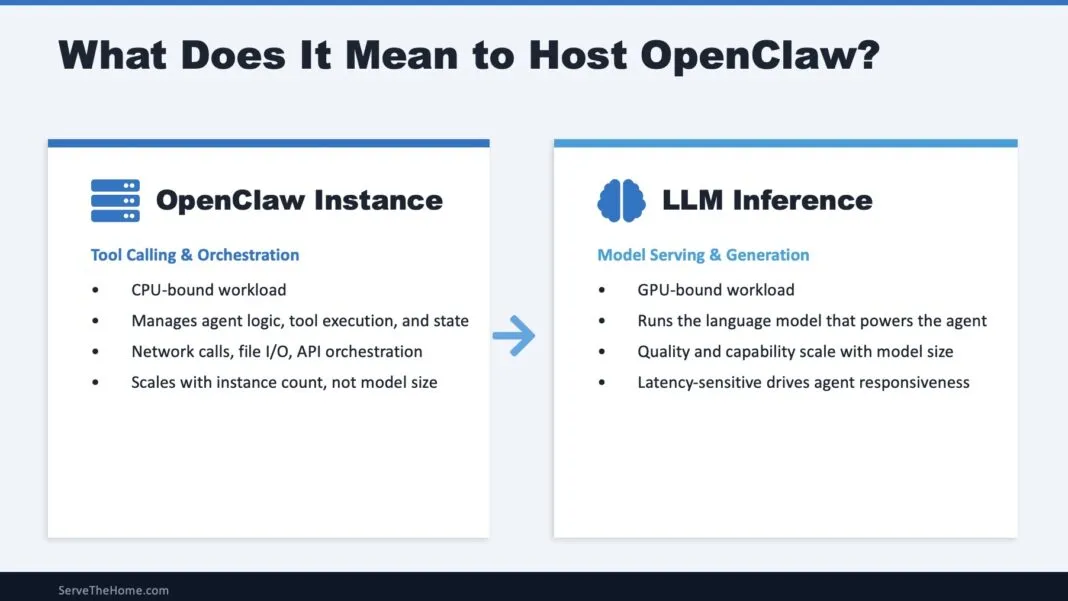

LLM推理层:GPU驱动的计算引擎
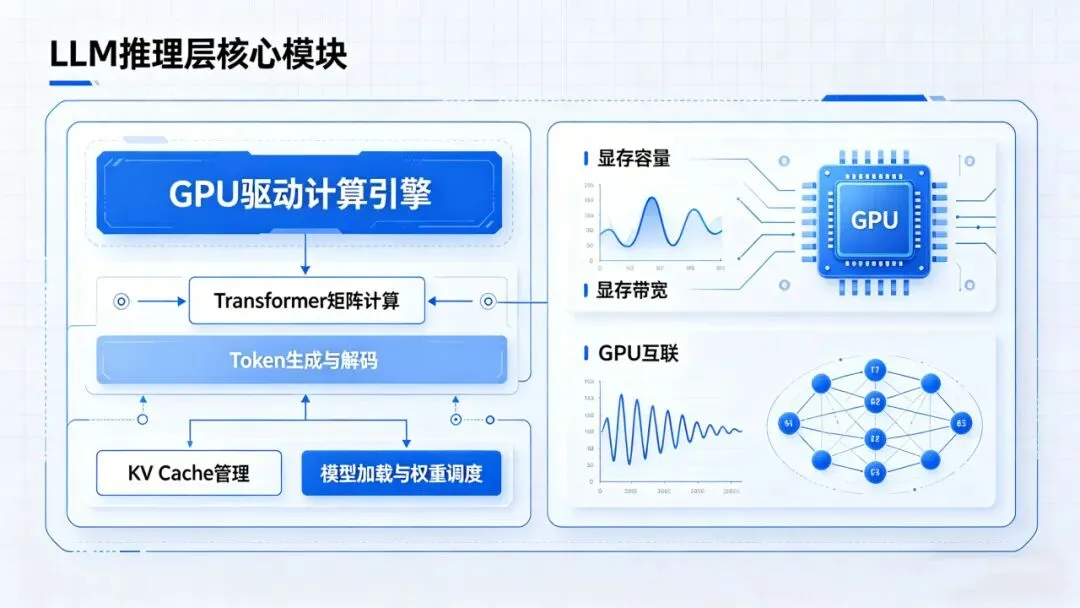
Agent“智能”的核心来自LLM推理,其主要负载包括:
● Transformer矩阵计算
● Token生成与解码
● KV Cache管理
● 模型加载与权重调度
这是典型的并行浮点计算场景,性能瓶颈集中在:
● 显存容量(决定模型规模)
● 显存带宽(决定生成速度)
● GPU互联(决定多卡效率)

架构分离的现实意义
桌面设备(如Mac Mini)通过统一内存架构,在一定程度上模糊了CPU与GPU的边界,使得单机运行中等规模模型成为可能。但这种“一体化体验”容易掩盖真实的系统结构。
例如,128GB统一内存设备确实可以运行压缩后的70B模型(如FP8量化),但在并发能力、推理速度和KV Cache容量方面,难以满足生产需求。
在企业环境中,更主流的方式是:
● Agent运行在CPU服务器
● LLM推理运行在GPU节点或集群
● 两者通过高速网络通信
这种分离架构的优势在于:
● 资源可以独立扩展
● CPU与GPU利用率最大化
● 支持多模型与多业务并行


PART.02
桌面级部署的边界

在进入数据中心部署之前,有必要明确桌面级方案的适用范围。

适用场景
桌面级部署适合以下场景:
● PoC验证与模型微调
● 小规模团队内部工具
● 强本地依赖(文件系统、终端工具等)
● 对预算敏感的初期阶段

企业级约束
当进入生产环境后,桌面部署会面临一系列结构性问题:
安全与合规
企业级安全策略(如零信任、数据隔离、审计机制)难以在分散设备上统一执行。
可靠性风险
办公网络、电力、设备管理都不具备数据中心级别的稳定性。
运维复杂度
日志、监控、备份与升级难以集中管理。
资源孤岛
算力无法池化,负载无法动态调度。
扩展瓶颈
单机内存与显存存在物理上限,无法支撑更大模型或更高并发。


PART.03
数据中心化部署的技术要求

将OpenClaw迁移至数据中心,本质上是为双层架构分别构建最优运行环境。

CPU计算层(Agent层)
核心目标是降低响应延迟并提升并发能力:
● 处理器:高主频 + 多核心(建议8-16核以上)
● 内存:按实例规模线性增长(建议预留冗余)
● 存储:NVMe SSD用于日志与缓存
● 网络:25GbE及以上

GPU推理层(LLM层)
核心瓶颈在显存与带宽:
● 显存容量:决定模型规模
○ 70B FP16 ≈ 140GB(实际需额外冗余)
● 实际建议:按1.2–1.5倍显存规划
● 显存带宽:直接影响Token生成速度
● 多卡互联:NVLink / Infinity Fabric

网络架构
分离架构下,网络成为关键因素:
● 延迟:建议同机房部署(微秒级到亚毫秒级)
● 带宽:25GbE起步,100GbE/400GbE用于集群
● RDMA:降低CPU参与,提高效率


PART.04
面向OpenClaw的服务器选型思路

在实际选型中,更有效的方法不是直接选择型号,而是从负载出发进行匹配。

Agent计算节点(CPU导向)
适用于:
● 高并发Agent调度
● 多工作流编排
● 高主频CPU优先
● 大内存容量(支撑上下文与状态)
● 高速网络(连接GPU层)
赋创定制塔式工作站

CPU:AMD 锐龙 9700X *1
内存:16G DDR5 6000*2
主板:AMD B850系列主板
硬盘1:2T M.2 NVMe PCIe4.0 x4 2280*1
硬盘2:10T SATA 3.5寸 7.2K HDD 企业级*1
网络:双25Gb的光口网卡*1
电源:800W的高效单电源*1

面向70B FP16的LLM推理节点(GPU导向)
适用于:
● 本地大模型推理
● 高吞吐生成任务
● 大显存GPU(80GB/192GB级)
● 高带宽显存架构
● GPU互联拓扑优化
赋创FG4412G-G4

CPU:Intel Gold 6530*2
内存:64G DDR5 RECC 4800*6
硬盘1:960G U.2 NVMe PCIe4 x4 2.5寸 SSD 企业级*2
硬盘2:3.84T U.2 NVMe PCIe4 x4 2.5寸 SSD 企业级*3
其他配件:Intel VROC KEY *1
GPU:RTX 4090 48G 双宽涡轮卡*4
网络:双25Gb的光口网卡*1
对于405B级模型,单节点理论可支持部署,但通常需要结合张量并行或推理框架优化(如TensorRT-LLM、DeepSpeed)才能实现有效运行。

融合节点(中小规模)
适用于:
● 部门级部署
● 边缘场景
特点:
● CPU + GPU同节点
● 部署简单
● 扩展能力有限

网络与调度层
当进入集群阶段,需要引入:
● RDMA网络
● Kubernetes调度
● 推理服务编排(如vLLM / Triton)

PART.05
部署模式选型决策

在实际落地中,可以根据业务规模进行分阶段规划:
|
阶段 |
架构建议 |
典型特征 |
|
起步期 |
桌面/云API |
低成本验证 |
|
成长期 |
融合节点 |
本地模型初步落地 |
|
成熟期 |
CPU+GPU分离 |
规模化部署 |
|
大规模期 |
GPU集群 |
多模型调度 |
选型的核心变量始终是:
● 并发规模
● 模型尺寸
● 延迟要求
● 运维能力
该架构在实际应用中具备以下特点:
资源隔离:生产环境与开发测试环境相互独立
成本优化:不同规模模型匹配不同硬件层级
弹性扩展:各层可根据业务需求独立扩容
在实施过程中可以观察到,软件层优化对性能释放的影响往往较为显著。例如,在相同硬件条件下,通过推理引擎优化、KV Cache 管理优化以及批处理策略调整,整体吞吐能力通常可以获得明显提升。

PART.06
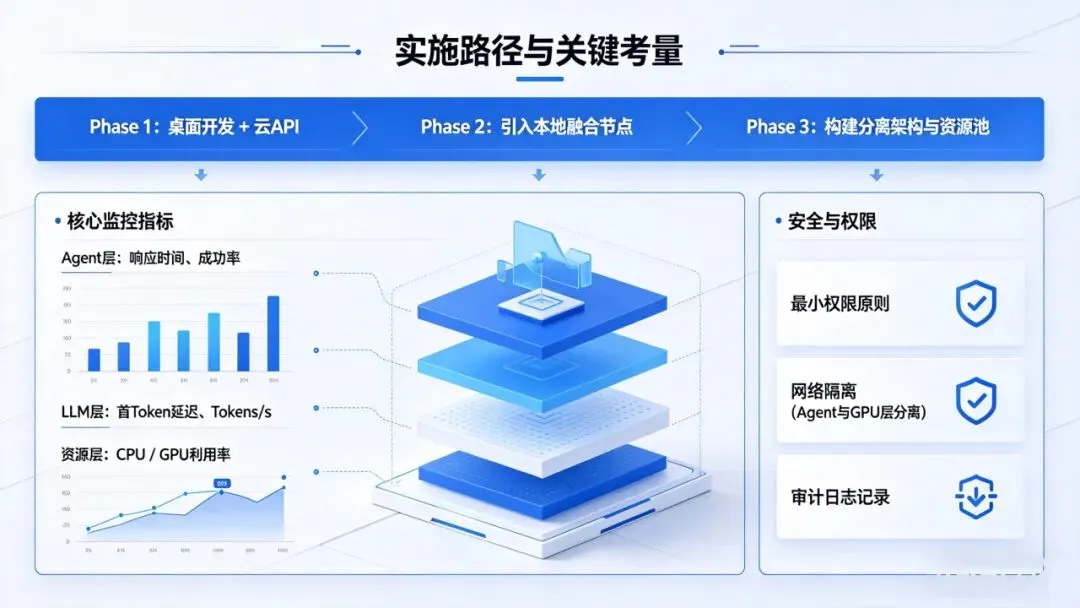
实施路径与关键考量


渐进式迁移
● Phase 1:桌面开发 + 云API
● Phase 2:引入本地融合节点
● Phase 3:构建分离架构与资源池

核心监控指标
● Agent层:响应时间、成功率
● LLM层:首Token延迟、Tokens/s
● 资源层:CPU / GPU利用率

安全与权限
● 最小权限原则
● 网络隔离(Agent与GPU层分离)
● 审计日志记录

PART.07
OpenClaw企业部署常见问题

Q
OpenClaw一定需要GPU吗?
不一定,但如果涉及本地大模型推理(尤其70B以上),GPU是必要条件。
A
Q
可以单机部署吗?
可以用于验证,但生产环境建议采用分离或集群架构。
A
Q
70B模型需要多少显存?
FP16约140GB,INT8约70GB,INT4约35GB,建议预留1.2–1.5倍冗余。
A
Q
为什么Agent更依赖CPU主频?
因为调度与响应属于低延迟任务,对单线程性能敏感。
A
Q
什么时候需要GPU集群?
当并发、模型规模或延迟要求超过单机能力时。
A
Q
企业部署最大挑战是什么?
资源拆分、网络延迟与推理成本控制。
A

PART.07
赋能科技,智创未来

从桌面设备到数据中心,OpenClaw的部署演进,本质是从“单机实验”走向“系统工程”。
理解CPU与GPU的职责分工,是构建稳定、高效Agent系统的前提。在此基础上,通过合理的架构设计与资源规划,才能真正让Agent从演示走向生产,成为可持续运行的业务基础设施。
在实际落地过程中,很多团队面临的挑战并不在于是否理解架构,而在于:
● 如何根据业务负载选择合适的CPU/GPU组合
● 如何在成本、性能与扩展性之间取得平衡
● 如何让部署方案具备可演进能力,而不是一次性投入

针对这些问题,赋创基于AI算力底座建设经验,提供从单节点部署到GPU集群的完整方案支持,包括Agent计算节点、推理节点以及整体架构设计与调优能力,帮助企业在不同阶段实现平滑演进。

如果你正在评估OpenClaw或类似Agent系统的部署路径,可以基于本文的架构框架进行初步判断,再结合具体业务需求进行方案细化。如需获取针对具体模型规模或并发需求的部署建议,可进一步沟通获取定制化方案。

END
往期精选