 夜雨聆风
夜雨聆风





AI工具链效率提升——以ClaudeCode为例,从Demo代码到工程化落地
最近看招聘JD,发现一个有趣的变化。
两年前,公司招人还只看技术栈:会Spring Boot、懂Kafka、熟悉React。现在呢?

JD里加了一条:熟练使用AI编程工具,能通过Prompt引导模型生成符合项目规范的代码。
这变化有点意思。不是说不用写代码了,而是说——你能不能让AI写出来的代码,像你亲手写的一样规范、可维护、能在现有架构里跑通。
Demo代码谁都会写。但要写出能进生产环境的代码,得懂架构、懂约束、懂边界。AI也是一样,给它一个”帮我写个排序”,它能给你一个快速排序。但你让它”基于现有Spring Boot架构,优化订单模块的排序逻辑,要兼容现有缓存机制,不能影响SLA”,这就不一样了。
问题来了:怎么让AI写出工程级代码,而不是Demo级代码?
工程化提示词:从”给我写个排序”到”基于现有架构优化排序模块”
“帮我写个排序”这种提示词,就像对餐馆服务员说”给我来个菜”。你点什么?什么口味?几个人吃?没说清楚,服务员只能给你端上来一个最普通的番茄炒蛋。
工程化提示词不一样,得有结构。
▪ 三层提示词框架:上下文层、任务层、约束层
上下文层告诉AI”你在哪儿”:
项目架构:Spring Boot 3.2 + MyBatis-Plus + Redis代码规范:遵循阿里巴巴Java开发手册目标模块:com.example.order.service现有排序:在内存中用Stream.sorted(),数据量>1万时性能下降
任务层告诉AI”你要干什么”:
优化订单列表排序逻辑,支持以下场景:1. 默认按创建时间倒序2. 支持按金额、状态、用户自定义字段排序3. 排序字段支持升序和降序4. 需要考虑分页场景
约束层告诉AI”你不能做什么”:
技术约束:– 不能破坏现有缓存机制(order_cache:*)– 查询时间不能超过200ms(p99)– SQL性能评分>80分– 需要兼容MySQL 8.0代码约束:– 必须使用MyBatis-Plus的QueryWrapper– 添加必要的日志和监控埋点– 单元测试覆盖率>80%
这三层写下来,Claude Code生成的代码,基本就是你想要的那个样子。
▪ 可复用提示词模板
每次都从头写三层提示词?太麻烦了。搞个模板库,像用代码模板一样用提示词模板。
比如,针对Spring Boot Service层重构,你可以准备一个模板:
# prompt-templates/spring-boot-service-refactor.yamlname: “Spring Boot Service Refactor”description: “重构Spring Boot Service层代码,保持业务逻辑不变,提升代码质量和性能”context_layer: | 项目信息: – 项目名称:{{project_name}} – 技术栈:{{tech_stack}} – 代码规范:{{code_standards}} – 相关模块:{{related_modules}}task_layer: | 重构目标: – 优化{{service_name}}的{{method_name}}方法 – 当前问题:{{current_issues}} – 期望改进:{{expected_improvements}}constraints_layer: | 技术约束: – 必须兼容现有API接口 – 不能影响下游调用方 – 性能指标:{{performance_requirements}} 代码约束: – 遵循{{code_style_guide}} – 添加必要的异常处理 – 补充单元测试
用的时候,替换掉占位符就行。Jinja2、Velocity都可以用,选你顺手的。
▪ 实战案例:用ClaudeCode重构Spring Boot Service
来看个真实案例。某电商系统的订单列表查询,原先的代码长这样:
@Service@RequiredArgsConstructorpublic class OrderService { private final OrderMapper orderMapper; private final RedisTemplate redisTemplate; public List listOrders(Long userId, String status, String sortBy) { // 先查缓存 String cacheKey = “orders:” + userId + “:” + status; List cached = (List) redisTemplate.opsForValue().get(cacheKey); if (cached != null) { // 内存排序 if (“amount”.equals(sortBy)) { cached.sort(Comparator.comparing(Order::getAmount).reversed()); } else if (“createTime”.equals(sortBy)) { cached.sort(Comparator.comparing(Order::getCreateTime).reversed()); } return cached; } // 查数据库 QueryWrapper wrapper = new QueryWrapper<>(); wrapper.eq(“user_id”, userId); if (status != null) { wrapper.eq(“status”, status); } List orders = orderMapper.selectList(wrapper); // 写缓存 redisTemplate.opsForValue().set(cacheKey, orders, 10, TimeUnit.MINUTES); return orders; }}
这段代码问题不少:
-
缓存key设计不合理,导致缓存命中率低 -
排序逻辑在内存中做,数据量大时性能差 -
缓存更新策略简单,容易读到脏数据 -
缺少异常处理和监控
用工程化提示词引导Claude Code重构:
# 上下文层项目:某电商订单系统技术栈:Spring Boot 3.2 + MyBatis-Plus + Redis 7.0 + MySQL 8.0代码规范:阿里巴巴Java开发手册(泰山版)目标方法:OrderService.listOrders()性能要求:p99 < 200ms,缓存命中率 > 80%# 任务层重构OrderService.listOrders()方法,解决以下问题:1. 缓存key设计不合理,导致缓存命中率低(当前只有40%)2. 排序逻辑在内存中做,订单数量>5000时响应时间>1s3. 缓存更新策略简单,订单状态变更后缓存未失效4. 缺少异常处理和监控埋点# 约束层技术约束:– 必须使用MyBatis-Plus的QueryWrapper– 排序逻辑下沉到数据库,避免内存排序– 缓存失效策略要考虑订单状态变更场景– 需要添加Metrics监控(查询次数、缓存命中率、响应时间)代码约束:– 遵循阿里巴巴Java开发手册– 方法签名不能改变,保证兼容性– 添加必要的异常处理– 补充单元测试(覆盖率>80%)
Claude Code给出的重构方案(节选):
@Service@RequiredArgsConstructor@Slf4jpublic class OrderService { private final OrderMapper orderMapper; private final RedisTemplate redisTemplate; private final MeterRegistry meterRegistry; private static final String CACHE_KEY_PREFIX = “order:list:”; private static final Duration CACHE_TTL = Duration.ofMinutes(10); /** * 查询订单列表 * * @param userId 用户ID * @param status 订单状态(可选) * @param sortBy 排序字段(amount/createTime/自定义字段) * @return 订单列表 */ public List listOrders(Long userId, String status, String sortBy) { Timer.Sample sample = Timer.start(meterRegistry); try { // 构建缓存key(包含排序字段,避免缓存未命中时排序错误) String cacheKey = buildCacheKey(userId, status, sortBy); // 尝试从缓存获取 List cached = getCachedOrders(cacheKey); if (cached != null) { meterRegistry.counter(“order.cache.hit”).increment(); return cached; } meterRegistry.counter(“order.cache.miss”).increment(); // 查数据库(排序下沉到SQL层) QueryWrapper wrapper = buildQueryWrapper(userId, status, sortBy); List orders = orderMapper.selectList(wrapper); // 写缓存 setCachedOrders(cacheKey, orders); return orders; } catch (Exception e) { log.error(“查询订单列表失败, userId={}, status={}”, userId, status, e); throw new OrderServiceException(“查询订单列表失败”, e); } finally { sample.stop(Timer.builder(“order.list.duration”) .tag(“status”, status) .register(meterRegistry)); } } private String buildCacheKey(Long userId, String status, String sortBy) { return String.format(“%s%d:%s:%s”, CACHE_KEY_PREFIX, userId, StringUtils.defaultString(status, “all”), StringUtils.defaultString(sortBy, “createTime:desc”)); } @SuppressWarnings(“unchecked”) private List getCachedOrders(String cacheKey) { try { return (List) redisTemplate.opsForValue().get(cacheKey); } catch (Exception e) { log.warn(“从缓存获取订单失败, cacheKey={}”, cacheKey, e); return null; } } private void setCachedOrders(String cacheKey, List orders) { try { redisTemplate.opsForValue().set(cacheKey, orders, CACHE_TTL); } catch (Exception e) { log.warn(“写入订单缓存失败, cacheKey={}”, cacheKey, e); } } private QueryWrapper buildQueryWrapper(Long userId, String status, String sortBy) { QueryWrapper wrapper = new QueryWrapper<>(); wrapper.eq(“user_id”, userId); if (StringUtils.isNotBlank(status)) { wrapper.eq(“status”, status); } // 排序逻辑下沉到数据库 if (StringUtils.isBlank(sortBy) || “createTime”.equals(sortBy)) { wrapper.orderByDesc(“create_time”); } else if (“amount”.equals(sortBy)) { wrapper.orderByDesc(“amount”); } else { // 支持自定义字段排序,但要白名单校验 if (isSafeSortField(sortBy)) { String[] parts = sortBy.split(“:”); wrapper.orderBy(true, “asc”.equals(parts[1]), parts[0]); } else { log.warn(“不安全的排序字段: {}”, sortBy); wrapper.orderByDesc(“create_time”); } } return wrapper; } private boolean isSafeSortField(String sortBy) { // 白名单校验,防止SQL注入 Set allowedFields = Set.of(“amount:asc”, “amount:desc”, “createTime:asc”, “createTime:desc”); return allowedFields.contains(sortBy); }}
这代码好看多了:
-
缓存key包含排序字段,避免排序逻辑不一致 -
排序下沉到SQL层,利用数据库索引 -
异常处理、日志、监控都有了 -
有SQL注入防护
关键点:不是Claude Code懂Spring Boot,是你的提示词给了它足够的上下文和约束。模型是通用的,但Harness是你定制的。
代码审查与优化:AI如何帮你”挑刺”
写代码只是第一步。写得好不好?有没有bug?性能会不会炸?这才是关键。
以前Code Review靠人眼,现在可以让AI先跑一遍,发现那些”人眼容易错过”的问题。
▪ 代码异味检测:重复代码、过长方法、复杂条件
Claude Code 2026年加了Security扫描功能,能自动检测安全漏洞。其实代码异味、性能问题,它也能发现。
让它review一段代码:
请review以下代码,重点关注:1. 代码异味:重复代码、过长方法、复杂条件、魔法数字2. 潜在bug:空指针、资源泄露、并发问题3. 性能问题:不必要的查询、内存浪费、算法复杂度[代码片段]
它会给你一份详细的报告:
🔍 代码审查报告⚠️ 代码异味1. 重复代码(严重) – OrderService.listOrders() 和 OrderService.searchOrders() 中有大量重复的缓存逻辑 – 建议:提取为 CachedOrderRepository2. 过长方法(中等) – OrderService.processOrder() 有87行,包含多个职责:验证、计算、发送通知 – 建议:拆分为 validateOrder()、calculatePrice()、sendNotification()3. 复杂条件(中等) – 第142行的if嵌套达到4层 – 建议:使用卫语句或策略模式🐛 潜在bug1. 空指针风险(高) – OrderService.listOrders() 中,userId可能为null,直接用于字符串拼接会NPE – 建议:添加校验或使用Objects.toString()2. 资源泄露(中) – FileService.readFile() 未关闭InputStream – 建议:使用try-with-resources🐌 性能问题1. N+1查询(高) – OrderService.listOrders() 在循环中调用 userService.getUser() – 建议:使用JOIN查询或批量查询2. 缓存失效策略不合理(中) – 订单状态变更后,对应缓存未失效 – 建议:使用消息队列异步失效缓存
这比人眼看代码快多了,也更全面。你写的代码,自己很难挑出毛病——因为你就是那么想的。AI不一样,它没有”思维惯性”,能发现那些你习以为常的问题。
▪ 性能瓶颈分析:SQL慢查询、N+1问题、缓存失效
性能问题最烦人。功能都对了,就是慢。上线后秒杀活动一来,直接炸。
Claude Code能帮你发现这些坑。
给它一段SQL,让它分析:
SELECT o.*, (SELECT u.name FROM user u WHERE u.id = o.user_id) as user_name, (SELECT COUNT(*) FROM order_item i WHERE i.order_id = o.id) as item_count, (SELECT SUM(i.price * i.quantity) FROM order_item i WHERE i.order_id = o.id) as total_amountFROM orders oWHERE o.status = ‘PAID’ AND o.create_time > DATE_SUB(NOW(), INTERVAL 7 DAY)ORDER BY o.create_time DESCLIMIT 100;
它的分析:
🐌 SQL性能分析报告❌ 严重问题1. 子查询(N+1问题的SQL版本) – 每个订单都执行3个子查询(user_name、item_count、total_amount) – 如果返回100条数据,实际执行301次查询(1次主查询 + 300次子查询) – 影响:查询时间 = 单次查询时间 × 数据量,随着数据量增长线性恶化2. 缺少索引 – WHERE条件使用 status 和 create_time,但未发现联合索引 – 建议:添加 INDEX idx_status_create_time (status, create_time)✅ 优化方案1. 改为JOIN查询(推荐) “`sql SELECT o.id, o.user_id, o.status, o.create_time, u.name as user_name, COUNT(i.id) as item_count, SUM(i.price * i.quantity) as total_amount FROM orders o LEFT JOIN user u ON u.id = o.user_id LEFT JOIN order_item i ON i.order_id = o.id WHERE o.status = ‘PAID’ AND o.create_time > DATE_SUB(NOW(), INTERVAL 7 DAY) GROUP BY o.id, u.name ORDER BY o.create_time DESC LIMIT 100;
-
查询次数:从301次降到1次 -
预计性能提升:10-50倍(取决于数据量)
-
添加索引
CREATE INDEX idx_status_create_time ON orders(status, create_time);
-
考虑分页优化
-
如果数据量很大,LIMIT 100需要扫描更多数据 -
建议:使用”游标分页”或”seek method”
这种分析,你一个人得花半小时。AI几秒钟给你一份完整的报告,还能给出优化方案。### 实战案例:ClaudeCode发现并修复性能问题真实案例。某系统的一个接口,响应时间从100ms慢慢涨到了3s。上线后才暴露问题,用户投诉来了。让Claude Code分析整个调用链:“`java@RestController@RequiredArgsConstructorpublic class ProductController { private final ProductService productService; @GetMapping(“/products”) public List listProducts(@RequestParam String category) { return productService.listProducts(category); }}@Service@RequiredArgsConstructorpublic class ProductService { private final ProductMapper productMapper; private final CategoryService categoryService; public List listProducts(String category) { // 查询分类信息(每个产品都会调用一次) Category categoryInfo = categoryService.getByName(category); // 查询产品列表 List products = productMapper.selectByCategory(category); // 转换为VO return products.stream() .map(p -> { ProductVO vo = new ProductVO(); vo.setId(p.getId()); vo.setName(p.getName()); vo.setPrice(p.getPrice()); // 这里又查了一次分类(N+1问题) vo.setCategoryName(categoryService.getByName(p.getCategory()).getName()); return vo; }) .collect(Collectors.toList()); }}
Claude Code发现了问题:
🐌 性能瓶颈分析❌ N+1查询问题(严重)– ProductController.listProducts() 调用 ProductService.listProducts()– ProductService.listProducts() 在循环中调用 categoryService.getByName()– 如果返回100个产品,实际执行101次数据库查询(1次产品查询 + 100次分类查询)– 响应时间 = 单次查询时间(10ms) × 101 ≈ 1s(实际测试3s,因为还有网络开销)✅ 优化方案1. 批量查询分类(推荐) – 先一次性查询所有需要的分类 – 在内存中组装产品VO2. 使用JOIN查询(更彻底) – 在SQL层面完成数据关联 – 减少数据库往返次数3. 添加缓存(加速) – 分类信息变化不频繁,可以缓存 – 建议TTL: 1小时
优化后的代码:
@Service@RequiredArgsConstructorpublic class ProductService { private final ProductMapper productMapper; private final CategoryService categoryService; private final RedisTemplate redisTemplate; public List listProducts(String category) { // 查询产品列表List products = productMapper.selectByCategory(category); if (products.isEmpty()) { return Collections.emptyList(); } // 提取所有分类名称(去重) Set categoryNames = products.stream() .map(Product::getCategory) .collect(Collectors.toSet()); // 批量查询分类(一次查询搞定所有分类) List categories = categoryService.batchGetByNames(categoryNames); Map categoryMap = categories.stream() .collect(Collectors.toMap(Category::getName, Function.identity())); // 转换为VO(使用内存中的分类数据) return products.stream() .map(p -> { ProductVO vo = new ProductVO(); vo.setId(p.getId()); vo.setName(p.getName()); vo.setPrice(p.getPrice()); vo.setCategoryName(categoryMap.get(p.getCategory()).getName()); return vo; }) .collect(Collectors.toList()); }}
结果:响应时间从3s降到50ms,提升了60倍。
这不是模型变强了,是你的Harness(批量查询、内存映射)变好了。
系统化提升效率:从”单点工具”到”工作流集成”
用Claude Code生成一段代码,这只是单点提升。真正让效率起飞的,是把它集成到你的工作流里。
▪ CI/CD集成:自动代码审查
每次提交代码都手动让AI审查?太麻烦了。把它集成到CI/CD里,自动跑。
GitHub Actions配置示例:
name: AI Code Reviewon: pull_request: types: [opened, synchronize]jobs: ai-review: runs-on: ubuntu-latest steps: – uses: actions/checkout@v4 – name: Install Claude Code run: npm install -g @anthropic-ai/claude-code – name: Get changed files id: changed-files uses: tj-actions/changed-files@v42 with: files: | src/**/*.java **/*.ts – name: AI Code Review env: ANTHROPIC_API_KEY:${{secrets.ANTHROPIC_API_KEY}} run: | for file in ${{ steps.changed-files.outputs.all_changed_files }}; do echo “Reviewing $file…” claude code review \ –file “$file” \ –focus “security,performance,code-smell” \ –output “review-$file.md” done – name: Comment on PR uses: actions/github-script@v7 with: script: | const fs = require(‘fs’); const glob = require(‘glob’); const files = glob.sync(‘review-*.md’); let body = ‘## 🤖 AI Code Review Report\n\n’; for (const file of files) { const content = fs.readFileSync(file, ‘utf8’); body += ‘### ‘ + file.replace(‘review-‘, ”).replace(‘.md’, ”) + ‘\n\n’; body += content + ‘\n\n—\n\n’; } github.rest.issues.createComment({ issue_number: context.issue.number, owner: context.repo.owner, repo: context.repo.repo, body: body });
这样,每次PR都会自动跑一遍AI代码审查,直接在PR里给反馈。你不用手动触发,也不用等。
▪ 文档生成:从代码到文档的自动化
代码写得好不好,文档也很重要。但写文档很烦,你懂的。
让Claude Code从代码自动生成文档:
# 生成API文档claude docs generate \ –input src/main/java/com/example/api \ –output docs/api.md \ –format “swagger” \ –include “request,response,example”# 生成架构图claude docs generate \ –input src/main/java/com/example \ –output docs/architecture.md \ –type “architecture” \ –format “mermaid”# 生成变更日志claude docs changelog \ –since “2024-01-01” \ –output CHANGELOG.md
代码改了,文档自动更新。不用你每次改代码还要想着改文档。
▪ 知识沉淀:构建项目专属提示词库
你每次用Claude Code,其实都是在积累经验。这些经验,应该沉淀下来,变成团队的资产。
搞一个项目专属的提示词库:
prompts/├── architecture/│ ├── spring-boot-service.yaml│ ├── mybatis-mapper.yaml│ └── redis-cache.yaml├── review/│ ├── security-check.yaml│ ├── performance-check.yaml│ └── style-check.yaml├── refactor/│ ├── extract-method.yaml│ └── remove-duplication.yaml└── test/ ├── unit-test.yaml └── integration-test.yaml
每个提示词模板,都是你踩过的坑、总结的经验。新同事来了,不用从头学,直接用这些模板,就能写出符合项目规范的代码。
Claude Code 2026年还加了Skills功能,可以把这些提示词打包成Skill,一键安装。团队里每个人都能用上同样的”最佳实践”。
关键洞察:别怪模型,看看harness
说到这儿,你应该明白了:AI工具链的本质是工程能力,不是模型能力。
LangChain 的 Coding Agent 在 Terminal Bench 2.0 上的成绩从 52.8% 涨到了 66.5%,排名从 Top 30 跳到 Top 5。模型完全没换,他们只改了三种东西——系统提示词、工具配置、中间件钩子。
同一个模型,换了套缰绳(Harness),成绩天差地别。
▪ Harness Engineering的重要性
Harness这个概念,最近挺火。但说白了,就是给AI Agent设计”缰绳+马鞍+跑道护栏+反馈镜子”的工程方法。
它不优化模型本身,而是构建一整套让Agent跑得稳、跑得久、不跑偏的运行控制系统。

三层关系很好懂:
- Prompt Engineering
是你对马说的话——”向左转”、”跑快点” - Context Engineering
是帮马看路的——地图、路标、地形 - Harness Engineering
是缰绳、马鞍、围栏和道路本身——让十匹马同时安全跑起来的系统
Prompt管你问什么;Context管你给模型看什么;Harness管整个东西怎么运转。
▪ 为什么同样的模型,不同的工具效果天差地别
OpenAI的Codex团队,三个工程师用Codex搞出了一个100万行代码的Beta产品,零行人工手写,约1500个PR合并。速度快了十倍。
但有个问题没人聊:这100万行代码的质量怎么样?
速度快了十倍,不代表产出好了十倍。每人每天3.5个PR,谁在做代码审查?六个月后需要改需求的时候,这100万行好改吗?
答案:看你的Harness怎么设计。
如果只是让AI随便写,不约束、不审查、不沉淀,那100万行代码就是100万行技术债务。但如果有一套完整的Harness——代码规范检查、自动化测试、架构约束、持续review——那这100万行代码就是生产力。
▪ 如何为你的项目定制harness
怎么给项目定制Harness?三条就够:
第一,给地图,不给说明书。
你的项目结构、文件关系、关键约束,这些得告诉AI。但不要把每步都写死。AI需要方向感,不需要僵化步骤。
写个PROJECT_CONTEXT.md:
# 项目上下文## 项目概述– 项目名称:电商订单系统– 技术栈:Spring Boot 3.2 + MyBatis-Plus + Redis 7.0 + MySQL 8.0– 代码规范:阿里巴巴Java开发手册(泰山版)## 目录结构

## 关键约束– 所有Service方法必须添加日志和监控埋点– 数据库查询必须走MyBatis-Plus的QueryWrapper– 缓存key统一格式:`模块:类型:参数`,如 `order:list:123`– 禁止在循环中查询数据库(N+1问题)– 任何涉及金额的计算必须使用BigDecimal## 性能要求– 接口响应时间p99 < 200ms– 缓存命中率 > 80%– SQL性能评分 > 80分
让Claude Code先读这个文件,再让它干活,效果完全不一样。
第二,每次犯错加一条规则。
空文件开始,Agent犯一个错就加一条。三个月后,那个文件就是你的Harness——高度定制,因为全是你场景里真实出过的问题。
比如,你可以维护一个RULES.md:
# Claude Code 使用规则## 2024-03-15– 问题:在循环中调用userService.getUser(),导致N+1查询– 规则:任何涉及批量用户查询的场景,必须使用batchGetByIds()## 2024-03-18– 问题:缓存key没有包含查询条件,导致缓存未命中– 规则:缓存key必须包含所有影响结果的关键参数## 2024-03-22– 问题:BigDecimal直接用double构造,导致精度丢失– 规则:BigDecimal必须使用String构造器,禁止使用double构造器## 2024-04-01– 问题:异常处理太笼统,直接catch Exception– 规则:异常处理要精确到具体异常类型,不能直接catch Exception
这个文件会越长,你的Harness就越强。
第三,让AI查AI。
Anthropic搞了个三Agent架构:
-
规划者(Planner):负责把简单指令扩展成详细的产品规格 -
生成者(Generator):按迭代一次做一个功能 -
评估者(Evaluator):跑端到端测试
灵感来自生成对抗网络(GAN)——训练一个专门的评估者让他一直挑刺,比让生成者自己检查自己管用得多。谁都不擅长批评自己,AI也一样。
最简单的做法:写完后开一个新对话,把结果贴进去,找出所有问题。你会惊讶第二个AI能发现多少第一个漏掉的。
总结:AI工具链的本质是工程能力,不是模型能力
Claude Code 2026年更新了很多功能:/loop定时任务、Computer Use、Voice Mode、Remote Control、背景Agent……这些功能很炫,但它们只是工具。
真正让效率起飞的,是你怎么用这些工具。
工程化提示词、自动化代码审查、持续集成、知识沉淀……这些才是AI工具链的核心价值。模型只是引擎,Harness才是方向盘、刹车、导航系统。
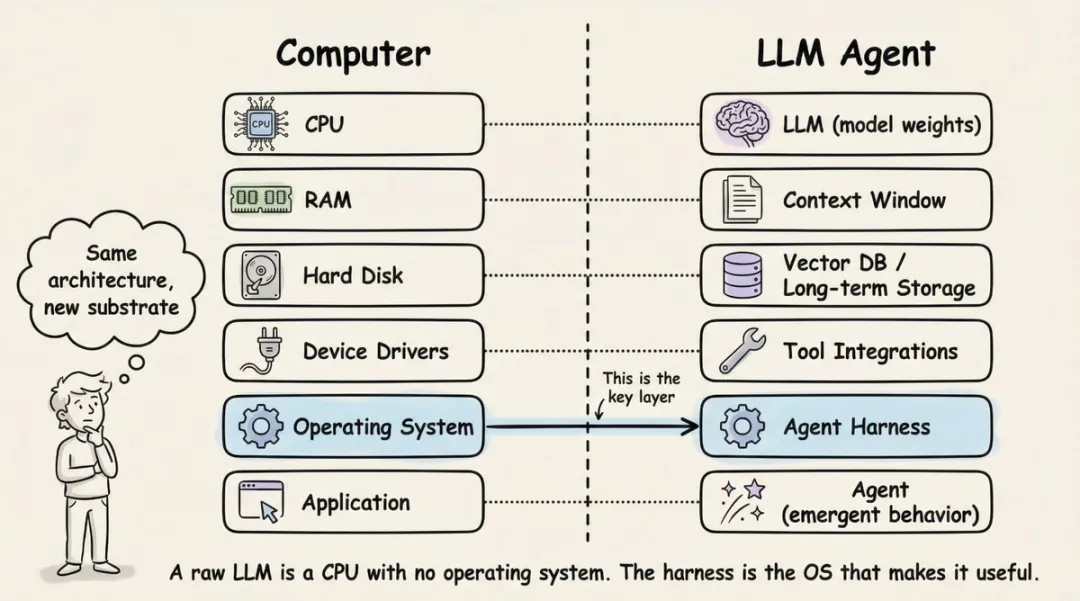
下次Claude Code失败时,别怪模型。看看你的harness——是不是上下文给得不够?是不是约束写得太松?是不是缺少必要的检查?
问题不在马身上,在缰绳上。
灵魂拷问:
你现在用AI工具,是每次都从头写提示词,还是有一套可复用的模板库?你的团队有没有积累项目专属的”最佳实践”,还是每个人都在重新造轮子?
一句话带走:
AI工具链不是让AI取代你写代码,而是让你通过工程化手段,让AI写出你想写但没时间写的代码。
踩坑提醒:
别指望AI一次就写出完美代码。给它上下文、给它约束、给它反馈,迭代优化才是正道。这不是AI的问题,这是工程的问题。
即便如今已迈入大模型编排(Harness)时代,最终驱动大模型生效的核心依旧是提示词。上下文工程是骨架,提示词工程是表象,二者相辅相成,共同支撑起完整的大模型调度与应用体系。
延伸阅读:
-
Claude Code 2026 全能力解读 https://juejin.cn/post/7630042678585638922 -
ClaudeCode-Harness Engineering驾驭者工程的最佳实践者http://m.toutiao.com/group/7626928899976380964/ -
Claude Code Prompt Engineering 实战手册:7个让模型输出质量飞升的技巧 https://juejin.cn/post/7622684825675399231 -
Claude Code 最详细的小白入门教程! -
Agent Harness工程化实战:如何解决大模型幻觉带来的不确定性?答案在文中+开箱可用的github源码 -
Agent三国的”最后一公里”:Hermes、Harness和OpenClaw到底在争什么? -
一文讲透 Harness:AI 从“聪明”到“靠谱”的关键跃迁