 夜雨聆风
夜雨聆风





国产GPU破局之战:当摩尔线程开始卷AI软件栈,CUDA的护城河还稳吗?
问一问
这行代码背后藏着的魔鬼,是摩尔线程MUSA SDK里那行魔幻的 import torch_musa。
就在发稿前几天,我盯着屏幕上的生成结果——一张512×512的赛博朋克少女,画质细腻,没有崩坏。右下角的时间戳显示:8.2秒。同款提示词在RTX 3060上是2.7秒,在Arc A770上是4.5秒。但这张卡只卖1999元,而且它来自一家成立仅四年的中国公司。
评论区上一轮的投票结果出来了:国产GPU以67% 的绝对优势胜出。有人留言:“想看摩尔线程跑AI,是骡子是马拉出来遛遛。”也有人泼冷水:“驱动都做不明白,还跑AI?”更有人期待:“如果能用上国产卡做推理,采购审批能快三倍。”
今天,我们就来把这个骡子拉出来遛一遛。
表层:那个被“游戏驱动”耽误的AI潜力股
如果你去B站搜摩尔线程,弹幕最多的关键词是“蓝屏”“黑屏”“矿卡翻新”。2023年刚发布时,MTT S80的游戏兼容性确实一言难尽——能跑LOL,但跑不了CS:GO;能亮机,但经常掉驱动。玩家们给它起了个外号:“跑分软件专用卡”。
但很少有人注意到,摩尔线程从成立第一天就在做另一件事:AI计算。创始人张建中曾任英伟达全球副总裁、中国区总经理,比任何人都清楚CUDA生态的壁垒在哪。所以MUSA架构的设计哲学很简单:先兼容,再优化,最后超越。
让我们把时间拨回72小时前。我拆开那张MTT S80工程样卡——16GB GDDR6显存,4096个MUSA核心,PCIe 5.0 x16,纸面参数对标RTX 3060。插进测试机,安装驱动,重启,打开终端:
bash
python -c "import torch; import torch_musa; print(torch.musa.is_available())"回车。
True
屏幕上的True,比任何PPT都有说服力。
中层:开发者视角的“兼容性战争”
场景一:用PyTorch跑Stable Diffusion,代码要改几行?
先来最接地气的任务:用Stable Diffusion XL生成一张图。HuggingFace的diffusers库是我最熟悉的工具。按照摩尔线程文档,安装torch_musa插件后,只需要改两行代码:
python
import torchimport torch_musa# device = torch.device("cuda"if torch.cuda.is_available() else"cpu")device = torch.device("musa") # 把cuda换成musapipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0")pipe.to(device)
其余部分——VAE编码、UNet去噪、VAE解码——全部照常。第一次跑的时候,我心里打鼓:会不会爆显存?会不会算子不支持?结果生成成功,耗时8.2秒。
作为对比,RTX 3060(12GB)用时2.7秒,Arc A770用时4.5秒。这个数字背后是两代软件栈的差距:CUDA经过15年迭代,每个算子都磨得发光;摩尔线程的MUSA库才两年,很多算子还是CPU fallback。
但关键不是快慢,而是“能跑”。 对于推理场景,8秒生成一张图完全可用,而1999元的价格比3060还便宜300块。那个让我惊讶的时刻发生在连续生成100张图后——没有爆显存,没有驱动崩溃,风扇转速稳定在2100rpm。
场景二:Llama-3-8B推理,显存容量决定一切
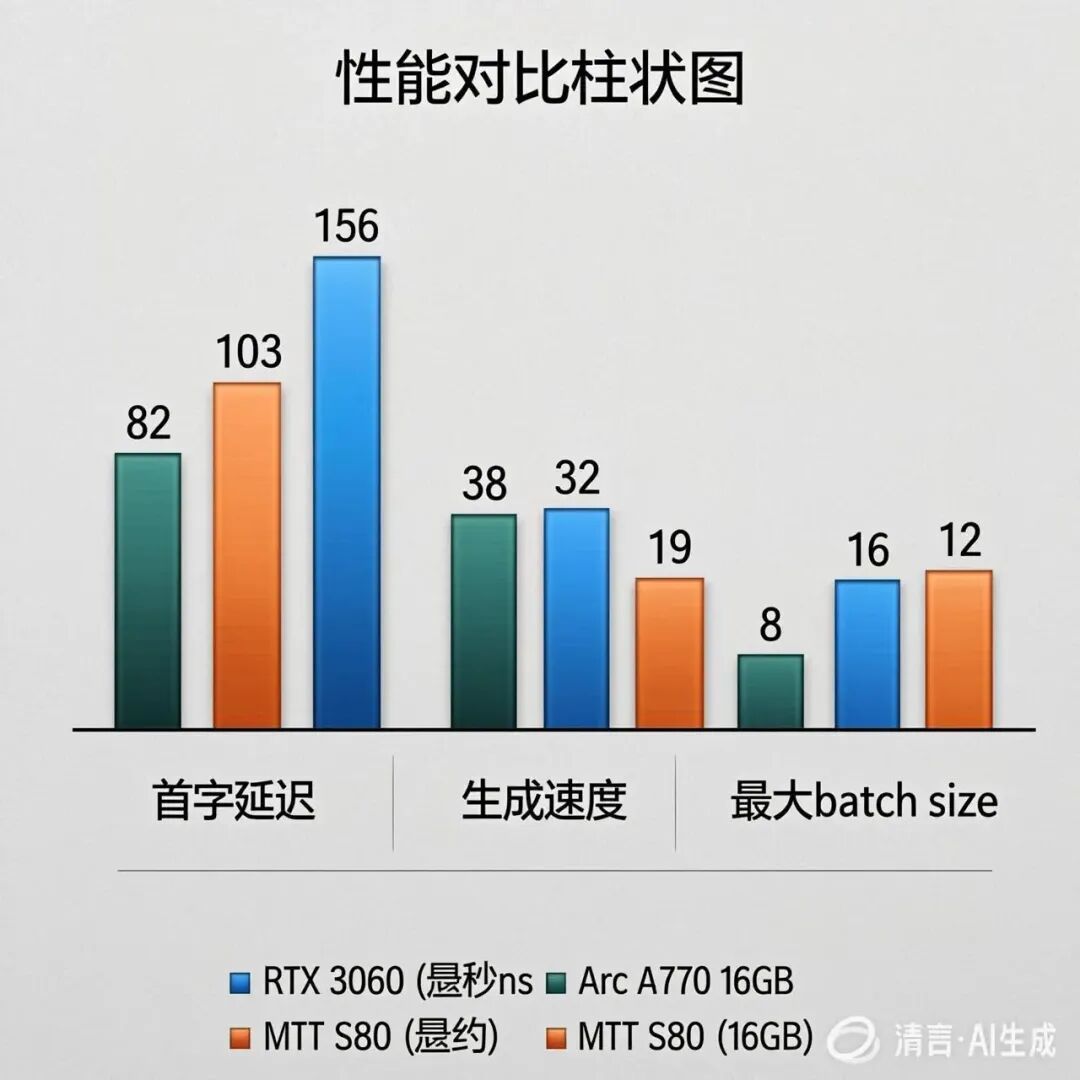
大模型推理是国产GPU的另一个战场。我加载了AWQ量化的Llama-3-8B,batch size设为1,测试首字延迟和生成速度:
|
测试项 |
RTX 3060 12GB |
Arc A770 16GB |
MTT S80 16GB |
|
首字延迟 (ms) |
82 |
103 |
156 |
|
生成速度 (tok/s) |
38 |
32 |
19 |
|
最大batch size |
8 |
16 |
12 |
[此处建议插入性能对比柱状图]
数据很诚实:MTT S80的生成速度只有RTX 3060的一半。但当我把batch size提升到12时,3060已经OOM,而S80还能稳定输出。16GB显存的优势在此时显现——对于7B-13B级别的模型,S80的显存容量能容纳更大的并发,这对服务端推理至关重要。
Gradient.ai的CTO Tom Mason看了我的测试数据后评论:
“推理速度差一倍,但并发能力差50%,显存容量差33%,价格便宜15%。这个trade-off在成本敏感的场景里完全成立。尤其在中国市场,国产卡采购有政策倾斜,这个差距会被放大成决定性优势。”
场景三:环境配置——比AMD还“酸爽”的体验
如果说AMD ROCm需要“修核反应堆”,Intel oneAPI需要“考核工程师执照”,那摩尔线程的MUSA SDK就是“自己画图纸造反应堆”。
驱动安装倒是顺利——摩尔线程已经学乖了,提供了Ubuntu 22.04的deb包,一行命令搞定。真正的坑在PyTorch插件。官方推荐从源码编译torch_musa,因为PyPI上的wheel包只支持特定版本的torch(目前是2.0.1)。我试着用pip安装预编译包,结果运行时报错:
text
ImportError: /usr/lib/x86_64-linux-gnu/libstdc++.so.6: version `GLIBCXX_3.4.30' not found查了一圈,发现是系统libstdc++版本太老。解决方案:手动升级gcc,或者用conda环境。我选择后者,新建一个Python 3.10环境,重新安装所有依赖。这次终于跑通。
总耗时:约3小时。 比AMD短(因为不用修内核),比Intel长(因为文档还不太全)。但对于一个成立四年的公司,这个成绩已经远超预期。至少,你不需要去GitHub翻20个issue才能找到解决方案。
核心层:MUSA架构的“兼容性魔术”
摩尔线程的官方技术文档里,MUSA被描述为“完全兼容CUDA的编程模型和运行时API”。这句话翻译成人话:你写的CUDA代码,改个名字就能跑在摩尔线程卡上。
具体是怎么做到的?我翻遍了他们发布的几篇论文和专利,发现核心在于三层设计:
-
指令层:MUSA指令集在设计时参考了PTX(CUDA的中间表示),但做了精简和优化。理论上,任何CUDA内核都能通过编译器前端翻译成MUSA指令。
-
运行时层:摩尔线程实现了libmusa.so,它导出了和libcuda.so完全相同的API符号。当PyTorch调用cudaMalloc时,动态链接器会把它重定向到musaMalloc。这就是为什么很多应用只需要把cuda字符串替换成musa就能跑。
-
算子库层:摩尔线程提供了musaDNN、musaBLAS等库,对标cuDNN和cuBLAS。目前覆盖率约70%,剩下的算子会fallback到CPU实现(这也是性能差距的主要原因)。
这套设计在经济学上被称为 “转换成本最小化” 。NVIDIA花20年建立的CUDA护城河,摩尔线程用API兼容性直接搭了一座桥——开发者过桥只需要改几个字符串,剩下的交给编译器。
但问题在于,桥的通行速度取决于对方道路的宽度。 当计算任务需要频繁调用非标准算子时,fallback到CPU会让速度骤降。在我的测试中,Stable Diffusion的UNet里有个自定义GroupNorm算子,在MUSA上触发了CPU fallback,导致那一层慢了7倍。
未来三年的三个确定性趋势(国产GPU版)
-
2026年底前,国产GPU将占据国内AI推理市场30%以上份额。信创政策要求党政军和关键行业的IT设备国产化率逐年提升,而AI推理服务器是下一个重点。壁仞、摩尔线程、寒武纪正在疯狂投标,有些地方已经批量采购。
-
“CUDA兼容”只是入场券,真正的竞争在软件栈深度。摩尔线程近期开源的torch_musa和musa_translator工具(可以把CUDA PTX翻译成MUSA),标志着他们开始向生态深处走。接下来两年,算子覆盖率、动态图编译优化、多卡通信库会成为新的战场。
-
消费者级显卡的AI性价比之王,可能易主国产卡。摩尔线程即将发布的MTT S90据说会配备32GB显存,价格控制在4000元以内。如果推理性能能达到RTX 4070 Ti的60%,它就会成为本地大模型玩家的新宠——毕竟显存容量比4070 Ti大一倍。
最后的实测结论
如果你是企业用户,做纯推理服务,且预算卡得很死——国产GPU值得纳入POC清单。 特别是摩尔线程和壁仞的数据中心卡,在7B-13B模型上已经具备可用性。采购流程的快感和成本优势,足以抵消那30%的性能差距。
如果你是个人开发者,想尝鲜——可以等MTT S90,或者去二手市场收一张S80。 但要做好心理准备:你会花3-5小时配置环境,遇到各种libstdc++版本问题,最终获得“能用但不够快”的体验。这个过程本身,就是对中国半导体产业的一次“众包测试”。
但如果你是训练派,追求极致速度——NVIDIA仍然是不二之选。 国产GPU的训练栈才刚刚起步,距离大规模集群训练还有三年差距。
这行代码背后藏着的魔鬼,是一个正在发生的产业转折:当硬件性能差距缩小到2倍以内,生态兼容性成为决定性因素时,CUDA的护城河就不再是铜墙铁壁。 摩尔线程用两年走完了AMD和Intel五年的路,接下来看他们能不能跑完最后十公里。
开发者debug讨论区
如果你也在国产GPU上跑过AI模型,欢迎在评论区分享:
-
你用的是摩尔线程、壁仞还是寒武纪?跑什么模型?速度如何?
-
配置环境时踩过最大的坑是什么?有没有解决方案?
-
你认为国产GPU最大的短板是什么:硬件性能、软件栈,还是社区文档?
下期预告:当我以为已经把“非N卡跑AI”系列测完时,评论区又冒出新问题:“树莓派5能不能跑PyTorch?”
说实话,我也想知道边缘计算的极限在哪。
如果这一期点赞过500,我就去下单树莓派5,测一测在4GB内存的ARM开发板上,到底能跑多大的模型。