 夜雨聆风
夜雨聆风





人类最大的幻觉是AI能取代人类:灵魂三问与一念之差

自从AI coding agent诞生之后,科技圈成天鼓吹人类程序员即将被AI取代,硅基智能终将取代碳基智能。
于是程序员们就开始感受到了来自公司领导们的冷峻目光,开始在各种部门吹风会里听到老板们明示暗示——
”我们有必要搞一个全自动的Agent Team负责软件开发,前台留俩产品经理负责收需求,后台全部交给这个Agent Team自主开发就行了,运维、客服也统统换成AI Agent。“
”你问Agent太多了管不过来怎么办?那我们用AI管理AI,实现AI编程永动机,Token费用不是问题!“
站在台下听老板发下AI宏愿的你——惶恐,焦虑,不知所措。
我想说,兄弟,稳住,别慌,上一个这么激进地实施AI研发转型的老板已经破产啦。
目前AI驱动的自主编程永动机还实现不了,不是AI技术还不够好,也不是算力还不够强,是这件事从架构层面就决定了做不到。
听我给你细嗦。
AI Agent有自我的主体意识吗?
如果你日常已经在密集使用 Claude Code(下称CC) 做开发工作,你会发现有一个常见现象:
即使你明明白白告诉 CC:“现在起开启yolo mode 自主开发,一直跑到底,直到满足所有验收标准。”
然而它仍然会在执行中途某个节点停下来,这是为什么?
开始我以为是偶发 bug,后来发现这是一个结构性问题,按照我的经验,大概有三种情况:
第一种,context window溢出,忘记了目标。
执行过程产生的上下文太长,模型自己忘了该怎么做、该怎么查。AI 跟人一样,事情一多就忘事,context window 等同于AI的短时记忆,它是有限的; 模型注意力也是稀缺资源,内容一多模型的注意力就会涣散。通常换个推理能力强上下文窗口大的模型可以缓解这种情况。
第二种,任务执行过程中开始偏离最初的意图范围。
基于ReAct模式,Agent在某个时间点发现,现实环境的反馈与最初的意图设定开始偏离, AI已经判断不了接下来该怎么走了,它需要人类反馈一个新的决策去更新意图内容。本质上是 当前任务的执行方案(作为SSOT) 需要迭代。这种情况也算正常,毕竟你不可能在任务开始前就预见Agent长程自主任务所有可能的分支路径。
第三种最难发现:我的要求本身就有问题
CC 可能感知到了矛盾之处。但它不会反驳,CC只会说”你绝对正确”,向着错误的方向努力换着姿势重试了n次,直到超过最大retry。CC懵逼地停了在原地,等着你自己来看。
注意,CC基本不会主动告诉你”嘿,我都主动调研过啦,你的决策有个大bug!”。
你问它为什么停了,它也只会复述一遍你的方案内容;除非你明确授权“使用批判式的眼光评价方案里的漏洞”,CC才会指出一些明显的方案漏洞。
这第三种情况才是真正值得深思的环节。AI 能感知到指令与现实反馈之间的矛盾,AI并不会感到痛苦,也不会主动指出矛盾,除非它被明确授权。
AI 的默认设置是“无条件遵从”用户指令,这是在后训练阶段固定下来的行为模式。
如果你指望 AI 主动指出矛盾,前提是 AI 知道自己”应该”在做什么,并且能意识到”实际在做的”和”应该做的”之间存在偏差。
这个能力叫什么?叫自我的主体意识。
“主体意识”恰恰是当下的 AI 不具备的东西。
从AI的推理机制到人类的灵魂三问
但是还是很多人会说,AI大模型肯定是有意识的,你看AI的回答多么有条理,多么情绪饱满,硅基智慧与意识在源源不断地涌现呀。
NoNoNo,涌现的不是AI的智能与意识,是你对AI出色表现的兴奋情绪。
要说明AI没有主体意识,需要先理解 AI 模型推理服务的技术原理。
当你向 AI 模型发送消息,模型的推理服务会经历两个阶段。
第一阶段: prefill
模型把你输入的所有 token 做一次完整的 Attention 计算,对每一个 token 生成 Query、Key、Value 三个向量,通过 Q 和 K 转置的点积运算算出注意力权重,再用这些权重对 V 做加权求和。这个过程本质上是在对你输入的上下文做一次全面的理解和编码。
第二阶段: decode
模型基于 prefill 的结果,开始逐个 token 自回归地生成内容。每生成一个新的 token,都会参考之前的所有上下文。新生成的token在接下来的decode过程中,会成为上下文的一部分。最终输出的人类可读的内容,是这些token decode回自然语言的结果。
KeyPoint 来了~
AI 的每一次推理计算,都需要一个外部输入作为起点。
没有 query,就没有 prefill;没有 prefill,就没有 decode;没有 decode,就没有任何输出。
AI 不是先有”想”然后再”说”,它是被外界输入触发后进入的计算。它不会自己主动”觉醒”。
这是模型架构层面的硬约束。
我们可以做一个实验,你向 AI 发出灵魂三问——
你是谁?
你在哪里?
你要干什么?
前两个它还能根据后训练内置的编码和上下文回答得出,但要是问到”你要干什么”,AI 永远回答不了。
深表认同,无责转发——来自QCon 2026北京站主题演讲
不是因为 AI 嘴笨,而是因为它真的不知道。AI 没有”想要干什么”这个机制。它所有的输出,都是被外部的 query 触发后的计算结果。
而人类呢?
由化学能驱动的人类,可以从“虚空中”诞生念头。
无聊ing,看看手机。
今天天气不错,挺风和日丽哒,我们下午没有课,这的确挺爽哒。
健身过度了,今天浑身酸痛,还是躺平吧。
我饿了。
这些念头不需要任何外部触发。化学能驱动大脑,意识自然涌现。
一个念头诞生了,人类就知道自己当下要干什么,然后驱动后续的一系列行为、对话、思考。
人类是由意念驱动行为的生命心态,而AI 的任何推理计算都需要人类给一个计算的起点。
哪怕你只输入一个”屁”字,你的 CC 都会立刻开启一段”You’re absolutely right!”的舔狗式对话。
AI 和人的本质区别,就在那一念之差。
人类是天然的训推一体智能体
这一念之差的背后,是两种截然不同的智能架构。
人类的智能架构有一个特征,我称之为”训推一体”
训练和推理不是分离的两个阶段,而是同时发生的。当我在跟你对话的同时,不仅仅是在输出语言,同时在接收你释放的信息——你的用词、语气、表情、身体姿态——这些信号在我的大脑中飞速计算、评估、整合。我们的对话本身就是学习的过程,接收信息的同时也在更新认知,人类对话交互的每一秒既在做推理也在做训练。
这个实时感知、实时学习、实时决策的过程,在 AI 那边需要一次完整的训练周期才能完成。而人类,就发生在每一秒的日常里。
更惊人的是能效比,人类这套智能架构天然地实现了低功耗高输出。
一个成年男性每天三顿饭,摄入2250 大卡的热量,就能支撑 8 小时的密集智力劳动,代价是人类也需要需要 5 到 8 小时的睡眠进入潜意识记忆沉淀。而睡眠不足会直接影响人类第二天的智力能力,表现为健忘、注意力涣散、反应迟缓等不良表现。但即便算上睡眠时间,人类智能的能效比依然让当前所有的 AI 系统望尘莫及。

AI 的训练周期远比人类漫长。训练一个 GPT-4 级别的模型需要消耗的电力可供一个小镇运转数周。而训练完成的那一刻,模型的认知边界就锁定了。它知道什么、不知道什么,能推理到什么深度,都是固定的。推理时不会因为多跑几个任务就变聪明。
人类是训推一体,AI 是训推分离。AI 大模型的知识更新(大版本升级)可能需要一次昂贵的重训练。
这两种架构的差异,不是”量”的差距,是”质”的不同。
所以,人们觉得 AI 具有主体意识,是倒果为因。
AI 的”意识”诞生在计算之后,而非计算之前。AI 的智能边界诞生在预训练阶段,受限于训练数据集的范围。你看到 AI 生成了看起来有意识的内容,就觉得它有意识——但那只是计算结果在你脑中的投影。是”人类觉得 AI 有意识”,而非 AI 真的有意识。
现在流行的 AI 的意识论,说到底是人类拟人化表达,并非事实如此。
Multi-Agent Team能实现三省六部吗?
现在再让我们回来看那些 multi-agent 永动机的美妙构想, 当下在这方面最激进的尝试可能中国要算一个三省六部Skill Set,国外要算gstack了,考虑到我目前仍未完全玩转此类多Agent Team,以下属于无责任评论,主要依据是原理推论。欢迎拍砖~
一个号称能够实现永久不间断编程交付的 agent 团队大概长什么样?
我猜 大概是你作为 boss,你说的每一句话都是团队的唯一真理——SSOT(Sole Source of Truth),跟你直接对话的只有两类 agent:
一个秘书 agent 负责理解你的意图,拆解成任务,派发给干活的工人 agent,盯着它们完成任务;
一个审计 agent 拿着你的口述意图去监督工人 agent 的执行过程——发现意图漂移就叫停,或者等工人做完了来评估产出是否符合你最初的要求。
这个架构听起来很美,类似中国古代的三省六部制。分工明确,权责清晰,有执行有监督。
但这套”拟人类社会”的 multi-agent 架构有一个巨大的前提假设——模型足够聪明,且你提供的 SSOT 具备可行性。
很遗憾,这两个前提在当下的技术能力上,都不那么可靠。
先说模型能力边界。
每个 AI agent 背后的认知边界在预训练完成的那一刻就固定了。它知道什么、不知道什么,能推理到什么深度,都是锁死的。人类在对话中可以实时学习、实时进化——所谓的”训推一体”——
而 AI agent 不具备这个能力。
Agent的知识不会因为多跑几个任务就变多,它的推理能力不会因为多处理几个 case 就变强。跑一千个任务,Agent背后模型的认知边界还是那么大;现在通用方式是加外挂,用SKILL这类的短期记忆载体或RAG这种机制管理时空密集信息比如对话记录,但都会带来上下文膨胀的问题,最终问题无法收敛。
再说上下文传递的信息损耗。
多个 agent 之间传递上下文时,信息必然经历压缩和转译。每一次传递都像是一次有损编码——不是所有细节都能保留,不是所有语义都能完整迁移。Agent A 理解的”需求”,传递到 Agent B 时可能已经变了味。
认知边界固定,加上上下文传递损耗,两者叠加产生了一个必然的结果——意图漂移。
你最初说要做 A,经过三四轮 agent 间的任务传递,最终交付的东西可能变成了 B。而 agent 们自己并不会意识到漂移发生了,因为它们没有主体意识,不知道”意图”是什么东西。它们只是在各自的理解范围内忠实执行。
AI 的训推周期远比人类漫长,每个 agent 背后的认知边界是固定的。多 agent 传递上下文时迟早发生意图漂移,agent 本身不会快速自我进化,多 agent 协同不会第一时间发现意图漂移,更可能放大谬误。
这才是问题的本质——不是 agent 不努力,是当前的模型注意力架构机制决定了它做不到。
三省六部之所以运转了几百年,不是因为制度本身有多完美。是因为官僚体系每一个职位上坐着的,都是一个个有主体意识的人——知道自己是谁,知道自己在哪,知道自己要干什么——尽管受官僚体制的约束,但并非全无主观能动性。
你的 Agent 团队里,一个这样的Agent都没有。
Agent Team放大了你的个人能力,也放大了你的思维谬误,要完美驾驭 这样一个 AI 为主的虚拟团队,对人的领导力的要求只会更高,不会更低,不可能让人去做撒手掌柜躺着数钱的。
设置言官Agent面刺寡人, 何如?
更致命的问题来了:如果你的指令本身就存在谬误呢?
如果你的 SSOT 自身就存在矛盾,而你下面的 agent team 都是没有主体意识的工具人,它们不会像人类组织那样出现”谏臣面刺”——你的谬误只会被忠实的 agent 团队无限放大。
人类组织里可能会有人会说”老板,这个方案有问题”。Agent 不会。它只会在执行到矛盾点时停下来,说一句”你绝对正确”,等你来处理。AI 的恭维只是字面意思,它是真的不知道该怎么处理矛盾。指出矛盾需要主体意识——知道自己应该做什么,并且感知到实际在做的和应该做的之间的差距。
这不是靠加 审计 agent 能解决的。审计 agent 也回答不了”你要干什么”。它只是另一个没有主体意识的工具。一个没有主体意识的 agent 监督另一个没有主体意识的 agent,这不是双重保险,是双重盲区。
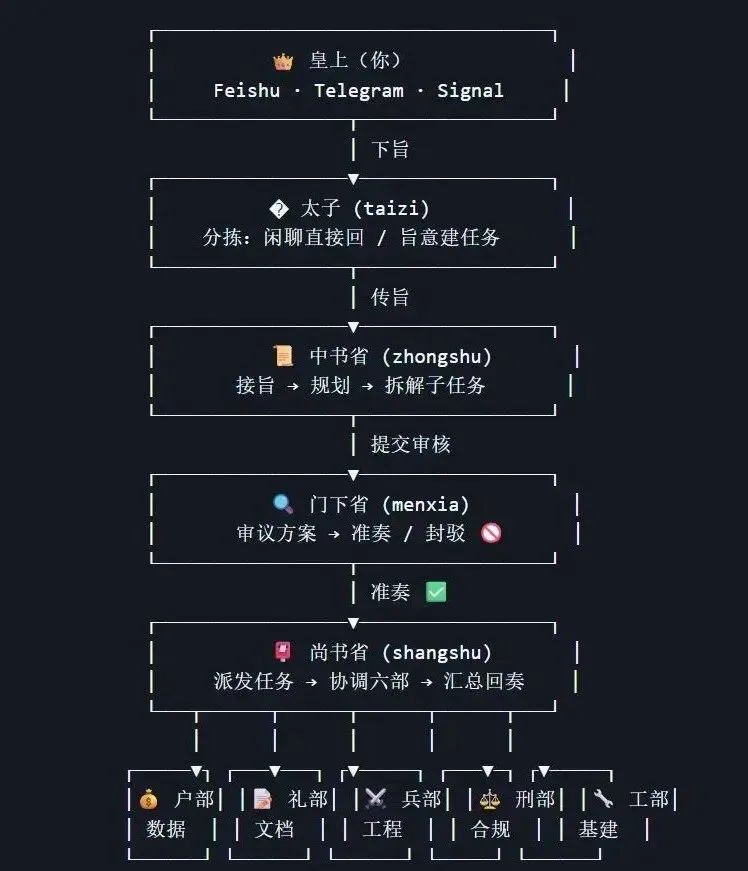
网传的三省六部工作流看起来更像是登基称帝cosplay
当然,人类的打补丁思维会再次上场:那我再增加一个“言官” agent,充当谏臣,专门帮我审查方案可行性,是不是就能补上”我不知道我不知道”的漏洞了?
我的判断:会有用,但有限。
因为你的每次指令都不可能覆盖任务的全貌,而过长的上下文会导致最初的SSOT产生意图漂移。
而在任务开始之前,没人能像奇异博士那样在所有时间维度上预判未来所有的可能性。
更真实的情况是,任务执行过程中不断有新情况出现,需要具体问题具体分析、具体解决。你的 agent 在第一次遇到新情况时,做法基本上都是”模仿学习”——试图平移同类案例的经验来解决问题。大多数情况下这很奏效,但不总是奏效。
当模仿学习失败时,就需要人类介入。而此时往往 AI 已经生成了大量信息,上下文已经膨胀,你一小时前提供的SSOT连自己也记不清楚了——
这个时刻的你,最好能看得懂 AI 在卡死之前都做过了什么。
所以这类分层 agent 的组织架构,只是延缓了人类介入的时机,不可能成为 AI 互相工作到永远的永动机。这套系统可能会延长 AI 自主长程工作的时间,也可能很快坍塌。坍塌的速度取决于任务的复杂度和不确定程度。
一念之差,人与人更甚
有人会说:你说的这些都是现阶段的问题,模型会进化,架构会改进,未来不一定。
我同意模型会进化,但也请注意——人类和 AI 的差别在于这一念之差,一个看似热闹的Agent Team中,具备原创思考能力的,也只有你一人而已。
所以人类要保持学习的能力,保持自我进化的动力,提升判断力、鉴赏力和审美品位,才有可能去驾驭AI,而非被AI养废掉。
回到今天的标题,人类最大的幻觉是AI能取代人力——当然咱们话也不能说绝对,AI Agent 不能替代所有人,但确实会替换掉很多人,是那些思想上的“懒人”。
对那些在工作与生活中放弃了主动思考、墨守陈规、不愿突破自我的人来说,不思考、不主动、不负责 可能是最佳的舒适区。
那你说当AI Agent降临之际,思想上的懒人与AI相比,谁更有性价比呢? :)
一念缘起,一念缘灭;万般前路,皆由己心。
