 夜雨聆风
夜雨聆风





打造 AI 智能体专属的代码知识库:GitNexus 完整上手攻略
AI 编码工具发展到今天,已经不只是帮你补全几行代码了。像 Claude Code、Cursor、 Codex 这类工具,正在慢慢变成真正能参与开发流程的「搭档」。但在真实项目里,一个问题会越来越明显:AI 不是不会写代码,而是经常看不全代码。
它也许能看懂当前文件,却不知道一个函数还被哪些地方调用;它可能完成了一次重构,却漏掉了某个跨模块依赖;有时候甚至只是改了一个不起眼的返回值,最后却影响了后面整条业务流程。
GitNexus 想解决的,正是这个问题。它会先把代码库整理成一张「知识图谱」,提前分析依赖关系、调用链、功能聚类和执行流,再通过 MCP、CLI、Web UI 等方式交给 AI Agent 使用。
换句话说,GitNexus 做的不是让模型「更会猜」,而是让它在动手改代码之前,先真正理解你的代码库。
为什么需要代码知识库
AI 编码的真实瓶颈:不是不会写,而是看不全
在小项目里,AI Agent 只要读几个文件,就能大致判断代码应该怎么改。但项目一旦变大,真正难的就不是「写出一段代码」,而是知道这段代码和整个系统之间的关系。
比如,一个 UserService.validate() 看起来只是普通校验函数,但它可能被几十个接口、任务队列、测试用例、权限逻辑间接依赖。Agent 如果只看到当前文件,很容易做出局部正确、全局错误的修改。
代码库越复杂,AI 越需要的不是更多提示词,而是一套稳定的代码上下文。
这也是为什么 GitNexus 这类工具开始变得重要。它不是替代模型,而是给模型补上「理解项目」这一层基础设施。
GitNexus 是什么:AI Agent 的代码神经系统
GitNexus 官方对自己的定位很直接:
Building nervous system for agent context.
翻译成中文,可以理解为:为 AI Agent 构建代码上下文的神经系统。
它会把任意代码库索引成一张知识图谱,把依赖关系、调用链、功能聚类、执行流这些信息提前整理出来。这样 Agent 需要理解某个函数、模块或业务流程时,不必只靠关键词搜索和临时猜测。
普通代码搜索关心的是「这段文本出现在哪里」。
GitNexus 更关心的是:这个符号属于哪个模块?谁调用了它?它会影响哪些流程?它和哪些代码天然相关?
这就是它和传统代码搜索最大的不同。
普通搜索、通用 RAG 与 GitNexus 的区别
很多人会问:既然已经有全文搜索、向量检索、RAG,为什么还需要 GitNexus?
关键在于,代码不是普通文本。代码之间有明确结构,有调用关系,有依赖边界,也有执行路径。只把代码切成片段再检索,很容易漏掉那些「没有出现在同一个文本块里,但逻辑上强相关」的内容。
可以简单理解成下面这个区别:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
GitNexus 的核心思路,可以概括为一个词:预计算关系智能。
也就是先在索引阶段把代码结构、依赖关系、调用链、功能聚类、执行流都计算好。等 Agent 真正执行任务时,它拿到的不是一堆零散片段,而是一份经过结构化整理的项目上下文。
GitNexus 核心能力
技术原理
GitNexus 之所以能提供这些结构化上下文,是因为它的索引流程不是简单扫文件。
它大致会经历几个阶段:
-
1. Structure:扫描文件树和目录关系; -
2. Parsing:用 Tree-sitter 解析函数、类、方法、接口等符号; -
3. Resolution:解析 import、函数调用、继承、构造器和self、this等关系; -
4. Clustering:把相关符号聚成社区; -
5. Processes:从入口点追踪执行流; -
6. Search:构建混合搜索索引。
也就是说,它不是等 Agent 提问时才临时拼上下文,而是在索引阶段就把一部分关系计算好了。
这也是「预计算关系智能」的核心价值:让 Agent 查询时拿到的不是散落片段,而是更接近项目结构本身的上下文。
支持范围
-
• 14 种编程语言:TypeScript、JavaScript、Python、Java、Kotlin、C#、Go、Rust、PHP、Ruby、Swift、C、C++、Dart -
• 16 个 MCP 工具:查询、影响分析、上下文视图、变更检测、重命名、Cypher 查询等 -
• 4 个 Agent Skills:代码探索、调试追踪、影响分析、重构规划 -
• 完全本地运行:代码不离开你的机器
MCP 工具一览
接入 MCP 后,GitNexus 会向 AI Agent 暴露一组工具。
这里不需要把它们理解成普通命令,而应该理解成 Agent 的「项目理解接口」。
单仓库工具(11 个):
|
|
|
|---|---|
list_repos |
|
query |
|
context |
|
impact |
|
detect_changes |
|
rename |
|
cypher |
|
多仓库 / 仓库组工具(5 个):
|
|
|
|---|---|
group_list |
|
group_sync |
|
group_contracts |
|
group_query |
|
group_status |
|
这些工具背后的意义是:Agent 不再只是「读文件然后猜」。
它可以先查询相关模块,再查看符号上下文,然后分析影响范围,最后再决定怎么改代码。
这会让 AI 编码从「局部生成」更接近「带项目理解的协作开发」。
两种使用方式
GitNexus 提供两种使用方式,适配不同场景:
|
|
CLI + MCP | Web UI |
|---|---|---|
| 适合场景 |
|
|
| 规模支持 |
|
|
| 安装方式 | npm install -g gitnexus |
|
| 存储方式 |
|
|
| 隐私保障 |
|
|
Bridge 模式: 运行
gitnexus serve后,Web UI 会自动检测本地服务器,可以直接浏览所有 CLI 已索引的仓库,无需重新上传或重新索引。
快速上手指南
第一步:用 npx gitnexus analyze 索引代码库
GitNexus 推荐的使用方式,是先在本地项目里建立索引。
进入你的项目根目录,执行:
npx gitnexus analyze这个命令会完成一组初始化动作:索引代码库、安装 agent skills、注册 Claude Code hooks,并创建 AGENTS.md 或 CLAUDE.md 这类上下文文件。
你可以把它理解为:先让 GitNexus 扫一遍项目,把代码库从「文件集合」整理成「关系网络」。
后续无论是 AI Agent 查询代码,还是你通过 Web UI 查看图谱,都会基于这份索引来工作。
如果代码发生了较大变化,也可以重新运行分析命令。需要强制全量重建时,可以使用:
gitnexus analyze --force运行 gitnexus analyze 后,以下 Skills 会自动安装到 .claude/skills/:
-
• Exploring——使用知识图谱导航陌生代码 -
• Debugging——通过调用链追踪 Bug -
• Impact Analysis——变更前分析影响半径 -
• Refactoring——利用依赖映射规划安全重构
如果运行 gitnexus analyze --skills,GitNexus 还会通过 Leiden 社区检测算法识别你代码库的功能模块,为每个模块生成专属的 SKILL.md 文件,放在 .claude/skills/generated/ 下。每个 Skill 描述该模块的关键文件、入口点、执行流和跨模块连接——让 AI 在处理特定模块时获得精准的上下文。
第二步:用 npx gitnexus setup 配置 MCP
索引完成后,下一步就是让 AI 编码工具能用上这份知识图谱。
GitNexus 通过 MCP 暴露能力。你只需要执行一次:
npx gitnexus setup它会自动检测你的编辑器,并写入对应的全局 MCP 配置。
MCP 的作用可以理解为:给 AI Agent 增加一组可调用工具。以前 Agent 只能靠读文件、搜索文本来理解项目;接入 GitNexus 后,它就可以主动查询代码图谱、分析影响范围、获取符号上下文。
这一步非常关键。
没有 MCP,GitNexus 更像是一个代码分析工具;接入 MCP 后,它才真正变成 Agent 的代码知识库。
第三步:接入 Claude Code、Cursor、Codex 等 AI 编码工具
GitNexus 支持多种 AI 编码工具,包括 Claude Code、Cursor、Codex、Windsurf、OpenCode 等。
其中 Claude Code 的集成最完整,支持:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Claude Code 的优势在于,它不仅能通过 MCP 调用 GitNexus 工具,还可以结合 Skills 和 Hooks。
比如,PreToolUse hooks 可以在搜索前补充图谱上下文;PostToolUse hooks 可以在提交后检测索引是否过期,并提醒 Agent 重新索引。
这类机制的价值不在于「自动化炫技」,而在于让 Agent 的工作流更稳定:搜索前先补上下文,修改后再检查索引状态。
第四步:启动 Web UI 浏览代码图谱
除了 CLI + MCP,GitNexus 还提供 Web UI。
如果你想用可视化方式浏览代码图谱,可以运行:
npx gitnexus@latest serve然后通过 Web UI 查看本地已经索引的仓库。Web UI 适合快速探索项目结构、做架构梳理,或者在接手陌生代码库时先建立整体印象。
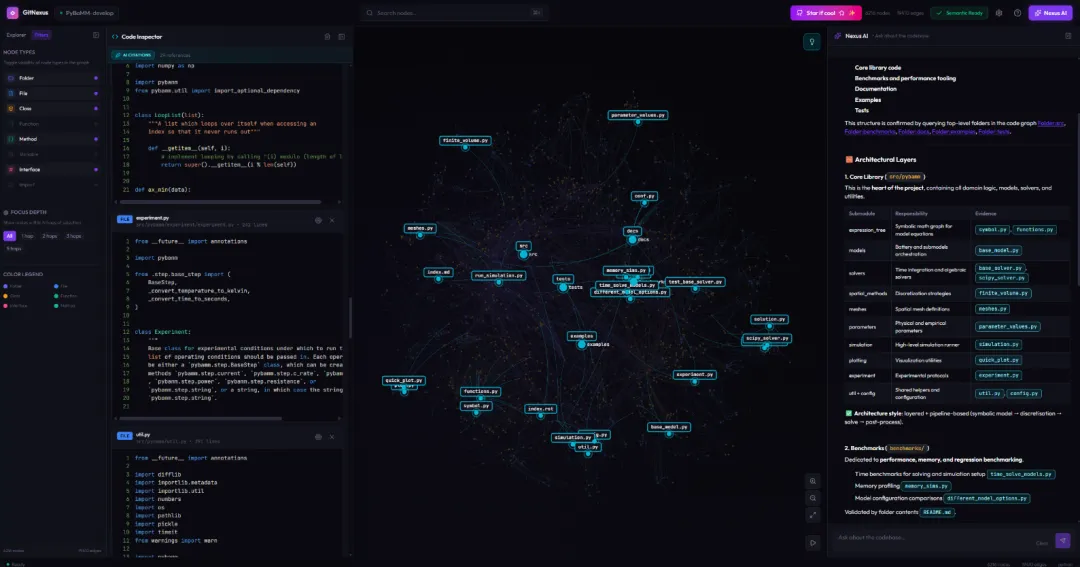
相比纯命令行,图谱视图更适合人类开发者观察模块关系。你可以把它当成一张项目地图:哪些文件聚在一起,哪些模块互相依赖,哪些执行流跨越多个目录,都能更直观地看到。
如果只是快速体验,也可以直接访问:
https://gitnexus.vercel.app
Web UI 主要适合快速探索、演示和一次性分析。对于更大的仓库,官方建议配合 backend mode,也就是通过本地 gitnexus serve 连接 CLI 已索引的仓库。
高级技巧:用 gitnexus wiki 生成项目 Wiki
GitNexus 还有一个很实用的能力:基于代码知识图谱生成项目 Wiki。
命令很简单:
gitnexus wiki这类 Wiki 的价值,不只是给团队多一份文档。
更重要的是,它可以把代码库里的模块、功能区域和结构关系整理出来,让新人、维护者,甚至 AI Agent 都能更快理解项目。
对于长期演进的项目来说,文档很容易过期。但如果 Wiki 能基于代码图谱生成,它就更接近一份「随代码而变化」的项目知识库。
实战应用场景
场景一:改动前先看影响范围
这是 GitNexus 最核心的使用场景。真正改代码之前,先确认一句:“这个改动会影响到哪里?”
impact({target: "UserService", direction: "upstream", minConfidence: 0.8})TARGET: Class UserService (src/services/user.ts)UPSTREAM (what depends on this): Depth 1 (WILL BREAK): handleLogin [CALLS 90%] -> src/api/auth.ts:45 handleRegister [CALLS 90%] -> src/api/auth.ts:78 UserController [CALLS 85%] -> src/controllers/user.ts:12 Depth 2 (LIKELY AFFECTED): authRouter [IMPORTS] -> src/routes/auth.tsminConfidence 用来控制置信度阈值,maxDepth 控制追踪深度,relationTypes 则可以过滤关系类型,比如只看 CALLS、IMPORTS、EXTENDS。
提交代码前,还可以再跑一次 detect_changes 做预检:
detect_changes({scope: "all"})summary: changed_count: 12 affected_count: 3 changed_files: 4 risk_level: mediumchanged_symbols: [validateUser, AuthService, ...]affected_processes: [LoginFlow, RegistrationFlow, ...]风险等级会直接告诉你这次改动「危险不危险」,哪些执行流受影响也能一眼看清。
场景二:顺着调用链追 Bug
线上出了问题,却不知道该从哪里查?可以直接用 context 查看某个函数的完整上下文:
context({name: "validateUser"})symbol: uid: "Function:validateUser" kind: Function filePath: src/auth/validate.ts startLine: 15incoming: calls: [handleLogin, handleRegister, UserController] imports: [authRouter]outgoing: calls: [checkPassword, createSession]processes: - name: LoginFlow (step 2/7) - name: RegistrationFlow (step 3/5)谁调用了它、它又调用了谁、参与了哪些执行流、处在哪一步,都会一次性返回。调试时不用再靠全局搜索一个个翻文件。
场景三:安全重命名,不留死角
重命名最怕的就是漏引用。rename 会同时结合图谱关系和文本搜索做双重检查:
rename({symbol_name: "validateUser", new_name: "verifyUser", dry_run: true})status: successfiles_affected: 5total_edits: 8graph_edits: 6text_search_edits: 2changes: [...]dry_run: true 可以先预览。
其中 graph_edits 是高置信度替换,而 text_search_edits 表示图谱无法完全确认,需要人工重点检查。
场景四:用自然语言搜代码
忘了某个功能写在哪?直接搜索:
query({query: "authentication middleware"})processes: - summary: "LoginFlow" priority: 0.042 symbol_count: 4 process_type: cross_community step_count: 7process_symbols: - name: validateUser type: Function filePath: src/auth/validate.ts process_id: proc_login step_index: 2definitions: - name: AuthConfig type: Interface filePath: src/types/auth.ts它不是简单返回文件列表,而是结合 BM25、向量搜索和 RRF 排序,把结果按执行流组织起来。
场景五:Web UI 可视化探索
面对陌生代码库时,有时候更需要全局视角。
可以直接访问 gitnexus.vercel.app,或者本地运行:
# 启动本地后端npx gitnexus@latest serve# Web UI 会自动连接本地服务Web UI 提供基于 Sigma.js + WebGL 的交互式图谱视图,可以直接在浏览器里和 AI 对话,探索整个代码结构。
整个过程里,代码都不会离开本地机器。
场景六:多仓库 / 微服务架构
如果项目是微服务架构,多个仓库之间有 API 契约依赖,GitNexus 的仓库组功能会很有用:
gitnexus group create my-servicesgitnexus group add my-services hr/hiring/backend backend-servicegitnexus group add my-services hr/hiring/frontend frontend-servicegitnexus group sync my-servicesgitnexus group query my-services "user authentication flow"一个 MCP 服务,就能同时管理所有已索引仓库,不需要每个项目单独配置。
场景七:直接查底层图谱
如果你熟悉图数据库,还可以直接用 cypher 查询代码图谱:
MATCH (c:Community {heuristicLabel: 'Authentication'})<-[:CodeRelation {type: 'MEMBER_OF'}]-(fn)MATCH (caller)-[r:CodeRelation {type: 'CALLS'}]->(fn)WHERE r.confidence > 0.8RETURN caller.name, fn.name, r.confidenceORDER BY r.confidence DESC这时候,GitNexus 更像是一个可查询的「代码知识库」,而不只是搜索工具。
常用技巧与最佳实践
接手陌生项目,先理解模块和执行流
接手陌生项目时,最难的不是打开代码,而是知道从哪里开始看。
传统做法通常是:先读 README,再全局搜索关键词,然后顺着入口文件一路追调用。但这种方式很依赖经验,也容易被项目结构绕晕。
GitNexus 的优势,是它已经提前做了功能聚类和执行流分析。
你可以先通过 Web UI 看整体图谱,再让 Agent 使用 query 或 context 查询某个功能相关的代码。比如你想理解认证模块,不必先猜文件名,而是可以让 Agent 从图谱里找相关符号、流程和依赖。
这对新人有用,对 AI Agent 更有用。
因为 Agent 最怕的不是工作量大,而是从一开始就拿错上下文。
重构核心函数前,先做影响面分析
重构最怕什么?
不是改不动,而是你以为只改了一处,实际上影响了一片。
比如你准备调整一个核心服务的返回结构,表面上只是改了一个函数签名,但下游可能有接口、任务、测试、权限逻辑都依赖它。
这时,GitNexus 的 impact 就很适合放在动手之前使用。
它可以帮助 Agent 分析某个目标的上游依赖、下游影响和相关流程。改完之后,再通过 detect_changes 查看当前 diff 影响了哪些符号和流程。
如果还涉及重命名,可以结合 rename 做跨文件协同处理。
当然,GitNexus 不能替代测试,也不能替代代码审查。但它能帮你在测试之前先回答一个关键问题:这次修改最可能影响哪里?
与 Claude Code 的 Skills、Hooks 组成 Agent 工作流
如果你正在使用 Claude Code,GitNexus 的价值会更明显。
因为它不仅可以通过 MCP 提供工具,还能结合 Skills 和 Hooks,把「理解项目」这件事嵌进 Agent 工作流里。
比如,Agent 在搜索代码之前,可以先借助图谱上下文缩小范围;在提交或较大修改之后,可以检查索引是否过期;在处理重构任务时,可以先调用影响分析,再开始改代码。
这意味着 GitNexus 不是一个独立的「查询面板」,而是可以变成 Agent 行动前后的上下文层。
你可以把它理解成一种工作习惯:先问项目,再改代码。
对复杂项目来说,这个顺序非常重要。
安全与隐私:代码会不会上传?
很多团队在使用 AI 编码工具时,最关心的问题之一就是:代码会不会离开本机?
GitNexus 在这点上做得比较克制。
CLI 模式下,它在本地运行,索引存储在项目的 .gitnexus/ 中,全局 registry 只保存路径和元数据。也就是说,日常开发时,它更适合处理私有代码库和本地仓库分析。
Web UI 模式下,官方资料也强调是在浏览器内运行,不上传代码。API key 存在 localStorage 中,代码分析主要发生在本地或浏览器环境里。
当然,这不等于可以忽略团队自己的安全规范。
但至少从设计取向上看,GitNexus 更像是一个本地优先的代码知识库,而不是把你的仓库上传到远端再分析的服务。
进阶技巧:企业版、多仓库与 Docker 部署
如果只是在个人项目或团队内部试用,CLI + MCP + Web UI 已经足够覆盖大多数场景。
但 GitNexus 也提供一些更偏企业级的能力,比如 PR Review、自动更新 Code Wiki、Auto-reindexing、多仓库支持等。
对于微服务或 monorepo 场景,它还提供 repository group 相关能力,可以跨仓库搜索执行流、同步合约关系、检查仓库组状态。
部署方面,资料中也提到可以通过 Docker 启动 backend 和 Web UI。对普通上手读者来说,这部分不需要一开始就展开。
建议路径是:先在一个真实项目里跑通 analyze 和 MCP,再考虑多仓库、自动化 Wiki 和企业部署。
总结
过去我们讨论 AI 编码,经常把重点放在模型能力上:哪个模型更强,哪个工具补全更快,哪个 Agent 更会改代码。
但随着项目规模变大,真正决定体验的,往往是另一件事:Agent 到底能不能拿到正确、完整、结构化的上下文。
GitNexus 的意义就在这里。
它把代码库从一堆文件,变成一张面向 AI Agent 的代码知识图谱;再通过 MCP、CLI、Web UI,把这张图谱接入真实开发流程。
如果你已经在用 Claude Code、Cursor 或 Codex,不妨找一个中等规模的项目试一试 GitNexus。
先让 Agent 理解项目,再让 Agent 修改代码。
这可能会是 AI 编程从「能写」走向「写得稳」的关键一步。
GitHub 地址:https://github.com/abhigyanpatwari/GitNexus
引用链接
[1] gitnexus.vercel.app: https://gitnexus.vercel.app
既然看到这里了,如果觉得有启发,随手点个赞、推荐、转发三连吧,你的支持是我持续分享干货的动力。
GitHub 地