 夜雨聆风
夜雨聆风





深入Redis线程模型:从源码拆解为什么它能单线程扛住百万QPS?

你有没有过这样的疑惑:Redis明明对外宣称是单线程模型,为什么却能轻松扛住百万级别的并发请求?为什么它的性能远超很多采用多线程架构的中间件?本文将从Redis官方源码层面,一步步拆解线程模型的核心原理,帮你彻底搞懂这个高性能缓存的底层运行逻辑。
一、先打破认知误区:Redis真的是单线程?
很多初学者听到Redis单线程模型的时候,第一反应是“单线程怎么可能处理高并发?”,其实这里的“单线程”指的是Redis的网络IO和键值对读写操作是由一个主线程完成的,而并非所有任务都在单线程中执行。实际上Redis的后台任务,比如RDB/AOF持久化、大key异步删除、过期键清理等,都是由单独的后台线程或子进程来处理的。
我们可以从Redis的源码入口来验证这一点,Redis的主函数在src/server.c中,启动后会进入主事件循环,而这个循环的执行者就是主线程:
// src/server.c Redis主函数简化版
int main(int argc, char **argv) {
// 初始化服务器配置、网络连接等
initServer(argc, argv);
// 进入主事件循环
aeMain(server.el);
// 清理资源
aeDeleteEventLoop(server.el);
return 0;
}
这里的aeMain函数来自src/ae.c,也就是Redis的事件驱动核心模块,我们稍后会详细拆解这个函数的逻辑。
二、核心基石:IO多路复用与事件循环
Redis能实现高并发的核心之一,就是采用了IO多路复用技术,配合单线程的事件循环,实现了同时处理成千上万个客户端连接而不需要创建大量线程。Redis抽象了一套统一的事件处理层aeEventLoop,可以兼容epoll、kqueue、select等多种IO多路复用实现,在Linux系统下默认使用epoll。
2.1 事件循环的核心流程
我们先来看Redis事件循环的核心函数aeProcessEvents,这是主线程处理所有事件的入口:
// src/ae.c 事件处理核心函数
int aeProcessEvents(aeEventLoop *eventLoop, int flags) {
int processed = 0, numevents;
// 调用IO多路复用接口监听事件
numevents = aeApiPoll(eventLoop, tvp);
// 处理触发的文件事件
for (int j = 0; j < numevents; j++) {
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
int rfired = 0;
// 处理读事件
if (fe->mask & mask & AE_READABLE) {
rfired = 1;
fe->fileProc(eventLoop, fd, fe->clientData, mask);
}
// 处理写事件
if (fe->mask & mask & AE_WRITABLE) {
if (!rfired || fe->fileProc != fe->fileProc) {
fe->fileProc(eventLoop, fd, fe->clientData, mask);
}
}
processed++;
}
// 处理定时事件
processTimeEvents(eventLoop);
return processed;
}
这段代码的逻辑非常清晰:
1. 调用aeApiPoll(不同系统下的IO多路复用实现,比如epoll_wait)监听客户端的事件
2. 遍历触发的事件,分别处理读事件(接收客户端请求、读取命令)和写事件(返回结果给客户端)
3. 处理定时任务,比如过期键扫描、定时持久化等
2.2 客户端连接的处理流程
当有新的客户端连接到Redis时,主线程会触发AE_READABLE事件,调用acceptTcpHandler函数来接受连接:
// src/networking.c 接受客户端连接
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[NET_IP_STR_LEN];
while(max--) {
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
serverLog(LL_WARNING, "Accepting client connection: %s", server.neterr);
return;
}
// 创建客户端对象,绑定事件处理函数
createClient(cfd, 0);
}
}
createClient函数会为新的客户端创建一个client结构体,并为其绑定readQueryFromClient函数,用来读取客户端发送的命令:
// src/networking.c 创建客户端
client *createClient(int fd) {
client *c = zmalloc(sizeof(client));
// 设置非阻塞
anetNonBlock(NULL, fd);
anetEnableTcpNoDelay(NULL, fd);
// 绑定读事件处理函数
aeCreateFileEvent(server.el, fd, AE_READABLE, readQueryFromClient, c);
// 初始化客户端其他属性
c->fd = fd;
c->querybuf = sdsempty();
return c;
}
三、命令执行:单线程的快乐与烦恼
当客户端的命令被读取到主线程的缓冲区后,就会进入命令执行阶段,这也是Redis单线程模型的核心部分。我们来看processCommand函数,这是处理客户端命令的核心逻辑:
// src/server.c 处理客户端命令
int processCommand(client *c) {
// 命令参数校验
if (!c->argc || !c->argv[0]) return C_ERR;
// 查找命令对应的处理函数
struct redisCommand *cmd = lookupCommand(c->argv[0]->ptr);
if (!cmd) {
addReplyError(c, "unknown command '%s'", c->argv[0]->ptr);
return C_OK;
}
// 命令权限校验、参数校验
if (checkCommandPermissions(c, cmd) != C_OK) return C_ERR;
// 执行命令
if (cmd->flags & CMD_BLOCKING) {
// 处理阻塞命令,比如BLPOP、BRPOP
handleBlockingCommand(c);
} else {
// 非阻塞命令,直接调用处理函数
cmd->proc(c);
}
// 更新命令统计信息
server.stat_numcommands++;
return C_OK;
}
这里的关键在于,所有的键值对读写操作都是在主线程中串行执行的,这意味着Redis不需要处理多线程环境下的锁竞争、内存屏障等问题,大大简化了代码的复杂度,同时避免了因锁竞争带来的性能损耗。这也是Redis为什么能这么快的核心原因之一。
比如我们常见的SET、GET命令,它们的处理函数分别是setCommand和getCommand,都是在主线程中直接执行的,整个过程没有任何锁操作。
四、幕后帮手:Redis的后台线程与子进程
刚才我们提到,Redis的主线程只处理网络IO和命令执行,而其他耗时的任务都会被转移到后台线程或者子进程中处理,这样就不会阻塞主线程的事件循环。常见的后台任务包括:
1. RDB持久化
2. AOF日志重写
3. 大key异步删除(UNLINK命令)
4. 过期键定期清理
5. 异步关闭客户端连接
我们以UNLINK命令为例,来看一下Redis的异步删除是如何实现的:
// src/db.c 异步删除命令实现
void unlinkCommand(client *c) {
int64_t deleted = 0;
for (int j = 1; j < c->argc; j++) {
// 尝试异步删除key
if (dbAsyncDelete(c->db, c->argv[j]->ptr)) {
deleted++;
}
}
addReplyLongLong(c, deleted);
}
int dbAsyncDelete(redisDb *db, robj *key) {
// 从数据库中移除key
if (dictDelete(db->dict, key->ptr) == DICT_OK) {
// 如果开启了后台线程,将key的销毁任务加入队列
if (server.threaded_libc && server.io_threads_num > 0) {
bioCreateBackgroundJob(REDIS_BIO_JOB_UNLINK, key, NULL, NULL);
return 1;
} else {
// 没有后台线程,直接销毁
freeDbKey(key);
return 1;
}
}
return 0;
}
当调用UNLINK命令时,Redis并不会立即销毁key对应的内存,而是将销毁任务加入到后台线程的任务队列中,由后台线程来完成实际的内存释放操作,这样就不会阻塞主线程的命令处理流程。
五、完整流程:一张图看懂Redis线程模型
现在我们可以用一张UML流程图来完整展示Redis线程模型的运行流程:
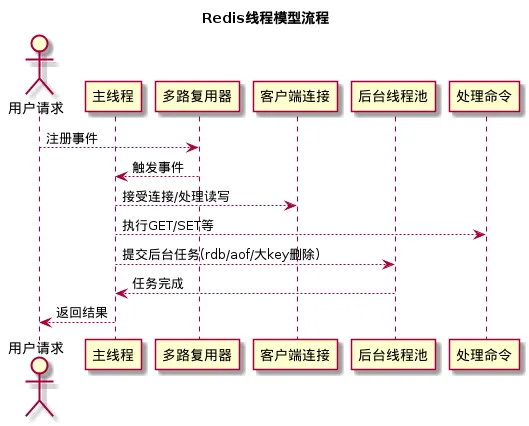
这张图清晰地展示了整个流程:
1. 客户端的连接请求首先被注册到多路复用器中
2. 多路复用器监听到事件后通知主线程
3. 主线程接受客户端连接,读取客户端发送的命令
4. 主线程执行命令,如果是耗时任务则提交到后台线程池
5. 后台线程完成任务后通知主线程
6. 主线程将执行结果返回给客户端
六、为什么单线程模型比多线程更快?
很多读者可能会有疑问:既然多线程可以充分利用多核CPU的资源,为什么Redis的单线程模型反而更快?其实主要有以下几个原因:
1. 避免了线程上下文切换的开销:多线程环境下,CPU需要在不同的线程之间切换,每次切换都需要保存和恢复寄存器、栈等上下文信息,这会带来不小的性能损耗。而Redis的单线程模型不需要频繁的上下文切换。
2. 避免了锁竞争的开销:多线程环境下,为了保证共享资源的线程安全,需要使用各种锁机制,比如互斥锁、读写锁等,这些锁会带来额外的性能损耗,甚至可能出现死锁、活锁等问题。而Redis的单线程模型不需要任何锁机制,所有操作都是串行执行的。
3. 更高效的缓存利用率:单线程模型下,CPU的缓存命中率更高,因为不需要在不同的线程之间共享缓存数据,避免了缓存失效的问题。
当然,Redis的单线程模型也有其局限性,比如无法充分利用多核CPU的资源,所以在Redis 6.0版本之后,官方引入了多线程模型来处理网络IO操作,但是键值对的读写操作仍然是单线程的。
七、写在最后
Redis的线程模型看似简单,实则暗藏玄机,它通过单线程+IO多路复用的组合,在保证代码简洁性的同时,实现了超高的并发性能。希望通过本文的源码拆解,你能对Redis的底层运行逻辑有更深入的理解。
好了,今天的Redis线程模型源码拆解就到这里啦,不知道你有没有彻底搞懂Redis为什么这么快?如果你还有其他关于Redis的疑惑,或者想让我拆解其他技术源码,欢迎在评论区留言交流!点赞收藏不迷路,我们下期再见~