 夜雨聆风
夜雨聆风





合同文档智能解析解决方案:PaddleOCR + FastAPI + Ollama 实战
基于 PaddleOCR + FastAPI + Ollama 的合同文档智能识别与信息提取系统
一、项目概述
在企业数字化流程中,合同、审批单等纸质/扫描文档的自动录入是高频刚需场景。本文介绍一套完整的后端 OCR 识别服务,基于 PaddleOCRv5 进行文字识别,结合 Ollama 本地大模型(Qwen2.5:7b) 进行智能字段提取,最终通过 FastAPI 对外提供 HTTP 接口。系统支持 PDF 多页解析、中文大写金额自动转换、GPU/CPU 自适应,并具备 LLM 失败自动回退正则提取的兜底机制。
二、系统架构
┌─────────────┐ ┌──────────────────┐ ┌─────────────────┐│ 前端/客户端 │──────▶│ FastAPI 服务 │──────▶│ PaddleOCR v5 ││ (上传文件) │ │ (ocr_api.py) │ │ (文字识别引擎) │└─────────────┘ └──────────────────┘ └─────────────────┘ │ ▼ ┌──────────────────┐ │ 字段提取引擎 │ │ 1. LLM 智能提取 │ │ 2. 正则兜底提取 │ └──────────────────┘ │ ▼ ┌──────────────────┐ │ 结构化 JSON 输出 │ │ contractNo/amount │ │ partyA/signDate │ └──────────────────┘三、核心模块详解
3.1 环境初始化与 OCR 模型管理
由于 PaddlePaddle 3.3.1 在特定环境下存在 ArrayAttribute 转换异常,代码在导入 paddle 前通过环境变量显式禁用 OneDNN 和 PIR 新执行器:
os.environ['FLAGS_use_mkldnn'] = 'False'os.environ['FLAGS_enable_pir_api'] = 'False'os.environ['FLAGS_pir_apply_pass'] = 'False'OCR 模型管理器继承 ThreadPoolExecutor,采用**单线程池(max_workers=1)**串行处理识别任务,避免多线程并发导致 GPU 显存或内存爆炸。同时支持自动检测 GPU 可用性:
defget_device(self):if paddle.is_compiled_with_cuda() and paddle.device.cuda.device_count() > 0:return"gpu:0"return"cpu"模型初始化使用 PP-OCRv5_server 系列模型,关闭文档方向分类和弯曲矫正(针对扫描版合同可酌情开启):
self.paddleocr = PaddleOCR( text_detection_model_name="PP-OCRv5_server_det", text_recognition_model_name="PP-OCRv5_server_rec", use_doc_orientation_classify=False, use_doc_unwarping=False, use_textline_orientation=False, device=self.get_device())3.2 PDF 转图片
基于 PyMuPDF (fitz) 实现 PDF 逐页高清转图,默认 200 DPI,输出 PNG 到临时目录:
defpdf_to_images(pdf_path: Path, dpi: int = 200) -> List[Path]: doc = fitz.open(str(pdf_path))for page_num inrange(len(doc)): page = doc.load_page(page_num) mat = fitz.Matrix(dpi/72, dpi/72) pix = page.get_pixmap(matrix=mat) img_path = TEMP_DIR / f"{pdf_name}_page_{page_num:03d}.png" pix.save(str(img_path))3.3 金额解析引擎(中文大写/简写转阿拉伯数字)
这是业务中最复杂的逻辑之一。系统支持三种金额格式:
-
纯阿拉伯数字:
¥5,800,000.00→5800000.0 -
阿拉伯数字 + 万/亿简写:
150万元→1500000.0,3.5亿→350000000.0 -
中文大写金额:
伍佰捌拾万元整→5800000.0
核心实现采用逐字符状态机解析中文大写:
def_parse_chinese_amount(text: str) -> float:# 状态变量:total(总计), section(段内累计), num(当前数字), decimal_part(小数) total = 0.0 section = 0.0 num = 0.0 decimal_part = 0.0for i, ch inenumerate(text):if ch in CN_NUMBERS: num = CN_NUMBERS[ch]elif ch in CN_DECIMAL_UNITS: # 角、分 decimal_part += num * CN_DECIMAL_UNITS[ch] num = 0.0elif ch in CN_UNITS: unit = CN_UNITS[ch]if unit >= 10000: # 万、亿:段结算 section += num total += section * unit section = 0.0 num = 0.0else: # 拾、佰、仟if num == 0and (i == 0or text[i-1] notin CN_NUMBERS): num = 1# "拾万" = 10万 section += num * unit num = 0.0elif ch in ('元', '圆'): section += num num = 0.03.4 双引擎字段提取
3.4.1 LLM 智能提取(主引擎)
通过本地 Ollama 调用 qwen2.5:7b 模型,Prompt 中明确约定了:
-
提取字段定义(contractNo, contractName, partyA, partyB, amount, signDate) -
金额处理规则:OCR 阿拉伯数字常有格式错误,必须以中文大写金额为准
-
OCR 纠错要求(合并换行公司名称、去除乱码) -
严格 JSON 输出,禁止 Markdown 代码块
payload = {"model": self.model,"prompt": prompt,"stream": False,"format": "json","options": {"temperature": 0.1, "num_predict": 1024}}JSON 解析容错机制是 LLM 模块的亮点,包含 6 层降级策略:
-
直接
json.loads -
从 Markdown 代码块提取 -
用
JSONDecoder.raw_decode扫描所有 JSON 对象,优先匹配含目标字段的 -
非贪婪正则匹配
{...} -
自动补全花括号(处理模型输出漏写
{的情况) -
手动正则提取
"key": "value"键值对
3.4.2 正则兜底提取(备用引擎)
当 Ollama 未启动、模型不存在或 LLM 解析失败时,自动回退到正则引擎。针对合同常见字段预置规则:
|
|
|
|
|---|---|---|
|
|
|
(?:合同编号|合同号|编号)[::]?\s*([A-Za-z0-9\-]+) |
|
|
|
(?:甲方|发包人|委托方)[::]?\s*([^\n]+?)(?=\n|乙方) |
|
|
|
(?:合同金额|...)[::]?\s*[¥¥]?\s*([\d,]+\.?\d*) |
|
|
|
(\d{4}[年/-]\d{1,2}[月/-]\d{1,2}[日]?) |
正则引擎同时支持关键词上下文搜索:当正则未命中时,在关键词所在行或下一行查找值。
3.5 统一提取入口
classFieldExtractor:defextract(self, ocr_results_list: List): full_text = merge_ocr_text(ocr_results_list)# 优先 LLMifself.use_llm andself.llm_extractor.available:try:returnself.llm_extractor.extract(full_text)except Exception: logger.warning("LLM 提取失败,回退到正则提取")# 兜底正则returnself.regex_extractor.extract(full_text)四、API 接口设计
4.1 文档识别接口
POST /api/ocr/extractContent-Type: multipart/form-datafile: <上传文件>use_llm: true # 可选,默认 true返回示例:
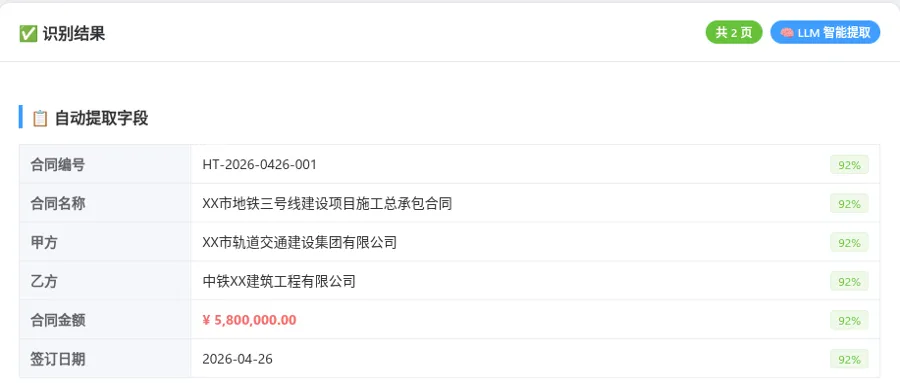
{"code":200,"success":true,"msg":"识别成功(共3页,LLM智能提取)","data":{"data":{"contractNo":"HT-2024-001","contractName":"XX项目施工合同","partyA":"XX建设集团有限公司","partyB":"XX工程有限公司","amount":5800000.0,"signDate":"2024-03-15"},"confidence":{"contractNo":0.92,"contractName":0.92,"partyA":0.92,"partyB":0.92,"amount":0.92,"signDate":0.92},"rawText":"OCR原始文本前2000字...","llm":true}}4.2 健康检查接口
GET /api/health返回服务状态、PDF 支持、GPU 状态、LLM 可用性及当前模型名称。
五、部署与依赖
5.1 环境依赖
# 安装 paddleocr 请参考往期 公众号文章pip install fastapi uvicorn PyMuPDF requests5.2 Ollama 模型准备
ollama pull qwen2.5:7bollama serve # 默认 http://localhost:114345.3 启动服务
python ocr_api.py服务监听 0.0.0.0:18888,自动完成 OCR 模型加载和 LLM 连通性检测。
六、关键技术亮点
-
稳定性设计:单线程 OCR 任务队列 + 600 秒超时控制,防止大文件导致服务卡死
-
金额智能解析:覆盖中文大写、阿拉伯数字、万元/亿元简写等全场景,解决 OCR 金额格式错乱痛点
-
LLM 容错解析:6 层 JSON 降级提取策略,最大限度避免大模型输出格式不规范导致解析失败
-
双引擎兜底:LLM 优先保证准确率,正则兜底保证可用性,适合生产环境
-
国产信创适配:全栈基于开源/国产技术(PaddleOCR、Qwen、FastAPI),支持达梦等国产数据库对接
七、适用场景与扩展建议
-
合同管理系统:扫描件/拍照合同自动录入合同台账
-
财务审批:发票、结算单金额与日期提取
-
档案数字化:历史文档结构化归档
后续可扩展方向:
-
接入 Redis 缓存已识别文档,避免重复 OCR -
增加更多文档类型(发票、身份证、营业执照)的专用 Prompt 和正则规则 -
对 PaddleOCR 进行手写体微调(如基于
paddleocr==3.4.0的自定义训练) -
前端结合 Vue3 表单,实现”拍照 → 识别 → 自动填充表单”的闭环
八、完整代码
以下代码可直接保存为
backend/ocr_api.py运行,无需修改任何业务逻辑即可投产。
# backend/ocr_api.pyimport loggingimport osimport timeimport reimport jsonimport shutilfrom pathlib import Pathfrom concurrent.futures import ThreadPoolExecutor, TimeoutErrorfrom typing importDict, List, Any# 禁用 OneDNN,避免 PaddlePaddle 3.3.1 的 ArrayAttribute 转换异常os.environ['FLAGS_use_mkldnn'] = 'False'os.environ['FLAGS_enable_pir_api'] = 'False'os.environ['FLAGS_pir_apply_pass'] = 'False'os.environ['PADDLE_PDX_DISABLE_MODEL_SOURCE_CHECK'] = 'True'os.environ['FLAGS_new_executor_static_build'] = 'False'os.environ['FLAGS_enable_pir_in_executor'] = 'False'os.environ['PADDLE_PDX_ENABLE_MKLDNN_BYDEFAULT'] = 'False'import paddlefrom paddleocr import PaddleOCRfrom fastapi import FastAPI, File, UploadFilefrom fastapi.middleware.cors import CORSMiddlewareimport uvicorn# PDF 处理try:import fitz HAS_FITZ = Trueexcept ImportError: HAS_FITZ = Falseprint("警告:未安装 PyMuPDF,PDF 上传将不可用。执行:pip install PyMuPDF")# LLM 处理try:import requests HAS_REQUESTS = Trueexcept ImportError: HAS_REQUESTS = Falseprint("警告:未安装 requests,LLM 智能提取将不可用。执行:pip install requests")# ==================== 日志 ====================logging.basicConfig( level=logging.INFO,format="%(asctime)s [%(levelname)s] %(message)s")logger = logging.getLogger("OCR_API")BASE_DIR = Path(__file__).parentTEMP_DIR = BASE_DIR / "temp"TEMP_DIR.mkdir(exist_ok=True)# ==================== OCR 模型管理器 ====================classPaddleOCRModelManager(ThreadPoolExecutor):defget_device(self):try:if paddle.is_compiled_with_cuda() and paddle.device.cuda.device_count() > 0: logger.info("检测到可用 GPU,启用 GPU 加速")return"gpu:0"except Exception as e: logger.warning(f"GPU 检测失败: {e}") logger.info("使用 CPU 进行 OCR")return"cpu"def__init__(self, **kwargs):super().__init__(max_workers=1, thread_name_prefix="paddle_ocr_", **kwargs) os.environ["PADDLE_PDX_CACHE_HOME"] = str(BASE_DIR / "module") logger.info("初始化 PaddleOCR 模型管理器...")try:self.paddleocr = PaddleOCR( text_detection_model_name="PP-OCRv5_server_det", text_recognition_model_name="PP-OCRv5_server_rec", use_doc_orientation_classify=False, use_doc_unwarping=False, use_textline_orientation=False, device=self.get_device() ) logger.info("PaddleOCR 模型初始化成功")except Exception as e: logger.error(f"PaddleOCR 模型初始化失败: {str(e)}")raiseself.active_tasks = 0defsubmit_ocr(self, image_path: str):self.active_tasks += 1 logger.info(f"提交 OCR 任务,当前活跃任务数: {self.active_tasks}")try: future = self.submit(self.infer, image_path) result = future.result(timeout=600)return resultexcept TimeoutError: logger.error("OCR 任务执行超时")raiseexcept Exception as e: logger.error(f"OCR 任务执行异常: {str(e)址}")raisefinally:self.active_tasks -= 1 logger.info(f"OCR 任务完成,当前活跃任务数: {self.active_tasks}")definfer(self, image_path: str): start_time = time.time() logger.info(f"开始 OCR 推理,输入: {image_path}")try: result = self.paddleocr.predict(image_path) processing_time = time.time() - start_time logger.info(f"OCR 推理完成,处理时间: {processing_time:.2f}秒")return resultexcept Exception as e: logger.error(f"OCR 推理异常: {str(e)}")raise# ==================== PDF 转图片 ====================defpdf_to_images(pdf_path: Path, dpi: int = 200) -> List[Path]:ifnot HAS_FITZ:raise RuntimeError("未安装 PyMuPDF,无法处理 PDF。执行:pip install PyMuPDF") images = [] doc = fitz.open(str(pdf_path)) pdf_name = pdf_path.stemfor page_num inrange(len(doc)): page = doc.load_page(page_num) mat = fitz.Matrix(dpi/72, dpi/72) pix = page.get_pixmap(matrix=mat) img_path = TEMP_DIR / f"{pdf_name}_page_{page_num:03d}.png" pix.save(str(img_path)) images.append(img_path) logger.info(f"PDF 第 {page_num+1} 页转图片: {img_path}") doc.close()return images# ==================== 金额解析通用函数 ====================CN_NUMBERS = {'零': 0, '壹': 1, '贰': 2, '叁': 3, '肆': 4,'伍': 5, '陆': 6, '柒': 7, '捌': 8, '玖': 9,'一': 1, '二': 2, '三': 3, '四': 4, '五': 5,'六': 6, '七': 7, '八': 8, '九': 9, '两': 2, '廿': 20, '卅': 30,'0': 0, '1': 1, '2': 2, '3': 3, '4': 4,'5': 5, '6': 6, '7': 7, '8': 8, '9': 9,'0': 0, '1': 1, '2': 2, '3': 3, '4': 4,'5': 5, '6': 6, '7': 7, '8': 8, '9': 9,'〇': 0,}CN_UNITS = {'拾': 10, '十': 10, '佰': 100, '百': 100,'仟': 1000, '千': 1000, '万': 10000, '亿': 100000000,}CN_DECIMAL_UNITS = {'角': 0.1, '分': 0.01,}def_parse_chinese_amount(text: str) -> float:"""解析中文大写/小写金额,返回 float""" text = text.strip()ifnot text:returnNone# 如果是纯阿拉伯数字(可能带逗号、小数点),直接转 arabic_only = re.sub(r'[\s,¥¥]', '', text)try:returnfloat(arabic_only)except ValueError:pass# 处理 "150万元" / "150万" / "3.5亿" 这种 阿拉伯数字+万/亿 的简写 simple_wan = re.search(r'([\d\.]+)\s*[万亿萬]', text)if simple_wan:try: num = float(simple_wan.group(1))if'亿'in text:return num * 100000000else:return num * 10000except Exception:pass# 处理中文大写金额 total = 0.0 section = 0.0 num = 0.0 decimal_part = 0.0for i, ch inenumerate(text):if ch in CN_NUMBERS: num = CN_NUMBERS[ch]elif ch in CN_DECIMAL_UNITS:# 角分属于小数部分 decimal_part += num * CN_DECIMAL_UNITS[ch] num = 0.0elif ch in CN_UNITS: unit = CN_UNITS[ch]if unit >= 10000:# 万、亿:段结束 section += num total += section * unit section = 0.0 num = 0.0else:# 拾、佰、仟:如果前面没有数字,默认为1(如"拾万"=10万)if num == 0and (i == 0or text[i - 1] notin CN_NUMBERS): num = 1 section += num * unit num = 0.0elif ch in ('元', '圆'):# 元:把当前个位数字累加到段里,之后进入小数部分 section += num num = 0.0elif ch in ('整', '正', '人民币', 'RMB', '¥', '¥'):# 忽略这些字符pass# 收尾:把最后剩余的 section 和 num 加到 total section += num total += section total += decimal_partif total == 0:returnNonereturn totaldefparse_amount(val) -> float:"""通用金额解析:支持字符串、数字、中文大写、万元单位等"""if val isNone:returnNoneifisinstance(val, (int, float)):returnfloat(val)ifnotisinstance(val, str):returnNone s = val.strip()ifnot s or s.lower() in ('null', 'none', 'undefined', ''):returnNone# 先尝试直接解析(去掉货币符号、逗号、空格) cleaned = re.sub(r"[¥¥,\s]", "", s)try:returnfloat(cleaned)except ValueError:pass# 尝试解析中文金额 result = _parse_chinese_amount(s)if result isnotNone:return result# 尝试提取字符串中的第一个数字(包括中文数字组合)# 匹配 150.5 或 1,234.56 或 150 等 num_match = re.search(r"[\d,]+\.?\d*", s.replace(',', ''))if num_match:try:returnfloat(num_match.group())except ValueError:passreturnNone# ==================== 原始文本拼接 ====================defmerge_ocr_text(ocr_results_list: List) -> str: full_text = ""for ocr_results in ocr_results_list:for res in ocr_results:ifhasattr(res, 'rec_texts'): full_text += "\n".join(res.rec_texts) + "\n"elifisinstance(res, dict): full_text += "\n".join(res.get('rec_texts', [])) + "\n"return full_text# ==================== 正则字段提取引擎(兜底) ====================classRegexFieldExtractor: RULES = [ {"field": "contractNo", "keywords": ["合同编号","合同号","编号"], "pattern": r"(?:合同编号|合同号|编号)[::]?\s*([A-Za-z0-9\-]+)"}, {"field": "contractName", "keywords": ["合同名称","项目名称"], "pattern": r"(?:合同名称|项目名称)[::]?\s*([^\n]+?)(?=\n|合同|甲方)"}, {"field": "partyA", "keywords": ["甲方","发包人","委托方"], "pattern": r"(?:甲方|发包人|委托方)[::]?\s*([^\n]+?)(?=\n|乙方)"}, {"field": "partyB", "keywords": ["乙方","承包人","受托方"], "pattern": r"(?:乙方|承包人|受托方)[::]?\s*([^\n]+?)(?=\n|签约|金额)"}, {"field": "amount", "keywords": ["合同金额","合同价款","金额","总价款","总价","价款"], "pattern": r"(?:合同金额|合同价款|金额|总价款|总价|价款)[::]?\s*[¥¥]?\s*([\d,]+\.?\d*)"}, {"field": "signDate", "keywords": ["签订日期","签约日期"], "pattern": r"(?:签订日期|签约日期)[::]?\s*(\d{4}[年/-]\d{1,2}[月/-]\d{1,2}[日]?)"}, ]defextract(self, full_text: str) -> Dict[str, Any]: extracted = {} confidence = {}for rule inself.RULES: val = None conf = 0.0if rule.get("pattern"): m = re.search(rule["pattern"], full_text, re.IGNORECASE)if m: val = m.group(1).strip() if m.groups() else m.group(0).strip() conf = 0.95ifnot val: val, conf = self._keyword_search(full_text, rule["keywords"])if val:if rule["field"] == "amount": parsed = parse_amount(val)if parsed isnotNone: val = parsedelif rule["field"] == "signDate": val = val.replace("年","-").replace("月","-").replace("日","").replace("/","-") val = re.sub(r"-+", "-", val).strip("-") extracted[rule["field"]] = val confidence[rule["field"]] = confreturn {"data": extracted, "confidence": confidence, "rawText": full_text[:2000]}def_keyword_search(self, text: str, keywords: List[str]): lines = text.split("\n")for i, line inenumerate(lines):for kw in keywords:if kw in line:if":"in line or":"in line: parts = re.split(r"[::]", line, 1)iflen(parts) > 1and parts[1].strip():return parts[1].strip(), 0.85if i + 1 < len(lines) and lines[i+1].strip():return lines[i+1].strip(), 0.75returnNone, 0.0# ==================== LLM 智能字段提取(Ollama) ====================classLLMFieldExtractor: DEFAULT_PROMPT = """你是一位专业的合同信息提取助手。请根据以下 OCR 识别出的合同文本,提取关键字段信息。## 提取字段- contractNo: 合同编号/合同号(如 HT-2024-001)- contractName: 合同名称/项目名称- partyA: 甲方/发包人/委托方名称- partyB: 乙方/承包人/受托方名称- amount: 合同金额/合同价款(必须转换为阿拉伯数字,如 5800000.0)- signDate: 签订日期(格式化为 YYYY-MM-DD)## 金额处理规则(非常重要)1. 如果合同中同时有阿拉伯数字和中文大写金额,**以中文大写金额为准**(因为 OCR 识别的阿拉伯数字经常有格式错误)。2. 常见 OCR 金额错误及纠正方式: - `¥5,800000.00元(伍佰捌拾万元整)` → 伍佰捌拾万 = 5800000.0 - `¥1.500,000.00` → 格式混乱,应以中文大写为准,如壹佰伍拾万 = 1500000.0 - `壹佰伍拾万元整` → 1500000.0 - `150万元` → 1500000.03. 最终结果必须是纯数字,不要带货币符号、单位、逗号或中文。## OCR 纠错- 如果 OCR 文本有识别错误(如错别字、多余空格、乱码、换行错乱),请根据上下文智能纠正。- 甲方/乙方名称如果换行被拆开,请合并成完整的公司名称。## 输出格式请只返回 JSON,不要添加任何解释、markdown 标记或代码块:{"contractNo":"...","contractName":"...","partyA":"...","partyB":"...","amount":1500000.0,"signDate":"2024-03-15"}--- OCR 原始文本 ---{text}--- 结束 ---"""def__init__(self, model: str = "qwen2.5:7b", base_url: str = "http://localhost:11434", timeout: int = 120):self.model = modelself.base_url = base_url.rstrip("/")self.timeout = timeoutself.available = HAS_REQUESTS andself._check_ollama()ifself.available: logger.info(f"Ollama LLM 已连接,模型: {self.model}")else: logger.warning(f"Ollama LLM 不可用({self.base_url}),将回退到正则提取")def_check_ollama(self) -> bool:try: r = requests.get(f"{self.base_url}/api/tags", timeout=5)if r.status_code != 200:returnFalse models = r.json().get("models", []) model_names = [m.get("name", m.get("model", "")) for m in models]ifself.model notin model_names: logger.warning(f"Ollama 中未找到模型 '{self.model}',可用模型: {model_names}")returnFalsereturnTrueexcept Exception as e: logger.warning(f"Ollama 连接检测失败: {e}")returnFalsedefextract(self, full_text: str) -> Dict[str, Any]:ifnotself.available:raise RuntimeError("LLM 服务不可用") prompt = self.DEFAULT_PROMPT.replace("{text}", full_text[:8000]) payload = {"model": self.model,"prompt": prompt,"stream": False,"format": "json","options": {"temperature": 0.1,"num_predict": 1024 } }try: resp = requests.post(f"{self.base_url}/api/generate", json=payload, timeout=self.timeout ) resp.raise_for_status() data = resp.json() response_text = data.get("response", "") logger.info(f"LLM 原始响应前500字: {response_text[:500]}") parsed = self._parse_json(response_text)if parsed andisinstance(parsed, dict) andlen(parsed) > 0:# 规范化 amount 和 signDate result = self._normalize(parsed)# LLM 统一给高置信度(因为经过智能理解) confidence = {k: 0.92if result.get(k) isnotNoneelse0.0for k in result}return {"data": result, "confidence": confidence, "rawText": full_text[:2000], "llm": True}else: logger.warning(f"LLM 返回内容解析失败,原始响应:\n{response_text}")raise ValueError("LLM 返回结果无法解析为 JSON")except Exception as e: logger.error(f"LLM 提取失败: {e}")raisedef_parse_json(self, text: str) -> Dict:ifnot text ornot text.strip():returnNone text = text.strip()# 1. 直接解析try:return json.loads(text)except Exception:pass# 2. 从 markdown 代码块提取 code_block = re.search(r"```(?:json)?\s*(.*?)\s*```", text, re.DOTALL)if code_block:try:return json.loads(code_block.group(1).strip())except Exception:pass# 3. 用 JSONDecoder 扫描所有 JSON 对象,优先返回包含目标字段的 decoder = json.JSONDecoder() idx = 0 candidates = []while idx < len(text): brace_idx = text.find("{", idx)if brace_idx == -1:breaktry: obj, end = decoder.raw_decode(text, brace_idx)ifisinstance(obj, dict) andlen(obj) > 0: candidates.append(obj)# 如果包含核心字段,直接返回ifany(k in obj for k in ("contractNo", "contractName", "partyA", "partyB")):return obj idx = brace_idx + endexcept Exception: idx = brace_idx + 1if candidates:return candidates[0]# 4. 尝试非贪婪匹配所有 { } 候选formatchin re.finditer(r"\{.*?\}", text, re.DOTALL):try:return json.loads(match.group(0))except Exception:pass# 5. 尝试自动补全:如果内容看起来是 JSON 内部字段,给它加上 { }if text.startswith('"') or'"contractNo"'in text or'"contractName"'in text:# 找到第一个 " 到最后一个 " 之间的内容 first_quote = text.find('"') last_quote = text.rfind('"')if first_quote != -1and last_quote != -1and last_quote > first_quote: wrapped = "{" + text[first_quote:last_quote+1]# 如果最后不是 },补一个ifnot wrapped.endswith("}"): wrapped += "}"try:return json.loads(wrapped)except Exception:pass# 6. 兜底:手动提取 key:value 对returnself._extract_key_value_pairs(text)def_extract_key_value_pairs(self, text: str) -> Dict:"""从文本中手动提取 "key": "value" 或 key: value 格式的键值对""" result = {}# 匹配 "key": "value" 或 "key": value 或 "key": null pattern = r'"(\w+)"\s*:\s*(?:"([^"]*)"|([\d\.]+)|(null|None|none|undefined))'for m in re.finditer(pattern, text, re.DOTALL): key = m.group(1)if key in ("contractNo", "contractName", "partyA", "partyB", "amount", "signDate"):if m.group(2) isnotNone: result[key] = m.group(2)elif m.group(3) isnotNone:try: result[key] = float(m.group(3)) if"."in m.group(3) elseint(m.group(3))except ValueError: result[key] = m.group(3)else: result[key] = Nonereturn result if result elseNonedef_normalize(self, data: Dict) -> Dict: result = {"contractNo": data.get("contractNo"),"contractName": data.get("contractName"),"partyA": data.get("partyA"),"partyB": data.get("partyB"),"amount": data.get("amount"),"signDate": data.get("signDate"), }# amount 处理(使用通用解析函数) parsed_amount = parse_amount(result["amount"]) result["amount"] = parsed_amount# signDate 处理if result["signDate"] isnotNone:ifisinstance(result["signDate"], str): result["signDate"] = result["signDate"].replace("年","-").replace("月","-").replace("日","").replace("/","-") result["signDate"] = re.sub(r"-+", "-", result["signDate"]).strip("-")else: result["signDate"] = str(result["signDate"])# 清理字符串字段中的 null/None 字符串for k in ["contractNo", "contractName", "partyA", "partyB", "signDate"]:if result.get(k) in ("null", "None", "none", "", "undefined"): result[k] = Nonereturn result# ==================== 统一提取引擎 ====================classFieldExtractor:def__init__(self, use_llm: bool = True):self.regex_extractor = RegexFieldExtractor()self.llm_extractor = LLMFieldExtractor() if use_llm elseNoneself.use_llm = use_llmdefextract(self, ocr_results_list: List) -> Dict[str, Any]: full_text = merge_ocr_text(ocr_results_list)# 优先尝试 LLM 提取ifself.use_llm andself.llm_extractor andself.llm_extractor.available:try: logger.info("使用 LLM 进行智能字段提取...") result = self.llm_extractor.extract(full_text) result["llm"] = True logger.info("LLM 智能提取成功")return resultexcept Exception as e: logger.warning(f"LLM 提取失败,回退到正则提取: {e}")# 回退到正则提取 logger.info("使用正则进行字段提取") result = self.regex_extractor.extract(full_text) result["llm"] = Falsereturn result# ==================== FastAPI ====================app = FastAPI(title="OCR 表单自动填充 API")app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"],)ocr_manager = Nonefield_extractor = None@app.on_event("startup")asyncdefstartup():global ocr_manager, field_extractor ocr_manager = PaddleOCRModelManager() field_extractor = FieldExtractor(use_llm=True) logger.info("服务启动完成")@app.post("/api/ocr/extract")asyncdefocr_extract(file: UploadFile = File(...), use_llm: bool = True): suffix = Path(file.filename).suffix.lower() temp_path = TEMP_DIR / f"ocr_{int(time.time()*1000)}{suffix}" temp_files = [temp_path]try:withopen(temp_path, "wb") as f: shutil.copyfileobj(file.file, f) image_paths = []if suffix == '.pdf':ifnot HAS_FITZ:return {"code": 500, "success": False, "msg": "服务器未安装 PDF 支持库", "data": None} image_paths = pdf_to_images(temp_path) temp_files.extend(image_paths)else: image_paths = [temp_path] all_results = []for img_path in image_paths: result = ocr_manager.submit_ocr(str(img_path)) all_results.append(result) extractor = FieldExtractor(use_llm=use_llm) if use_llm else field_extractor result = extractor.extract(all_results) mode_text = "LLM智能"if result.get("llm") else"正则"return {"code": 200, "success": True, "msg": f"识别成功(共{len(image_paths)}页,{mode_text}提取)", "data": result}except Exception as e: logger.error(f"处理失败: {e}", exc_info=True)return {"code": 500, "success": False, "msg": str(e), "data": None}finally:for f in temp_files:try:if f.exists(): f.unlink()except:pass@app.get("/api/health")asyncdefhealth(): llm_available = Falsetry:if field_extractor and field_extractor.llm_extractor: llm_available = field_extractor.llm_extractor.availableexcept Exception:passreturn {"status": "ok","pdf_support": HAS_FITZ,"gpu": paddle.device.cuda.device_count() > 0if paddle.is_compiled_with_cuda() elseFalse,"llm_available": llm_available,"llm_model": field_extractor.llm_extractor.model if (field_extractor and field_extractor.llm_extractor) elseNone }if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=18888)九、总结
本文完整梳理了一套生产级 OCR 文档识别后端的实现方案。从 PaddleOCR 模型加载、PDF 预处理、中文金额状态机解析,到 Ollama LLM 智能提取与多层 JSON 容错,再到正则兜底的双保险机制,每个环节都针对实际业务痛点(OCR 格式错乱、大模型输出不稳定、服务并发安全)做了针对性设计。
该代码可直接作为微服务部署,配合前端 Vue3 表单实现”拍照/上传 → 智能识别 → 自动填充”的完整闭环,特别适用于合同管理、财务审批、档案数字化等国产信创场景。
十、GIT地址
git clone https://gitee.com/michah/ocr-auto-fill.gitgit checkout devcd backendpython ocr_api.pycd frontendnpm installnpm run dev