 夜雨聆风
夜雨聆风





信息焦虑的解药: 这个AI工具让我告别"错过恐惧症"
信息焦虑的解药: 这个AI工具让我告别”错过恐惧症”

程序员的痛: 信息爆炸时代的无力感
你是否也有这样的焦虑? 早上打开X, 几百条未读; 刷一遍Reddit, 热门话题已经换了好几轮; 想了解一下最新的AI工具, 却发现YouTube上堆积如山的评测视频根本看不完。
我们这一代人, 正经历着人类历史上最残酷的信息过载。AI领域更是日新月异, 昨天还在讨论Claude 3.5, 今天GPT-5的传闻已经满天飞。错过一个关键信息, 可能就意味着在技术上落后半年。
今天给大家介绍一个让我彻底告别这种焦虑的开源神器: last30days。
什么是last30days?
这是一个专为Claude Code设计的深度研究技能(Skill), 能够在2-8分钟内, 同时搜索10+个主流平台, 为你生成一份带有真实引用的研究报告。
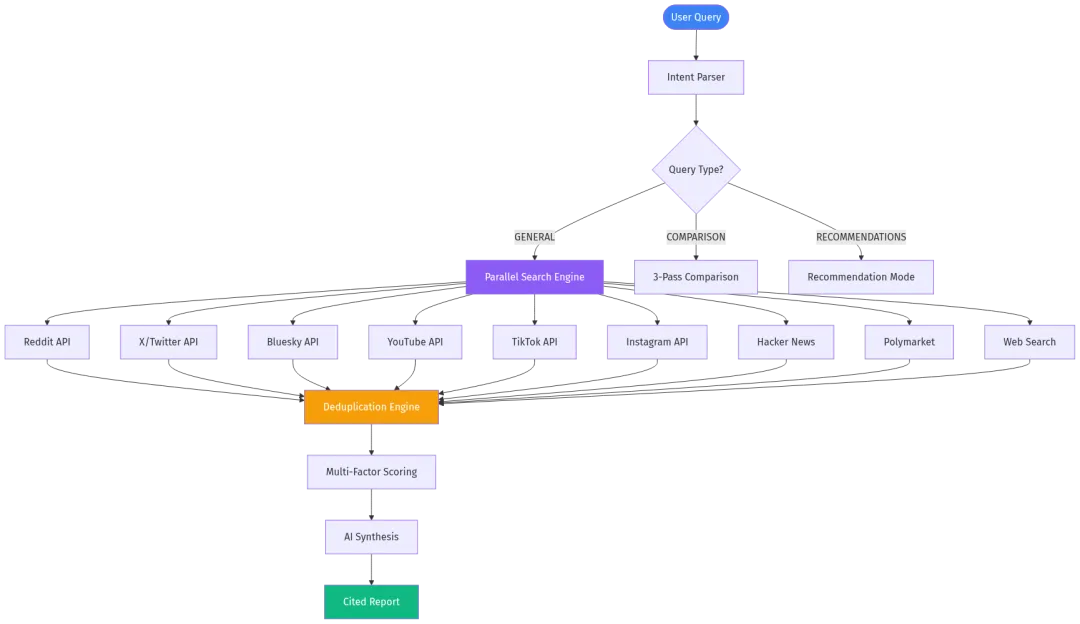
它覆盖的数据源包括:
- •Reddit – 真实用户的深度讨论
- •X/Twitter – 实时热点和专家观点
- •Bluesky – 新兴社交平台的声音
- •YouTube – 视频内容和字幕转录
- •TikTok – 短视频趋势
- •Instagram – 视觉内容趋势
- •Hacker News – 技术圈硬核讨论
- •Polymarket – 预测市场的真实赌注
- •Web搜索 – 博客、教程、新闻
核心技术揭秘
1. 并行搜索架构
这个项目的核心是一个高度并发的搜索引擎。它使用Python的ThreadPoolExecutor同时向10个数据源发起请求, 而不是串行等待。
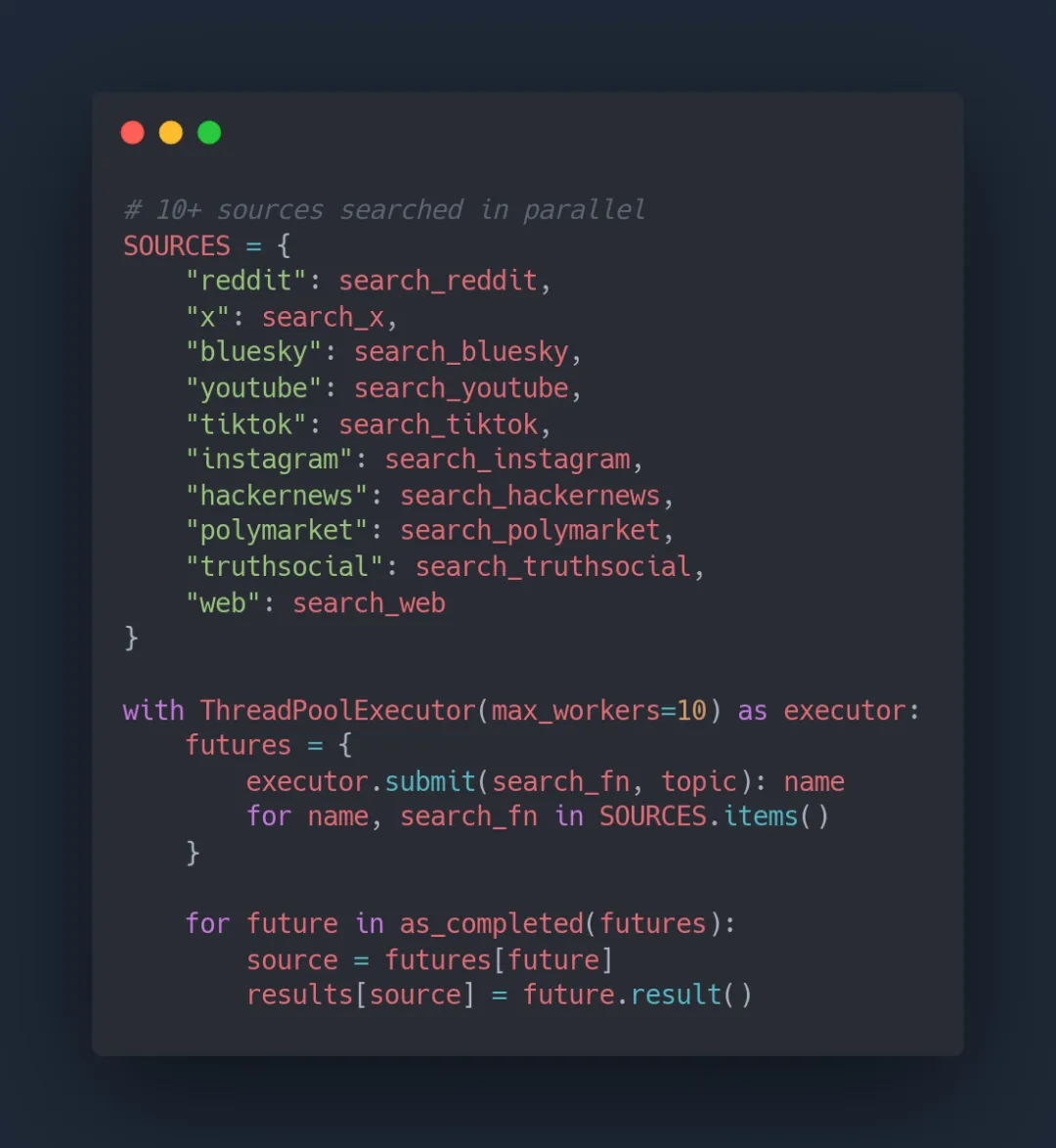
这种设计让原本需要几十分钟的搜索任务, 在3分钟内就能完成。每个数据源都有独立的超时控制, 不会因为某个平台响应慢而拖累整体速度。
2. 多因子评分算法
raw data不等于有用的信息。last30days实现了一套复杂的多因子评分系统:
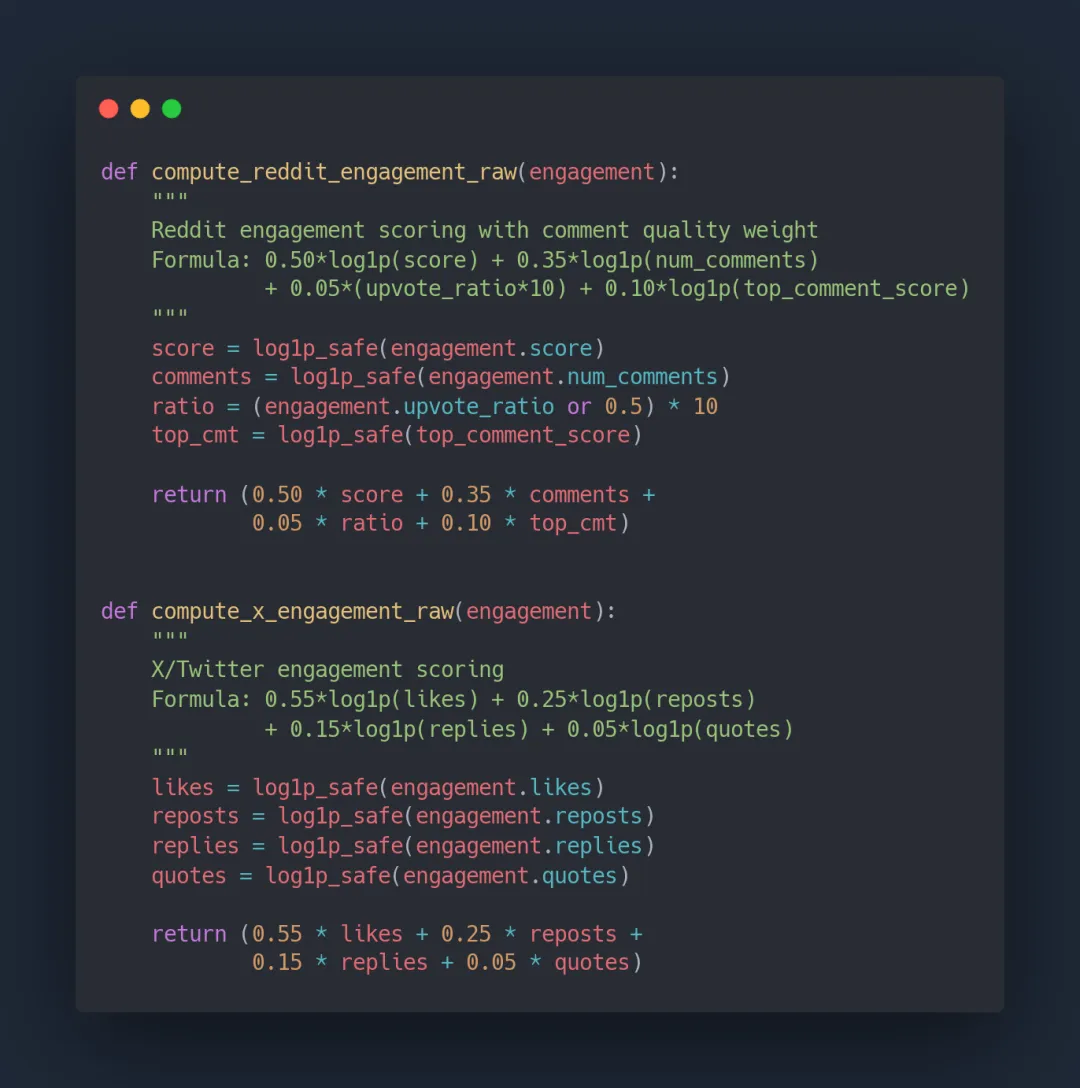
对于Reddit帖子, 它不仅看upvote数量, 还把评论质量(10%权重)纳入考量。一条有很多高质量评论的帖子, 比单纯点赞多但没人讨论的帖子更有价值。
对于X/Twitter, 它采用加权公式: 点赞(55%) + 转发(25%) + 回复(15%) + 引用(5%), 这种权重分配比单纯看点赞数更能反映内容的真实影响力。
3. 智能去重与跨平台关联
同一个话题可能在多个平台被讨论。last30days使用混合Jaccard相似度算法(三元组+token)来识别跨平台的相同话题, 避免报告里出现重复内容。
实际应用场景
场景一: Prompt工程研究
输入: “Nano Banana Pro prompting techniques”
输出: 一份包含JSON Prompt技巧、ICS框架、5元素公式等专业内容的报告, 附带Reddit和X上的真实案例。
场景二: 竞品对比
输入: “Cursor vs Windsurf”
输出: 系统自动进行3轮并行研究, 生成包含优劣势对比、功能对照表、数据驱动结论的完整分析。
场景三: 趋势追踪
输入: “AI video tools”
输出: 汇总YouTube评测、Reddit讨论、X上的专家观点, 告诉你现在最值得关注的工具是什么。
为什么这很重要?

在AI时代, 知道什么信息重要, 比知道所有信息更重要。last30days的价值在于:
-
1. 节省时间: 8分钟完成原本需要几小时的信息收集 -
2. 保证质量: 多源交叉验证, 避免单一平台的偏见 -
3. 真实引用: 每个结论都有来源链接, 可以追溯验证 -
4. 持续更新: 只关注最近30天的内容, 确保信息的时效性
开源与扩展
这个项目完全开源, 采用MIT协议。你可以:
- •添加新的数据源(比如小红书、知乎)
- •自定义评分权重
- •接入自己的AI模型进行内容合成
- •集成到自动化工作流中
安装方式也很简单, 支持Claude Code、Gemini CLI、OpenAI Codex等多个平台。
写在最后
信息焦虑的本质, 是害怕错过重要信息而产生的无力感。last30days并不能减少信息的总量, 但它能帮你建立一套自动化的信息筛选机制。
作为程序员, 我们应该用技术解决技术带来的问题。与其被动地刷信息流, 不如让AI帮我们做初筛, 把有限的时间花在真正有价值的内容上。
毕竟, 在这个信息爆炸的时代, 注意力才是最稀缺的资源。