 夜雨聆风
夜雨聆风





参数差200倍,小模型赢了:文档解析的瓶颈根本不是架构
📍 文 / 老Z
上海AI Lab做了一个很直接的实验:把几个最强的文档解析模型放在一批PDF上,看它们在哪些地方出错。
结果有点出人意料:不同架构、不同参数规模的模型,在完全相同的困难样本上出错,出的是同样的错误。
这个观察很值得停下来想一想。如果各家模型的失败模式高度一致,那这些失败就不是因为某个模型的架构不好——它们来自一个更上游的共同原因:训练数据里这类样本太少,而且标注质量太差。
这篇发在HuggingFace日榜第二的论文就是从这个发现出发的。他们保持MinerU2.5的1.2B参数架构完全不动,只改数据工程,最后在文档解析基准上打败了参数量是它200倍的大模型。
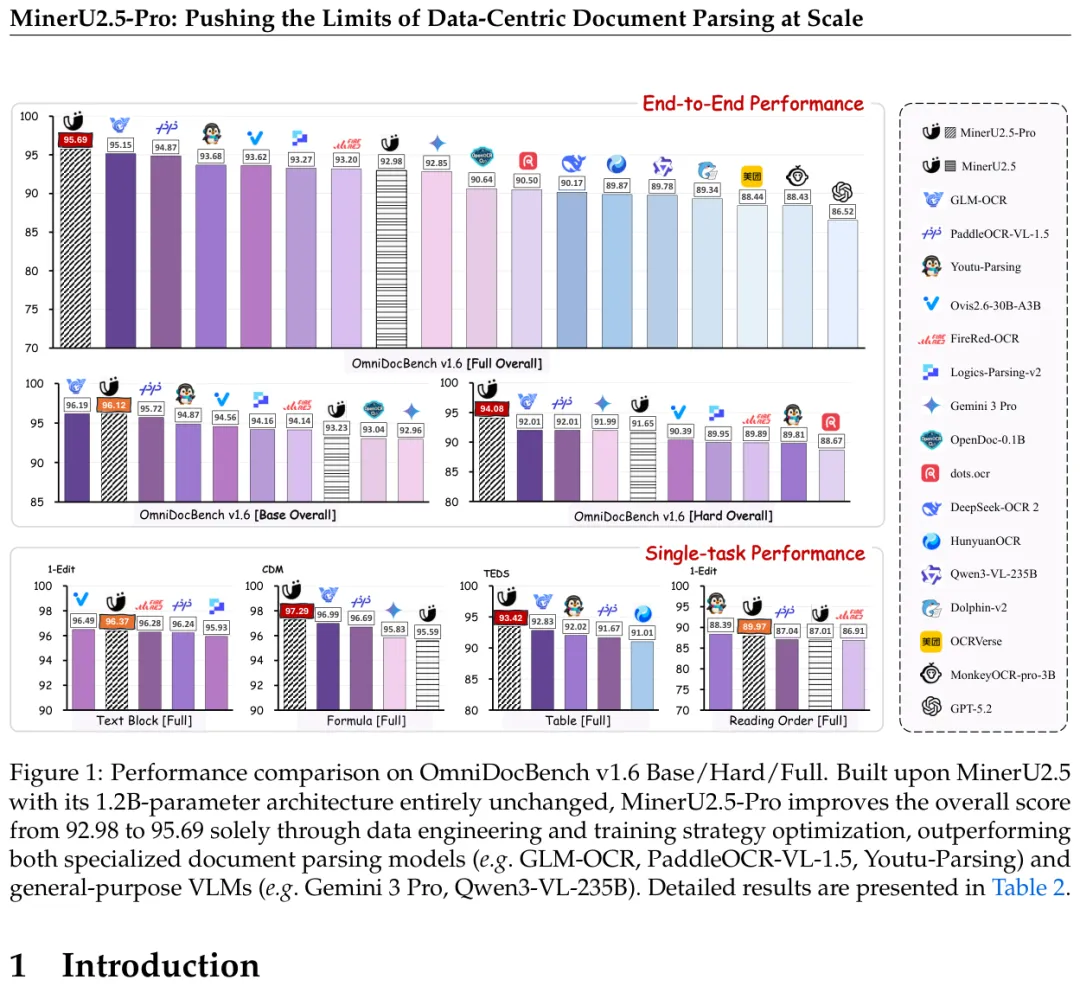
图:OmniDocBench v1.6 整体对比——MinerU2.5-Pro(1.2B)以95.69分领跑,超越Gemini 3 Pro、Qwen3-VL-235B等更大参数的模型
为什么架构卷不动了
过去两年,文档解析这个方向的论文都在比拼模型架构。从最早的pipeline式(分模块串联)到端到端VLM,到现在的解耦式(布局分析+内容识别分开走),方法迭代很快,但有一个现象开始出现:主流benchmark上的分数越来越接近,很难拉开差距。
论文里的这个cross-analysis实验解释了为什么:MinerU2.5、PaddleOCR-VL-1.5、Qwen3-VL-30B,三个架构不同、参数规模相差悬殊的模型,看到同一批难样本,给出的错误几乎一样。嵌套表格识别错,密集公式识别错,多列复杂布局识别错——错的点高度重合。
这说明这些模型共享了同一个弱点,而这个弱点不在架构层面,在训练数据层面:这类难样本在所有人的训练集里都太少了,而且就算有,标注也不可靠。
MinerU2.5的原始训练数据不到1000万页,高频类别(标准学术论文、单列报告)占主导,真正难的场景——复杂嵌套表格、密集数学公式、多列混排——在训练集里比例极低。更麻烦的是,这些难样本恰恰是现有自动标注工具最不擅长处理的,噪声大,直接用来训练会降低性能。
他们怎么解决的
MinerU2.5-Pro的核心是一套Data Engine,四个组件协同工作:
DDAS(多样性+难度感知采样)
原来的训练数据不到1000万页,他们用DDAS扩充到了6500万页。
方法是两级采样。页面级:用ViT-Base提取每页的视觉特征,做K-Means聚类,按照cluster里Easy/Hard样本的比例调整采样权重——Easy多的cluster降低采样概率,Hard多的cluster提高采样概率,同时把非目标语言、空白页之类的无效内容过滤掉。元素级:对text/formula/table三种元素分别独立聚类和难度评估,确保每种元素类型都有足够的难例覆盖。
CMCV(跨模型一致性验证)
扩充数据解决了覆盖问题,但还有标注质量问题:难样本的自动标注怎么可信?
他们用了一个聪明的方法:让三个异构模型(MinerU2.5、PaddleOCR-VL-1.5、Qwen3-VL-30B)独立解析同一个样本,看它们的输出是否一致。
三者都一致 → 标注可信(Easy);外部两个一致但MinerU2.5不同 → 说明这个样本是MinerU2.5的弱点,外部共识可以直接用作标注(Medium,训练价值最高);三者都不一致 → 没有可信的自动标注,需要人工介入(Hard)。
这个设计的聪明之处在于:Medium样本是”别的模型能做好,MinerU2.5做不好”的样本,这类样本的训练价值最高——它们是可学的,而且有可靠的标注来源。
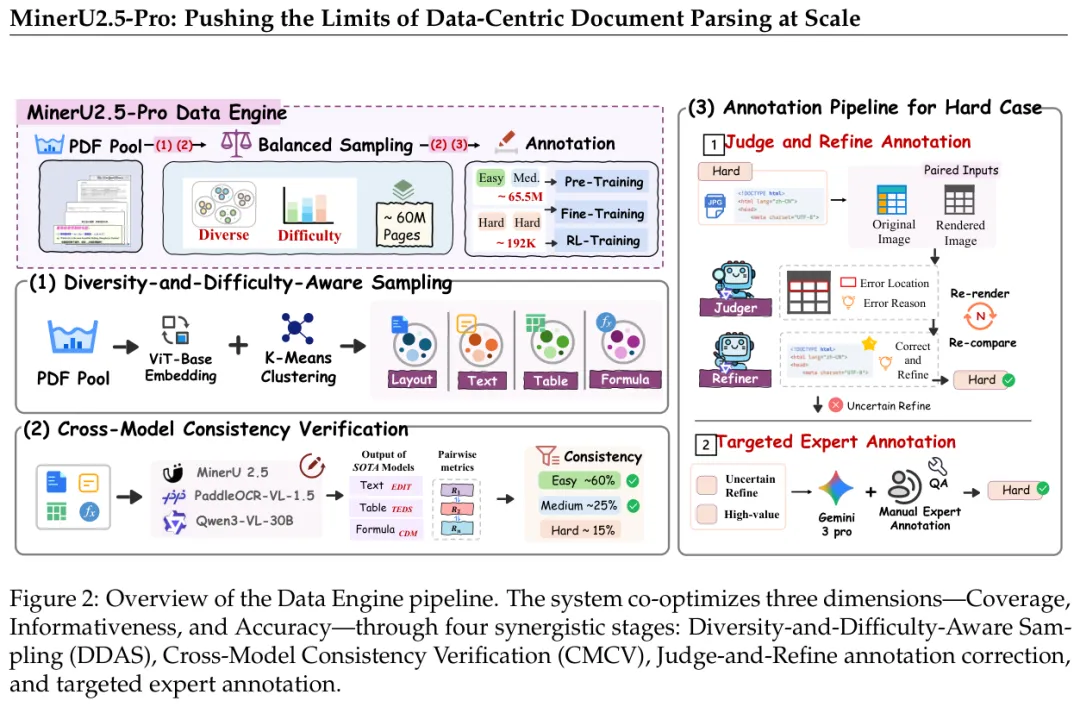
图:Data Engine的四个组件——DDAS采样、CMCV难度验证、Judge-and-Refine标注修正、专家标注,形成从粗到细的质量提升链路
Judge-and-Refine
Hard样本没有可靠的自动标注,直接扔给人工又太贵,他们设计了一个渲染验证的迭代修正流水线。
核心思路是打破模型自我验证的确认偏差:让模型检查自己的输出时,它倾向于认为自己输出是对的(因为从文档图到结构化序列这个映射方向它做得不错,但反过来从序列到视觉布局的推断能力很弱)。
解决方案:把模型输出的LaTeX公式编译渲染成图片,把HTML表格渲染成可视化界面,然后把原始文档和渲染结果并排送给Qwen3-VL-235B,让它做视觉对比判断。这样模型看到的是两张图的差异,而不是结构化文本的差异,更容易发现missing的alignment符号或unclosed的标签。
经过Judge-and-Refine处理后仍然搞不定的极端困难样本,才进入人工标注流程。
三阶段训练
数据引擎产出三个质量层级的数据,对应三阶段训练:
Stage 1 用6500万页Easy/Medium样本做大规模预训练,建立宽泛的基础能力。Stage 2 用19.2万条专家标注的Hard样本做精调,强化困难场景,同时混入Stage 1数据防止灾难遗忘。Stage 3 用GRPO强化学习,直接把评估指标(文本用编辑距离、公式用CDM、表格用TEDS)作为reward信号,消除训练目标和评估标准之间的gap。
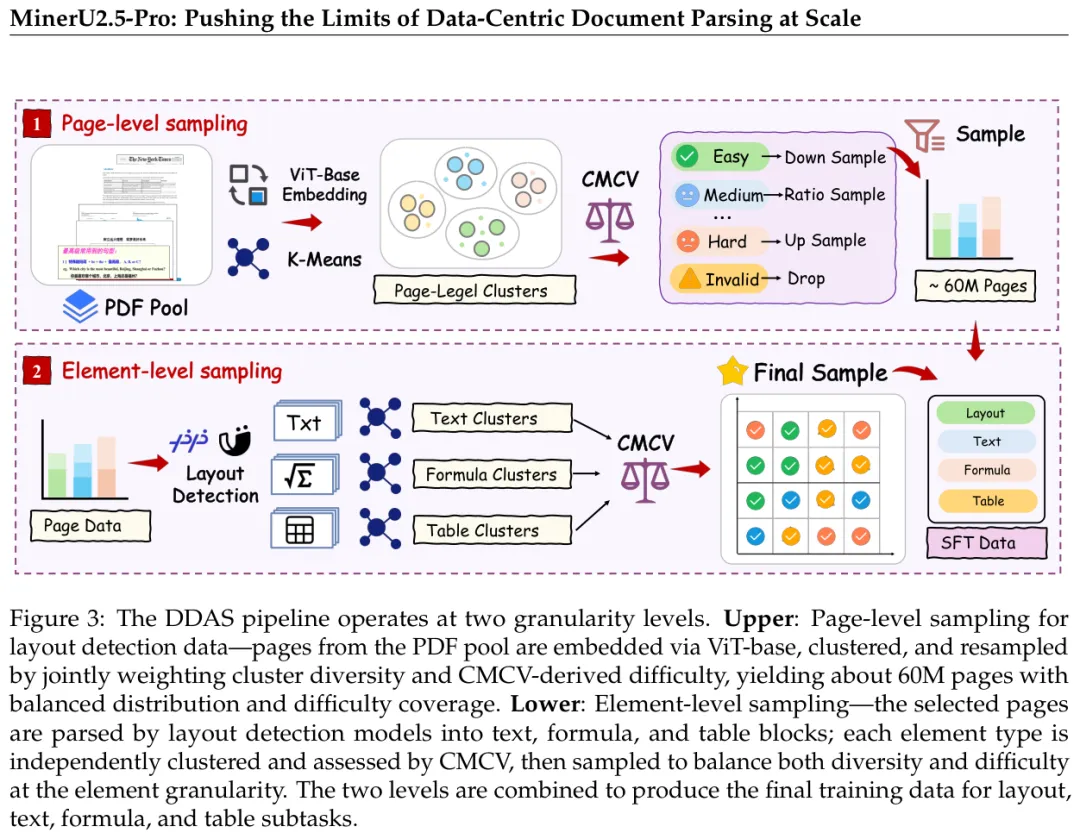
图:DDAS在页面级和元素级分别聚类并用CMCV重新加权,最终生成覆盖多样性和难度均衡的训练集
结果
OmniDocBench v1.6整体得分95.69,比同架构基线MinerU2.5(92.98)提升2.71分。
对比的具体数字:Gemini 3 Pro得92.85,Qwen3-VL-235B得89.78,1.2B的MinerU2.5-Pro都超过了它们。专门针对难样本的Hard子集上,MinerU2.5-Pro得94.08,比GLM-OCR和PaddleOCR-VL-1.5(两者都是92.01)高了2.07分。
消融实验把三个stage的贡献拆开来看:Stage 1数据扩充贡献最大(+1.31),Stage 2精调+0.96,Stage 3 GRPO+0.45。其中GRPO的贡献主要体现在公式CDM上(96.48→97.29),符合预期——强化学习直接优化任务指标,对format alignment的提升效果最明显。
他们还顺手升级了评估基准。原来的OmniDocBench v1.5有个系统性偏差:一个多行公式如果被模型正确识别了,但分成了两个block,v1.5会给零分,因为它用固定粒度的one-to-one匹配。这让输出粒度和ground truth不一样的模型被系统性低估,比如Gemini 3 Pro因为这个在v1.5上比实际表现差了很多。新版v1.6引入了Multi-Granularity Adaptive Matching,在预测侧搜索最优分割粒度,消除这个偏差,同时加入了专门的Hard子集(296页)。
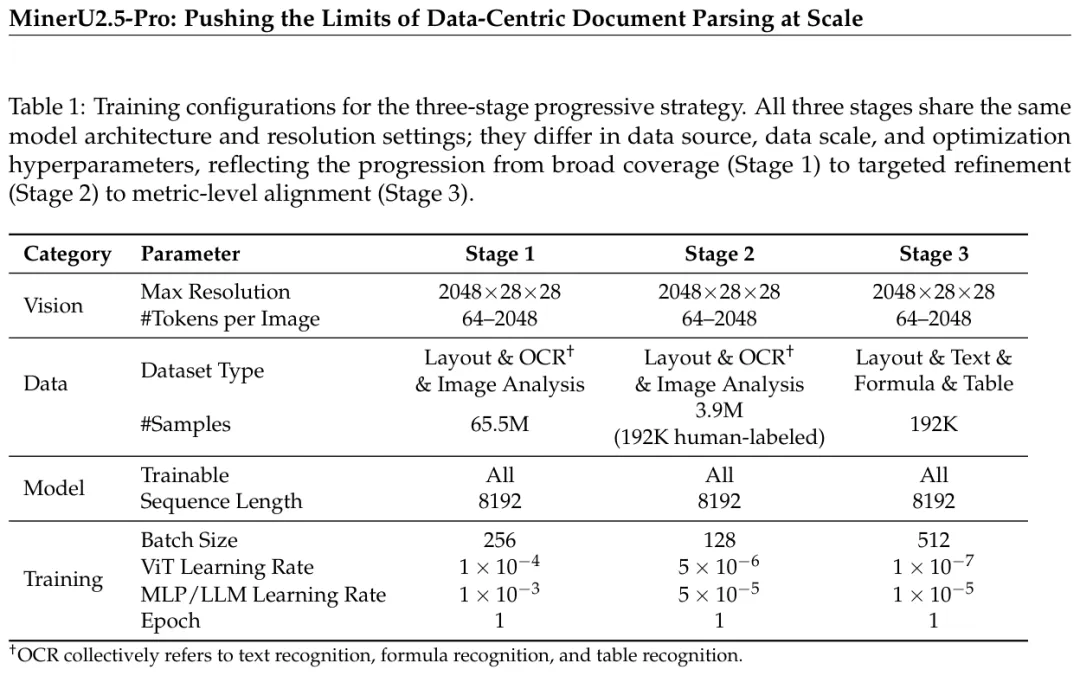
图:三阶段训练配置对比——相同架构、不同数据质量和训练策略,逐步提升性能
我的判断
这篇论文的结论,从直觉上说是对的:在一个成熟的架构上,数据质量提升的边际收益可能远大于架构迭代。
但我觉得有一点需要注意:这个结论的成立有一个前提,就是当前的模型架构已经足够表达能力丰富,性能瓶颈确实在数据侧。如果架构本身就有根本性的缺陷,再好的数据也没用。MinerU2.5-Pro能成功,部分原因是MinerU2.5的架构本身已经经过充分迭代,能力天花板足够高。
另一个有意思的点:他们用200多倍参数量的Qwen3-VL-235B作为Judge-and-Refine的评判模型,来改进1.2B小模型的训练数据质量。这种”大模型帮小模型造数据”的思路,在文档解析领域落地的方式还挺独特。
公式识别接近满分(CDM 99.20),表格识别接近满分(TEDS-S 95.92),剩下的提升空间主要在结构关系理解上——论文里也提到了,从”内容提取”到”结构语义理解”是下一步的自然演进方向。
论文:arxiv 2604.04771 | 模型:huggingface.co/opendatalab/MinerU2.5-Pro-2604-1.2B
✍️ 老Z ·
欢迎转发,谢绝洗稿