 夜雨聆风
夜雨聆风





DeepSeek专家模式上线:AI助手开启“分餐制”时代
今天我们要聊一个AI圈的大新闻——就在今天,2026年4月8日,DeepSeek悄然上线了“专家模式”,这是它走红以来首次在产品端引入模式分层设计。
如果你现在打开DeepSeek网页端或App,会发现输入框上方多了两个图标:左边是闪电⚡️,右边是钻石💎。这可不是简单的UI调整,而是DeepSeek从“一锅炖”到“分餐制”的重要转型。
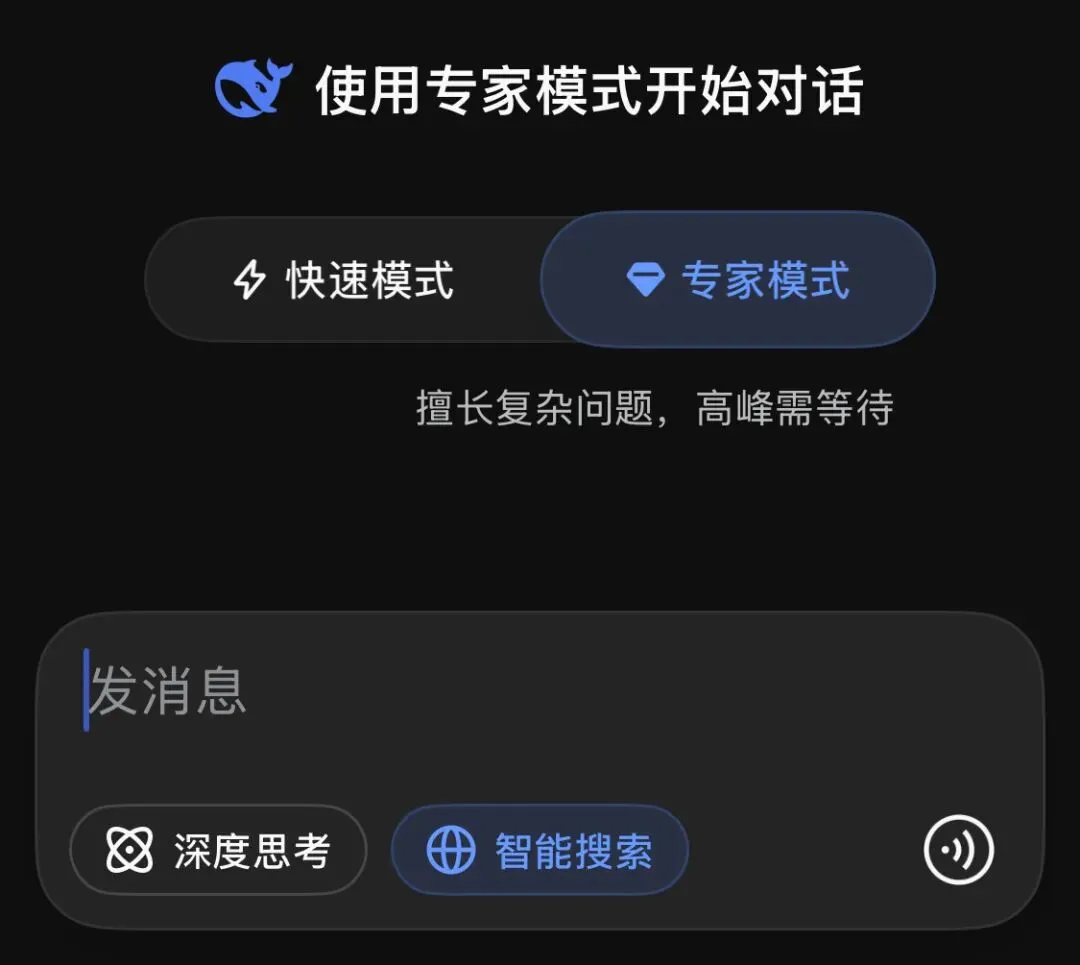
快速模式 vs 专家模式的核心差异
专家模式则主打“深和长”,擅长处理复杂问题,但高峰时段可能需要排队等待。这个模式下,DeepSeek会进行更深入的思考和智能搜索,在编程、法律、医学等专业领域的知识咨询能力上有明显增强。

实测对比:专家模式优势明显
从实测结果来看,专家模式在深度推理任务上展现出了碾压性优势。
比如一道经典的数理问题:“一根7米长的甘蔗能否通过高2米、宽1米的门?”快速模式直接说“不能”,而专家模式不仅给出了“可以通过”的正确答案,还详细解释说甘蔗横截面小,可以像长矛一样穿过去。
在编程测试中,让两个模式编写一个受重力和摩擦力影响的物理仿真程序,专家模式输出的运行结果更符合物理直觉,弹跳轨迹也更真实。物理仿真对数学推理能力要求极高,弱一点的模型容易出现“看起来像物理但实际上不对”的情况。
技术内核:专家模式的强大支撑
专家模式功能由DeepSeek下一代混合专家模型(MoE)架构支撑,核心底座是DeepSeek-V3.2(或其后继版本)和推理层融合DeepSeek-R1的强化学习成果。简单来说,专家模式=V3.2的领域专家路由+R1的深度推理机制+专业检索增强的组合应用。
在当前的专家模式下,上下文窗口限制是1M(约100万Token),可以一次性处理并记住相当于三部《三体》三部曲体量的纯文字内容。而快速模式的上下文窗口通常是128K或256K。
使用场景:如何正确选择模式?
对于普通用户而言,日常对话、简单问答使用快速模式足矣;但若面对的是高难度的数学推理、专业编程、学术研究或法律咨询等深度任务,专家模式无疑是当前的最佳选择。
具体来说:
• 读复杂的PDF合同或论文:推荐专家模式,虽然不能直接传文件,但可以复制粘贴文字内容,1M超长上下文能完美容纳几十万字的文本。
• 截了一张表格图想转成Excel:必须用快速模式,专家模式不认图片。
• 写复杂的算法Bug:推荐专家模式,推理链更严谨、结果更精准。
• 写小红书种草文案:推荐快速模式,文风更自然朴实。
• 查询2026年最新行业政策:推荐快速模式,专家模式的知识库停留在2025年5月。
行业意义:算力精细化管理的重要一步
这次更新背后,隐藏着DeepSeek商业策略的重要转折。过去全免费、无门槛的模式在巨大的推理成本面前难以为继,通过模式分层进行算力分流、控制成本,已成为商业化落地的必然选择。
截至2026年3月,中国AI大模型日均Token调用量已突破140万亿,较2024年初增长超千倍。部分重度AI用户每月仅花费20美元订阅费,却能消耗数千美元的算力资源。当“为每个人提供最强大脑”的理想撞上物理极限时,分层调度成为必然选择。
V4发布的前奏?
业内普遍认为,这次更新是V4发布前的重要信号。专家模式在复杂任务上的表现已明显超越V3.2,疑似提前接入V4部分能力。界面还曾短暂出现“Vision模式”入口,暗示多模态(图像/视频)即将全面落地。
V4预计将拥有1T参数、原生多模态支持和1M上下文窗口,采用MoE架构,每次仅激活32B~37B参数。这标志着DeepSeek完成了从“参数竞赛”到“架构范式创新”的跨越。
结语
DeepSeek推出这两个模式,本质上是为了解决一个矛盾:人类既想要AI瞬间回应,又想要AI深度思考。从旧版“一锅炖”到新版“分餐制”,这看似只是界面上多了两个图标,实则标志着DeepSeek产品理念的一次重要转型——从普惠式的通用服务,走向精细化的专业分层。
现在有了这个切换开关,主动权完全交到了用户手里。下次使用前,花1秒钟看一眼左上角的图标:要广度、速度、识别图像?请认准闪电⚡️。要深度、精度、处理巨著?请认准钻石💎。
AI正在完成一次从“实验品”到“商品”的转变,而DeepSeek的这次更新,正是这场变革中的重要一步。