 夜雨聆风
夜雨聆风





语义分块:让RAG系统真正理解你的文档
最近做了一个制度文档RAG项目,发现之前的分块方法都不够智能。
制度文档逻辑很强,用固定长度分块会把一个完整的条款切成两半,用结构感知分块又因为文档结构不明显而效果一般。
后来试了语义与主题分块,效果直接提升了一个档次。今天把这个方法分享给大家。
什么是语义与主题分块?
不再按字数、换行、标题硬切,而是根据”语义是否连贯”来切分文本,让每个chunk都是一段意义完整、主题统一的内容。
它是目前RAG里效果最强、最智能的分块方式,特别适合:长文章、制度文档、报告、合同、专业手册、人事流程这类逻辑强、连贯性高的文本。
语义分块的核心原理
通过句向量计算,检测相邻句子间的”语义突变”(相似度骤降),以此作为分块边界。
-
优势:块体内语义高度内聚,适配高精度检索场景 -
不足:计算开销大,短文档优化效果有限 -
适用场景:学术论文、行业白皮书、技术论证类长文档
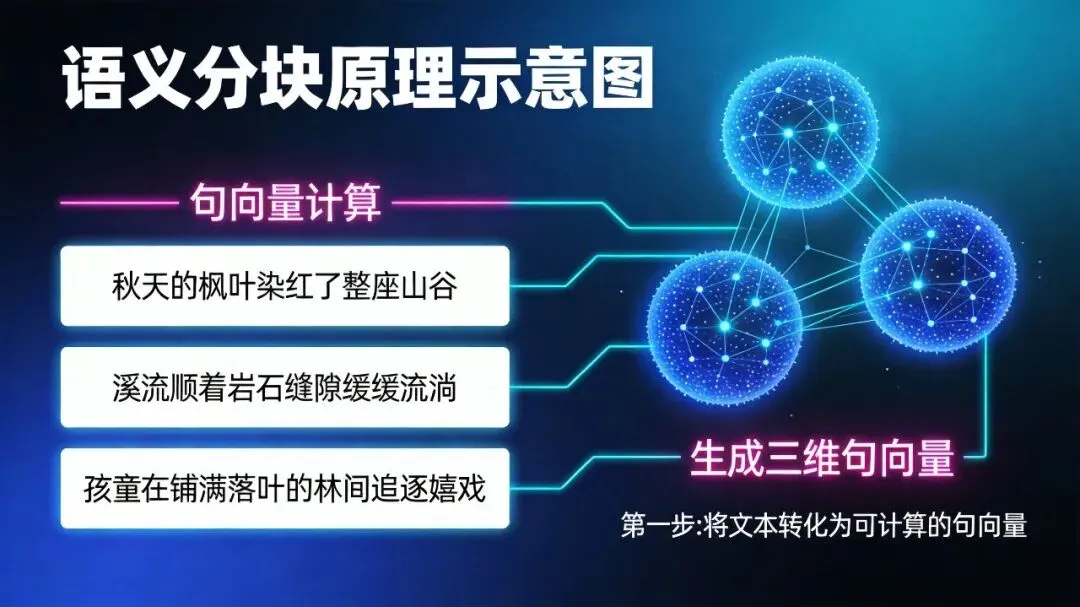
语义分块的简单原理
-
先把文本切成短句(句子级别) -
用embedding模型给每句话生成向量 -
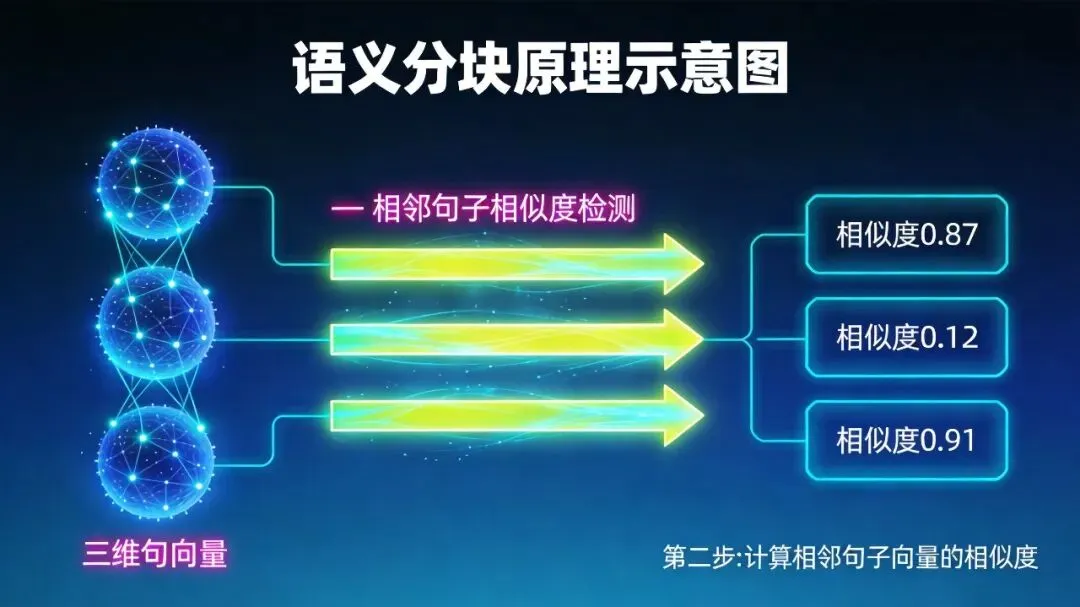
计算相邻句子之间的相似度 -
相似度高 → 语义连续 → 合并 -
相似度突然变低 → 话题切换 → 切分 -
最后再控制chunk大小,避免过长/过短
我做学术论文RAG的时候,用这个方法分块,模型能准确回答关于某个章节的问题,而不会把不同章节的内容混在一起。
什么时候使用语义分块
-
文档没有明显标题结构,但逻辑很强 -
文档很长、内容密集(制度、合同、论文) -
你希望RAG检索极准、不乱回答 -
流程类、制度类、条款类文档(你的人事流程非常适合)
我做人事流程RAG的时候,用语义分块,模型能准确回答”入职流程的具体步骤”,而不会把入职流程和离职流程的内容混在一起。
# 伪代码逻辑1. 把全文切成句子sentences = split_sentences(text)2. 对每个句子生成向量vecs = [embedding.embed_query(s) for s in sentences]3. 计算相邻句子相似度scores = cos_sim(vecs[i], vecs[i+1])4. 相似度低于阈值 → 切分chunks = []current = []for i, s in enumerate(sentences):current.append(s)if i < len(sentences)-1 and scores[i] < THRESHOLD:chunks.append("\n".join(current))current = []chunks.append("\n".join(current))

实操心得
-
选择合适的embedding模型:中文建议用text2vec-base-chinese或m3e-base -
设置合理的相似度阈值:一般0.8-0.9之间,根据文档类型调整 -
控制chunk大小:最小200token,最大800token,根据模型上下文窗口调整 -
保留一定的重叠:10-20%的重叠,避免语义断裂 -
结合结构信息:如果文档有标题结构,可以结合结构感知分块一起使用
最近做一个合同RAG项目,用语义分块,模型能准确回答”违约责任条款”的具体内容,效果比之前用固定长度分块好太多了。
语义分块的局限
-
计算开销大:需要给每句话生成向量,处理长文档时速度较慢 -
对短文档效果有限:短文档语义变化少,分块效果不明显 -
需要调参:相似度阈值、chunk大小等参数需要根据具体文档调整
最后想说的
语义与主题分块是目前RAG分块的最高境界,效果确实好,但也需要一定的技术储备。
如果你正在做逻辑强、连贯性高的文档RAG,强烈建议试试语义分块,效果会比普通分块好很多。
当然,具体实现的时候要根据文档类型和项目需求调整参数,找到最适合的分块策略。
大家有什么语义分块的经验,欢迎在评论区分享!