 夜雨聆风
夜雨聆风





文档处理工具对比:从 PaddleOCR 到现代 PDF 解析方案
WECHATIMGPH_1
PaddleOCR 爆火之后,文档处理赛道涌现更多玩家。如果你需要处理 PDF、表格、复杂文档,除了 PaddleOCR 还有哪些选择?
一、为什么需要文档处理工具?
如果你处理过大量文档,一定遇到过这些问题:
-
• PDF 转文字乱码:多栏排版被打乱 -
• 表格识别困难:OCR 后变成纯文本,结构丢失 -
• 公式/图表无法提取:学术论文里的数学公式识别率低 -
• 多语言混合:中英文混排时切换模型麻烦
PaddleOCR 解决了基础 OCR 问题,但复杂文档还需要更专业的工具。
二、工具对比
|
|
|
|
|
|
|---|---|---|---|---|
| PaddleOCR |
|
|
|
|
| Surya |
|
|
|
|
| Marker |
|
|
|
|
| DocTR |
|
|
|
|
三、Surya:全能型选手
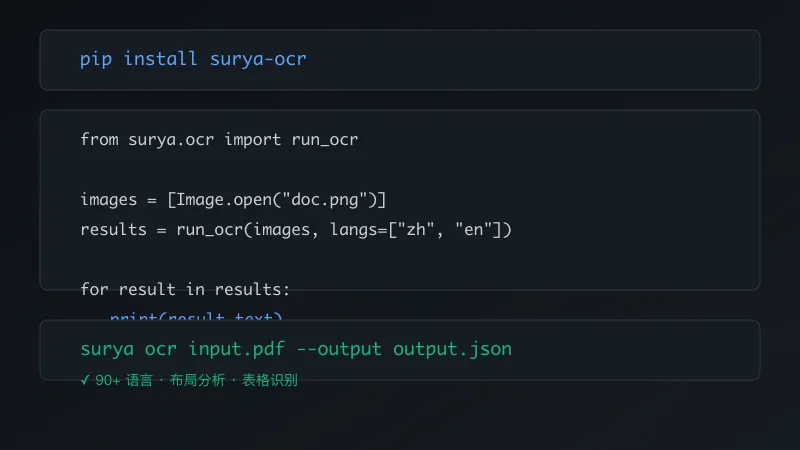
安装
pip install surya-ocr基本使用
from surya.ocr import run_ocrimages = [...] # 你的图片列表results = run_ocr(images, langs=["zh", "en"])for result in results: print(result.text)处理 PDF
surya ocr input.pdf --output output.jsonSurya 会自动处理 PDF 转图片、OCR、布局分析、输出结构化数据。
核心能力
-
• 布局分析:区分标题、正文、侧边栏、表格 -
• 阅读顺序:多栏文档自动排序 -
• 表格识别:保留行列结构
四、Marker:PDF 转 Markdown
安装
pip install marker-pdf基本使用
marker input.pdf output_dir --langs Chinese特点
-
• 输出为 Markdown(保留标题、列表、表格) -
• 公式转为 LaTeX -
• 图片提取为独立文件
适合场景:
-
• 学术论文 PDF 转 Markdown -
• 技术文档提取 -
• 知识库构建
五、PaddleOCR 何时够用?
PaddleOCR 依然值得用,适合:
-
• 简单文档:单栏、无表格 -
• 中文优先:中文识别准确率最高 -
• 实时 OCR:摄像头流处理 -
• 轻量部署:移动端/边缘设备
不适合:
-
• 复杂排版(多栏、表格、公式) -
• 需要结构化输出 -
• PDF 直接转 Markdown
六、选型建议
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
七、总结
文档处理赛道正在从 “能识别” 向 “理解文档结构” 进化。
-
• PaddleOCR:中文 OCR 标杆,简单场景首选 -
• Surya:全能型选手,复杂文档处理 -
• Marker:PDF 转 Markdown 专用
根据你的需求选择,或者组合使用。
下期预告:开源安全事件复盘——Megalodon 攻击 5500+ GitHub 仓库。
觉得有用?转发给需要的朋友,评论区聊聊你的文档处理需求。
作者:10 +年 Java 开发者,AI 项目实战派