 夜雨聆风
夜雨聆风





文档管理的终极形态:LLM Wiki
企业知识管理有一个不成文的规律:文档上传之日,就是它死去的开始。
这句话刺耳,但符合现实。企业网盘、共享目录、文档中心——绝大多数组织的知识库在文件上传之后,再也没有被打开过第二次。
不是不想用,是找不到、看不懂、懒得翻。
文件管理的三次进化
第一阶段:普通文档管理
上传文件→命名→文件夹分类→靠人记忆路径
问题:文件名即语义上限。搜索依赖记忆,跨文件关联靠人。
第二阶段:RAG检索增强生成
文档切块→向量化→语义检索→LLM生成
进步:解决了搜索问题,可以问问题了。
问题:单次问答为主,无法呈现文件间的结构关系。用户不知道AI回答来自哪个文件、哪个段落。无法综合多个文档给出完整图景。
第三阶段:LLM Wiki
把整个知识库变成一个会呼吸的专家。你扔给它压缩包,它自己解压、整理、建模。你问它问题,它基于内部知识综合回答——不是片段,是结构。
这是Karpathy提出的方法,也是当前最接近企业知识库终极形态的方案。
实战:扔一个ZIP包进去
新零售体系不是单一产品,是一套持续迭代了两年的系统。知识库包含了:线上商城、分销模块、管理后台、客服系统、财务对账、供应链管理等各端的历史文档。版本多、文件多、更新频繁,光是分销模块就有至少6个历史版本。
这次测试,把整个新零售体系的历史文档打包扔进去。42个文件,覆盖从V1.0到V3.0的所有迭代记录,涵盖分销协议、佣金计算规则、考核指标、合同模板、系统操作手册等多个维度。内部格式混乱,有Word、Excel、PDF,编码也不统一。
LLM Wiki自动完成了以下工作:
1. 解压原始资料—系统自动识别ZIP并解压

2. 文件名编码修复—处理乱码文件名,42个文件去重压缩至27个
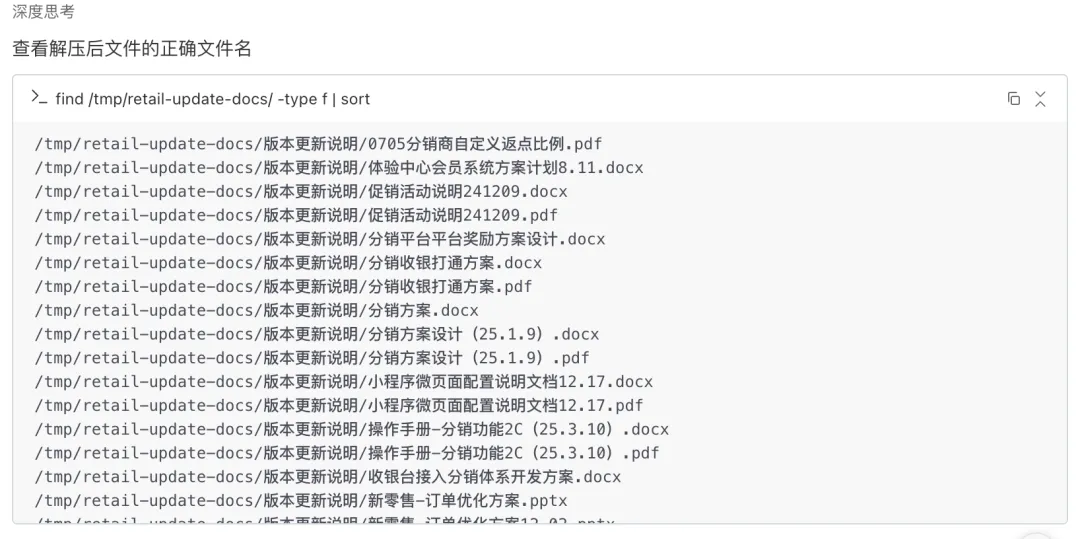
3. 原始资料处理完毕—生成文件清单与来源摘要

4. Wiki页面生成—提取概念、实体、导航结构
用户不需要手动整理任何一个文件。
传统RAG做不到的事
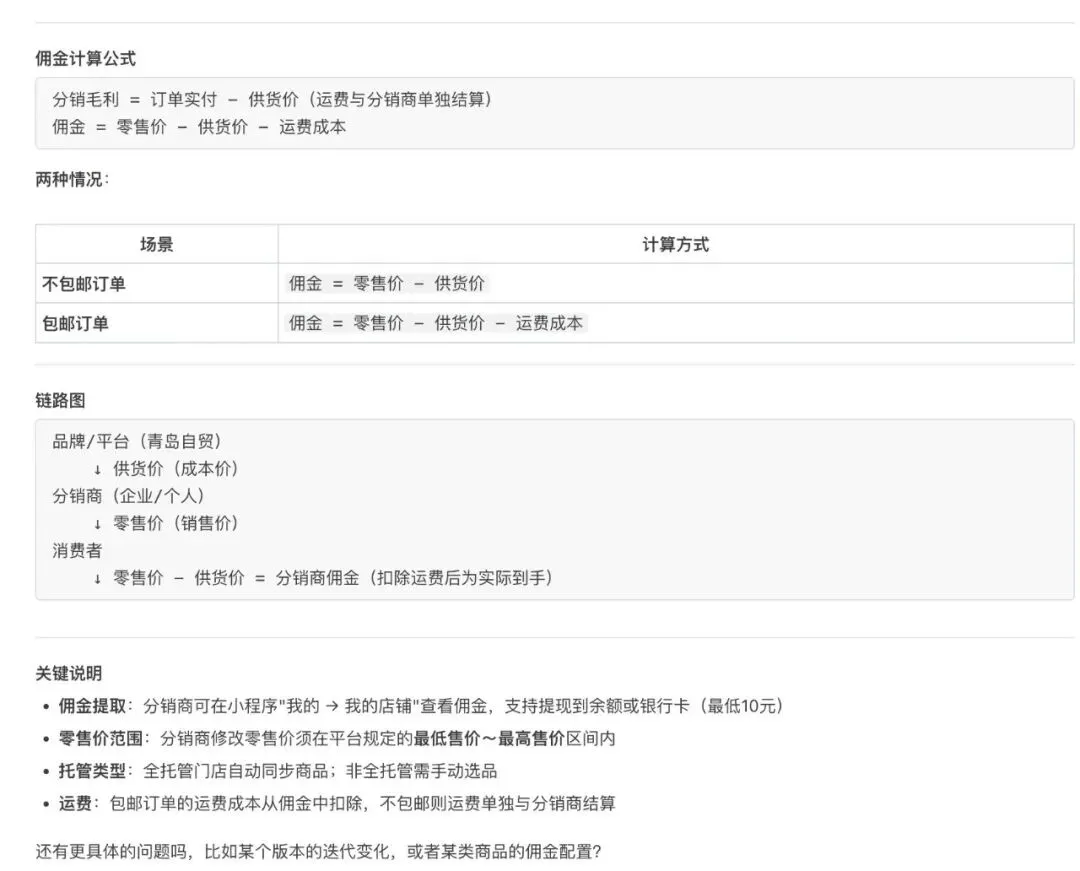
对比测试场景:问分销佣金计算逻辑是什么

传统RAG的回答路径:
用户提问→语义检索最相关的Top-K片段→LLM拼凑回答
问题:佣金计算逻辑分散在多个文件中(协议文本写规则、Excel表格给参数、Word文档给例外说明),RAG只会匹配到最像的那个片段,无法综合。
LLM Wiki的回答路径:
用户提问→LLM理解问题→遍历知识库结构→综合多个文件输出完整答案
输出不仅包含计算逻辑,还附带例外情况、适用条件、合同依据——相当于一个读完了全部相关文件的顾问在回答。
LLM Wiki当前的局限同样明显:
上下文窗口限制:27个文件能否一次性建模,取决于总Token数量。超长知识库仍需要分级检索策略,不是全量塞进去。
幻觉风险:综合回答比单片段检索更容易出现逻辑跳跃。需要有来源追溯机制,Wiki页面的导航功能就是为此设计的。
部署成本:普通RAG的向量数据库方案已经很轻量。LLM Wiki需要更强的LLM推理能力,ROI要按知识库规模来算。
适用边界:知识库活跃度高、文件间关联紧密、业务逻辑分散在多个文档中的场景,LLM Wiki优势明显;静态文档库、查询简单的场景,传统RAG性价比更高。
行业洞察
文档管理的本质不是存储,是激活。
99%的企业知识库死于存储思维——把文件放上去就算完成了知识管理。LLM Wiki带来的是一次范式转移:从文档在哪里到知识怎么运作。
工具会继续进化。但不变的是:能让知识流动起来的系统,才有价值。