 夜雨聆风
夜雨聆风





给数据做个“全身体检”:如何用软件工程思维打造高质量行业数据集



行业高质量数据集成为支撑大模型训练和智能分析
的核心生产要素,并持续推动行业发展。
编者按

在大模型浪潮下,几乎所有企业都在喊:“我们要All in AI!”,但现实往往很骨感。很多企业在训练行业大模型时发现:算法有了,算力够了,效果却总是不尽人意。 问题出在哪?
答案往往是:数据。
如果说大模型是“超级大脑”,那么高质量的数据集就是“脑白金”。没有高质量的数据,AI就是“Garbage In, Garbage Out”(垃圾进,垃圾出)。
最近,一篇发表于《智能感知工程》的论文,针对行业高质量数据集的建设难题,提出了一套系统化的解决方案——DDLC(数据集开发生命周期,Dataset Development Life Cycle)模型。今天我们就来拆解这套“数据炼金术”。
01 痛点:为什么你的数据集总是“难产”?
在很多传统行业中,数据集的建设往往是“拍脑袋”工程:
-
缺乏统筹规划,想到哪做到哪;
-
数据来源杂乱,质量参差不齐;
-
只管建不管养,数据很快过时失效。
这导致的结果就是:AI模型训练出来的效果不稳定,甚至因为数据偏见产生误导。
02 破局:像管理软件一样管理数据
论文作者李哲洙等专家提出了一个核心观点:把数据集当作一款特殊的“软件产品”来管理。
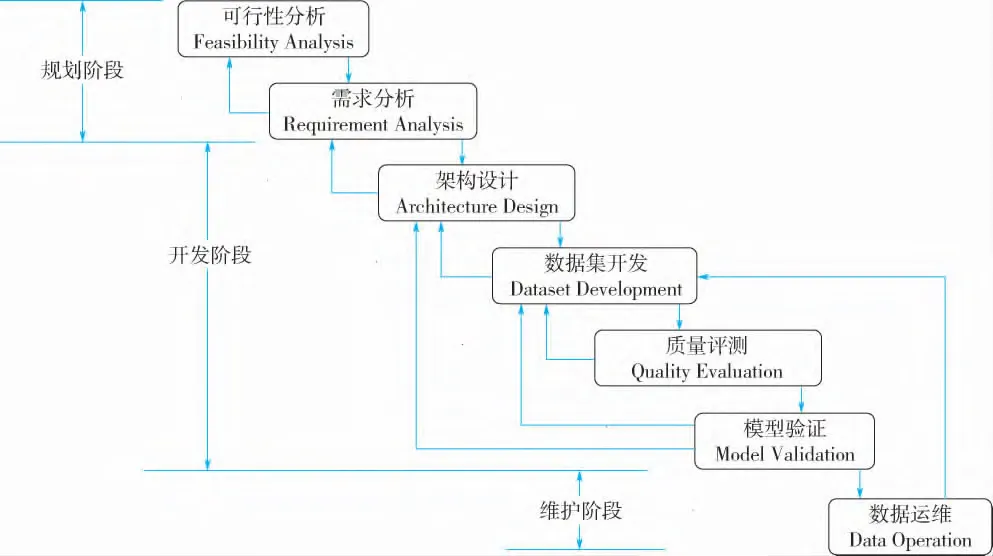
为此,他们构建了DDLC(Dataset Development Life Cycle)模型,将数据集的生命周期严格划分为3个阶段、7个关键环节:
📌 第一阶段:规划(Plan)
-
可行性分析: 不仅要看技术能不能做,还要算算经济账(ROI),更要看清法律风险(数据合规)。
-
需求分析: 明确数据集到底要用来干什么?是生成工艺图纸,还是做合规校验?
📌 第二阶段:开发(Develop)
-
架构设计: 设计数据结构、存储方案和知识图谱。
-
数据集开发: 采集、清洗、标注、集成。
-
质量评测: 检查数据是否准确、完整、一致。
-
模型验证: 把数据喂给模型,用模型的效果反推数据的缺陷。
📌 第三阶段:维护(Maintain)
-
数据运维: 版本控制、增量更新、检测数据漂移,直到最终的安全销毁。
03 升级:引入“敏捷”,让数据动起来
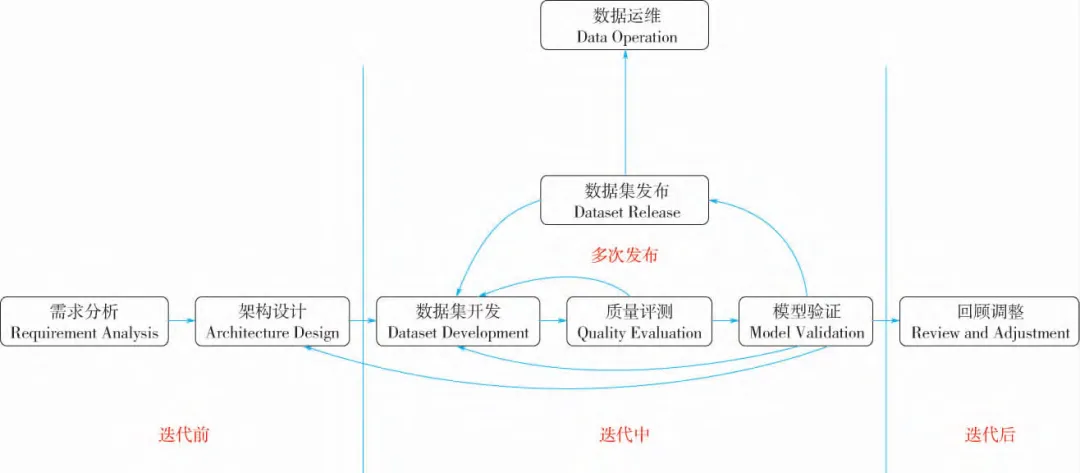
传统的瀑布式开发太慢了,市场瞬息万变。论文特别强调了一个进阶版玩法——敏捷式DDLC。
不再是一次性交付,而是通过短周期迭代:
-
先快速出一个基础版数据集。
-
投入模型训练,发现问题(如某个工艺参数缺失)。
-
立刻回溯修正,发布新版本。
-
循环往复,持续优化。
这就解决了行业需求多变、数据动态演化的痛点。
04 实战:轨道交通装备制造的“翻身仗”
这套理论真的有用吗?论文中以某轨道交通装备制造企业为例进行了验证。该企业面临焊接工艺质量不稳、新手培训难、文件更新慢等问题。
他们是怎么做的?
采用敏捷式DDLC模型,每季度一轮迭代:
-
建图谱: 构建了“材料-参数-标准”的知识图谱。
-
洗数据: 完成了15000份工艺指导书的数字化与清洗。
-
快迭代: 发现模型生成不准,就立刻回头补数据、修标注。
成果如何?
-
工艺指导书生成效率提升3倍。
-
工艺合规性校验自动化率达90%。
-
彻底改变了依赖老师傅经验的旧模式,实现了数据驱动的智能工艺。
05 结语
数据不是静止的资产,而是流动的血液。
无论是金融、医疗还是制造业,要想在大模型时代占据先机,就必须摒弃“粗放式”的数据堆砌,转向“工程化”的数据管理。DDLC模型不仅是一套流程,更是一种“数据质量即产品生命”的思维转变。
你觉得你们公司的数据质量过关吗?欢迎在评论区聊聊你的看法。
咨询电话:139-9132-5608




本文基于《行业高质量数据集生命周期模型构建与应用研究》(李哲洙、李荪,《智能感知工程》撰写》