 夜雨聆风
夜雨聆风





Oracle官方文档翻译《Database Concepts 26ai》第1章-Oracle AI 数据库简介
1 Introduction to Oracle AI Database(1 Oracle AI 数据库简介)
本章提供 Oracle AI 数据库的概述。本章包含以下主题:
-
• About Relational Databases(关系型数据库简介):每个组织都有必须存储和管理以满足其需求的信息。例如,一家公司必须收集并维护其员工的人力资源记录。这些信息必须可供需要者使用。 -
• Schema Objects(模式对象):RDBMS 的一个特征在于物理数据存储与逻辑数据结构的独立性。 -
• Data Access(数据访问):DBMS 的一项普遍要求是遵循公认的行业数据访问语言标准。 -
• Transaction Management(事务管理):Oracle AI 数据库被设计为多用户数据库。该数据库必须确保多个用户可以并发工作,而不会破坏彼此的数据。 -
• Oracle AI Database Architecture(Oracle AI 数据库体系结构):数据库服务器是信息管理的关键。
About Relational Databases(关系型数据库简介)
每个组织都有必须存储和管理以满足其需求的信息。例如,一家公司必须收集并维护其员工的人力资源记录。这些信息必须可供需要者使用。
信息系统(Information System)是用于存储和处理信息的正式系统。信息系统可以是一组带有马尼拉文件夹的纸板箱,以及如何存储和检索这些文件夹的规则。然而,如今大多数公司使用数据库来自动化其信息系统。数据库(Database)是被视为一个单元的有组织的信息集合。数据库的目的是收集、存储和检索相关信息,供数据库应用程序使用。
-
• Database Management System (DBMS)(数据库管理系统(DBMS)) -
• Relational Model(关系模型) -
• Relational Database Management System (RDBMS)(关系型数据库管理系统(RDBMS))
Database Management System (DBMS)(数据库管理系统(DBMS))
数据库管理系统(DBMS,Database Management System)是控制数据存储、组织和检索的软件。
通常,DBMS 包含以下元素:
-
• 内核代码(Kernel code):此代码管理 DBMS 的内存和存储。 -
• 元数据存储库(Repository of metadata):该存储库通常称为数据字典(Data Dictionary)。 -
• 查询语言(Query language):此语言使应用程序能够访问数据。
数据库应用程序(Database Application)是一个与数据库交互以访问和操作数据的软件程序。
第一代数据库管理系统包括以下类型:
-
• 层次型(Hierarchical):层次型数据库(Hierarchical Database)以树形结构组织数据。每个父记录有一个或多个子记录,类似于文件系统的结构。 -
• 网状型(Network):网状型数据库(Network Database)类似于层次型数据库,但记录之间是多对多关系而非一对多关系。
前述数据库管理系统将数据存储在僵化的、预先确定的关系中。由于不存在数据定义语言,更改数据结构非常困难。此外,这些系统缺乏简单的查询语言,这阻碍了应用程序开发。
Relational Model(关系模型)
在其开创性的 1970 年论文《A Relational Model of Data for Large Shared Data Banks》中,E. F. Codd 基于数学集合论定义了关系模型。如今,最广泛接受的数据库模型是关系模型。
关系型数据库(Relational Database)是符合关系模型的数据库。关系模型具有以下主要方面:
-
• 结构(Structures):定义明确的对象用于存储或访问数据库的数据。 -
• 操作(Operations):定义清晰的操作使应用程序能够操作数据库的数据和结构。 -
• 完整性规则(Integrity rules):完整性规则管控对数据库数据和结构进行的操作。
关系型数据库将数据存储在一组简单的关系中。关系(Relation)是一组元组。元组(Tuple)是一组无序的属性值。
表(Table)是关系以行(元组)和列(属性)形式的二维表示。表中的每一行都拥有相同的列集合。关系型数据库是将数据存储在关系(表)中的数据库。例如,一个关系型数据库可以将公司员工的信息存储在 employee 表、department 表和 salary 表中。
相关主题:
-
• 《A Relational Model of Data for Large Shared Data Banks》by E.F. Codd
Relational Database Management System (RDBMS)(关系型数据库管理系统(RDBMS))
关系模型是关系型数据库管理系统(RDBMS,Relational Database Management System)的基础。RDBMS 将数据移入数据库、存储数据并检索数据,以便应用程序可以操作数据。
RDBMS 区分以下类型的操作:
-
• 逻辑操作(Logical operations):在这种情况下,应用程序指定“需要什么内容”。例如,应用程序请求一个员工姓名或将一条员工记录添加到表中。 -
• 物理操作(Physical operations):在这种情况下,RDBMS 决定“应该如何完成”并执行操作。例如,在应用程序查询一个表之后,数据库可能使用索引来查找请求的行,将数据读入内存,并在向用户返回结果之前执行许多其他步骤。RDBMS 存储和检索数据,使得物理操作对数据库应用程序是透明的。
Oracle AI 数据库是一个 RDBMS。一种实现了面向对象特性(如用户定义类型、继承和多态)的 RDBMS 被称为对象关系型数据库管理系统(ORDBMS,Object-Relational Database Management System)。Oracle AI 数据库已将关系模型扩展为对象关系模型,从而可以在关系型数据库中存储复杂的业务模型。
Schema Objects(模式对象)
RDBMS 的一个特征在于物理数据存储与逻辑数据结构的独立性。
在 Oracle AI 数据库中,数据库模式(Database Schema)是一组逻辑数据结构,即模式对象。一个数据库用户拥有一个数据库模式,该模式具有与该用户名相同的名称。
模式对象是用户创建的、直接引用数据库中数据的结构。数据库支持多种类型的模式对象,其中最重要的是表和索引。
模式对象是数据库对象(Database Object)的一种类型。某些数据库对象(如配置文件(Profile)和角色(Role))并不驻留在模式中。
-
• Tables(表):表描述某个实体,例如员工。 -
• Indexes(索引):索引(Index)是一种可选的数据结构,可以在表的一个或多个列上创建。索引可以提高数据检索的性能。
相关主题:
-
• Introduction to Schema Objects(模式对象简介)
Tables(表)
表描述某个实体,例如员工。
您通过指定表名(如 employees)和一组列来定义一个表。通常,在创建表时,您为每个列(Column)指定一个名称、一种数据类型(Data Type)和一个宽度。
表是一组行。列标识由该表描述的实体的一个属性,而行标识该实体的一个实例。例如,employees 实体的属性对应于员工 ID 和姓氏的列。某一行标识某个特定的员工。
您可以选择为某列指定一条规则,称为完整性约束(Integrity Constraint)。一个示例是 NOT NULL 完整性约束。此约束强制该列在每一行中都必须包含一个值。
相关主题:
-
• Overview of Tables(表概述) -
• Data Integrity(数据完整性)
Indexes(索引)
索引(Index)是一种可选的数据结构,可以在表的一个或多个列上创建。索引可以提高数据检索的性能。
在处理请求时,数据库可以使用可用的索引高效地定位被请求的行。当应用程序经常查询特定的行或行的范围时,索引非常有用。
索引在逻辑上和物理上都独立于数据。因此,您可以删除和创建索引,而对表或其他索引没有影响。删除索引后,所有应用程序仍可继续运行。
相关主题:
-
• Introduction to Indexes(索引简介)
Data Access(数据访问)
DBMS 的一项普遍要求是遵循公认的行业数据访问语言标准。
注意:JavaScript 要求在运行 Linux x86-64 或 Linux aarch64 的 Oracle 26ai 上使用。
-
• Structured Query Language (SQL)(结构化查询语言(SQL)) -
• PL/SQL, Java, and JavaScript(PL/SQL、Java 和 JavaScript)
Structured Query Language (SQL)(结构化查询语言(SQL))
SQL 是一种基于集合的声明式语言,为诸如 Oracle AI 数据库这样的 RDBMS 提供接口。
诸如 C 语言这样的过程式语言描述“应该如何完成”。SQL 是非过程式的,描述“应该完成什么”。
SQL 是关系型数据库的 ANSI 标准语言。对 Oracle 数据库中数据的所有操作都通过 SQL 语句执行。例如,您使用 SQL 创建表、查询和修改表中的数据。
一条 SQL 语句可以被看作一个非常简单但功能强大的计算机程序或指令。用户指定他们想要的结果(例如,员工的名字),而不是如何得出它。一条 SQL 语句是这样的一段 SQL 文本字符串:
SELECT first_name, last_name FROM employees;SQL 语句使您能够执行以下任务:
-
• 查询数据 -
• 插入、更新和删除表中的行 -
• 创建、替换、更改和删除对象 -
• 控制对数据库及其对象的访问 -
• 保证数据库的一致性和完整性
SQL 将上述所有任务统一在一种一致的语言中。Oracle SQL 是对 ANSI 标准的实现。Oracle SQL 支持许多超出标准 SQL 的功能。
相关主题:
-
• SQL
PL/SQL, Java, and JavaScript(PL/SQL、Java 和 JavaScript)
PL/SQL 是对 Oracle SQL 的过程式扩展。Java 和 JavaScript 是您可用来在数据库中存储业务逻辑的其他选项。
PL/SQL 与 Oracle AI 数据库集成,使您能够使用所有 Oracle AI 数据库 SQL 语句、函数和数据类型。您可以使用 PL/SQL 来控制 SQL 程序的流程、使用变量以及编写错误处理过程。
PL/SQL 的一个主要好处是能够将应用程序逻辑存储在数据库本身中。PL/SQL 过程(Procedure)或函数(Function)是一个模式对象,它由一组 SQL 语句和其他 PL/SQL 构造组成,这些构造组合在一起,存储在数据库中,并作为一个单元运行以解决特定问题或执行一组相关任务。服务器端编程的主要好处是内置功能可以部署在任何地方。
Oracle AI 数据库还可以存储用 Java 和 JavaScript 编写的程序单元。Java 存储过程是一个 Java 方法,它被发布给 SQL 并存储在数据库中供一般使用。您可以从 Java 和 JavaScript 调用现有的 PL/SQL 程序,也可以从 PL/SQL 调用 Java 和 JavaScript 程序。
多语言引擎(MLE,Multilingual Engine)为您提供了使用 JavaScript 编写业务逻辑并将代码作为 MLE 模块存储在数据库中的能力。由 MLE 模块导出的函数可以通过调用规范(Call Specifications)暴露给 SQL 和 PL/SQL。这些调用规范是 PL/SQL 单元(函数、过程和包),可以在任何调用 PL/SQL 的地方调用。
相关主题:
-
• Server-Side Programming: PL/SQL, Java, and JavaScript(服务器端编程:PL/SQL、Java 和 JavaScript) -
• Choosing a Programming Environment(选择编程环境)
Transaction Management(事务管理)
Oracle AI 数据库被设计为多用户数据库。该数据库必须确保多个用户可以并发工作,而不会破坏彼此的数据。
-
• Transactions(事务) -
• Data Concurrency(数据并发) -
• Data Consistency(数据一致性)
Transactions(事务)
事务(Transaction)是一个包含一条或多条 SQL 语句的逻辑的、原子的工作单元。
RDBMS 必须能够将 SQL 语句分组,使得它们要么全部提交,即应用到数据库,要么全部回滚,即被撤销。
说明事务必要性的一个示例是从储蓄账户到支票账户的资金转账。该转账由以下独立操作组成:
-
1. 减少储蓄账户金额。 -
2. 增加支票账户金额。 -
3. 在事务日志中记录该事务。
Oracle AI 数据库保证所有这三个操作作为一个单元要么全部成功,要么全部失败。例如,如果硬件故障导致事务中的某条语句无法执行,那么其他语句必须回滚。
事务是使 Oracle AI 数据库有别于文件系统的一个特性。如果您执行一个更新多个文件的原子操作,并且系统中途失败,那么这些文件将不一致。相反,事务将 Oracle 数据库从一个一致状态转移到另一个一致状态。事务的基本原则是“要么全做,要么全不做”:一个原子操作作为一个整体成功或失败。
相关主题:
-
• Transactions(事务)
Data Concurrency(数据并发)
多用户 RDBMS 的一个要求是控制数据并发(Data Concurrency),即多个用户对同一数据的同时访问。
如果没有并发控制,用户可能会不正确地更改数据,从而危害数据完整性(Data Integrity)。例如,一个用户可能更新某行,而另一个不同的用户同时也在更新它。
如果多个用户访问同一数据,那么管理并发的一种方法是让用户等待。然而,DBMS 的目标是减少等待时间,使其要么不存在,要么可以忽略不计。所有修改数据的 SQL 语句必须尽可能少地受到干扰。必须避免破坏性交互,即那些错误更新数据或更改底层数据结构的交互。
Oracle AI 数据库使用锁来控制对数据的并发访问。锁(Lock)是一种防止访问共享资源的事务之间发生破坏性交互的机制。锁有助于确保数据完整性,同时允许最大程度地并发访问数据。
相关主题:
-
• Overview of the Oracle Database Locking Mechanism(Oracle 数据库锁定机制概述)
Data Consistency(数据一致性)
在 Oracle AI 数据库中,每个用户必须看到一个一致的数据视图,包括用户自己的事务所做的可见更改以及其他用户已提交的事务。
例如,数据库必须防止脏读(Dirty Read)问题,即一个事务看到另一个并发事务未提交的更改。
Oracle AI 数据库始终强制执行语句级读一致性(Statement-Level Read Consistency),这保证单个查询返回的数据对于单个时间点而言是已提交且一致的。根据事务隔离级别的不同,该时间点可以是语句打开的时间或事务开始的时间。Oracle 闪回查询(Flashback Query)功能使您可以显式指定此时间点。
数据库还可以为事务中所有查询提供读一致性,这被称为事务级读一致性(Transaction-Level Read Consistency)。在这种情况下,事务中的每条语句看到的数据都来自同一个时间点,即事务开始的时间。
相关主题:
-
• Data Concurrency and Consistency(数据并发与一致性) -
• Using Oracle Flashback Query (SELECT AS OF)(使用 Oracle 闪回查询(SELECT AS OF))
Oracle AI Database Architecture(Oracle AI 数据库体系结构)
数据库服务器(Database Server)是信息管理的关键。
通常,服务器(Server)在多用户环境中可靠地管理大量数据,以便用户可以并发地访问相同的数据。数据库服务器还可以防止未经授权的访问,并为故障恢复提供高效的解决方案。
-
• Database and Instance(数据库与实例) -
• Database Storage Structures(数据库存储结构) -
• Database Instance Structures(数据库实例结构) -
• Application and Networking Architecture(应用程序与网络体系结构)
Database and Instance(数据库与实例)
一个 Oracle 数据库服务器由一个数据库和至少一个数据库实例(Database Instance)(通常简称为实例)组成。
因为实例和数据库联系如此紧密,“Oracle 数据库”这个术语有时同时指实例和数据库。在最严格的意义上,这些术语具有以下含义:
-
• 数据库(Database):数据库是一组位于磁盘上、存储用户数据的文件。这些数据文件可以独立于数据库实例存在。从 Oracle Database 21c 开始,“数据库”特指多租户容器数据库(CDB,Multitenant Container Database)、可插入数据库(PDB,Pluggable Database)或应用程序容器(Application Container)的数据文件。 -
• 数据库实例(Database instance):实例是一个命名的内存结构集合,用于管理数据库文件。数据库实例由一个称为系统全局区(SGA,System Global Area)的共享内存区域和一组后台进程组成。实例可以独立于数据库文件存在。 -
• Multitenant Architecture(多租户体系结构) -
• Globally Distributed Database Architecture(全局分布式数据库体系结构)
Multitenant Architecture(多租户体系结构)
多租户体系结构(Multitenant Architecture)使 Oracle AI 数据库能够成为一个 CDB。
每个 Oracle AI 数据库必须包含或能够被另一个数据库包含。例如,一个 CDB 包含 PDB,一个应用程序容器包含应用程序 PDB。PDB 被 CDB 或应用程序容器包含,应用程序容器被 CDB 包含。
从 Oracle Database 21c 开始,多租户容器数据库是唯一受支持的体系结构。在以前的版本中,Oracle 支持非容器数据库(non-CDB)。
-
• CDBs(CDB):CDB 包含一个或多个用户创建的 PDB 和应用程序容器。 -
• PDBs(PDB):PDB 是模式、模式对象和非模式对象的可移植集合,对应用程序而言表现为一个独立的数据库。 -
• Application Containers(应用程序容器):应用程序容器(Application Container)是 CDB 内可选的、用户创建的容器,用于存储一个或多个应用程序的数据和元数据。
CDBs(CDB)
CDB 包含一个或多个用户创建的 PDB 和应用程序容器。
在物理层面,CDB 是一组文件:控制文件、联机重做日志文件和数据文件。数据库实例管理构成 CDB 的文件。
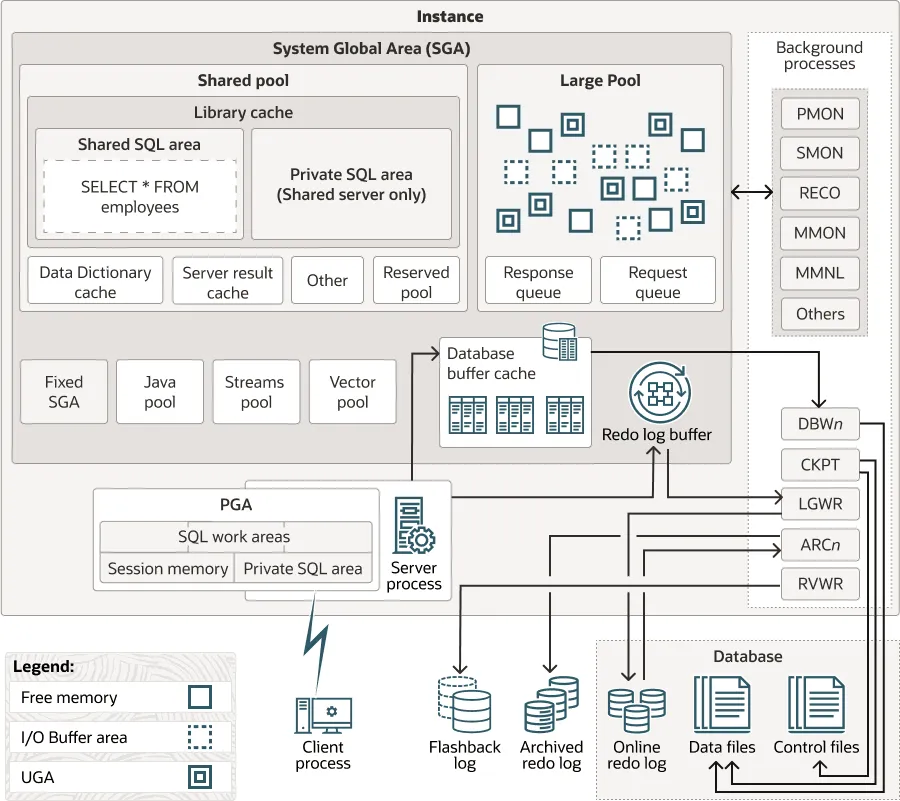
下图显示了一个 CDB 及其关联的数据库实例。
Figure 1-1 Database Instance and CDB(图 1-1 数据库实例与 CDB)
PDBs(PDB)
PDB 是模式、模式对象和非模式对象的可移植集合,对应用程序而言表现为一个独立的数据库。
在物理层面,每个 PDB 都有自己的一组数据文件,用于存储该 PDB 的数据。CDB 包含了其中所有 PDB 的全部数据文件,以及一组用于存储 CDB 自身元数据的系统数据文件。
要移动或归档一个 PDB,您可以将其拔下(Unplug)。一个已拔下的 PDB 由 PDB 数据文件和一个元数据文件组成。一个已拔下的 PDB 在插入(Plug in)某个 CDB 之前不可用。
下图显示了一个名为 MYCDB 的 CDB。
Figure 1-2 PDBs in a CDB(图 1-2 CDB 中的 PDB)
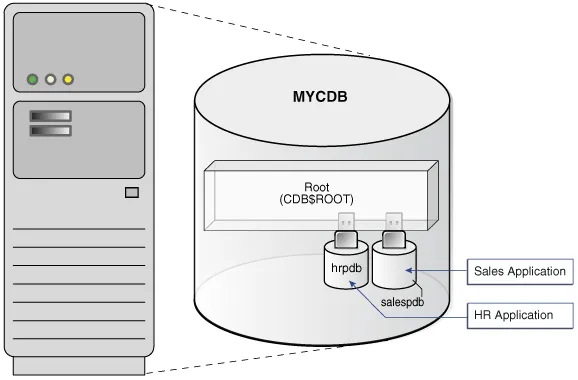
从物理上讲,MYCDB 是一个 Oracle AI 数据库,也就是说它是与一个实例关联的一组数据文件。MYCDB 有一个数据库实例(尽管在 Oracle 真正应用集群中可能有多个实例),以及一组数据库文件。
MYCDB 包含两个 PDB:hrpdb 和 salespdb。如图 1-2 所示,这些 PDB 对它们各自的应用程序而言表现为独立的、分立的数据库。应用程序不知道它连接的是 CDB 还是 PDB。
要管理 CDB 本身或其中的任何 PDB,您可以连接到 CDB 根容器(CDB Root)。根容器是所有 PDB 和应用程序容器所属的模式、模式对象和非模式对象的集合。
Application Containers(应用程序容器)
应用程序容器(Application Container)是 CDB 内可选的、用户创建的容器,用于存储一个或多个应用程序的数据和元数据。
在此上下文中,应用程序(Application)(也称为主应用程序定义(Master Application Definition))是存储在应用程序根容器(Application Root)中的一个命名、带版本号的公用数据和元数据集合。例如,该应用程序可能包含对表、视图、用户账户以及 PL/SQL 包的定义,这些定义为一组 PDB 所公用。
在某些方面,应用程序容器的功能类似于 CDB 内部的一个特定于应用程序的 CDB。与 CDB 本身一样,一个应用程序容器可以包含多个应用程序 PDB,并使这些 PDB 能够共享元数据和数据。在物理层面,应用程序容器拥有自己的一组数据文件,就像 PDB 一样。
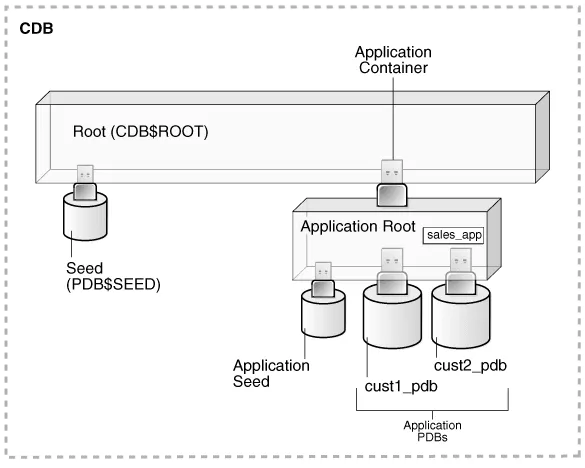
例如,一个 SaaS 部署可以使用多个应用程序 PDB,每个对应一个不同的客户,它们共享应用程序元数据和数据。举例来说,在下图中,sales_app 是应用程序根中的应用程序模型。名为 cust1_pdb 的应用程序 PDB 仅包含客户 1 的销售数据,而名为 cust2_pdb 的应用程序 PDB 仅包含客户 2 的销售数据。拔下、插入、克隆和其他 PDB 级操作对各个客户 PDB 可用。
Figure 1-3 SaaS Use Case(图 1-3 SaaS 用例)
Globally Distributed Database Architecture(全局分布式数据库体系结构)
Oracle 全局分布式数据库(Globally Distributed Database,以前称为 Oracle Sharding)是一种基于跨多个 PDB 水平分区数据的数据可伸缩性技术。应用程序将 PDB 池感知为单个逻辑数据库。每个分区称为一个分片(Shard)。
分片对应用程序的主要好处包括线性可伸缩性、故障隔离和地理数据分布。全局分布式数据库非常适合在 Oracle 云中部署。与实现分片的 NoSQL 数据存储不同,全局分布式数据库在不牺牲企业级 RDBMS 能力的情况下提供了分片的好处。
在分片体系结构中,每个 CDB 都托管在具有其自身本地资源(CPU、内存、闪存或磁盘)的专用服务器上。您可以将一个 PDB 指定为一个分片。来自不同 CDB 的 PDB 分片构成了一个单一的逻辑数据库,这被称为分片数据库(Sharded Database)。同一个 CDB 中的两个分片不能是同一个分片数据库的成员。然而,在同一个 CDB 内,一个 PDB 可以在一个分片数据库中,而另一个 PDB 可以在另一个独立的分片数据库中。
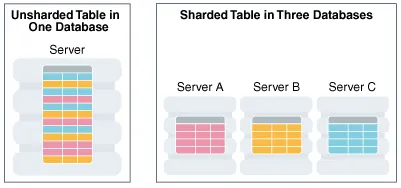
水平分区涉及将数据库表拆分到各个分片上,使得每个分片都包含具有相同列但不同行子集的表。以这种方式拆分的表也称为分片表(Sharded Table)。下图显示了一个水平分区到三个分片的分片表,每个分片都是独立 CDB 中的一个 PDB。
Figure 1-4 Horizontal Partitioning of a Table Across Shards(图 1-4 跨分片的表水平分区)
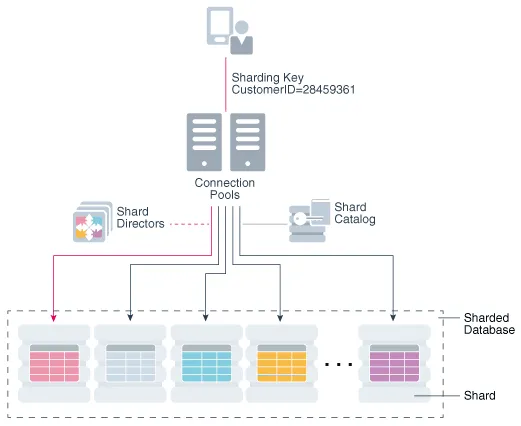
一个用例是将客户账户数据分布到多个 CDB 上。例如,ID 为 28459361 的客户可以查找他的记录。下图显示了一种可能的体系结构。客户端请求通过连接池路由,其中分片导向器(网络监听器)将请求定向到相应的 PDB 分片,该分片包含所有客户行。
Figure 1-5 Oracle Globally Distributed Database Architecture(图 1-5 Oracle 全局分布式数据库体系结构)
相关主题:
-
• Oracle Globally Distributed AI Database(Oracle 全局分布式 AI 数据库)
Database Storage Structures(数据库存储结构)
可以从物理和逻辑两个视角来看待数据库。
物理数据是在操作系统级别可见的数据。例如,诸如 Linux 的 ls 和 ps 等操作系统实用程序可以列出数据库文件和进程。逻辑数据(如表)仅对数据库有意义。一条 SQL 语句可以列出 Oracle 数据库中的表,但操作系统实用程序不能。
数据库具有物理结构和逻辑结构。由于物理结构和逻辑结构是分离的,您可以管理数据的物理存储,而不会影响对逻辑存储结构的访问。例如,重命名一个物理数据库文件不会重命名其数据存储在该文件中的那些表。
-
• Physical Storage Structures(物理存储结构):物理数据库结构是存储数据的文件。 -
• Logical Storage Structures(逻辑存储结构):逻辑存储结构使 Oracle AI 数据库能够细粒度地控制磁盘空间使用。
Physical Storage Structures(物理存储结构)
物理数据库结构是存储数据的文件。
当您执行 CREATE DATABASE 命令时,您就创建了一个 CDB。将创建以下文件:
-
• 数据文件(Data files):无论何种 CDB,都有一个或多个物理数据文件,这些文件包含所有数据库数据。逻辑数据库结构(如表和索引)的数据在物理上存储在这些数据文件中。 -
• 控制文件(Control files):无论何种 CDB,都有一个控制文件(Control File)。控制文件包含指定数据库物理结构的元数据,包括数据库名称以及数据库文件的名称和位置。 -
• 联机重做日志文件(Online redo log files):无论何种 CDB,都有一个联机重做日志(Online Redo Log),它是一组两个或多个联机重做日志文件。联机重做日志由重做条目(Redo Entries)(也称为重做日志记录)组成,这些条目记录了对数据所做的所有更改。
当您在 CDB 内执行 CREATE PLUGGABLE DATABASE 命令时,就创建了一个 PDB。该 PDB 包含 CDB 内的一组专用数据文件。PDB 没有单独的、专用的控制文件和联机重做日志:这些文件由各个 PDB 共享。
许多其他文件对于 CDB 的运行也很重要。这些文件包括参数文件和网络文件。备份文件和归档重做日志文件是对备份和恢复很重要的离线文件。
相关主题:
-
• Physical Storage Structures(物理存储结构)
另请参见:
-
• “Physical Storage Structures”(物理存储结构)
Logical Storage Structures(逻辑存储结构)
逻辑存储结构使 Oracle AI 数据库能够细粒度地控制磁盘空间使用。
本主题讨论逻辑存储结构:
-
• 数据块(Data blocks):在最细粒度的级别上,Oracle AI 数据库数据存储在数据块中。一个数据块(Data Block)对应于磁盘上特定数量的字节。 -
• 区(Extents):区(Extent)是特定数量的逻辑上连续的数据块,在单次分配中获得,用于存储特定类型的信息。 -
• 段(Segments):段(Segment)是为用户对象(例如表或索引)、撤销数据(Undo Data)或临时数据分配的一组区。 -
• 表空间(Tablespaces):数据库被划分为称为表空间的逻辑存储单元。表空间(Tablespace)是段的逻辑容器。每个表空间至少由一個数据文件组成。
相关主题:
-
• Logical Storage Structures(逻辑存储结构)
Database Instance Structures(数据库实例结构)
Oracle 数据库使用内存结构和进程来管理和访问 CDB。所有内存结构都存在于构成 RDBMS 的计算机的主内存中。
当应用程序连接到 CDB 或 PDB 时,它们会连接到一个数据库实例(Database Instance)。该实例通过分配除 SGA 之外的其他内存区域,并启动除后台进程之外的其他进程,来为应用程序提供服务。
-
• Oracle AI Database Processes(Oracle AI 数据库进程) -
• Instance Memory Structures(实例内存结构)
Oracle AI Database Processes(Oracle AI 数据库进程)
进程(Process)是操作系统中可以运行一系列步骤的机制。有些操作系统使用术语作业(Job)、任务(Task)或线程(Thread)。
就本主题而言,线程等同于进程。一个 Oracle 数据库实例具有以下类型的进程:
-
• 客户端进程(Client processes):这些进程被创建和维护,用于运行应用程序或 Oracle 工具的软件代码。大多数环境中,客户端进程运行在独立的计算机上。 -
• 后台进程(Background processes):这些进程整合了原本由针对每个客户端进程运行的多个 Oracle AI 数据库程序处理的功能。后台进程异步执行 I/O 并监控其他 Oracle AI 数据库进程,以提供更高的并行度,从而获得更好的性能和可靠性。 -
• 服务器进程(Server processes):这些进程与客户端进程通信,并与 Oracle AI 数据库交互以完成请求。
Oracle 进程包括服务器进程和后台进程。在大多数环境中,Oracle 进程和客户端进程运行在不同的计算机上。
相关主题:
-
• Process Architecture(进程体系结构)
Instance Memory Structures(实例内存结构)
Oracle AI 数据库创建并使用内存结构,用于程序代码、用户间共享的数据以及为每个连接用户提供的私有数据区域。
以下内存结构与数据库实例关联:
-
• 系统全局区(SGA):SGA 是一组共享内存结构,包含一个数据库实例的数据和控制信息。SGA 组件的示例包括数据库缓冲区高速缓存和共享 SQL 区域。SGA 可以包含可选的 In-Memory 列存储(IM 列存储),它使数据能够以列格式(Columnar Format)填充到内存中。 -
• 程序全局区(PGA):PGA 是一个内存区域,包含服务器进程或后台进程的数据和控制信息。对 PGA 的访问是该进程独占的。每个服务器进程和后台进程都有自己的 PGA。
相关主题:
-
• Memory Architecture(内存体系结构)
Application and Networking Architecture(应用程序与网络体系结构)
为了充分利用给定的计算机系统或网络,Oracle AI 数据库支持在数据库服务器和客户端程序之间拆分处理。运行 RDBMS 的计算机处理数据库服务器的职责,而运行应用程序的计算机处理数据的解释和显示。
-
• Application Architecture(应用程序体系结构) -
• Oracle Net Services Architecture(Oracle Net Services 体系结构)
Application Architecture(应用程序体系结构)
应用程序体系结构是数据库应用程序连接到 Oracle 数据库的计算环境。两种最常见的数据库体系结构是客户端/服务器和多层。
客户端/服务器体系结构(Client-Server Architecture)在客户端/服务器体系结构中,客户端应用程序发起在数据库服务器上执行操作的请求。服务器运行 Oracle AI 数据库软件,并处理并发、共享数据访问所需的功能。服务器接收和处理来自客户端的请求。
多层体系结构(Multitier Architecture)在多层体系结构中,一个或多个应用程序服务器执行部分操作。应用程序服务器(Application Server)包含大部分应用程序逻辑,为客户端提供对数据的访问,并执行某些查询处理。通过这种方式,数据库上的负载得以降低。应用程序服务器可以充当客户端与多个数据库之间的接口,并提供额外级别的安全性。
面向服务的体系结构(SOA,Service-Oriented Architecture)是一种多层体系结构,其中应用程序功能被封装在服务中。SOA 服务通常作为 Web 服务实现。Web 服务可通过 HTTP 访问,并基于诸如 Web Services Description Language (WSDL) 和 SOAP 等基于 XML 的标准。Oracle AI 数据库可以在传统的多层或 SOA 环境中充当 Web 服务提供者。
简单 Oracle 文档访问(SODA,Simple Oracle Document Access)是 SOA 的一种变体,使您能够访问存储在数据库中的数据。SODA 专为无模式应用程序开发而设计,无需关系型数据库特性或诸如 SQL 和 PL/SQL 等语言的知识。您可以在 Oracle AI 数据库中创建和存储文档集合、检索它们并查询它们,而无需了解这些文档是如何存储的。SODA for REST 使用表述性状态转移(REST)架构风格来实现 SODA。
相关主题:
-
• Overview of Multitier Architecture(多层体系结构概述) -
• Native Oracle XML DB Web Services(原生 Oracle XML DB Web 服务)
Oracle Net Services Architecture(Oracle Net Services 体系结构)
Oracle Net Services 是数据库与网络通信协议之间的接口,这些协议促进了分布式处理和分布式数据库。
通信协议定义了数据在网络上的传输和接收方式。Oracle Net Services 支持所有主要网络协议上的通信,包括 TCP/IP、HTTP、FTP 和 WebDAV。
Oracle Net(Oracle Net Services 的一个组件)在客户端应用程序和数据库服务器之间建立并维护网络会话。网络会话建立后,Oracle Net 充当客户端应用程序和数据库服务器两者的数据信使,在它们之间交换消息。Oracle Net 能够执行这些工作,因为它位于网络中的每台计算机上。
Net Services 的一个重要组件是 Oracle Net 监听器(Oracle Net Listener)(称为监听器(Listener)),它是一个运行在数据库上或网络中其他位置的进程。客户端应用程序向监听器发送连接请求,监听器管理流向数据库的这些请求的流量。当连接建立后,客户端和数据库直接通信。
将 Oracle 数据库配置为处理客户端请求的最常见的方式是:
-
• 专用服务器体系结构(Dedicated server architecture):每个客户端进程连接到一个专用服务器(Dedicated Server)进程。在客户端会话的持续期间,该服务器进程不被任何其他客户端共享。每个新会话都分配一个专用服务器进程。 -
• 共享服务器体系结构(Shared server architecture):数据库为多个会话使用一个共享服务器(Shared Server)进程池。客户端进程与调度器(Dispatcher)通信,调度器是一个进程,它使许多客户端能够连接到同一个数据库实例,而无需为每个客户端配备一个专用服务器进程。
相关主题:
-
• Overview of Oracle Net Services Architecture(Oracle Net Services 体系结构概述) -
• Understanding Oracle Net Architecture(了解 Oracle Net 体系结构) -
• WebDAV and Oracle XML DB(WebDAV 与 Oracle XML DB)