 夜雨聆风
夜雨聆风





不改模型,只改数据:用合成数据让文档版式分析提升2-4%

文档智能版式分析合成数据YOLO11MinerU
论文解读 · 2026年3月
一篇来自 Applied Sciences 的新论文,展示了如何通过优化合成数据生成策略,零成本提升 YOLO11 在文档版式分析任务上的表现——并已集成到开源文档解析工具 MinerU 中。
· · ·
背景:DLA 的数据困境
文档版式分析(Document Layout Analysis, DLA)是文档智能的基石——把一页 PDF 里的标题、段落、表格、图片等元素识别出来,是后续所有结构化处理的前提。
现在主流方案都是用目标检测模型来做,YOLO 系列、DETR 系列都有人用。模型架构卷得差不多了,大家发现一个尴尬的事实:瓶颈往往不在模型,而在数据。
高质量的文档版式标注数据贵、少、偏。PubLayNet 偏学术论文,DocLayNet 偏商业文档,拿一个场景的数据去训另一个场景,效果就打折。
那如果标注数据不够,能不能”造”数据?
· · ·
核心思路:形式化的合成数据生成
这篇论文的思路非常直接:与其苦哈哈地去标注,不如建一个数学模型来自动生成合成文档版式。
他们设计了一套形式化的生成框架,可以精确控制元素密度、尺寸和空间分布。下面是生成流程:
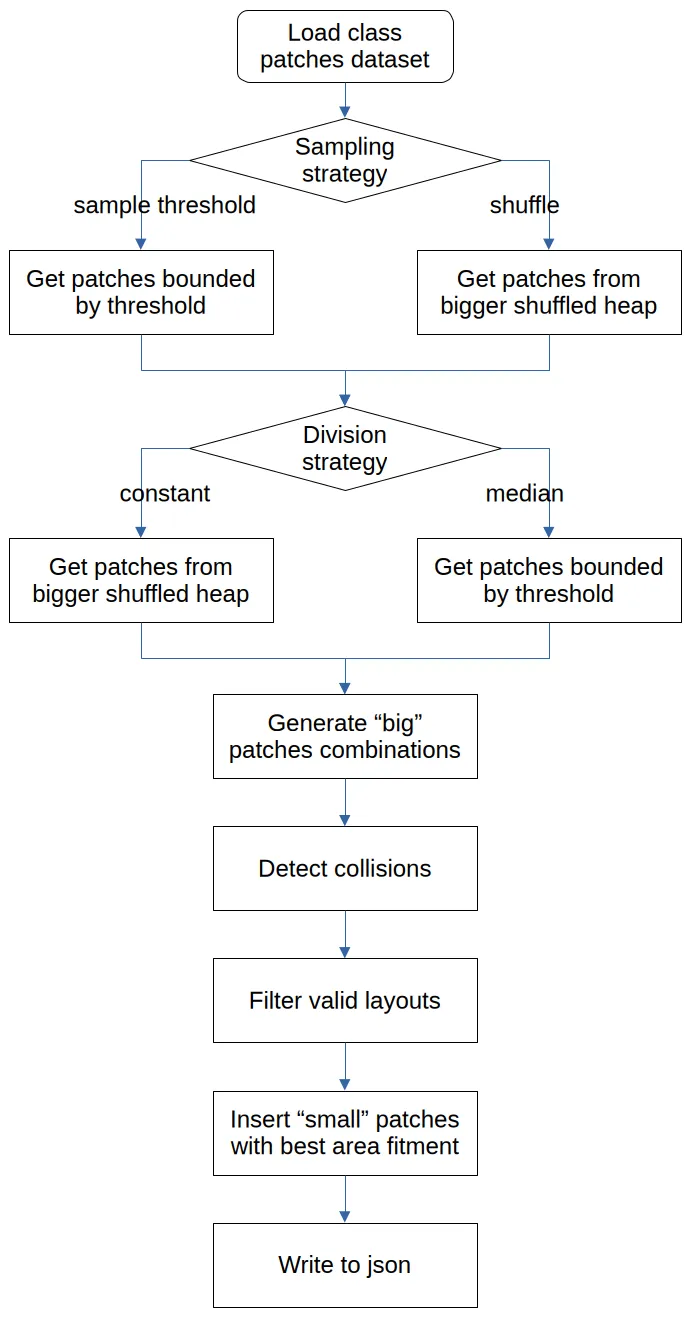
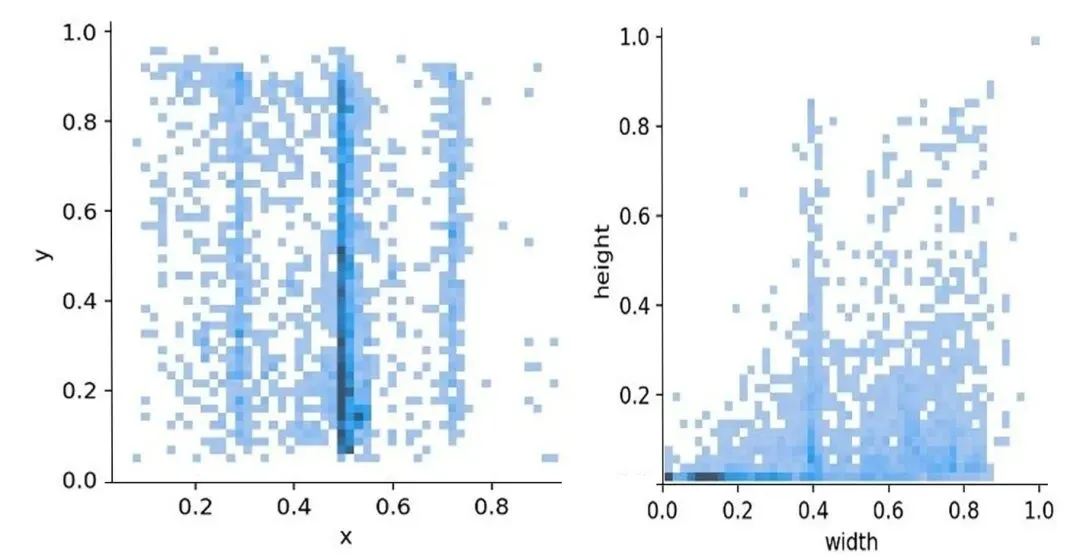
生成出来的是带有精确 bounding box 标注的版式数据——直接可以喂给检测模型训练。先来看一下数据集中元素的空间分布特征:
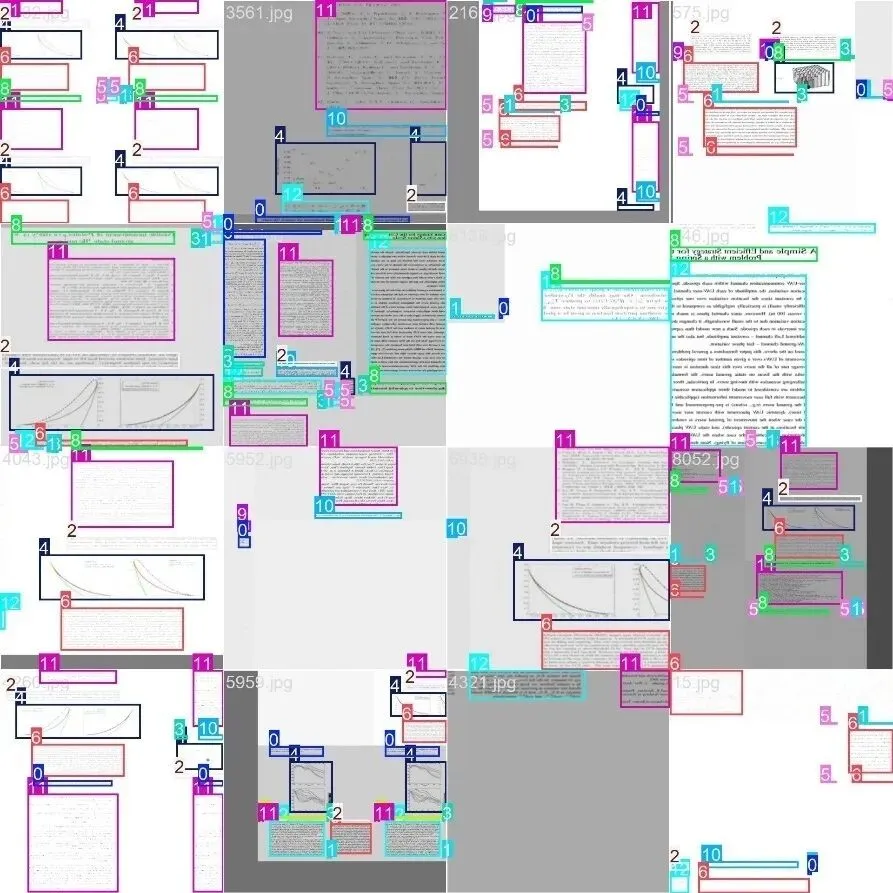
下面是合成数据的样本示例:
· · ·
关键发现:数据策略比数据量更重要
论文用 YOLO11m 作为检测模型,系统对比了多种合成数据策略。核心发现:
最佳策略:中位数分割 + 随机采样
|
|
|
|---|---|
|
|
+2~4% |
|
|
+2~4% |
|
|
+2~4% |
|
|
+2~4% |
💡 2-4% 看起来不多?在 DLA 这个任务上,模型 mAP 普遍 90+,能稳定提升 2-4% 而且不改任何模型结构,纯靠数据侧优化,性价比极高。
来看训练过程的 Precision 和 Recall 曲线对比:
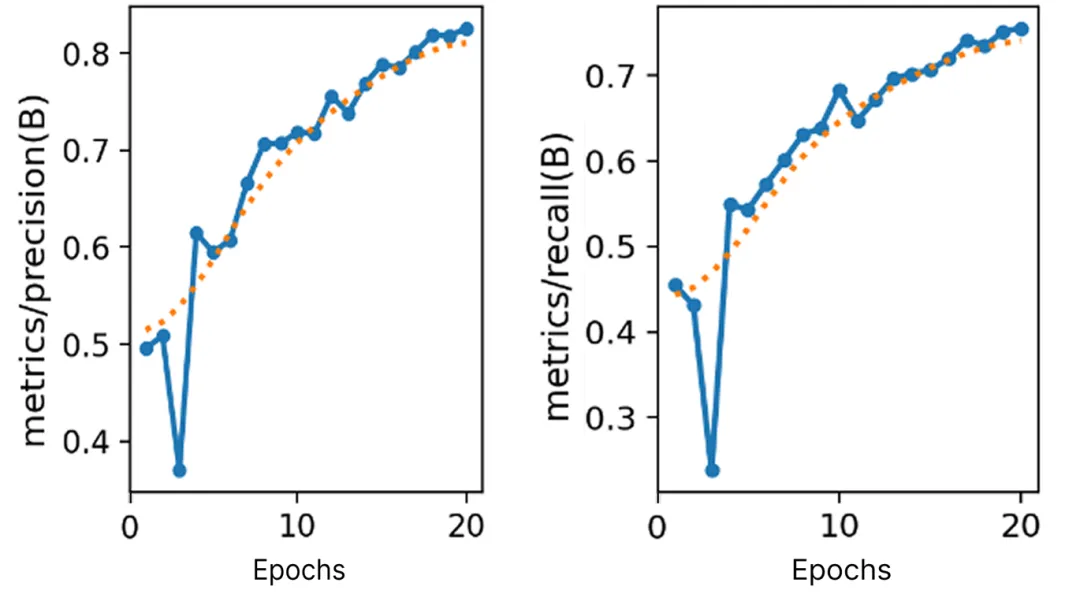
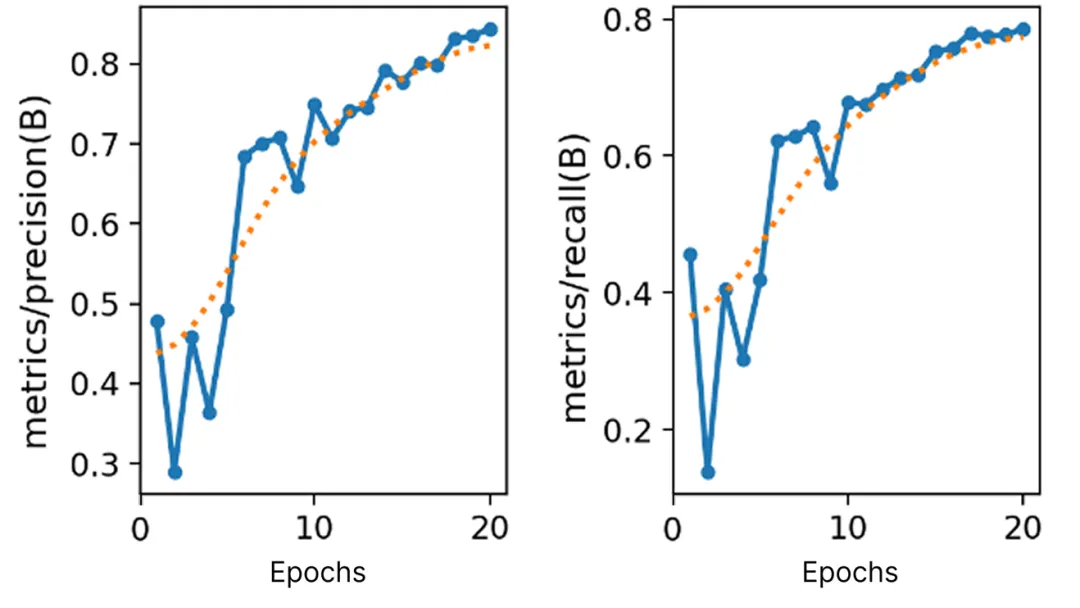
可以看到,使用优化后的合成数据策略,模型在训练早期就展现出更稳定的收敛趋势。
· · ·
已集成到 MinerU
最值得关注的是,这个方法已经集成到了 MinerU 中。

MinerU 是 OpenDataLab(上海人工智能实验室)开源的文档解析工具,在国内文档智能圈子里用的人不少。它的核心流程就是:版式检测 → OCR → 结构化输出。这篇论文的合成数据方法被用在了版式检测这一步。
🔥 这意味着:不是 paper 里的 toy experiment,而是在生产级工具中验证过的方法。
· · ·
启示
1. 数据工程 > 模型工程
在 DLA 这个相对成熟的任务上,换模型架构的边际收益越来越小。但数据侧的优化空间还很大——合成数据、数据增强、数据清洗,每一步都能带来实打实的提升。
2. 合成数据的”配方”很重要
不是随便生成一堆假数据就能提升效果。元素分割方式、采样策略这些看似细节的选择,决定了合成数据能不能真正帮助模型学到有用的东西。
3. 低成本、可复制的改进路径
如果你在做 DLA 相关的工作,这个方法几乎是”免费”的——不需要更大的模型、更多的 GPU,只需要在数据准备阶段多花点心思。
📄 论文信息
标题:Improving Document Layout Analysis Using Synthetic Data Generation and Convolutional Models
作者:O. Pronina, Tao Xia, K. Sheliah, O. Piatykop, V. Efremenko, E. Balalayeva
发表:Applied Sciences (MDPI), 2026
DOI:10.3390/app16063089