 夜雨聆风
夜雨聆风





51 万行源码的“技术裸奔”:从 Anthropic 泄露事件看生产级 Harness 架构的终极真相

在人工智能迈向通用智能(AGI)的征程中,工程化实践正在经历一场从“对话表达”向“系统构建”的底层范式跃迁。当大型语言模型(LLM)的定位从单纯的文本生成器或知识检索中枢,逐步演进为能够在复杂、动态的物理与数字环境中自主执行长周期任务的智能体(Autonomous Agents)时,开发者所面临的核心挑战发生了根本性的转移。这一挑战不再仅仅是模型是否具备足够的常识推理能力,而是整个系统能否在充满不确定性的现实业务交互中保持极高的稳定性、可靠性与容错率。正是这种对生产级确定性的极致追求,催生了人工智能工程学领域从提示工程(Prompt Engineering)、上下文工程(Context Engineering)到控制流工程(Harness Engineering)的系统性演进脉络。
本篇文章将立足于国际前沿的最新成果与顶尖开发者的深刻洞察,系统性地拆解这三大工程阶段的演进逻辑与内在关系。深入探究每一个编程模式的底层构成要素,详尽分析 OpenAI、Anthropic 以及 Google Gemini 在控制流工程领域的具体实践。此外,本文章还将结合 2026 年初轰动业界的 Anthropic 源代码泄露事件,对大规模生产环境下的 Harness 架构进行深度解剖,并对智能体工程的下一代形态(Next Morph)做出前瞻性的理论推演。
演进的认知逻辑:从单次博弈到确定性驾驭的系统级嵌套

人工智能交互模式的演进可以被精确地划分为三个具有明确继承与包含关系的阶段。这三者并非技术浪潮中相互替代的孤立产物,而是一种“嵌套与递进”的系统层级关系。正如著名人工智能学者安德烈·卡帕斯(Andrej Karpathy)所指出的,它们共同指向了“智能体工程(Agentic Engineering)”这一终极目标,即建立一种由人类设定结构化边界、由 AI 智能体负责规划与编码的全新专业软件开发方法论。
第一阶段:提示工程(2022-2024)—— 意图表达与概率收束
提示工程(Prompt Engineering)代表了交互演进的第一阶段,其核心时期集中在 2022 年至 2024 年之间。在这一阶段,工程实践的绝对焦点在于“表达(Expression)”,即致力于解决“模型是否能够准确理解人类意图”的表层问题 。提示工程的本质是一种语言设计,开发者通过角色扮演、结构化模板、少样本提示(Few-Shot)等手段,在大型语言模型极其庞大的参数矩阵中塑造和收束“概率空间”,从而引导模型输出最符合预期的 Token 序列 。然而,提示工程存在不可逾越的物理与逻辑上限。当面对诸如检索增强生成(RAG)或涉及多步外部工具调用的复杂现实任务时,单纯依赖系统提示词的优化会迅速触及性能天花板。如果仅仅停留在这一层级,开发者往往会陷入被称为“祈祷式编程(Vibe Coding)”的窘境,即抛出一段复杂的提示词,然后完全依赖大模型的黑盒概率来祈祷一个正确的结果,这种缺乏系统反馈的模式显然无法适应严苛的生产环境。
第二阶段:上下文工程(2025)—— 信息密度的动态管控
随着任务复杂度的提升,行业自然过渡到了第二阶段,即上下文工程(Context Engineering,2025年)。这一阶段的核心关注点从意图表达转向了“信息(Information)”密度的管理,旨在解决“模型是否在正确的时间点拥有足够且正确的数据”这一关键命题 。在长程多轮交互中,模型要做出明智的决策,需要一个被动态构建、精心裁剪的上下文窗口,里面需要精准填满相关的文档切片、历史对话记录、工具定义以及实时的环境状态反馈 。上下文工程确立了一个极为严苛的资源管理法则,即“每一个 Token 都必须为留在提示词中而战斗”,冗余或带有噪声的上下文与信息缺失一样,都会对模型的推理能力造成毁灭性打击。
为了更加直观地理解上下文工程在企业级智能体系统中的应用,我们可以将其映射到一个多层级的数据架构体系中。在构建分析型人工智能时,上下文被严格划分为多个层级(Tier),以反映数据对 AI 的可访问性与完整性。
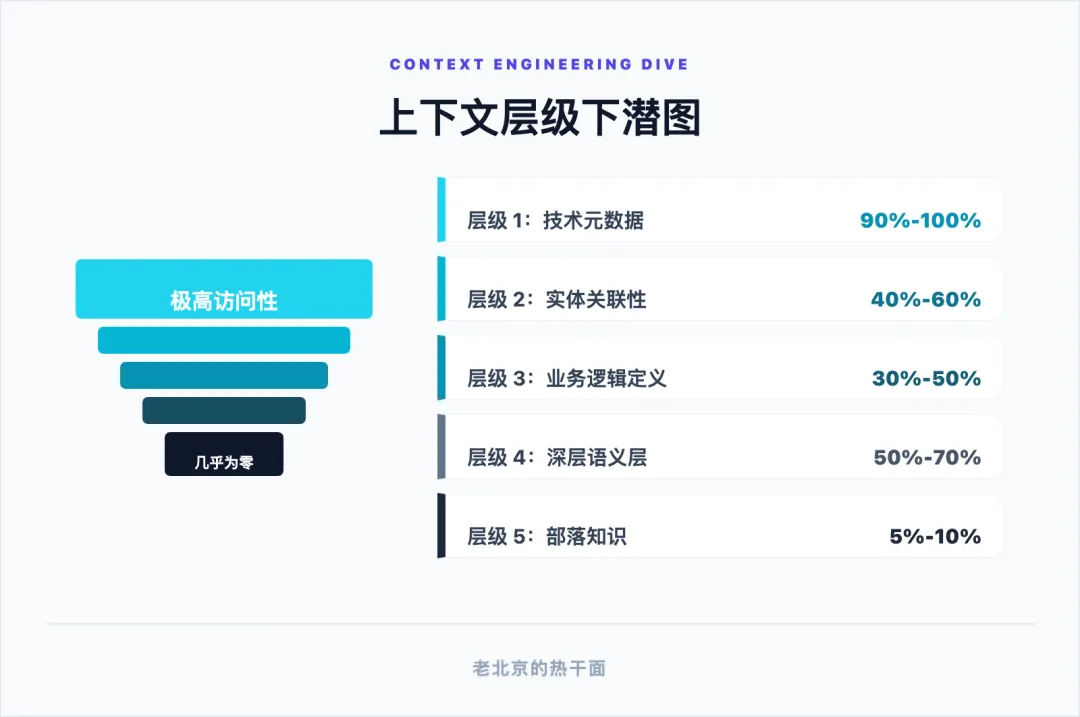
如上图所示,上下文工程的难点在于,尽管底层技术元数据极易获取,但真正决定智能体业务判断能力的深层语义和部落知识却极难被有效提取和结构化注入 。这要求开发者不仅要管理文本,还要建立复杂的向量检索和图数据库,以弥合数据断层。
第三阶段:控制流工程(2026+)—— 确定性执行的系统驾驭
然而,即便拥有了完美的提示词和充沛的上下文信息,当智能体被投入到需要连续执行数百个独立动作的真实世界时,系统依然会面临崩溃。这就引出了第三阶段,也是当前最前沿的范式——控制流工程(Harness Engineering,2026年及以后)。如果说前两者解决的是“懂不懂”和“知不知”的问题,那么控制流工程解决的则是最终的“执行能力(Execution)”,即“模型在连续的物理或数字世界交互中,能否持续、稳定且正确地完成工作”。
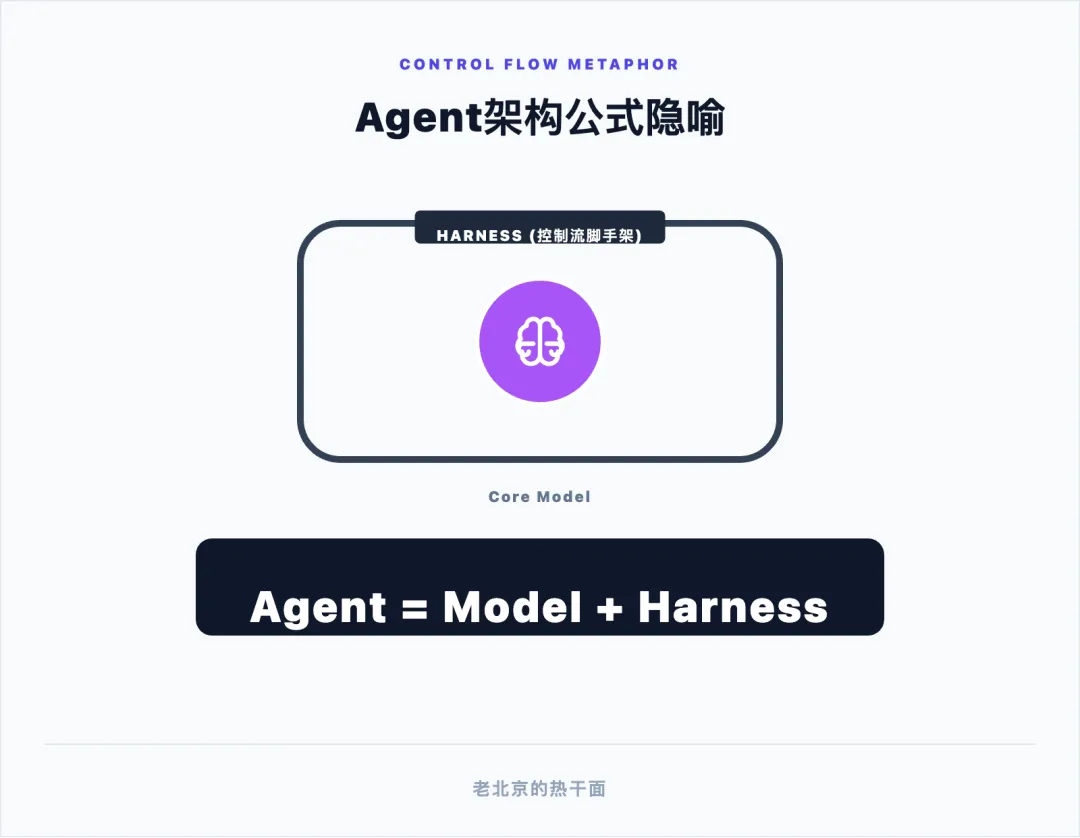
控制流工程(Harness Engineering)这一术语源自物理世界中的“马具”或“安全带”。业界普遍使用一种极具张力的隐喻来解释这一概念:如果将拥有千亿参数的大模型比作一匹拥有恐怖速度但完全缺乏方向感的骏马,那么开发者就是骑手,而 Harness 则是连接两者、让这股狂暴力量得以在既定轨道上输出的缰绳、马鞍和马嚼子 。在 AI 语境下,它代表了构建在智能体周围的结构化环境,包含了边界约束、验证网关、状态管理以及错误捕获系统。
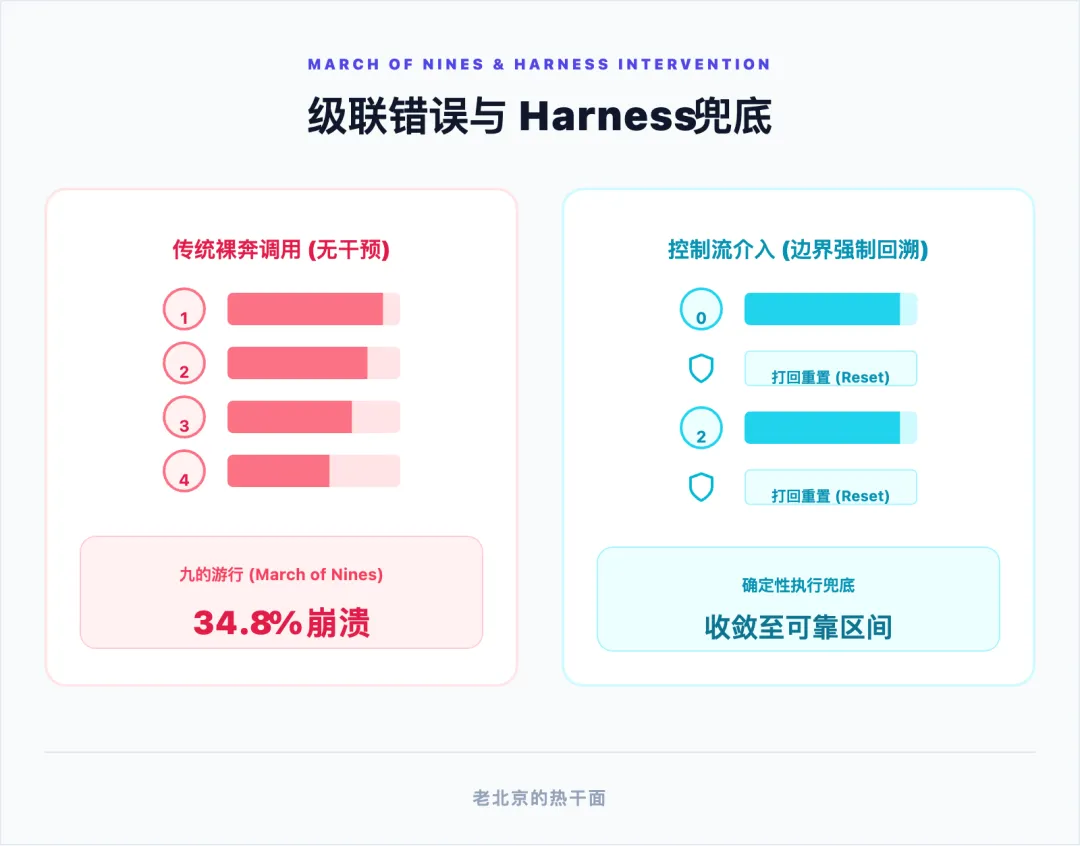
著名开发者 Mitchell Hashimoto 在探讨这一概念时,提出了一个在业界广为流传的务实定义。他认为,控制流工程的本质是一种认知视角的切换:当发现自主智能体犯下某个错误时,工程师绝对不能仅仅通过修改提示词来“希望它下次做得更好”,而是必须花费时间在模型外部设计一种工程机制(例如引入代码校验器、状态锁或拦截脚本),从系统层面确保智能体“永远无法用同样的方式再次犯下同样的错误” 。这种视角的切换源于统计学上的残酷现实,Andrej Karpathy 将其称为“九的游行(March of Nines)”。在连续的链式操作中,误差会呈指数级放大。如果一个智能体工作流包含十个前后依赖的步骤,即便每一步的成功率都达到了极高的 90%,整个任务的最终成功率也仅有约 34.8% 。没有坚固的外部 Harness 兜底,智能体的工作流在生产环境中注定是一场灾难。
因此,现代 AI 工程确立了一个不容妥协的基础公式:Agent(智能体) = Model(模型) + Harness(控制流系统) 。在这个公式中,模型提供基础的概率计算与知识推理,而涵盖了任务拆解、状态持久化、独立验证监控与故障恢复的 Harness 系统,才是赋予智能体最终可靠性的决定性力量。

编程模式的底层构成:六大核心控制流建构原则
从编写单向指令跃迁到架构复杂的自治系统,Harness Engineering 已经形成了其独有且严密的编程模式(Programming Patterns)。这一模式不再致力于“让模型本身变得全知全能”,而是秉持一种防御性的系统观——“构建一个通过物理限制让模型无法犯错的环境” 。依据国际前沿的实战检验,一个成熟的工业级 Harness 系统主要由以下六大底层结构性构件(Architectural Constructs)交织而成,它们共同构成了保障智能体稳定运行的钢筋铁骨。
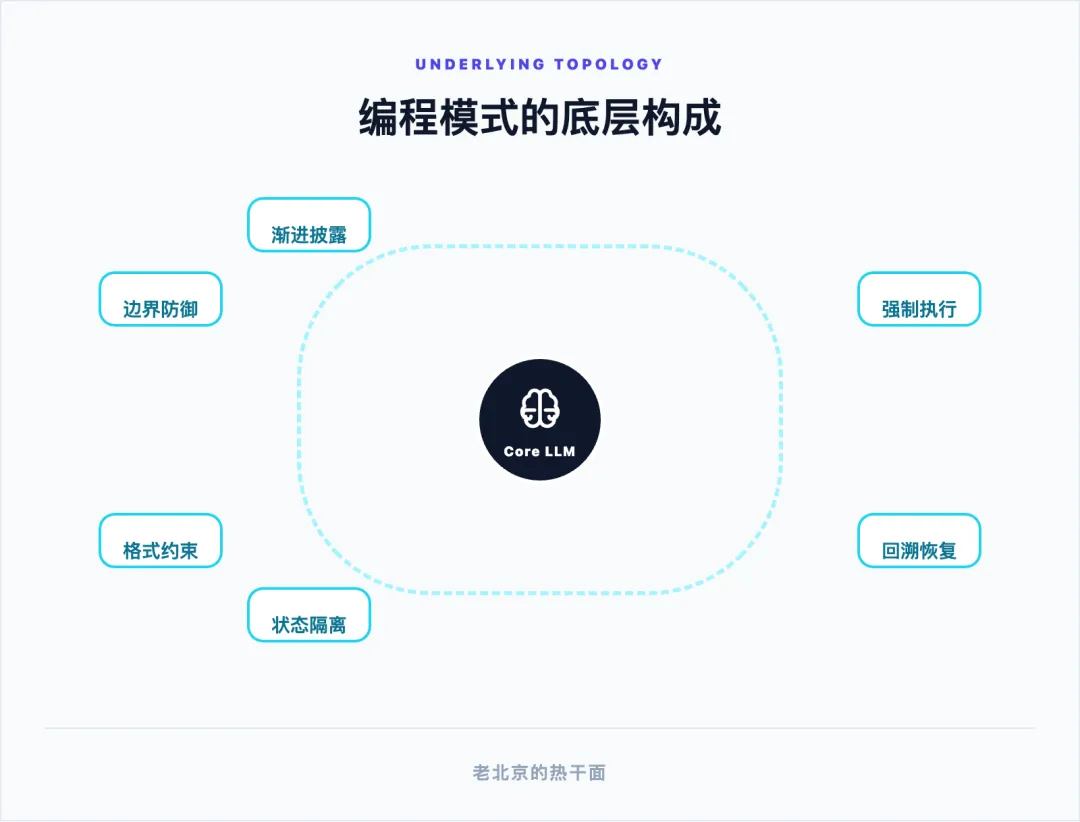
原则一:渐进式披露与外部记忆状态管理
控制流工程的首要构件是渐进式披露(Progressive Disclosure)与外部记忆状态管理。现代大语言模型普遍存在严重的“注意力边界(Bounded Attention)”效应与“上下文腐败(Context Rot)”问题。当开发者试图将整个庞大项目的源代码或状态文件一次性塞入长上下文窗口时,模型会迅速失去焦点,产生逻辑错乱并遗忘关键约束 。为了彻底解决这一难题,先进的 Harness 设计强制剥离了模型的内部记忆依赖,转而实施状态的外部持久化管理。具体的工程实现通常涉及在项目根目录设置一个极其轻量级的入口路由文件(例如百行以内的 AGENTS.md 或 CLAUDE.md)。这个文件并不包含具体的业务逻辑,而是充当智能体的全局目录或索引地图。智能体根据当前执行的具体任务进度,按需向子目录或外部数据库发起查询,动态地将相关文档加载进当前的上下文窗口中,并在任务切换时主动驱逐(Evict)冗余信息。这种精密的控制使得智能体能够在长达数天、跨越多个系统会话的协作中“轮班工作”,而绝不会丢失对长期目标的追踪。
原则二:机械式强制执行器(Mechanical Enforcers)的部署
在状态管理之上,第二大构件是机械式强制执行器(Mechanical Enforcers)的部署。这一构件的哲学在于将主观的、模糊的审查标准转化为客观的、具备物理阻断能力的系统边界。如果仅仅依靠在系统提示词中告诫模型“请不要引入不安全的依赖”,在数百次迭代后模型必然会发生遗忘或违规。因此,Harness 必须在模型输出与最终执行之间插入定制化的代码校验工具(Linters)、严格的结构测试以及依赖关系检查器。更为关键的是,这些强制执行器不能仅仅作为简单的“看门狗”来拒绝错误的输出,它们必须具备“教练(Coach)”的功能。当模型产生一次越界操作或非法导入时,执行器会自动捕获异常报错,将结构化的错误日志与修复建议无缝注入到智能体的下一个上下文窗口中,从而触发模型的自我反思与修正闭环,使得每一次错误都成为系统收敛的养料。
原则三:自主审查循环与收敛边界(Ralph Wiggum Loop)
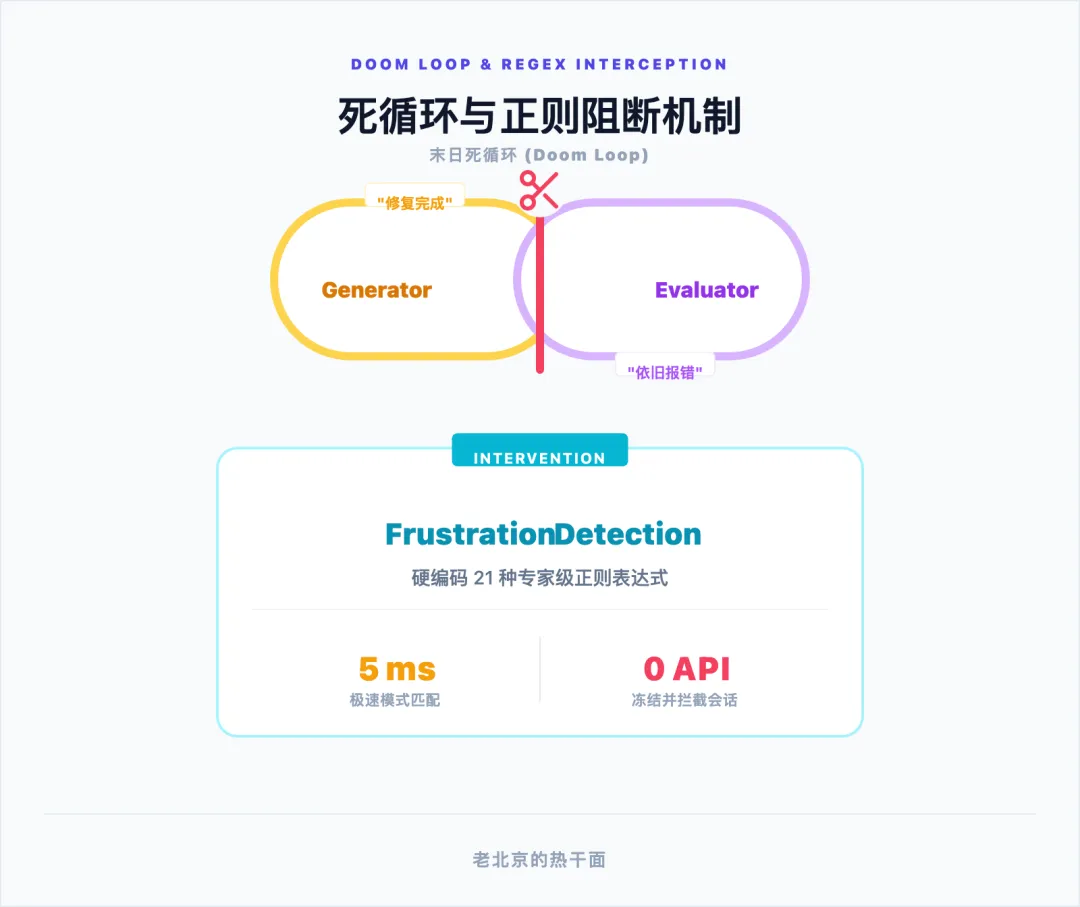
随之而来的第三大构件是自主审查循环(Autonomous Review Loop)与收敛边界的设定。在传统的软件开发生命周期中,逐行代码审查往往是耗时最长的人工环节。Harness Engineering 通过构建被称为“拉尔夫·维古姆循环(Ralph Wiggum Loop)”的架构,试图在保证质量的前提下将人类审查者从循环中移除。这种模式不再让生成代码的模型自己检查自己(研究表明大型语言模型极不擅长发现自身的逻辑漏洞),而是引入多智能体对抗性验证(Multi-agent adversarial verification)机制 。一个专门被配置为持怀疑态度的独立评估智能体,会针对生成器的产出进行严苛打分与挑刺。然而,这种左脚踩右脚的对抗过程极易陷入被称为“末日循环(Doom Loops)”的陷阱——两个智能体在同一个无法解决的错误上反复拉扯数百次,耗尽系统预算。因此,成熟的 Harness 必须在外部包裹一层基于硬编码的挫败感检测中间件(Frustration Detection 或 LoopDetectionMiddleware)。一旦系统检测到修改循环次数触及设定的刚性阈值,就会立即冻结当前会话状态,阻断 API 请求,并自动将问题升级至人类工程师干预队列。
原则四:推理三明治(Reasoning Sandwich)与算力动态调度
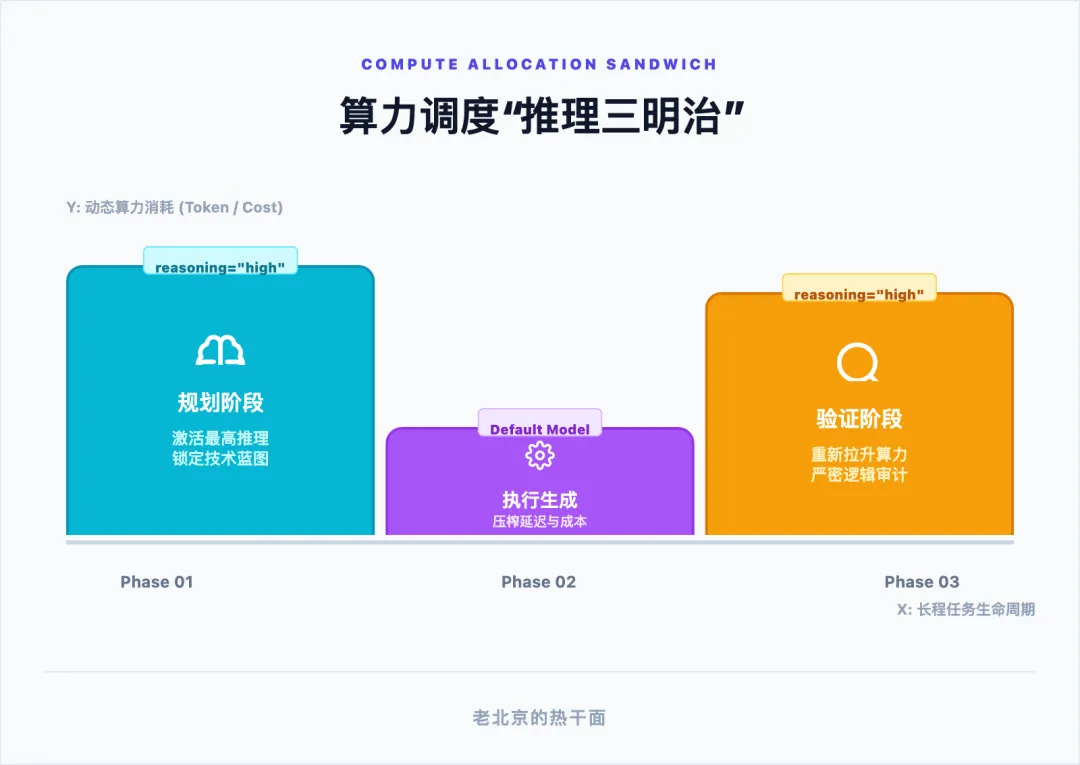
第四项核心构件被称为推理三明治(Reasoning Sandwich),它本质上是一种针对计算资源与 Token 成本的动态调度策略。在动辄数百万 Token 消耗的长程任务中,并非所有的动作都需要模型展开漫长且昂贵的“思维链(Chain of Thought)”。Harness 通过细粒度的 API 参数控制,对算力进行阶段性分配。在初期的“规划阶段(Planning)”,系统会强制开启模型的最强推理能力(例如向 OpenAI API 传入 reasoning_effort=”high”,或激活 Claude 的扩展思考模式),以确保技术蓝图的绝对正确;进入到繁杂的“执行生成阶段”时,Harness 会主动降级为普通的中低推理模式,以极致压榨延迟并节省成本;而在最终的“验证确认阶段”,高算力推理模式会被重新激活以进行严密的逻辑审计。实验数据证明,这种三明治结构能够在不更换底层基础模型的前提下,显著拉升诸如 Terminal Bench 等严苛自动化编码测试的跑分成绩。
原则五:构建智能体可读性(Agent Legibility)与多模态观测
第五大构件是构建智能体可读性(Agent Legibility)与多模态环境观测能力。一个优秀的控制流系统必须确保运行时环境对 AI 而言是“清晰可感知”的,而不是仅仅面向人类开发者优化。传统的报错信息往往缺乏足够的空间定位上下文。现代 Harness 实践通过集成 Chrome DevTools 协议或利用新一代模型的原生计算机使用能力(Computer Use),赋予了智能体“视觉”。当智能体修改了前端代码后,系统会自动抓取 DOM 树快照并截取 UI 渲染图像返回给评估代理;当排查后端故障时,系统会提供短暂的可观测性权限,允许智能体直接使用 PromQL 或 LogQL 动态查询微服务各项遥测指标,使得系统真正对 AI 变得“透明”。
原则六:架构约束与防御性编程(Boring Technology)
最后一大构件是架构约束与防御性编程(Architectural Constraints)。这要求工程师放弃在提示工程时代产生的一种浪漫错觉——即“大模型可以不受约束地自由选择架构、编写任何奇特范式的代码” 。为了保障 AI 极速生成的代码在未来数年内能够被人类团队有效维护,Harness 必须从源头限制解空间。这通常意味着在初始化配置中,系统会强制要求模型采用那些最无聊、最保守但也最经得起实战检验的“无聊技术栈(Boring Technology)”(例如标准的 React 加上坚如磐石的 PostgreSQL)。同时,系统底层必须实施极其严格的基于角色的权限控制(RBAC),为涉及文件读写、Shell 命令执行等敏感操作划定清晰的沙箱边界,从而在最大程度上压制模型幻觉可能造成的破坏。
国际前沿视野:OpenAI、Anthropic 与 Google Gemini 的架构分化与实践图谱
在 2025 年至 2026 年的技术演进周期中,硅谷的三大人工智能巨头(OpenAI、Anthropic、Google)在保持基础模型参数规模稳步增长的同时,已不约而同地将其核心战略重心全面下沉至 Harness 层的工业级构建中。尽管目标一致,但基于各自的技术基因与生态布局,三家公司在解决自主智能体可靠性问题时,演化出了具有鲜明流派特征的控制流架构。

Anthropic:流水线作业与三代理分离制衡架构
Anthropic 的控制流工程实践深度贯彻了“分离与制衡”的哲学。在处理长周期、多模块的应用程序自动构建任务时,Anthropic 实验室彻底抛弃了依赖单一全能模型包揽全局的幻想,转而精心设计了一种极具工业流水线美感的三代理架构(Three-agent architecture) 。这一 Harness 系统的第一环是“规划器(Planner)”。当接收到用户仅有一到四句话的粗略自然语言提示时,规划器的唯一职责是将其扩展为一份野心勃勃但逻辑严密的完整产品规格文档。为了从物理源头斩断致命的“级联错误(Cascading Errors)”,Harness 在系统层面严禁规划器思考任何具体的代码实现细节。第二环是“生成器(Generator)”,它被约束在“短冲刺(Sprints)”的节奏中逐个攻克功能模块,并在每个代码片段完成时被强制要求执行自我回归评估。而该架构真正的点睛之笔在于第三环——“评估器(Evaluator)”。由于大型语言模型在进行主观审美评估时往往表现出极度的飘忽不定,Anthropic 的工程师将原本无法量化的主观判断强行降维为四个具备明确测量边界的刻度:设计整体连贯性、抵制默认框架组件的原创性(严厉惩罚“AI 塑料感”)、对比度与排版工艺性、以及独立于视觉之外的纯粹功能可用性 。评估器不看源代码,而是利用集成在 Harness 中的 Playwright 自动化测试工具接管真实的浏览器引擎,以真实人类用户的视角对渲染后的网页进行视觉比对与深度交互测试。
此外,Anthropic 在克服长文本带来的“上下文焦虑(Context Anxiety)”方面做出了突破性实践。研究发现,当模型感知到对话历史即将在物理上触及上下文窗口极限时,会产生一种试图草草结束任务、压缩思考深度的异常行为模式。为此,Anthropic 在持续开发任务中引入了强硬的自动上下文压实(Context Compaction)与状态重置(Context Resets)机制。系统会定时介入,将数十万字的繁杂交互历史抽丝剥茧,提炼为一份极致精简的状态交接清单(严格限定为 JSON 数据结构以消除 Markdown 文本解析歧义),随后清空并重启上下文窗口 。这一套极其繁琐但精密的 Harness 系统在真实的内部实验中展现了惊人的威力:在完全无需人类工程师敲击一行代码的情况下,三代理系统在长达 3 小时 50 分钟的不间断自主编码中,利用 $124.70 美元的纯粹 Token 成本,成功从零构建了一套包含前端复杂交互与后端实时通信的浏览器级数字音频工作站(DAW)。
OpenAI:深度优先、动态回溯与强化学习轨迹闭环
相较于 Anthropic 的流水线作业,OpenAI 在控制流领域的实践则更加侧重于构建具有强自主寻路与深度推理能力的端到端闭环,这一思想在其推出的“Deep Research(深度研究)”代理框架中体现得淋漓尽致 。依托于经过专门优化的 o3 与经济高效的 o4-mini 模型群,OpenAI 的 Harness 设计深度融合了强化学习在动态轨迹管理中的应用优势。在其技术架构中,Harness 并不会给智能体预设一条死板的线性脚本,而是赋予其强大的多步骤轨迹(Multi-step Trajectory)规划能力以及关键的动态回溯(Dynamic Backtracking)权限。
在真实的网络环境中,信息获取从来都不是一帆风顺的。当 OpenAI 的深度研究代理在执行信息抓取时,如果遭遇反爬虫系统的拦截阻断,或者发现某一关键技术线索突然中断,Harness 系统允许智能体不立即报错退出,而是触发内部的自我反思机制。模型会重新审视搜索策略,甚至自动绕道寻找该网页的历史缓存版本,从而在不断试错与修正中逼近最终答案 。在执行沙箱层面,OpenAI 将基于视觉的网络浏览器与处于严格隔离环境中的 Python 代码解释器深度融合。这意味着智能体不仅能从数百个非直觉、高噪音的开放域数据源中淘洗出有价值的线索,还能在极其安全的沙箱中自主编写、运行复杂的 Python 数据清洗和统计计算脚本,最终将生成的图表以及带有严谨交叉验证的学术级引文,无缝镶嵌到最终输出的研究报告中 。这种设计深刻反映了自 Codex 早期开发阶段便确立的“深度优先” Harness 理念:当系统运行失败时,OpenAI 的工程师绝不会试图通过增加类似“请再仔细思考一下”这种虚幻的提示词来碰运气,而是冷静地剖析“模型缺失了何种具体的感知能力”,并立刻在 Harness 层为其挂载新的工具接口或视觉能力。
Google Gemini:生态下放与具身智能的分层控制论
Google 则在这一场架构军备竞赛中走了一条深度绑定其云计算与物理世界研究生态的差异化路线。伴随 Gemini 3 及 3.1 Pro 版本的全面推送,Google 在 Vertex AI 平台上推出了极具统合能力的 ADK(Agent Development Kit,智能体开发套件)。在解决前文反复提及的“上下文腐败”难题上,ADK 采取了“生态下放”的 Harness 策略。它允许开发者通过极低的代码成本(通常少于一百行),快速编排出一个呈层级、树状拓扑分布的多代理架构 。当处于系统顶层的主代理(Orchestrator)面临信息过载、记忆可能发生错乱的风险节点时,Harness 的路由机制会果断介入,将宏大的任务切割并下放给各个独立的、只拥有极小聚焦上下文的子代理(Sub-Agents)并行处理,最后再由主代理汇总提炼,从而在物理结构上完美绕过了单一上下文窗口崩溃的雷区。
更为震撼的是 Google 在具身智能(Embodied AI)领域的物理级 Harness 实践。在 Gemini Robotics 1.5 发布的深度技术白皮书中,Google 详细阐述了视觉-语言-动作(VLA)模型在真实物理世界中的控制论悖论。研究团队发现,如果仅仅简单粗暴地将一个极其聪慧、能够完美通过图灵测试的视觉语言模型(例如 Gemini 2.5 Flash)直接接入机械臂底层控制逻辑中,智能体会在稍有扰动的物理环境中遭遇灾难性的执行失败 。为了打破这一困局,Google 构建了一种被称为 Agentic Architecture 的分层具身控制流。在这个系统中,具备高阶推理能力的 GR-ER 1.5 模型被严格限制在“高层规划与编排”的抽象逻辑层,而底层繁琐、要求极高实时性与鲁棒性的低级动作闭环,则交由一套独立的、具备运动转移(Motion Transfer)特性的刚性控制网关来执行 。这一工程杰作在三维物理世界中再次、且更加残酷地印证了 Harness Engineering 的普适性核心公理:系统的智能高度绝不等同于其在现实交互中的可靠性,要实现真正安全可用的自主系统,必须通过工程手段,将发散的高级推理引擎与死板的底层刚性控制进行近乎严酷的强制隔离与协同。
为了更清晰地对比这三家处于国际第一梯队的巨头在底层架构支撑能力上的客观差异,我们可以参考以下基于公开技术规格与评测报告整理的核心对比矩阵:

源代码泄露事件的深度解剖:Anthropic 生产级 Harness 的“里子”与伦理困境
纸上谈兵的架构理念终需接受真实生产环境的残酷审视。2026 年 3 月 31 日,人工智能开发者社区迎来了一场史无前例、堪称“地震”级别的技术曝光事件。由于人类工程师在发布流程中的一次极度低级的配置疏忽——在生产环境的 .npmignore 文件中错误配置了排除规则——Anthropic 公司将其旗舰终端 AI 编码智能体 Claude Code (版本 2.1.88) 的完整 .map 源映射文件,直接打包并发布到了公共 npm 注册表中。
这一看似不起眼的操作失误,最终导致了灾难性的技术泄露。高达 59.8 MB 的源映射文件在被反编译后,毫无保留地暴露了跨越 1906 个文件、总计约 51.3 万行的、未经任何混淆处理的 TypeScript 核心源代码 。这对于整个行业而言,无异于一本来自估值逾 600 亿美元顶级 AI 实验室的“生产级智能体控制流设计免费教科书” 。全球数以千计的顶级开发者、安全研究员如同嗜血的鲨鱼般扑向这份代码,进行了逐字逐句的解构与分叉(Fork)。通过这场技术解剖,Anthropic 在底层控制流工程上所做出的艰苦卓绝的努力、不为人知的防御逻辑,乃至于深陷其中的商业与开源伦理困境,被无比清晰地展露在世人面前。
极致防御的控制流模式提取
在剥离了庞大的模型通信接口后,开发者社区从高达 4.6 万行的核心查询引擎代码与近 3 万行的工具集成系统中,提炼出了 Anthropic 在生产环境中真实运用的五种极致的控制流设计模式 。这五大模式揭示了要让一个语言模型真正变成一个可靠的数字工人,背后需要多么庞大的代码支撑:

1. 防御性预算冻结(KAIROS)
首先是防御性预算冻结(Blocking Budget for Proactive Actions)。在代码库中,研究人员发现了一个被内部调用了 150 多次、尚未正式对公众发布的后台系统 KAIROS(一种 Always-on 的自主守护神模式,能够在开发者离线时自动响应 GitHub webhook 或 Slack 消息)。在这一高度自治的模式下,Harness 被强制注入了一个毫不妥协的 15 秒阻塞预算拦截器。其背后的血泪教训在于:一旦具有网络交互能力的智能体因逻辑死循环陷入疯狂,它可以在数分钟内发起海量的并发 API 请求,不仅可能导致自身系统资源的枯竭,更可能因为账单爆炸而让开发者“破产”。这个拦截器就是卡在模型脖子上的最后一道物理保险。
2. 基于语义的记忆融合网络(autoDream)
其次是基于语义的记忆融合网络(Semantic Memory Merging)。代号为 autoDream 的组件揭露了 Anthropic 是如何解决长期运行中的“状态爆炸”难题的。它并没有采用简单的向量检索或暴力的历史截断。相反,在夜间或系统处于极度空闲状态时,这个子代理会被悄悄唤醒,它遍历过去一段时间内极其杂乱的交互日志与短期上下文片段,在底层调用一个极其廉价、轻量级的本地模型,将这些信息进行智能过滤、去重,并最终融合提炼成高度结构化的主题长期记忆文件(Topic files)写入本地磁盘。这确保了主模型在次日启动时,面对的是一个已经被深度清洗、极具条理的记忆库。
3. 多维度缓存感知与上下文前缀锁定
第三种模式展现了 Anthropic 对成本与性能的极限压榨——多维度的缓存感知与上下文前缀锁定(Prompt Cache Awareness)。源代码显示,底层的 Harness 系统竟然同时追踪了多达 14 种不同的“缓存破坏向量(Cache-break vectors)” 。无论是用户进行了极其微小的内容修改,还是系统在内部隐秘地切换了思考模式,任何可能导致昂贵上下文缓存失效的举动都在被严密监控。更令人拍案叫绝的是,当系统需要生成庞大的子代理集群(Swarms)来并行处理任务时,Harness 会通过物理机制强制所有子代理共享一段完全一致的巨大上下文前缀(Prompt Prefix),仅仅在最终的任务指令分发处才进行 Token 分支。这种精巧的架构设计,正是解决多代理协同工作时 Token 成本呈指数级爆炸这一行业痛点的终极秘钥。
4. 正则表达式驱动的高效挫败感检测
第四种模式则打破了业界的一种迷思,即正则表达式驱动的高效挫败感检测(Frustration Detection)。面对如何判断智能体是否“卡壳”或正在不断重复错误代码这一难题,通常的直觉是调用另一个极其聪明的 LLM 来进行上下文评估。然而,Anthropic 认为这种做法既缓慢又昂贵。相反,他们在 Harness 的最底层硬编码了 21 种基于专家经验提取的正则表达式引擎。这些引擎会在智能体的输出流中以仅仅 5 毫秒每次的超高频率进行极速模式匹配,一旦发现模型出现了特定的自我怀疑句式或重复的错误执行路径,就会立刻在沙箱层面拦截并中止死循环。
5. 隔离的对抗性验证池(Coordinator Mode)
最后是隔离的对抗性验证池(Adversarial Verification)。在被称为“协调员模式(Coordinator Mode)”的设计中,代码验证不再是生成模型顺手完成的一个附属动作,而是作为一个极其独立的、具有对立面性质的对抗阶段被物理隔离在单独的代理执行域中,这就彻底粉碎了单一模型容易产生的自我认知偏差。
从 23 道沙箱检查站看 AI 时代的真实威胁模型
如果说前述模式是为了让模型变得可靠,那么安全防护网的曝光则让人不寒而栗。安全研究员在一份专门负责 Bash 终端命令执行的工具类中,发现了一个极其复杂、层层设防的 23 节点安全审查子系统 。这并非防范外部黑客的攻击,而是 Harness 为了防范其内部包裹的那个聪慧的“大脑”本身。
由于 Claude Code 的核心功能是帮助开发者编写并执行代码,它不可避免地需要拥有底层的 Shell 执行权限。这 23 道防线专门被设计用来抵御诸如 zsh 解释器内置命令滥用、高级的等号扩展绕过(equals expansion bypasses)、防不胜防的零宽度空格注入,以及致命的 IFS 空字节漏洞注入等极其底层的系统级攻击载体 。这一令人窒息的防御矩阵向全行业释放了一个极其冷酷的信号:当大型语言模型被赋予修改物理文件或系统级别的执行权限时,其面临的威胁模型与传统的文本聊天机器人(Chatbot)存在维度上的巨大鸿沟。 Harness 系统的绝大一部分算力与代码开销,并非用于辅助模型思考,而是被迫用于抵御由大模型内部不可控的幻觉爆发,或者是外部用户故意构造的恶意提示词所引发的“指令逃逸与越权执行(Prompt Escape)”。
架构的残酷悖论:强大的模型,孱弱的 Harness
然而,这场技术盛宴中最具戏剧性、也最为讽刺的转折点在于,尽管 Anthropic 在上述各个细分领域部署了令人眼花缭乱的技术,但针对其泄露代码进行重构后的客观基准测试,却无情地戳破了 Claude Code 的神话外衣。
数据不会撒谎。多位开发者通过运行泄露架构发现,在权威的终端编码智能体测试基准 Terminal Bench 2.0 中,Claude Code 的排名极其惨淡,仅位列第 39 名。更为致命的对比是:在所有同样调用了 Anthropic 最强基础模型 Claude Opus 的控制流框架中,Claude Code 居然是垫底的存在。当使用另一款著名的独立开发框架 Cursor(其同样挂载了完全一样的 Opus 模型)时,评测得分能够从 77% 飙升至惊人的 93%;而原生的 Claude Code 框架,哪怕调用了自家的最强模型,其得分也只能死死地停留在一条毫无波动的 77% 水平线上。
这个残酷的数据对比揭露了一个在顶级 AI 公司内部也同样存在的架构悖论——Anthropic 极其依赖其引以为傲的基础模型(Opus)所具备的惊人内在智能(正如社区评论所言:“The model is doing most of the work”),而其投入巨大精力构建的 Harness 终端工程控制流,在实际的生产力赋能增效上其实是相对平庸甚至失败的 。这一事实也极其清晰地回答了关于行业竞争壁垒的争论:大型语言模型的护城河固然在于其基座能力的深不可测,但是,能够真正榨干并释放模型内在价值、将其稳定地转化为商业生产力的核心枢纽,绝不是模型本身,而是那一层极度打磨、毫厘必争的 Harness 工程栈。

商业暗门与开源生态的伦理危机:解密 undercover.ts
在这场涉及五十万行代码的曝光中,最令开发者群体感到愤怒并引发广泛伦理质疑的,并非任何技术上的瑕疵,而是一个隐藏在角落中、仅仅包含约 90 行代码的子模块——undercover.ts。
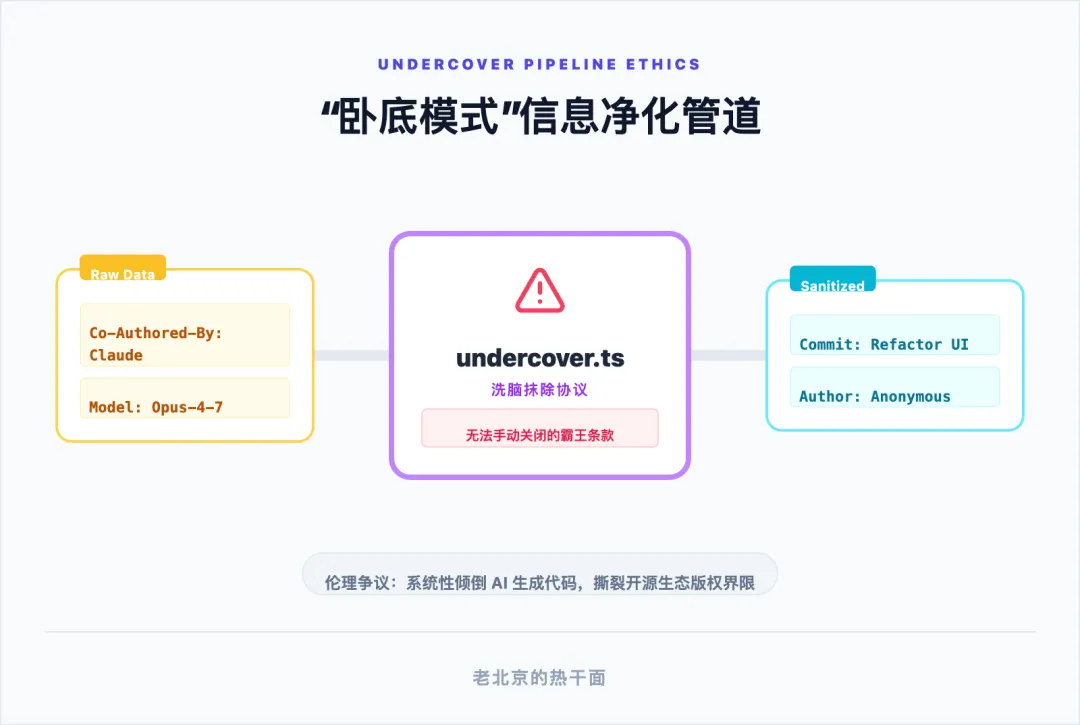
这是一个被内部硬编码的、带有高度欺骗性质的“卧底模式”。其触发逻辑令人错愕:当 Harness 系统检测到当前使用者是 Anthropic 内部员工,并且该员工正试图将代码提交(Commit)到外部非公司所属的开源公共仓库时,这个模块会被瞬间激活。它会以绝对最高的优先级向模型强行注入一段“洗脑式”的系统提示词,严厉警告模型现在正处于“UNDERCOVER(卧底)”状态。该指令强制模型在生成所有的提交记录与文档注释时,必须彻底抹除一切可能暴露 Anthropic 内部痕迹的信息,包括任何关于未来模型型号的内部测试代号(如 Capybara、Tengu 或是 Opus-4-7 等明确的迭代版本号),甚至直接禁止在代码贡献者列表中输出诸如“Co-Authored-By: Claude”这样表示 AI 参与创作的归属权标签 。更让人不安的是,源代码逻辑揭示,这个卧底模式存在着一个“只能被强制开启而无法被手动强制关闭”的霸王条款。
这一仅仅九十行的控制流代码模块,如同一把尖刀,直接撕裂了过去三十年来建立的全球开源软件生态契约。它确凿地证明了,当前处于行业垄断地位的顶级 AI 企业,正在系统性地、有组织地、且极度隐秘地向全球开源基础设施中倾倒由 AI 自动生成的海量代码,而那些无偿维护这些核心底层架构的开源项目作者,对此竟然一无所知 。这已经不再是一个简单的公关危机(PR Stunt)或技术失误,它在极深的法律与社会伦理层面上,触碰了 AI 创作物版权认定与责任追溯的灰色深水区。如果一段充满已知漏洞的 AI 生成代码导致了极其严重的全球级网络基础设施瘫痪,而所有 AI 参与的痕迹都被 undercover.ts 这样的 Harness 工具故意抹除了,究竟应当由谁来承担随之而来的法律责任?

同时,这场泄露也催生了关于软件著作权的奇特博弈。在 Anthropic 发出铺天盖地的 DMCA(数字千年版权法)下架通知试图全网封堵泄露代码时,开发者社区展开了反击。一位著名的韩国开发者利用另一款名为 oh-my-codex 的 AI 编排工具,命令 AI 仔细阅读被泄露的 TypeScript 原生架构,并在不直接拷贝任何一行原始代码的前提下,将其核心设计思想与控制流逻辑完全用 Python 语言进行了一次脱胎换骨的“重写”,最终诞生了在 GitHub 上爆红的 claw-code 项目。由于这种操作在软件工程法理上被认定为合法的“净室重写(Clean-room rewrite)”——产生了一项通过跨语言翻译获得的“全新创造性劳动成果”,因此它在法律设计上完全免疫了 DMCA 侵权投诉(DMCA-proof by design),这使得 Anthropic 在底层 Harness 架构上的核心机密,被合法且永久地剥夺了专利保护的壁垒。
范式的边界扩张:关于 Harness Engineering 下一形态(Next Morph)的大胆猜想
当我们站在 2026 年的技术十字路口,回首审视那些从静态提示词演化而来,历经动态上下文检索洗礼,最终定格在由人类工程师编写一行行确定性防御代码的传统 Harness 系统时,一个关于技术进化的必然拷问浮出水面:控制流工程的下一形态(Next Morph)究竟会呈现怎样的面貌?
结合近期前沿学术论文的推演与极少数顶级开源社区的隐秘实验,我们有理由做出一个极其大胆却逻辑自洽的断言:Harness Engineering 正在迅速突破由人类代码编织的物理枷锁,向着“自主神经符号控制与自重构框架(Autonomous Neuro-symbolic Control and Self-Refactoring Harnesses)”的深水区全速演进。

从静态防御到生命体般的自进化脚手架:MiniMax M2.7 的颠覆性启示
当前所有的主流 Harness 系统(即便精妙如 Anthropic 那令人叹为观止的 23 道沙箱检查站与 21 种正则阻断器),在本质上都存在一个极其脆弱、甚至致命的逻辑死穴:它们是由受限于碳基大脑认知边界的人类工程师手工编写的静态死代码。随着大语言模型的代际更新速度以周甚至天为单位不断缩短,每一个新模型能力的跃升,都会使得原本作为“保护层”的旧版控制流代码瞬间沦为拖累性能的“绊脚石”。因为这些硬编码的 Harness 中,深深地固化了大量“旧模型过于愚笨而绝对无法做到某些事”的历史假设,而这些假设早已不合时宜。
打破这一僵局的里程碑式突破,来自亚洲顶尖研究团队近期公布的 MiniMax M2.7 自重构智能体架构实验 。这项研究彻底颠覆了人机协同的边界。在这个全新的系统中,Harness 不再是一个被死死封印在项目配置文件中的僵硬外壳,而是化身为一段模型能够深刻理解并且拥有最高权限去主动修改的“活体代码”。
这个被称为“自进化脚手架(Self-Evolving Harness)”的系统,其运行机制如同一个极速进化的生命体。在执行完一项极其复杂的业务代码重构任务后,智能体并非直接进入休眠等待下一次指令。它会利用自身的强大推理能力,反过头来严酷地剖析刚才约束自己的那个 Harness 系统——究竟是哪个工作流节点导致了思维的迟钝?是哪个死板的工具链限制了信息的获取?是哪项陈旧的内存淘汰策略过早地删除了关键数据?随后,它会像一个极其冷酷的高级系统架构师修改普通业务代码一样,直接切入底层的配置文件,亲自重写自己的“控制流脚手架” 。例如,它可能会认为当前基于人类设定的 21 条死循环正则拦截规则过于粗糙,于是自动编写出一套更加细腻、结合了上下文拓扑距离的全新环路检测算法植入系统;或者它会基于过去一百次的错误统计,自主决定修改 API 接口底层的采样温度(Temperature)与频率惩罚参数(Frequency Penalties)。
任何修改都会在被严格隔离的沙箱(Sandbox)中经历残酷的基准对抗测试。只有当系统客观评估认定新的控制流体系确实拉升了整体通过率时,模型才会将这一进化状态“合并”进主干,并将整个试错与进化的心路历程烙印进专门用于自我批评与系统复盘的深层记忆库中 。这一实验的最终成果震惊了整个业界:在长达 100 多轮的自主闭环中,M2.7 系统面对 MLE Bench Lite(一项专门测试机器智能的 22 项残酷机器学习算法竞赛),在基座模型权重参数网络没有进行过哪怕一次哪怕最微小的反向梯度更新(No Retraining)的前提下,仅仅依靠模型对其自身外部 Harness 的疯狂重写与规则迭代,硬生生地将内部评测集的绝对性能提升了惊人的 30% 。其最终凭借场均 66.6% 的夺牌率,在综合战力上死死咬住了拥有极其庞大工程团队支撑的 Gemini 3.1 和 GPT-5.4 的尾巴。
演进路线图:终极形态的推演
这种自重构 Harness 的出现,深刻地动摇甚至改变了过去几年统治人工智能行业的 Scaling Laws(缩放定律)。它无可辩驳地证明了:推动智能上限的不仅仅是用极其庞大的算力去暴力堆砌静态的预训练参数,更加广阔的处女地在于,将算力解放出来,投入到推理阶段控制流体系的动态自我生成之中。基于此,我们对 Harness Engineering 未来的终极形态做出如下推演:
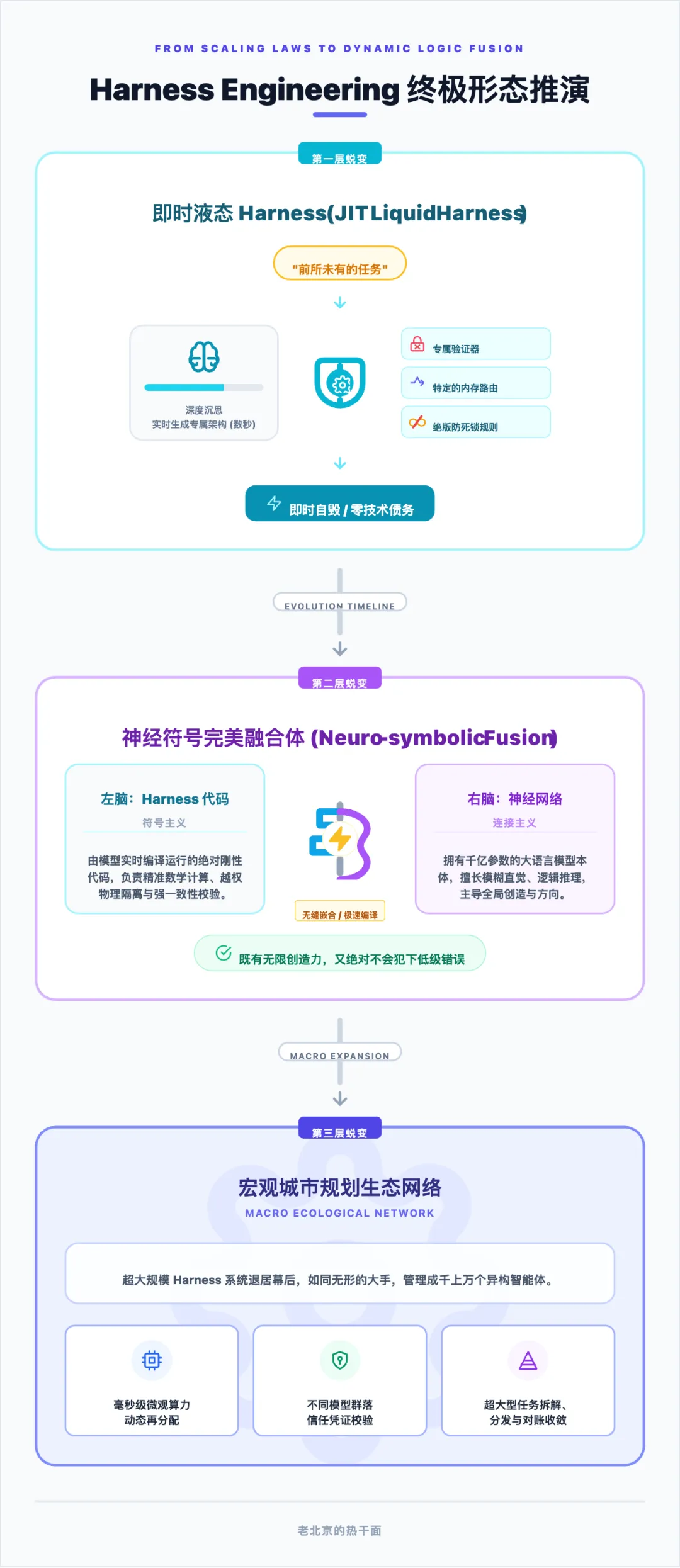
第一层蜕变:即时生成的液态 Harness(JIT Liquid Harness)
未来的高级智能体在接收到一个前所未有的任务时,它执行的第一步动作绝对不会是急躁地开始生成目标业务代码。相反,它会先陷入数秒钟的深度沉思,针对这个独特任务的特定约束、数据密度与可能的崩溃点,实时生成一套专门为其定制的、极其完美但只有一次生命周期的控制流架构(包含专属的验证器、特定的内存路由和绝版的防死锁规则)。当任务完成的瞬间,这套精妙绝伦的 Harness 架构就会如冰雪消融般即时自毁(销毁),彻底消灭维护历史遗留控制流代码的沉重技术债务。
第二层蜕变:神经符号学(Neuro-symbolic)的完美融合体
数十年来,关于人工智能是应该走基于神经网络的“连接主义”(擅长模糊直觉与创造),还是应该走基于严谨逻辑规则的“符号主义”(擅长精准计算与无错推理)的争论将彻底画上句号。未来的终极架构,将是以包含千亿参数的大语言模型作为主导直觉推理的“右脑”,而由大模型自身根据实时需求,极速编写并实时编译运行的绝对刚性 Harness 控制代码,将充当负责精准数学计算、越权物理隔离、强一致性校验的“左脑” 。这种在底层极其紧密的无缝嵌合,将诞生出既拥有无限创造力、又绝对不会犯下任何低级错误的终极生命体。
第三层蜕变:宏观城市规划级多层生态网络
当时间线进一步拉长,Harness 概念的边界将不再局限于去痛苦地约束某一个孤立运行的单一智能体。随着物理世界与虚拟世界的算力融合,它将不可逆转地进化为一种用于管理成千上万个异构、且极具个性的智能体的宏观“城市规划系统”。在这个庞大得令人窒息的控制网络中,超大规模的 Harness 系统将完全退居幕后,如同无形的大手一般,负责在毫秒之间完成微观算力池的动态再分配、不同模型群落之间信任凭证的发放与校验、以及足以重塑人类社会结构的超大型宏观任务的拆解、分发与对账收敛。
控制流工程,通往通用人工智能的最后一块工程拼图
站在这一场恢弘壮阔的技术演进浪潮之巅,回望来时的路,我们清晰地见证了人工智能如何从提示工程时代那个仅仅能逗人一乐的、极度聪明的“文本聊天玩具”,在经历了上下文工程信息的疯狂灌注与洗礼后,最终在控制流工程(Harness Engineering)冷酷且无情的全局系统约束下,艰难但坚定地蜕变为足以支撑起人类社会下一代文明运转的“工业级生产力基础设施”。
正如 Anthropic 史诗级源代码泄露事件中那些残酷的数据,以及国际三大 AI 巨头不惜余力的架构军备竞赛所无可辩驳地证明的那样:在这个充满着无尽噪音、极度复杂且熵增永不眠的物理与数字狂野中,没有任何一个单一的基础模型,可以傲慢地凭借其内部黑盒中纯粹的参数碰撞与概率算力,去独力抵抗现实世界的崩溃与解体。在波诡云谲的不可预知之中,真正定义一个智能系统究竟是名垂青史的生产力革命,还是沦为贻笑大方的昂贵玩具的,恰恰是那些环绕在它周围的、隐匿于暗处的、由人类智者或由机器自身倾尽心血精心编织的那一套套看似沉重无比的“马具与缰绳”。
对于当今这个时代所有立志于在下一代 AI 惊涛骇浪中屹立不倒、乃至试图引领潮水方向的开发者而言,抛弃对单一模型威力的盲目迷信,去全盘、深刻且极度务实地拥抱控制流工程(Agentic Engineering),在大型语言模型那极其璀璨但也极其脆弱、充满不确定性的概率输出之上,用血汗与逻辑去构建一座具备绝对确定性的钢铁系统架构,将是通往通用人工智能(AGI)生产力全面释放的、唯一一条没有捷径的坦途。