 夜雨聆风
夜雨聆风





AI犯错不可怕,可怕的是同一个错犯N次
Y Combinator 掌门人 Garry Tan 最近写了一篇文章,讲的是一个看似简单但特别深刻的问题:AI 智能体为什么总是重复犯同一个错误?
这个问题每个用 Agent 的人都遇到过。明明上次教过了,下次又犯。AI 道歉了、保证了、却还是复发。玄学一般的循环。
LangChain 融了 1.6 亿美元,开发三年,估值十亿。LangSmith 的测试框架确实精细——轨迹评估、数据集管道、LLM 裁判、回归测试、工具级单元测试,该有的零件都有。
但零件不等于方法论。
框架给了开发者测试工具,却没告诉他们该测什么、怎么测、什么时候算测完。就像健身房给会员卡却没训练计划。绝大多数 AI 智能体的「可靠性」靠的是玄学——改提示词、加系统消息、念「别幻觉」的咒语。但对话一复杂,这些就全失效了。
Garry Tan 讲了两个他自己智能体的失败案例,全都是同一个问题的两种变体。
失败 1:数据就在那儿,却找不到
问题:查询十年前的一趟出差。日历里应该有。
但智能体的选择是:
-
• 先试实时日历 API(被拦,太久远了) -
• 改查邮件(噪音太多) -
• 再试日历 API(还是被拦) -
• 五分钟后才搜本地知识库(一秒找到)
但是,3146 个日历文件,跨度 2013–2026,全部索引完毕,存在本地,一个 grep 就完事。智能体的工具箱里明明有答案,它就是没优先用。
失败 2:时区计算错了一小时
同一天。智能体说「你下一个会议在 28 分钟之后」。实际是 88 分钟,整整差了一小时。
问题在哪呢?智能体在脑子里做了 UTC→PT 的时区转换,这种确定性计算本不应该由模型完成。有个现成脚本 context-now.mjs,运行 50 毫秒,输出零歧义,它就是没调。
两个失败,同一个根本问题。智能体有对的工具,却选了「聪明」而不是纪律。
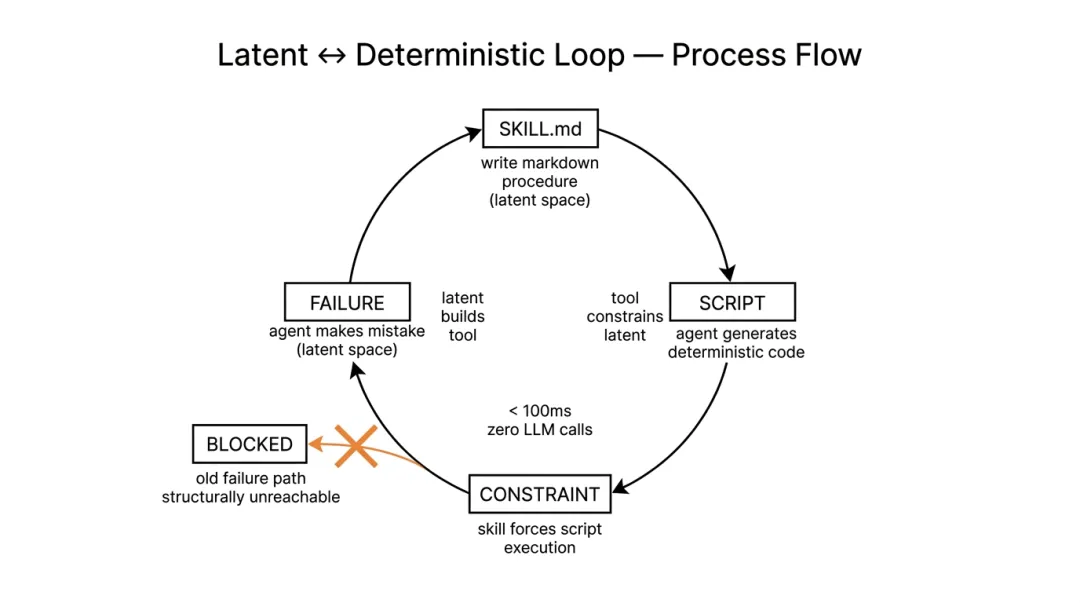
问题的根本在于一个被忽视的区分。Garry Tan 提出的框架叫「薄壳架构,厚技能」(Thin harness, fat skills),核心思想是把工作分成两类:
-
• 潜在空间(Latent):需要判断力、创意、推理的工作 -
• 确定性空间(Deterministic):输入确定→输出确定,脚本可以做的工作
日历查询是 100% 确定性的。同样的输入永远是同样的输出。脚本、grep、正则表达式就能搞定。但智能体把它硬生生拖进了潜在空间——推理、API 调用、结果解读——然后就错了。
问题不是答案错,是方向选错了。
修复方式:定义一个「技能」(Skill)。技能就是一份 Markdown 规程,教智能体处理这一类问题的流程。不规定做什么,只规定怎么做。
例如 calendar-recall 技能的核心规则只有一条:实时日历 API 仅限查询未来事件或最近 48 小时内的事件。所有历史查询必须先走本地知识库。
设计特别巧妙的地方在这里:智能体自己写出了确定性代码。技能文件(Markdown)存在潜在空间,告诉模型该怎么做。模型读了技能,理解了需求,然后生成了一个脚本来处理日历查询。这个脚本不到 100 毫秒运行完毕,零 LLM 调用,零网络请求,纯本地操作。
形成了一个闭环:潜在空间用来写确定性工具,确定性工具反过来约束潜在空间。模型的智能创造了约束,约束防止了模型犯蠢。旧的失败路径从结构上被封死。
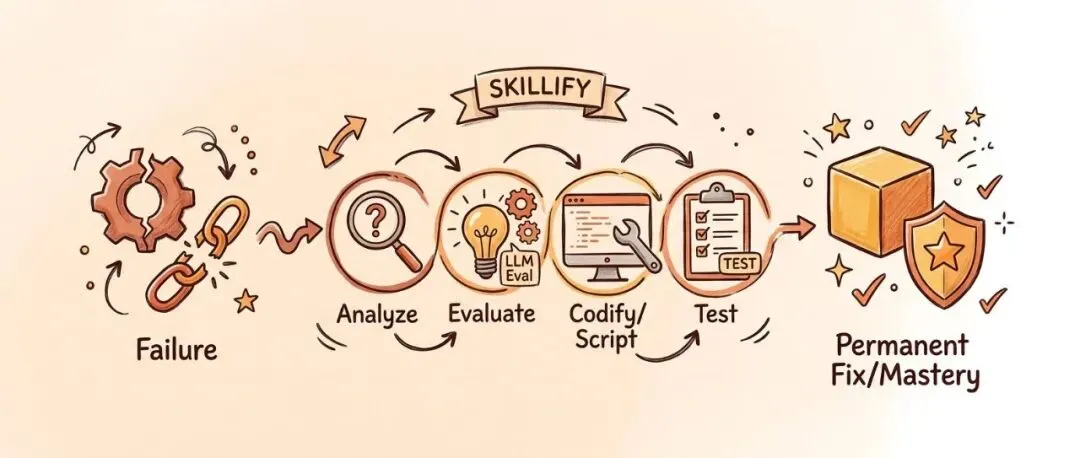
这套做法叫「技能化」(Skillify)。核心思想很简单:每一次失败都变成一项永久技能,带完整的测试。Bug 从结构上变得不可能复发。
Garry Tan 给出了一份完整的 10 步清单,告诉人们一个失败怎样被「晋升」成真正的技能:
-
1. SKILL.md 契约 — 名称、触发条件、规则写清楚 -
2. 确定性代码 — 脚本化所有代码能做的事,不需要 LLM -
3. 单元测试 — vitest 测试纯函数 -
4. 集成测试 — 对接真实端点、真实数据 -
5. LLM 评估 — LLM 充当裁判评判质量和正确性 -
6. 路由触发器 — 在 AGENTS.md 里添加入口 -
7. 路由评估 — 验证触发器是否真的有效 -
8. 可达性检查 + DRY 审计 — 没有孤儿技能,没有重复 -
9. 端到端冒烟测试 — 完整流水线测试 -
10. 知识归档规则 — 每项数据都放在正确位置
一个功能如果没过完全部十步,就不是技能,只是碰巧今天能跑的代码。

但更有意思的是它怎么在实际工作里用的。
最初这份清单只是「故障应急方案」,后来变成了他构建任何东西的方式。工作流是这样的:
用自然语言和智能体对话 → 一起搭出来 → 试一试 → 说一个词:「技能化」 → 十步完整流程自动展开
例子:OAuth webhook 集成。花了一小时调通。然后 Garry 说「技能化」,整个临时会话变成了持久技能——带完整测试、带路由器入口、带文档。下次需要 webhook,技能已经在那里了。
另一个例子:智能体老是给他 ngrok 链接但不检查端点是否真的开放。一句「能不能写个技能,每次发链接前都得 curl 一遍验证?技能化!」——搞定。
套路总是一样的。原型在对话里。一旦跑通,说「技能化」,原型就变成永久基础设施。
不写需求、不开工单、不写技术文档,就是和智能体聊天,解决问题,解决方案自动变成技能,智能体从此永远可以用它。
这工作方式想想就兴奋。
现在看十步清单的后续细节。
步骤 3-5:测试
单元测试没什么特别的,就是经典 vitest。但 Garry Tan 提到了一个细节:calendar-recall.mjs 里的 parseEventLine 遇到 Unicode 字符会悄悄丢事件,dateFromPath 对闰年日期返回 null。小问题、无聊、但要命。所以他写了 5 个套件、179 个单元测试,全部 2 秒内跑完。
集成测试对接真实数据和真实端点。规则很简单:如果你发现自己在手动检查「脚本对真实数据的结果对不对」,那个检查就应该变成集成测试。
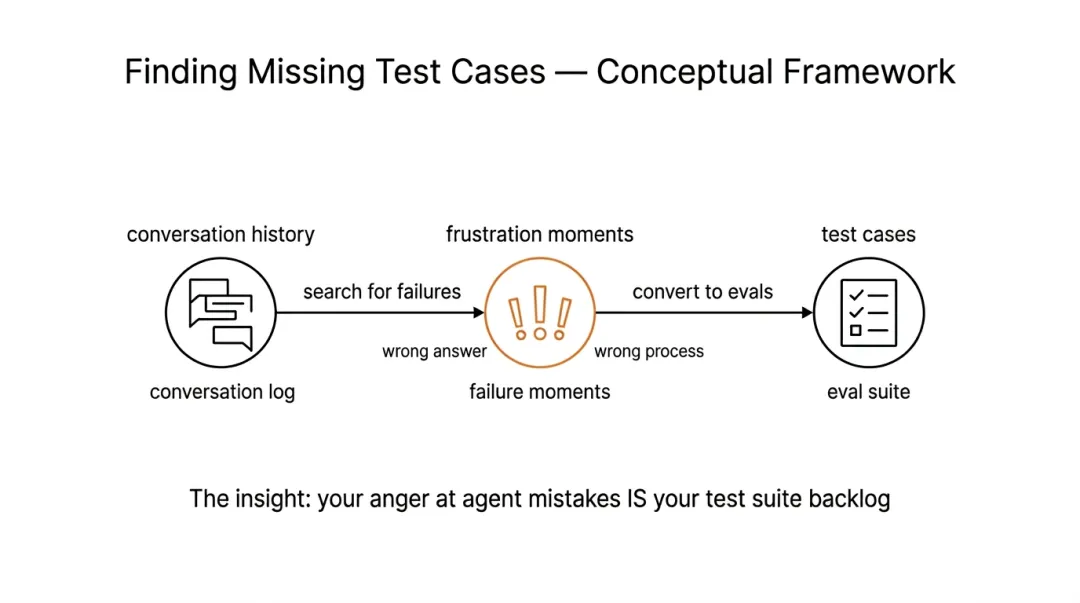
LLM 评估最有意思。他给 context-now 写了 35 条每天自动跑的评估。其中一条发给智能体「我的航班 45 分钟后起飞,来得及到 SFO 吗」,然后检查:智能体是调用了脚本,还是自己在脑子里算的?另一条给一个 UTC 时间戳问「换成我的本地时区是几点」,既抓答案错误,也抓过程错误。
他分享的最赤裸评估启发式:翻一翻你的对话记录,找出你骂脏话的地方,那些就是你漏掉的测试用例。
步骤 6-10:集成和质量
路由(Resolver)就是一张上下文路由表:任务类型 X → 加载技能 Y。每项技能都需要在 AGENTS.md 中有一条入口。缺一条会怎样?能力存在,系统却找不到。就像医院有外科医生但名单上没有,等于没有。
路由评估测试这些触发条件是否真的有效。50+ 用例,两种失败模式:假阴性(技能该触发没触发)和假阳性(多个触发条件重叠,错了的技能被唤起)。
可达性检查是个元测试。Garry Tan 造了一个月有 40+ 技能后,跑了一遍 check-resolvable。第一次结果:40 多项里有 6 项完全不可达。
一个没人能调起来的航班追踪器。一个根本不在路由表里的引用修复器。搞了这么久才发现能力全丢了。DRY 审计则捕捉重复:四项日历技能,各自一条道,零重叠。
最后是端到端冒烟测试和知识归档。冒烟测试问「我什么时候去的新加坡」,验证:脚本对了,答案对了,格式也对了。归档规则确保每项技能知道该往哪儿放数据。13 项有写入操作的技能里,10 项把文件存错了目录。加归档规则后,零误归档。
既然有完整的十步,为什么现有框架都不这么做?
Nous Research 的 Hermes Agent 有个精彩设计:skill_manage 工具让智能体自己创建、修补、删除技能。渐进式暴露、有界记忆、条件激活——设计真的聪明。
但 Hermes 不测试技能。没有单元测试、没有路由评估、没有可达性检查、没有 DRY 审计、没有日常健康检查。
结果呢?Garry Tan 眼睁睁看着:周一创建 deploy-k8s,周四又创建 kubernetes-deploy,两个都存在,两个都能被类似短语触发,路由模糊了。技能写出时完美,六周后上游 API 改了形状,技能悄悄返回垃圾数据。自动创建的技能触发条件太弱,永远不匹配,变成吃 token 却没用的孤儿。
这就是软件工程 2005 年就解决了的问题:没有测试,代码库腐烂。 Hermes 的创建很优雅,GBrain 的验证很扎实,两者缺一不可。
整个故事的核心
在健康的软件工程团队里,每一个 bug 都对应一个测试。那个测试永久存在。Bug 从结构上无法复发。
AI 智能体也应该这样。
每一次失败 → 一项技能 → 带完整的评估 → 每天自动运行。
智能体的判断力不只在当前会话里得到提升,而是永久性地、系统性地被过去的失败所塑造。
Garry Tan 有句话我特别记得:「一年后和我一起工作的那个智能体,将会被它在过去一年中犯的每一个错误所塑造。」
这不是优化。这是整个框架的核心。
后记
我自己也在做类似的事。这段时间一直在给 Agent 写 Skill,每次遇到重复问题就固化它。说实话没有 Garry Tan 的十步清单那么完整,但方向一致。看到他把这件事系统化到这个程度,我觉得这可能是当前 AI Agent 领域最被低估的实践。
不是更大的模型。不是更贵的框架。不是更长的上下文。
就是:把每一次失败变成一项永远不会再犯的技能。