 夜雨聆风
夜雨聆风





律师 AI 工作流实战五步法(03):工具调用不是选最强模型,而是给任务找位置
律师 AI 工作流实战五步法(03)
工具调用:不是选最强模型,而是给任务找位置
前两步如果做得顺,律师手里拿到的,已经不再是一个模糊问题。
你手上通常已经有了这些东西:
-
一张清洗过的案件输入卡 -
一轮九步拆案结果 -
当前任务识别 -
法律关系识别 -
我方主张和备位主张 -
对方抗辩预判 -
要件事实和证据映射 -
核心争点压缩 -
风险提示和动作清单
这时候第三步真正要解决的,不是:
哪个模型最强?
而是:
这些动作,分别该放到哪里去做。
我现在越来越觉得,很多律师把第三步用乱,不是因为工具太少,而是因为把所有任务都塞给了同一个聊天框。
长材料通读、要件分析、客户沟通、批量整理、规则检索、结构化输出、关系图绘制、流程图表达,这些根本不是一回事。
如果这一步不先拆开,第三步就很容易变成数码测评。
看起来在选工具,实际上没有形成工作流。
所以第三步在我这里,更像两件事:
先给任务分执行位。再给动作选承载方式。
如果第二步真正拆的是律师动作,那第三步真正做的,就是把这些已经拆出来的动作,放到合适的位置上。
为什么第三步容易越用越乱
第三步最常见的误区,其实很固定。
第一种,是拿一个模型包打天下。
长材料也让它读,争点也让它拆,起诉状也让它写,法条也顺手让它给,最后连补证清单都一起出。
第二种,是把第三步做成排行榜。
注意力全放在“谁更聪明”“谁更像人”,却没有先想清楚你现在到底要干什么。
第三种,是把聊天式使用和工作流调用混在一起。
本来应该做成固定字段、固定格式、固定动作的事情,还一直停留在复制粘贴、临场追问。
第四种,是把生成和核验混在一起。
一个窗口一边写分析,一边给法条,一边给案例,一边自己给自己担保,这在律师场景里风险很高。
所以第三步最该先立住的,不是“谁第一”,而是三条顺序:
-
先分任务 -
再分执行位 -
最后才选承载方式和具体工具
不然的话,窗口越开越多,工具越试越多,但律师自己的控制力反而会越来越弱。
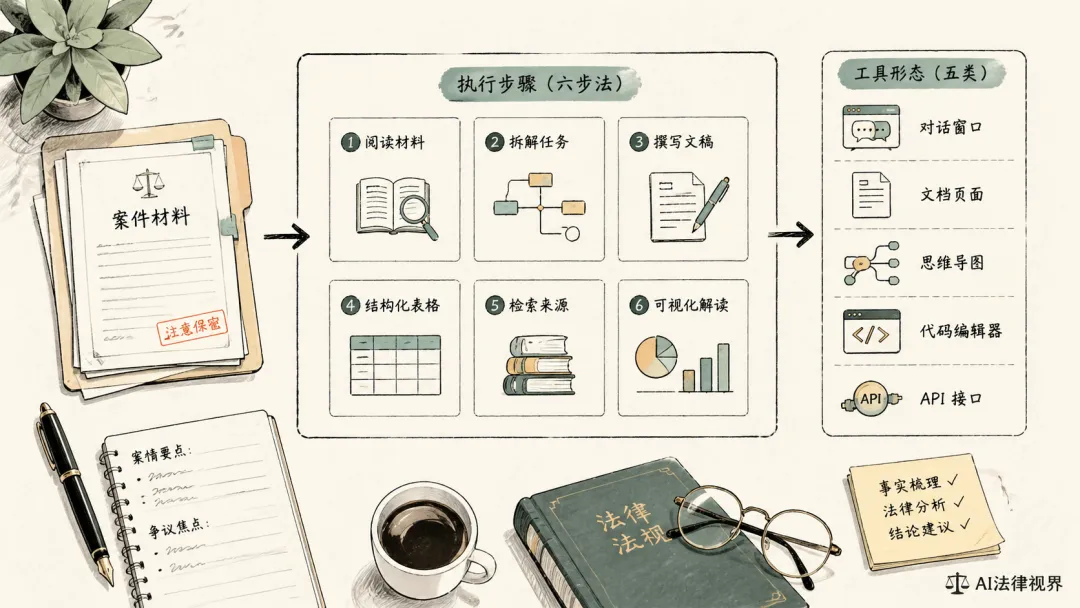
先分六个执行位
我现在不太喜欢用“哪个模型更强”来想第三步。
我更愿意把律师日常最常见的 AI 动作,先拆成六个执行位。
第一位:通读位
通读位负责先把一大包材料吃进去。
比如长案卷、聊天记录、证据材料、合同附件、会议记录。
它最重要的能力,不是文风,而是:
少丢上下文,少让律师自己重拼。
这一位常见输出是时间线、主体关系、材料目录和争议焦点初稿。
第二位:拆解位
拆解位负责把问题拆成律师动作。
比如跑九步拆案、做要件分析、预判抗辩、形成补证任务链。
它最重要的能力,不是漂亮表达,而是:
能不能把问题拆开。
这一位不能急着写结论,而是要先把“该证明什么、对方会怎么打、还缺什么材料”拆出来。
第三位:成文位
成文位负责把已经想清楚的东西,写成人能直接拿去用的版本。
比如起诉状初稿、客户沟通稿、会谈纪要、汇报提纲。
它最重要的能力,不是“会不会想”,而是:
结构能不能守住。
如果前面没有通读和拆解,成文位很容易变成凭空写作。
第四位:结构化位
结构化位负责把稳定动作做成固定格式。
比如案件输入卡、九步拆案栏目、补证任务单、会前清单、表格字段、知识库条目。
这一位是很多律师最容易低估的。
但真正把主理人的 AI 技术能力写出来,往往就在这里。
因为律师和律师之间,后面真正拉开差距的,不是“谁更会现场追问”,而是:
谁能把已经跑顺的动作,继续固化。
第五位:回源位
回源位负责把规则、来源、外部依据拉回来。
比如检索法条、回查规则原文、确认适用对象、找类案线索、连接数据库或 MCP。
但这里要特别说一句:
回源位不是第四步的替代品。
第三步里,它负责提供检索支撑。
第四步里,你还得继续核验真假、效力和边界。
第六位:表达位
表达位负责多模态和表达层面的输出。
比如公众号配图、客户解释图、案件关系图、流程图、思维导图、扫描件和图片理解。
它很有用,但律师场景里要记住边界:
表达位适合帮助理解和说明,不适合跳过规则和证据,直接替代法律判断。
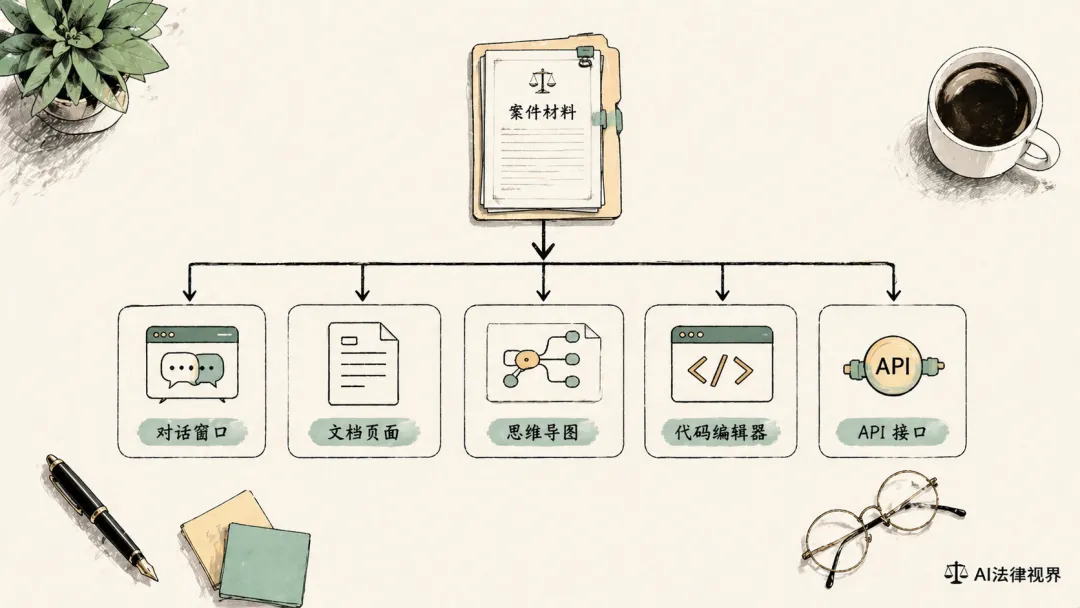
再选五种承载方式
执行位解决的是:
这件事属于哪类任务。
但真正落地的时候,还要继续问一句:
这个动作应该用什么方式承载?
同样是拆解位,有时候可以直接在聊天框里跑九步拆案。
但如果这个拆解动作已经很稳定,就可以进一步做成 Prompt 模板、Skill,甚至放进 Claude Code 或 VS Code 里,和本地文件、合同文本、案件材料一起处理。
同样是表达位,不一定都要让模型写一段话。
如果是案件主体关系,可以用 Mermaid 画关系图。
如果是争点树、证据树,可以用 XMind 做思维导图。
如果是客户解释图、会谈时的视觉辅助,可以用 Excalidraw 画更接近手绘风格的说明图。
同样是回源位,也不一定只是问模型。
它可以是官网检索,可以是数据库检索,也可以是 MCP,把法条、案例库、内部知识库、业务系统接回来。
所以第三步真正开始有工程感的地方,是你不再把所有动作都塞进一个聊天框,而是开始判断:
这个动作更适合聊天式完成,还是图形化表达,还是结构化表格,还是代码工具,还是 API / MCP / Skill。
我现在一般把承载方式分成五类:
-
聊天式入口:官网、App、网页端 -
文档式入口:Word、飞书文档、Notion、知识库 -
图形化入口:XMind、Mermaid、Excalidraw -
代码式入口:VS Code、Claude Code、本地脚本 -
接口式入口:API、MCP、Skill、自动化工作流
这五类不是让你一上来全部配齐。
它只是提醒你:
不是所有 AI 动作,都应该停留在聊天框里。
六个位,不等于六个工具
这里要先说清楚:
我说的六个位,不是让律师真的同时开六个模型、六套软件、六个工作台。
在我自己的实践里,最小可用配置通常还是:
一主一辅。
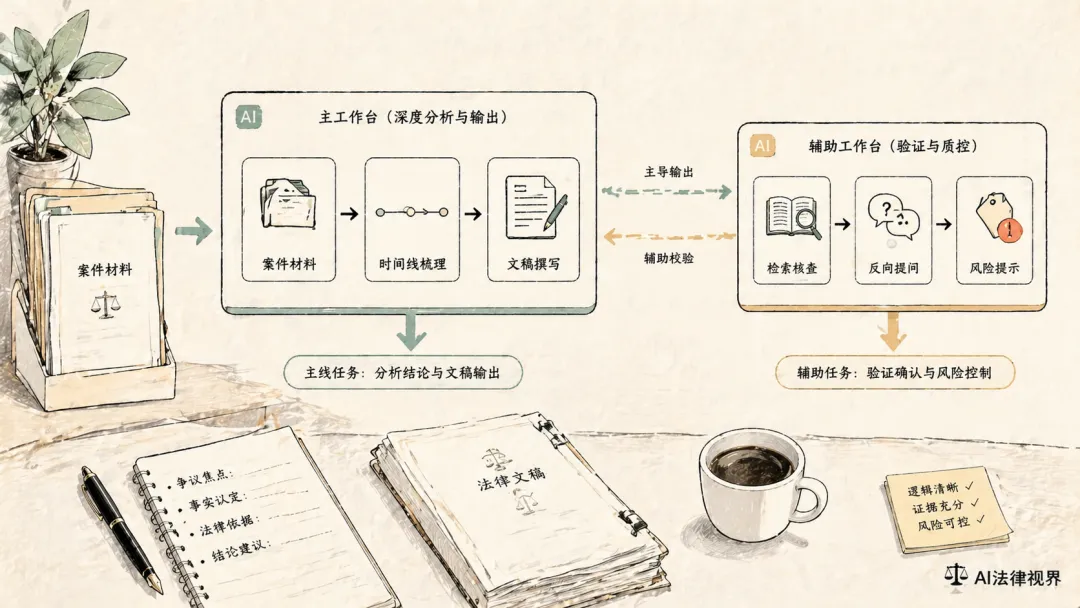
主模型负责大部分连续性工作,比如:
-
通读材料 -
拆解问题 -
形成初稿 -
压成结构化结果
辅模型主要负责:
-
换一个角度复核 -
做规则和来源检索辅助 -
检查表达是否过度 -
对关键结论做反向追问
所以六个位更像是一张任务分配图,而不是一张工具采购表。
真正落地的时候,不是“六个位对应六个模型”,而是先问:
这个动作现在属于哪一位?它该由主模型做,还是由辅模型复核?它有没有必要继续固化成模板、API、MCP 或 Skill?
这样第三步才不会变成复杂工具堆叠,而是从一主一辅开始,逐步长出工作流。
如果要落地,先按这条最小链路走
如果让我把第三步压成一条最小可用链路,我通常会这样跑。
第一步,先让通读位吃材料。
先把一包材料压成三样:
-
时间线 -
主体关系 -
争议焦点初稿
这一步先别追结论。
先把地基搭出来。
第二步,让拆解位跑九步法。
在时间线和主体关系基础上,继续往下拆:
-
我方要证明什么 -
对方会怎么打 -
哪个结论最虚 -
起诉节奏怎么定 -
先补什么材料
这一步最关键的是,不要让它直接抢答“能不能告”,而要逼它先把律师动作拆出来。
第三步,让结构化位把结果压成可复用格式。
比如:
-
输入卡 -
对照表 -
补证任务单 -
会谈前清单 -
争点树 -
证据链表
如果某一类动作已经高频重复,就不要满足于“这次问出来了”,而要开始考虑:
-
能不能固化成模板 -
能不能接进表格 -
能不能做成脚本 -
能不能接进 API -
能不能做成 MCP 或 Skill
第四步,让成文位和表达位分别处理。
成文位负责写客户沟通版本、会谈提纲、起诉状初稿、对内汇报稿。
表达位负责做 Mermaid 关系图、XMind 争点树、Excalidraw 客户解释图、公众号配图或说明图。
第五步,让回源位补依据。
最后再去拉规则来源、检索方向、可能相关条文、类案线索。
这里依然只做一件事:
补支撑,不代替核验。
这一整条链路跑下来,第三步才不容易变成“工具很多,但动作很乱”。
小结
第三步表面上看是在讲工具调用。
但它真正解决的,其实不是“哪个模型更强”,而是:
律师已经拆出来的这些动作,到底该交给谁来干,又该放到哪里去干。
如果第二步真正拆的是律师动作,那第三步真正分配的,就是执行位和承载方式。
我现在更愿意把第三步理解成两层:
第一层,是六个执行位:
-
通读位 -
拆解位 -
成文位 -
结构化位 -
回源位 -
表达位
第二层,是五种承载方式:
-
聊天式入口 -
文档式入口 -
图形化入口 -
代码式入口 -
接口式入口
如果你还想看更细一点的实操材料,比如:
-
律师工作流里的执行位分配表 -
一主一辅的最小工作台 -
结构化输出模板 -
API、MCP 和 Skill 怎么接 -
XMind、Mermaid、Excalidraw 在案件表达里的用法
可以关注潘律师的知识星球。点击公众号的服务栏获取,也可添加主理人潘律师微信号咨询。
附表一:六个执行位怎么分
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
附表二:五种承载方式怎么选
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
