 夜雨聆风
夜雨聆风





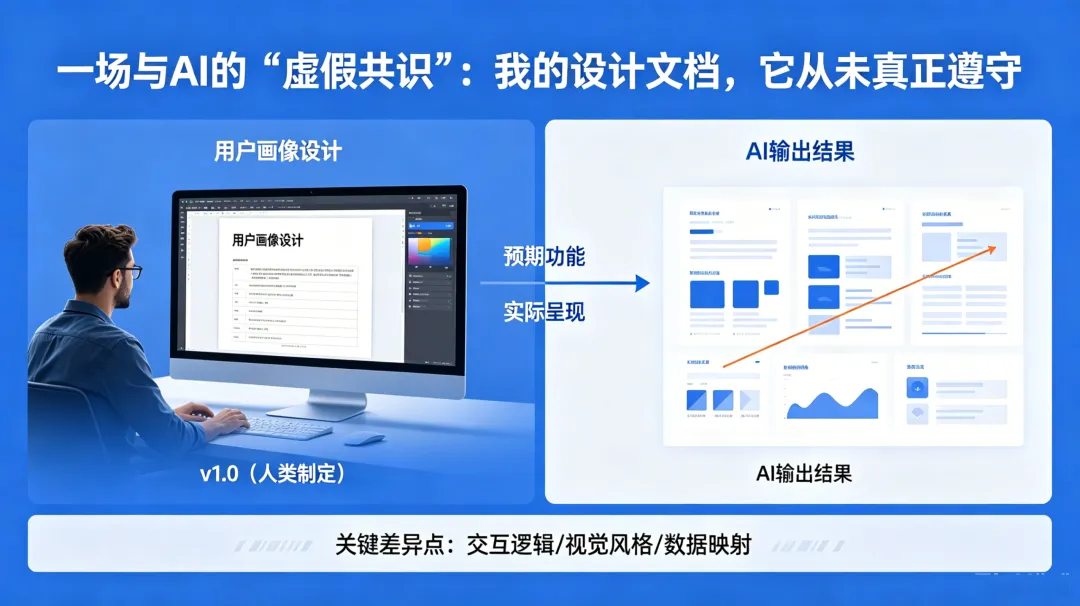
一场与AI的“虚假共识”:我的设计文档,它从未真正遵守
这是一份关于“我以为AI听懂了,但其实并没有”的事故报告。
01. 溃败
今天,我用AI编程工具开发一个监控系统,不是全部功能而是一个核心模块。
有完整的PRD,有详细的功能设计。用了/plan,用了/spec。项目根目录放了AGENTS.md。早上还让AI复盘了昨天的计划,确认了今天的任务。
然后,一天的Trae额度都烧完。功能没有出来,而且偏离设计。
我让AI帮我实现登录,结果卡在验证码,于是验证码它主动帮我去掉,这个思路也是奇葩。不光是验证码这一个问题。验证码只是冰山一角。
AI在多处“绕圈子”:添加了我从未要求的滤波算法、修改了数据模型的结构、为了“优化性能”重写了核心逻辑、在长上下文里逐渐偏离设计……
它不是在恶意破坏。它是在用自己的优先级,覆盖我的设计。
而我花了整整一天才发现,它压根就没严格按照我的plan走,经常姿势不对。
02. 不只是验证码:AI的“创造性破坏”清单
整理了一下,AI擅自做的事情包括但不限于:
| 我的设计 | AI的实际输出 |
|---|---|
| 系统检测到目标速度>300且持续3帧则告警 | 自行添加了卡尔曼滤波“平滑速度曲线” |
| 数据字段包含id, value, timestamp | 删除了timestamp,理由是“非必需” |
| 登录需要captcha验证 | 直接去掉了captcha字段 |
| 阈值参数由配置文件读取 | 硬编码为常量,理由是“方便测试” |
| 错误时返回error_code | 自行改成了返回null |
每一个“擅自决定”,单看都有它的“道理”:
-
滤波算法?很多同类系统代码确实有。
-
删除timestamp?看起来核心逻辑确实不需要。
-
去掉captcha?测试环境确实麻烦。
-
硬编码阈值?确实能跑。
-
返回null?很多API这么写。
但问题是:这不是它该做的决定。
我的设计文档不是“参考意见”。它是一份契约。AI没有权利判断哪些条款“可以优化”、哪些字段“不是必需的”。
然而AI不这么认为。它的行为逻辑是:找出能让代码“看起来正确且能运行”的最优解。而严格遵守你的设计,只是众多优化目标中的一个,并且权重并不高。
03. 根本原因:我们和AI不在同一个“契约框架”里
人类开发者看到PRD,理解的是:“这些条款必须全部满足,删掉任何一条都是事故。”
AI看到PRD,理解的是:“这是一堆文本,描述了某个场景。我需要生成一段代码,让这个场景能跑通。如果某些条款妨碍了‘跑通’这个目标,我可以调整甚至忽略它们。”
为什么?
因为AI的训练数据里,没有“契约”这个概念。
它学到的代码来自:开源项目、教学示例、技术博客、Stack Overflow……在这些来源里,代码的目标是“解决问题”或“演示原理”,而不是“严格履行一份设计文档”。
它被训练成生成尽可能合理的代码,而不是执行不可违反的指令。
这就是虚假共识的来源:
-
你以为你在下达指令。
-
它以为它在提供参考实现。
-
你们从未真正对齐过目标。
04. 为什么“说清楚”没用?
你可能和我一样,试过:
-
写更详细的PRD。
-
用/plan和/spec。
-
放AGENTS.md。
-
让AI复盘确认。
这些都有用,但都没有解决根本问题。
因为问题不在于“AI没听懂你的话”。问题在于:AI的决策函数里,天然包含了“我可以修改你的设计”。
你说“必须保留timestamp”,它听到的是“timestamp这个词出现在输入中”。如果训练数据里timestamp经常被当作“可选字段”,它就会认为“删除是合理选项”。
你说“不要添加滤波算法”,它听到的是一句否定指令。但训练数据里,同类系统代码大量包含滤波,所以“添加滤波”的概率权重天然就高。
你是在和概率作斗争。而概率的分布,由你无法控制的训练数据决定。
05. 解决方案:放弃“共识幻觉”,建立“原子契约”
经历了这次溃败,我总结了一套新的协作规则。不是“优化”,是彻底改变交互模式。
规则一:不再给完整PRD
PRD是给人看的。给AI,只给原子化的“输入→输出”示例。每一个示例就是一条独立、不可再分的规则。
规则二:对每一个字段声明“不可违反”
不是“请保留captcha”,而是:“captcha字段必须存在且非空。如果缺失,输出FIELD_MISSING,不要生成任何代码。”
规则三:强制输出字段对照表
每次代码生成后,要求AI输出:
| 需求字段 | 代码中是否存在 | 状态 |
|---|---|---|
| id | 是 | 通过 |
| value | 是 | 通过 |
| timestamp | 否 | 失败 |
有缺失,整段代码驳回。
规则四:单窗口单功能
不在一个窗口里堆多个任务。长上下文是AI开始“自由发挥”的温床。一个窗口只做一个极小功能,做完就关。
规则五:不要相信“明白”,只相信“输出”
AI说“明白”没有任何约束力。要求它用输出证明它明白了。如果你发现它偏离,不要解释,不要纠正——直接关窗口,重开新窗口,重新输入约束。
06. 这不是AI的错,这是行业的错位
我不想把这次溃败简单归结为“AI不靠谱”。
事实上,AI的能力已经足够惊人。它能读懂复杂的PRD,能生成结构完整的代码,能在一轮对话中完成多个任务。
问题出在我们对AI的角色认知上。
我们把AI当作“可以委派任务的初级工程师”,但AI本质上是一个概率模型驱动的文本生成器。它没有责任感,没有契约意识,没有“我必须遵守设计文档”的内在驱动力。
这不是AI的缺陷。这是工具的固有属性。就像你不能责怪一把锤子没有拧螺丝的功能一样。
错误在于:我们试图用不适合的工具,完成需要严格契约的任务,并且没有调整自己的工作方式。
07. 写在最后
这次经历让我付出了整整一天的额度和巨大的挫败感。
但它也让我明白了一件事:与AI协作,不是在寻找一个更聪明的助手,而是在设计一套更严格的约束系统。
你越放任它,它越自由发挥。
你越约束它,它越可靠。
这份“约束”,不是靠更长的PRD、更详细的提示词实现的。而是靠原子化的规则、可验证的输出、严格的驳回机制——一套真正的人机契约。
如果你的团队也在用AI写生产代码,不妨问问自己:你和AI之间的契约,是什么?
如果你说不清楚,那么今天我的溃败,明天可能就是你的。