机器学习二分类模型的评估图形和指标简要说明-混淆矩阵衍生指标
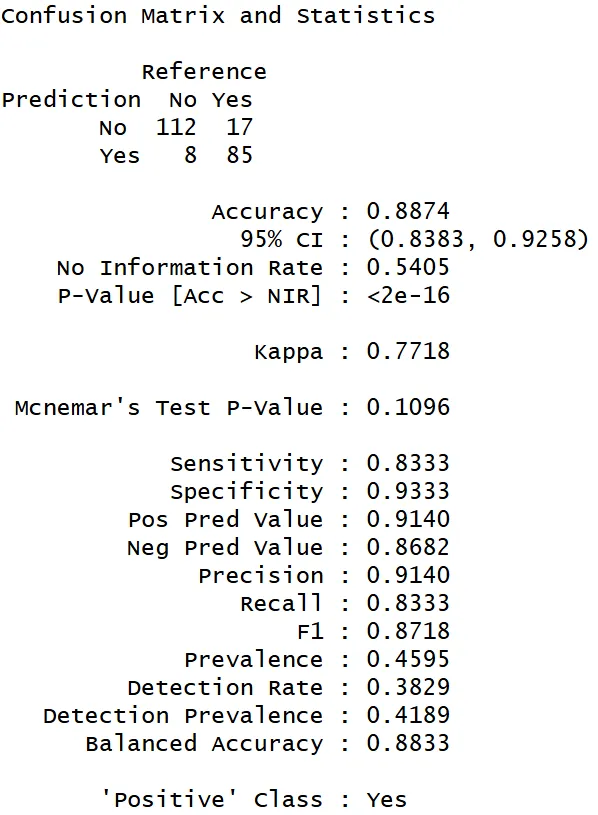
#混淆矩阵 及其衍生指标是评价#机器学习 #分类模型 的基础。混淆矩阵由模型预测类别和实际类别比较得到。如下所示是由#R语言 #caret包 的confusionMatrix函数输出的混淆矩阵对象,其中上面部分是传统的混淆矩阵,下面是基于混淆矩阵计算的各项指标。
在这个混淆矩阵中,列方向是实际类别,行方向是预测类别,Yes为阳性类别。具体而言:
在所谓TN、FP、TP、FN的概念中,N和P是指预测类别是阴性和阳性,T和F是指预测是否正确。
Accuracy,正确率,即预测正确的样本量占整个数据集的样本量比例,也即(TP+TN)/(TP+FP+TN+FN),其值介于0~1之间,越接近1越好;
No Information Rate,缩写为NIR,无信息比率,即样本中大类样本的实际占比,也即max(TP+FN, TN+FP)/(TP+FP+TN+FN)=max(85+17, 112+8)/(85+8+112+17);
P-Value [Acc > NIR],即关于正确率和无信息比率的大小关系的假设检验,跟前面正确率的95%置信区间均基于二项检验,p值小于指定的显著性水平则说明正确率显著高于无信息比率,也即预测优于随机盲猜;
Kappa旨在度量预测类别和实际类别的一致性,一般0.3以上即一致性尚可;
Mcnemar检验旨在检验预测类别和实际类别的差异显著性,p值大于指定的显著性水平则说明两者无显著差异;
Sensitivity,敏感性,即实际为阳性的样本中被预测为阳性的比例,也即TP/(TP+FN),其值介于0~1之间,越接近1越好;
Specificity,特异度,即实际为阴性的样本中被预测为阴性的比例,也即TN/(TN+FP),其值介于0~1之间,越接近1越好;
通俗理解,Sensitivity度量模型识别阳性的能力,Specificity度量模型识别阴性的能力,两者共同构成ROC曲线;
Precision,查准率,即被预测为阳性的样本中实际为阳性的比例,也即TP/(TP+FP),旨在度量阳性预测的准确性,其值介于0~1之间,越接近1越好;
Recall,查全率,也称召回率,即实际为阳性的样本中被预测为阳性的比例,也即TP/(TP+FN),与Sensitivity计算公式相同,其值介于0~1之间,越接近1越好;
F1,一般计算为Precision和Recall的调和平均数,两者越接近且越趋近于1,则F1越大。
以上即混淆矩阵部分衍生指标的简单介绍,其他未尽事项后续继续推文介绍。
 夜雨聆风
夜雨聆风