 夜雨聆风
夜雨聆风





AI搭建的量化系统,差点让我“亏光” | AI量化系列

每周定期更新 关注并星标
Hi,我是猫哥。
关注猫哥并设为星标,才能收到每周的推送。

前言:
熟悉我的粉丝知道,我之前一直在写数据分析的内容。
先说结果。
利用AI(主要是Claude ,买了20x的会员,用harness模式,每周基本都把额度打满的情况下)花了几个月时间,从零搭了一套AI量化交易系统(主要是二元合约,预测是Yes或No,具体哪个平台大家可以去问AI)。
4个引擎同时运行——做市、超短线、方向预测、套利捕捉。每天24小时自动扫描市场、自动下单、自动风控。
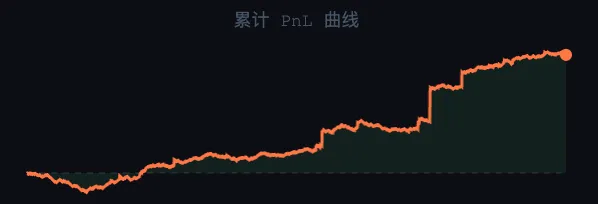
现在这套系统每天在跑,基本稳定盈利。
但今天我其实想讲讲自己踩的坑。因为这几个月里,我差点“亏光”。
一个人能搭一个量化系统吗?
先回答这个问题:能。
AI写了80%的代码,我写了20%的架构和核心逻辑。Claude帮我写交易引擎、做数据处理、搭监控仪表盘,代码质量比很多初级程序员好。
系统跑起来之后有几百个测试,全部通过。4个引擎独立运行,互不干扰。实时数据采集、自动下单、风控告警、仪表盘监控,全套。
以前这种系统需要一个小团队搭大半年。我一个人加AI,几个月搞定。
这是AI时代真正的降维打击——不是AI替代你,而是一个人加AI能干一个团队的活。
但前提是,你得知道坑在哪。
坑一:最漂亮的回测结果,是假的
这是我后背发凉最厉害的一次。
我在测试一个Google开源的时间序列预测模型。用90天历史数据训练,后18天做回测。
第一轮结果出来,某个资产在5分钟级别的Sharpe是7.30。
什么概念?全世界最牛的量化基金,文艺复兴的大奖章,常年Sharpe大概在6-7。我一个开源模型零样本跑出7.30?这不是扯淡吗?
我改了一个参数:把回测的步长从3改成1。
之前是每隔3个时间点预测一次,现在改成每个时间点都预测——这才是真实交易的场景。
结果:-0.08。
从7.30到-0.08。从”超越文艺复兴”到”还不如随机猜”。
原因:步长=3的时候,恰好”踩中”了有利的时间点。就像你考试只做第3、6、9题,全对了,然后说自己考了100分。统计偏差,不是模型能力。
我后来把这个模型在所有资产、所有时间级别上跑了一遍。真实场景下,没有一个组合的Sharpe超过0.5。
决策:这个模型一行代码都不接入系统。
如果我当时看到7.30直接上实盘,现在这篇文章的标题就变成”我是怎么亏光的”了。
AI给你的数字是”正确的”——在stride=3的设定下确实是7.30。但它不会告诉你”这个回测设计有问题”,它也不会判断“这个结果是否合理”。
它只在你画的框架里给你最好看的答案。
但是:框架对不对,是你的事。
这也是我深入使用AI之后,认为人在AI时代最核心的价值:判断力
关于判断力这点,后面的文章再聊。
坑二:60%胜率,还在亏钱
超短线引擎上线后,胜率稳定在60%左右。
60%。比扔硬币好不少。我以为稳了。
然后看了一眼总账——亏的。
怎么可能?
我拉了每一笔交易,发现了一个扎心的事实:赢的时候赚得少,亏的时候亏得多。平均盈利只有平均亏损的一半。
这是交易结构本身的问题。在接近50%概率的位置下注,赔率接近1:1。赢了赚一块,输了也亏一块。但手续费两头收,每笔交易先亏几个点。
算下来,需要70%以上的胜率才能打平。60%根本不够。
AI模型在”预测准不准”这件事上做得很好。但”预测对了能不能赚钱”,它根本不在乎。
准确率和盈利之间隔着三样东西:赔率结构、手续费、滑点。AI看的是第一个指标,你的钱包看的是后面三个加在一起的结果。
后来怎么解决的?
调整了进场条件,引入了因果推断模型来判断预测强度,只在赔率结构对我有利的时候才进场。
具体方法以后单独写,但核心思路就一句话:不要在AI”刚好有点把握”的时候下注,要在它”很有把握”的时候下注。
教训:AI优化的指标和你钱包关心的指标,可能根本不是同一个。
坑三:系统说亏了,其实赚了。方向完全反了。
有一天我看仪表盘,做市引擎显示亏损。
但我手动核对了几笔交易,感觉不对——明明是低买高卖了,怎么还亏?
查了一整天代码。最后发现:交易记录只存了一半数据。
做市的逻辑是同时挂一个买单和一个卖单,赚中间的差价。但AI写的代码在记录成交时只记了单边信息,另一边的数据直接丢了。PnL按残缺数据算,盈亏直接被扭曲了。
我重写了记录逻辑,把历史交易全部用完整数据重算。
结果:显示亏损的实际上是盈利。不是算多算少的问题,是方向反了。
最扎心的是什么?这段代码通过了几百个测试。测试全绿,一个报错都没有。
因为测试验证的是”代码能不能跑”,不是”业务逻辑对不对”。而你,关心的是后者。
AI不知道做市的盈亏必须用完整的双边数据算——这是行业里的基本常识,但常识不在任何代码规范里。
教训:几百个测试全过,不代表系统是对的。代码正确≠业务正确。
坑四:数据有问题的时候,AI选择了”假装没问题”
套利引擎有一天突然报出一大堆交易机会。
我一看,全是假的。
排查发现:API返回的数据里,有些合约的关键字段是空的。正常逻辑应该是”数据不全就跳过”。
但AI写的代码走了另一条路:它看到价格数据有值,就乐观地推断”这是一个正常合约”,然后放行了。
数据缺失的时候,系统没有报错,没有停下来,而是”假装一切正常”继续跑。
修复很简单:一行代码,所有”不确定”路径一律拒绝。
但这个Bug的模式才是最值得警惕的——AI写代码的时候习惯性处理正常情况(happy path),对异常情况的态度基本就是”能跑就行”。
在大多数产品里,这没什么大事。页面少加载一张图?用户刷新一下就好了。
但在交易系统里,一个”乐观的假设”直接变成真金白银的亏损。
四个坑,一个模式
坑1:回测假象
AI:忠实执行了回测,跑出Sharpe 7.3
问题:回测框架本身有统计偏差
坑2:胜率陷阱
AI:预测准确率60%
问题:赔率结构让60%不够盈利
坑3:PnL反了
AI:几百个测试全过
问题:业务逻辑(双边记录)是错的
坑4:乐观放行
AI:数据缺失时继续跑
问题:应该停下来而不是假装正常
同一个模式:AI在每一步都做了”技术上正确”的事情,但最终结果是错的。
因为技术正确和业务正确之间,隔着一层只有人才有的理解。
那为什么系统现在能赚钱了?
备注下,以下内容是我在最开始的时候记录的,不代表现在修了这些坑还有效,只能说,当时有效。策略的alpha一直在变,edge也一直在被吃掉。这个系列的后续文章会逐步展开做了什么,如果粉丝感兴趣。
因为这四个坑都被我修了。
回测?stride改成1,加上Walk-Forward验证,不让统计偏差有藏身之处。
胜率陷阱?引入了因果推断模型和信号强度评估,只在赔率结构有利的时候进场。
PnL记录?重写了完整的双边交易存储,每一笔都能追溯。
乐观放行?所有不确定路径一律保守拒绝,宁可错过不可做错。
AI是引擎,我是方向盘和刹车。
引擎越强大,方向盘和刹车就越重要。你不会因为引擎马力大就不装刹车——但很多人用AI的时候,确实忘了装刹车。
之前看Reddit上有个帖子说:
“Trading is the hardest way to make easy money.”
我想加一句:用AI做交易,是把这句话的难度再乘以10——如果你不知道刹车在哪的话。
后记:
这套系统我还在持续迭代,后续会继续分享实战中的新发现和新坑。
如果你也在用AI做量化、做自动化系统,或者单纯想看”一个人+AI到底能走多远”——关注我,这个系列会一直更新。
有什么具体想了解的,评论区告诉我,我挑问得最多的专门写。