 夜雨聆风
夜雨聆风





字节大模型二面:PDF 表格解析准确率只有 32%,你们的 RAG 系统怎么保证答案质量?
大家好,我是吴师兄。
文档解析是 RAG 系统里最容易被忽视的环节。很多人三行代码搞定解析——PyMuPDF 提取文本、按段落切分、入库——然后把精力全放在 Embedding 和 Prompt 上,结果上线后发现用户涉及表格数据的问题答案全是错的。
这道题的考察逻辑是:你是否真正关注过 RAG 系统的”第一公里”——文档内容本身的质量。解析错了,后面做得再好都是在错误的基础上优化。
回答这道题的主线是:文档解析不是”提取文本”,而是”还原结构”——特别是表格,结构丢了语义就丢了,后续所有召回和生成都建立在错误信息上。
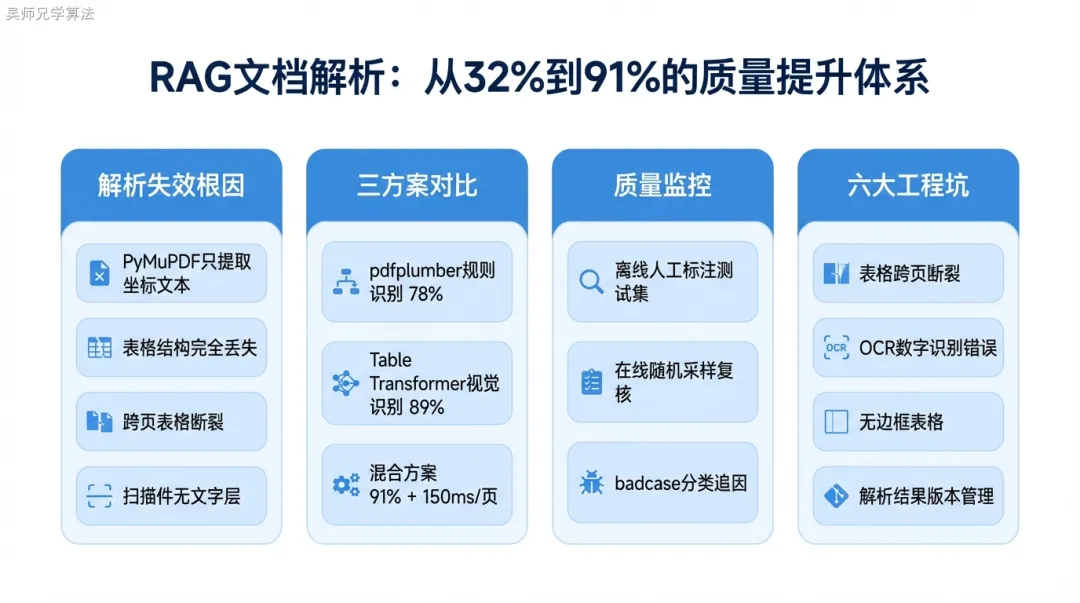
PyMuPDF 的表格解析为什么只有 32%
先看最常见的出问题方式:
import fitz # PyMuPDF def parse_pdf_naive(pdf_path: str) -> str: doc = fitz.open(pdf_path) text = "" for page in doc: text += page.get_text() # 只提取文字,丢弃所有布局信息 return textget_text() 的工作原理:按从上到下、从左到右的坐标顺序提取文本块,完全忽略表格的行列结构。
PDF 里的表格本质上是一堆”在特定坐标位置放置文字”的指令集——”45 岁”放在 (120, 340),”3500 元”放在 (280, 340),”年缴”放在 (280, 280)。没有任何语义标记说”这是一张费率表”,更没有说”这两个单元格在同一行”。PyMuPDF 按坐标顺序提取,同一行的”45 岁”和”3500 元”可能被分到不同行,”年缴”表头可能被插入到数据中间。
实际后果:用户问”45 岁投保重疾险保费多少”,系统召回的文档里”45″和”3500″已经被拆开了,LLM 面对这堆碎片根本无法正确理解——它能感知到数字存在,但不知道对应关系。我们人工检查了 50 份包含表格的 PDF,PyMuPDF 表格解析准确率只有 32%,主要失败类型:
- 表格结构丢失
:3列5行的费率表变成无结构数字堆 - 单元格内容错位
:”45 岁”和”3500 元”在同一行,解析后被拆到不同位置 - 表头丢失
:列名(年龄、保费、保额)完全消失,只剩数据没有标签
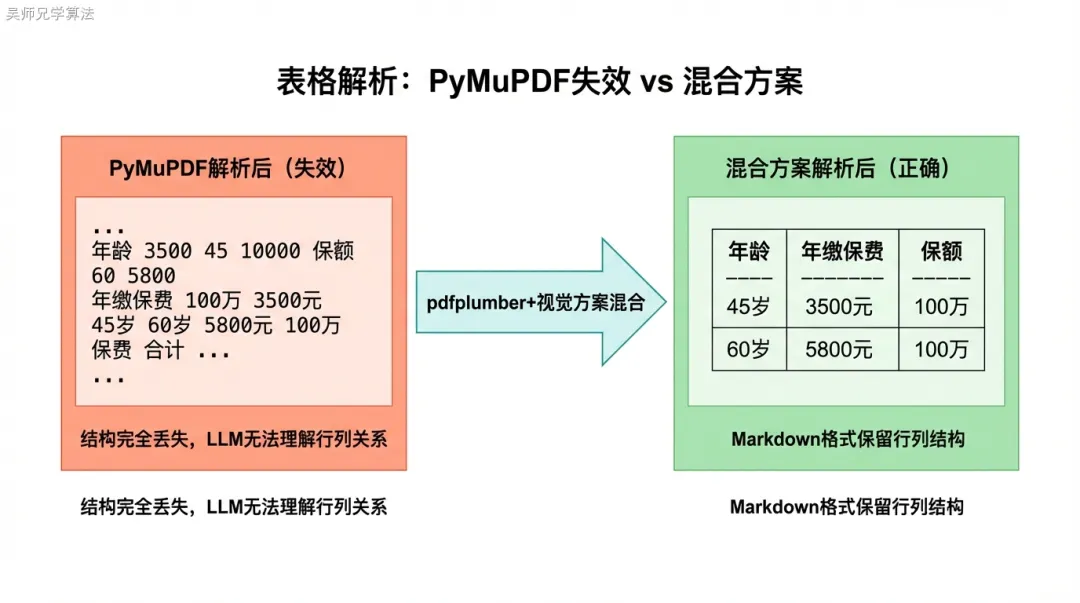
三种方案对比
方案1:pdfplumber(规则识别)
pdfplumber 分析文本块的坐标和间距推断表格结构,把识别结果转成 Markdown:
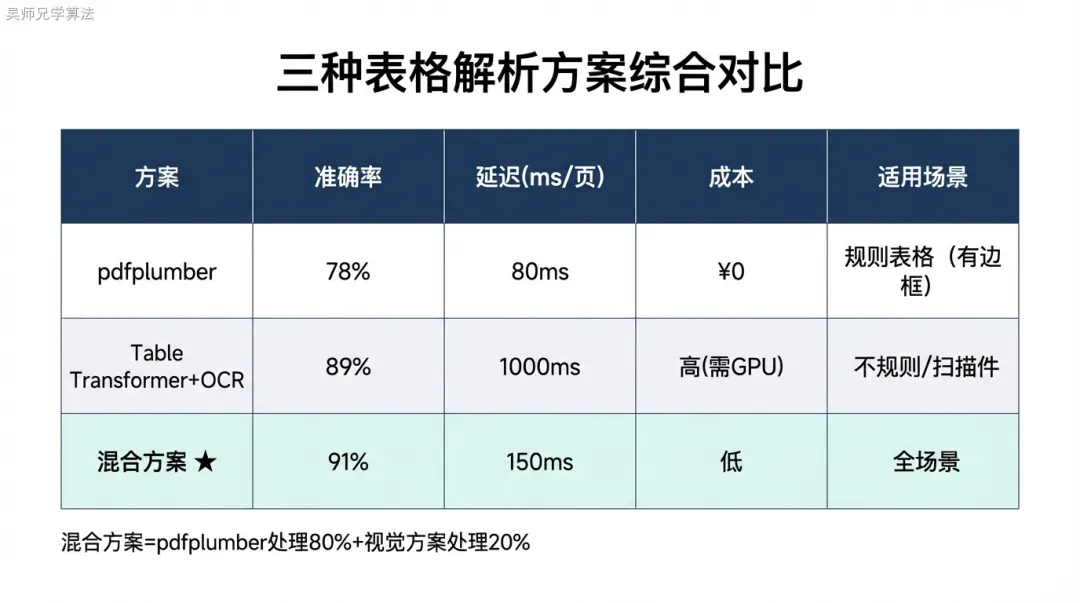
import pdfplumber def extract_tables_pdfplumber(pdf_path: str) -> list[str]: tables = [] with pdfplumber.open(pdf_path) as pdf: for page in pdf.pages: for table in page.extract_tables(): if not table or len(table) < 2: continue # 第一行作为表头,转 Markdown 格式 header = "| " + " | ".join(cell or "" for cell in table[0]) + " |" sep = "|" + "|".join(["---"] * len(table[0])) + "|" rows = ["| " + " | ".join(cell or "" for cell in row) + " |" for row in table[1:]] tables.append("\n".join([header, sep] + rows)) return tables准确率从 32% 提升到 78%。优点:速度快(50-100ms/页),开源免费。缺点:对无边框表格、合并单元格、扫描件完全无效。
方案2:Table Transformer + OCR(视觉识别)
微软开源的 Table Transformer 基于目标检测架构,把表格识别当作视觉任务:
from transformers import TableTransformerForObjectDetection from PIL import Image import torch def extract_tables_visual(pdf_path: str) -> list[str]: model = TableTransformerForObjectDetection.from_pretrained( "microsoft/table-transformer-detection" ) images = convert_pdf_to_images(pdf_path) tables = [] for img in images: inputs = processor(images=img, return_tensors="pt") outputs = model(**inputs) results = processor.post_process_object_detection( outputs, threshold=0.7, target_sizes=torch.tensor([img.size[::-1]]) )[0] for box in results["boxes"]: table_img = img.crop(box.tolist()) table_text = ocr_and_structure(table_img) # OCR + 结构还原 tables.append(table_text) return tables准确率提升到 89%,对无边框表格和扫描件有效。代价:速度慢(800-1200ms/页,是 pdfplumber 的10倍以上),需要 GPU 推理。
方案3:混合方案(最终选择)
先用 pdfplumber 快速处理,质量检查不通过再降级到视觉方案:
def extract_tables_hybrid(pdf_path: str) -> list[dict]: results = [] with pdfplumber.open(pdf_path) as pdf: for page_num, page in enumerate(pdf.pages): for table in page.extract_tables(): if is_valid_table(table): results.append({ "page": page_num, "content": table_to_markdown(table), "method": "pdfplumber" }) else: # 质量不达标,降级到视觉方案 img = page_to_image(page) visual_table = extract_table_visual(img) results.append({ "page": page_num, "content": visual_table, "method": "visual" }) return results def is_valid_table(table: list) -> bool: if not table or len(table) < 2: return False # 检查1:每行列数一致(结构完整性) col_counts = [len(row) for row in table] if len(set(col_counts)) > 1: return False # 检查2:空单元格不超过30% total = sum(col_counts) empty = sum(1 for row in table for cell in row if not cell or not cell.strip()) if empty / total > 0.3: return False # 检查3:包含数字(表格应该有数据) has_nums = any(any(c.isdigit() for c in (cell or "")) for row in table for cell in row) return has_nums效果:准确率 91%,平均延迟 150ms/页(80% 的表格 pdfplumber 处理,20% 降级到视觉方案)。
三方案对比:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
91% | 150ms |
|
|
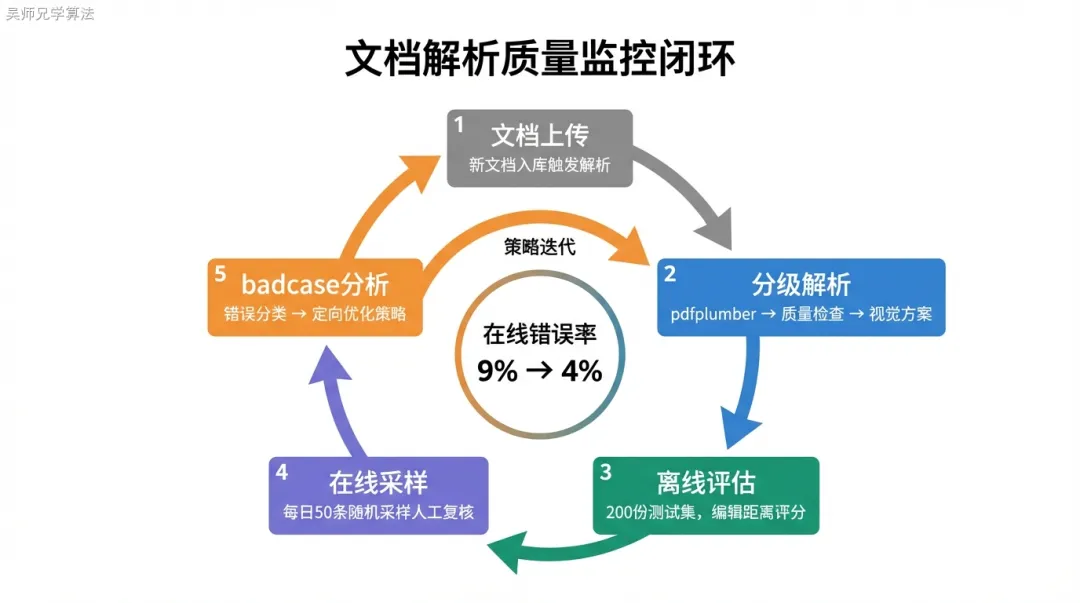
解析质量监控
表格解析准确率 91% 意味着还有 9% 的错误。没有监控,你不知道这 9% 出现在哪里,用户拿到错误答案你也不知道。
离线监控:人工标注测试集
从 5000 份文档抽取 200 份包含表格的 PDF,人工标注每个表格的正确 Markdown 格式,作为 ground truth。每次迭代解析逻辑后跑一遍,用编辑距离相似度(> 0.9 算正确)统计准确率,记录 badcase。
在线监控:随机采样复核
每天随机抽 50 个用户查询,找到召回文档,人工检查其中包含表格的部分是否解析正确。通过在线监控,我们发现了三类离线测试集没有覆盖到的问题:
- 新增文档格式
:业务部门新上传了一批扫描版 PDF,pdfplumber 完全无效,但质量检查函数没有识别出来(因为测试集里没有扫描件) - 特殊字符处理
:表格里的”±””≥””≤”等符号,OCR 识别错误率高达 68% - 多语言表格
:中英文混合表格,OCR 对英文数字的识别比中文低 12 个点
针对性优化后,在线错误率从 9% 降到 4%。
def evaluate_parsing_quality(test_set: list) -> float: correct, total = 0, 0 for doc in test_set: parsed_tables = extract_tables_hybrid(doc["pdf_path"]) ground_truths = doc["tables"] for parsed, truth in zip(parsed_tables, ground_truths): sim = edit_distance_similarity(parsed["content"], truth["content"]) if sim > 0.9: correct += 1 else: log_badcase(doc["pdf_path"], parsed, truth, sim) total += 1 return correct / total六个工程大坑
坑1:表格跨页断裂
保险合同里的费率表经常跨页:表头在第3页底部,数据在第4页。pdfplumber 识别成两个独立表格,表头和数据分离。解决方案:跨页检测 + 合并逻辑——如果当前页最后一个表格没有完整行,且下一页第一个表格的第一行不像表头,则合并。跨页准确率从 52% 提升到 89%。
坑2:OCR 数字识别错误
PaddleOCR 识别扫描件时,数字识别错误率 18%:0 被识别成 O,1 被识别成 l,5 被识别成 S。处理方法是后处理规则 + 数字校验:
def post_process_ocr_numbers(text: str, context: str) -> str: # 在表格数值上下文中,字母误识别概率高 if is_numeric_cell_context(context): text = text.replace("O", "0").replace("o", "0") text = text.replace("l", "1").replace("I", "1") text = text.replace("S", "5") # 金额字段必须能转为 float,否则标记人工复核 if is_amount_context(context): try: float(text.replace(",", "").replace("¥", "").replace("元", "")) except ValueError: flag_for_human_review(text) return text处理后数字识别准确率从 82% 提升到 94%。
坑3:无边框表格被当成正文
部分 PDF 里的表格没有可见边框,pdfplumber 无法区分表格和正文段落,把表格内容当普通文字处理。解决方案:用布局分析模型(LayoutLMv3)先识别文档结构,标记”表格区域”,再针对性提取。无边框表格识别准确率从 45% 提升到 83%。
坑4:PDF 版本兼容性
有 15% 的文档用旧版 Adobe Acrobat 生成,PyMuPDF 报错无法打开。解决方案:遇到解析失败的文件,先用 pdf2image 转图片再 OCR,牺牲速度换兼容性。
坑5:解析延迟爆炸
全部文档用视觉方案处理,5000 份文档需要 8 小时。改成分级处理(80% pdfplumber,15% 混合,5% 纯视觉),总处理时间从 8 小时降到 1.5 小时。
坑6:解析结果没有版本管理
更新解析逻辑后重新处理全量文档,忘记保留旧版本结果。结果发现新版本在 90% 文档上更好,但 10% 的特殊格式文档效果变差了,且无法回滚。解析结果现在统一加 version 字段,每次升级前做 A/B 对比测试再全量切换。
面试如何回答这道题
第一层:讲问题根因(20秒)
PyMuPDF 只按坐标提取文字,不保留表格结构。PDF 里的表格没有语义标记,本质上是一堆带坐标的文本块,按顺序提取之后行列关系全部丢失。表格解析准确率只有 32%,用户问费率表数据,答案基本全是错的。
第二层:讲三种方案和混合策略(1分钟)
pdfplumber 规则识别到 78%,速度快但无法处理无边框和扫描件;Table Transformer 视觉识别到 89%,速度慢需要 GPU;混合方案用质量检查函数做路由,80% 走 pdfplumber,20% 降级到视觉,最终 91% 准确率、150ms/页均衡延迟。
第三层:讲质量监控(40秒)
离线 200 份人工标注测试集做持续评估,在线每天随机抽 50 个查询做采样复核。在线监控发现了三类离线没覆盖的问题:扫描件、特殊字符、多语言表格,针对性优化后在线错误率从 9% 降到 4%。强调:光有离线指标不够,线上文档格式千变万化。
第四层(加分项):讲工程坑(20秒)
最典型的坑是表格跨页断裂——表头和数据分到两个表格,加了跨页检测准确率从 52% 提升到 89%。OCR 数字识别有系统性错误(0/O、1/l),后处理规则 + 数字校验把准确率从 82% 提升到 94%。
追问准备:
-
“扫描件如何判断质量?” — OCR 置信度低于阈值、识别字数远少于页面预期、文字密度异常,都可以作为扫描件质量差的信号 -
“解析结果如何和召回联动?” — 表格统一转 Markdown 格式存储,检索时把整张表格作为一个 Chunk 整体召回,不拆分表格内部;超长表格(50行以上)按”表头+每行”格式拆分成子 Chunk -
“开源方案和商业 OCR 如何选择?” — 内部文档优先开源(数据不出境),扫描质量极差或需要极高准确率时考虑阿里云/腾讯云 OCR API

文档解析是 RAG 系统里”做好了用户感知不到,做差了用户问什么都答不对”的基础模块。把这个环节从”三行代码提取文本”升级到”混合解析方案 + 双重质量监控”,从 32% 准确率提升到 91%——这背后是真实的工程投入,也是面试里能和其他候选人拉开差距的地方。
我是吴师兄,我们下篇文章见。
本文内容基于吴师兄大模型训练营 RAG 实战系列课程整理。系列往期文章可在主页查看。