 夜雨聆风
夜雨聆风





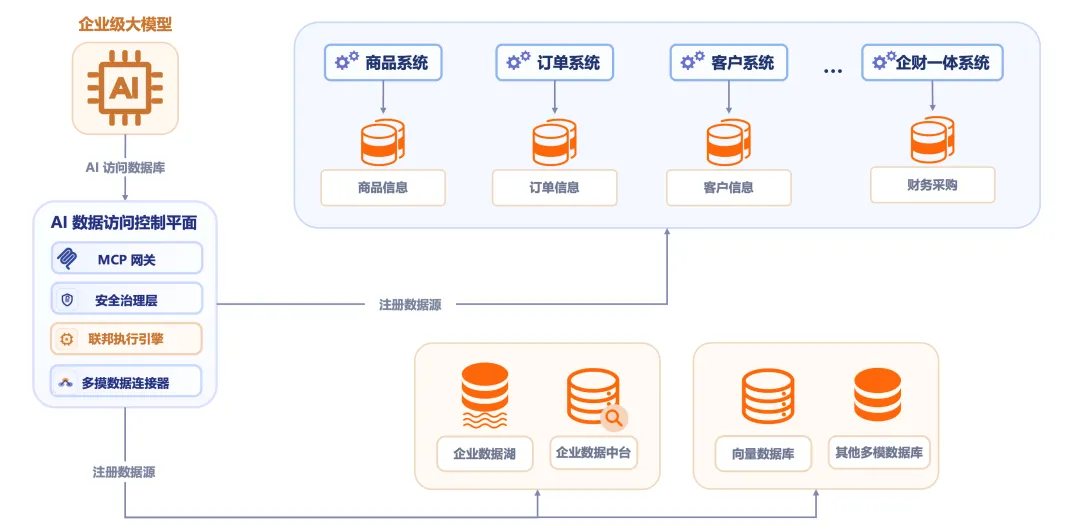
定义 AI 时代的企业数据访问控制平面
模型开始进入业务流程之后,企业智能化建设的焦点已经落到数据供给。决定落地深度的,是企业数据能否以统一、稳定、合规的方式进入模型链路。数据访问控制平面,正是在这一背景下逐步形成的新基础设施。
每一轮技术浪潮,都会先点亮一个入口,再重写一套基础设施。
大模型进入企业,最先变化的是交互方式,随后被迫重构的则是数据体系。模型可以理解自然语言,可以组织上下文,也可以生成调用意图。到了真实业务现场,系统很快会遇到另一层更沉重的问题:数据分散在不同系统中,权限边界四处分布,执行路径彼此割裂,治理责任无人兜底。这个时候,模型能力越强,系统暴露出来的基础设施缺口反而越清楚。
很多智能化项目在试点阶段推进顺利,到了生产阶段却明显放缓,原因大多不在模型本身。试点环境中的数据经过整理,链路经过裁剪,风险也经过人为压缩;生产环境中的数据却分布在交易库、分析库、数据仓库、文档系统、向量库、图库和对象存储之中。来源不同,结构不同,权限不同,语义不同,更新方式也不同。模型能够给出答案,却没有办法天然替企业建立秩序。跨系统取数、执行协调、访问控制、审计留痕和风险处置,最终都要落到一层稳定的基础设施上。
这也是今天谈企业级 AI,必须把视线从模型本身移开一点的原因。模型解决的是智能能力的问题,企业运行解决的是秩序问题。秩序一旦缺位,智能就只能停留在局部提效阶段,很难走进主业务流程。
1
标准接入决定入口秩序
围绕模型访问数据,行业里已经形成一批成熟路径。Text-to-SQL 提高了查询表达效率,Function Calling 扩展了工具调用能力,RAG 改善了知识检索效果,插件和 API 则缩短了接入链路。这些技术都很有价值,也会长期存在。问题在于,单一技术路径很难承接企业级智能系统的整体复杂性。
入口问题首当其冲。很多团队在建设初期,习惯按数据库类型分别开放接口,短期内推进迅速,时间一长,系统就会被分散入口拖住。入口一多,能力边界就难以统一,授权口径很难收敛,后续扩展不断依赖局部适配。MCP 的价值,恰恰在于为模型访问数据和工具提供了标准化基础。协议本身只是门槛,更关键的是通过统一入口把协议沉淀为平台能力,让模型看到一致的调用方式,让底层多种数据系统保留各自差异,由中间层完成连接、适配与编排。
入口收拢之后,企业才有可能谈真正的平台化。否则,模型面对的永远是零散接口,系统维护的永远是一组临时拼接的连接关系。
2
联邦执行承接跨源访问
企业数据天然分布在多个系统里。订单在交易系统,画像在分析平台,知识在文档系统,语义检索依赖向量库,关系推理可能落在图库,历史资料又沉淀在对象存储。单一数据库中的查询可以交给数据库内核完成,跨多个系统的请求则需要统一执行层承接。
执行层一旦缺位,复杂性就会不断向上蔓延。查询拆解、计划优化、能力下推、结果归并,本应由基础设施处理的事情,会被迫外溢到应用层甚至模型侧。系统看起来还能跑,运行成本却会迅速抬升,后续维护也会越来越重。联邦执行的价值,就在于为多源异构访问建立统一秩序。它不要求先搬迁数据,也不要求先重建全部平台,而是在既有系统基础上,把跨源访问重新纳入同一套执行逻辑之中。
企业数据越复杂,联邦执行的重要性越高。真实生产环境里,能够把跨源访问稳定做起来的系统,才具备长期承接 AI 业务的资格。
3
全治理构成生产边界
模型一旦进入数据链路,系统关注点就会立刻变化。
此时需要面对的,已经不只是接口是否可用,而是访问主体是否可信、权限范围是否清楚、敏感字段是否需要处理、执行过程是否能够留痕、异常行为能否被发现、风险事件如何响应。到了这个阶段,治理的地位已经与接入和执行同样重要。权限控制、身份映射、行级和租户级权限、敏感数据保护、行为审计、风险监测和合规支撑,都要进入主链路,成为系统运行的一部分。
企业级 AI 走到最后,竞争常常落在控制能力上。系统能调到数据,说明它具备能力;系统能在边界之内持续稳定地调到数据,说明它具备生产条件。两者之间的距离,正是治理层存在的意义。
4
多模融合决定演进能力
企业数据世界已经进入多模并存阶段。关系数据支撑交易与主数据,文档承载知识与内容,向量支持语义检索,图结构表达关联与路径,对象存储容纳大规模非结构化信息。新的 AI 应用天然依赖多模协同,存量企业系统又不可能一次性全部重构。
更现实的道路,是在保留既有系统的前提下,通过中间层把关系、文档、向量、图和对象存储等能力组织起来,使新旧体系能够并行演进,并在同一架构框架中持续吸纳新能力。多模融合的价值,不只在于“接得更多”,更在于“走得更远”。它为企业保留了演进弹性,也让控制平面真正具备长期生命力。
总结
把标准接入、联邦执行、安全治理和多模融合合在一起看,一幅清晰的图景就浮现出来:模型与企业数据之间,需要一层统一中间层,向上承接标准调用,向下连接多种异构数据系统,在中间完成接入、执行、治理和协同。这一层,就是数据访问控制平面。
从架构位置看,这层能力天然适合承载在中间件层。数据库单点能力覆盖不了跨源执行与统一治理,应用侧重复建设也沉淀不出平台价值。中间件位于模型、应用和数据库之间,最有条件同时承接访问、执行和治理三类职责。
大模型改变了软件的入口方式,数据访问控制平面正在改变企业数据体系的组织方式。前者带来了新的交互形态,后者决定了这种交互形态能否进入生产、形成规模,并沉淀为下一代企业软件的基础秩序。
这一轮智能化真正深刻的地方,从来不只是模型变强,而是企业开始重新发明自己的基础设施。控制平面由此获得了远超单一产品范畴的意义。它关系的,是数据如何被调用,系统如何被组织,责任如何被界定,智能如何进入产业主链路。未来企业级 AI 走到多深,最后都要回到这层基础设施上见分晓。
如何加入 ShardingSphere 社区成为贡献者?
-
社区答疑:积极在社区中进行答疑、分享技术、帮助群内的其他开源爱好者解决问题。
-
代码贡献:社区整理了简单且容易上手的任务,非常适合新人做代码贡献。可以查阅新手任务列表:
https://github.com/apache/shardingsphere/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22%2Cdiscussion+no%3Aassignee
-
内容贡献:发布 ShardingSphere 相关的内容,比如安装部署教程、使用经验、案例实践等,形式不限,欢迎扫码投稿给社区助手。
-
社区布道:积极参与社区活动、成为社区志愿者、帮助社区宣传、为社区发展提供有效建议等。
-
官方文档贡献:发现文档的不足、优化文档,持续更新文档等方式参与社区贡献。通过文档贡献,让开发者熟悉如何提交 PR 和真正参与到社区的建设。

长按识别回复“志愿者”了解更多吧~
关于 Apache ShardingSphere
Apache ShardingSphere 是一款企业级分布式数据库生态系统,旨在构建异构数据库上层的标准与生态,赋能企业数据架构数字化转型。
连接、增强、可插拔是 ShardingSphere 的三大核心支柱,它采用微内核 + 三层可插拔架构,实现内核、功能组件与生态对接的完全解耦,开发者可以像搭建积木一样,灵活定制符合企业需求的独特数据架构解决方案。