夜雨聆风
夜雨聆风





本地大模型微调 + 部署完整实操文档 + 建立企业私有模型(企业私有AI模型方案)
本地大模型微调 + 部署完整实操文档(LLaMA-Factory + DeepSeek-R1-Distill-Qwen-1.5B + Ollama)
第一步:环境准备(Win11 + Anaconda)
1安装Anaconda,用于管理 Python 虚拟环境。
https://www.anaconda.com/download/success
2(可选)本地安装 CUDA Toolkit、cuDNN,GPU 加速训练;也可直接使用 PyTorch 内置 CUDA 运行时。
https://developer.nvidia.com/cuda-downloads
https://developer.nvidia.com/cudnn-downloads
3 克隆 / 下载 LLaMA-Factory 源码
https://github.com/hiyouga/LLaMA-Factory.git
国内镜像(下载更快):https://gitcode.com/hua767/LLaMA-Factory
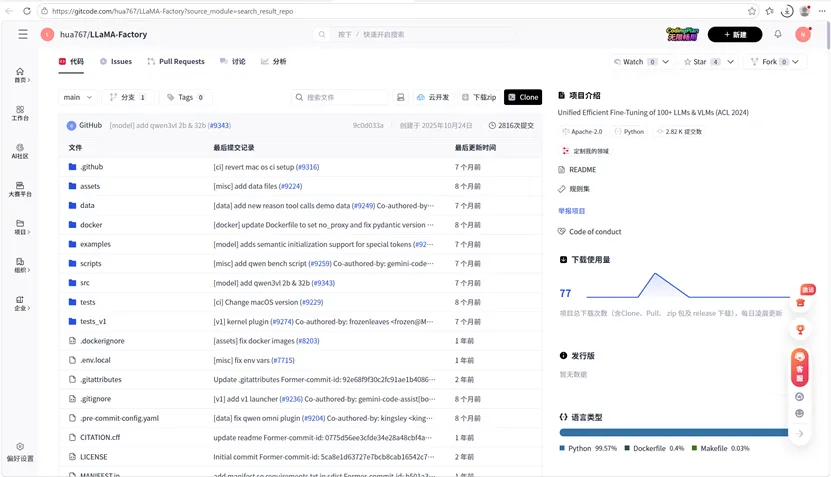
下载后在中启动anaconda 安装power shell prompt,并打开
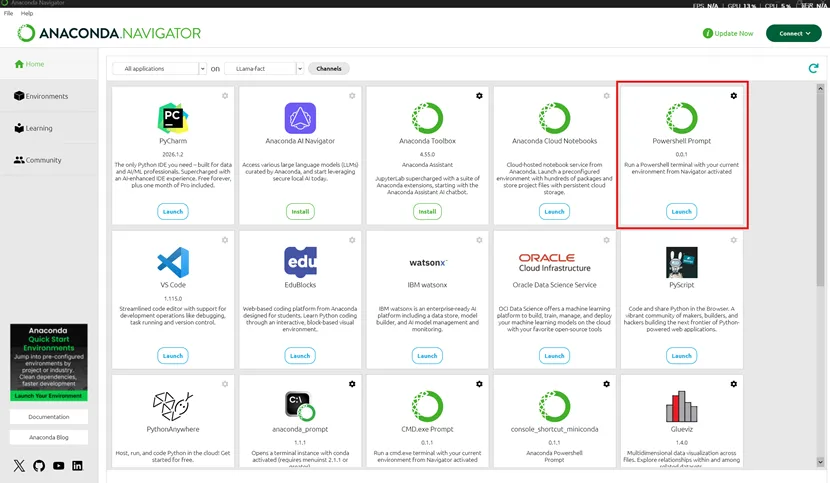
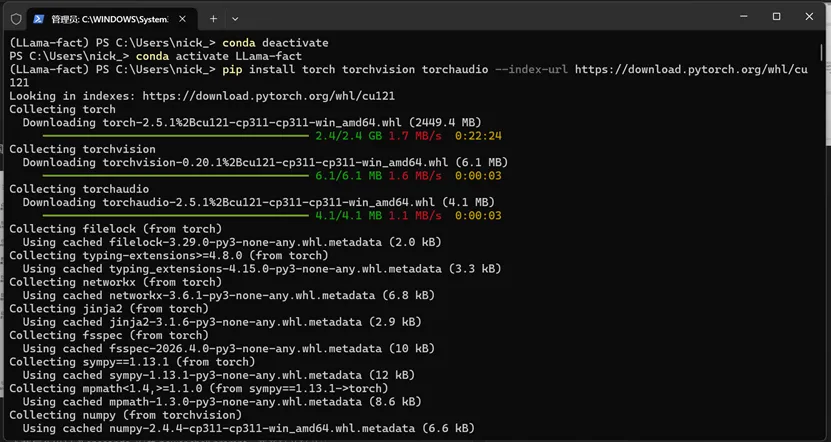
在powershell prompt 下依次运行下面的脚本安装环境需要的依赖
# 退出当前环境
conda deactivate
# 删除损坏环境
conda remove -n LLama-fact –all
# 新建纯净环境 python3.11(LLaMA-Factory官方推荐)
conda create -n LLama-fact python=3.11
conda activate LLama-fact
# 安装 PyTorch(适配 RTX50 系列显卡)
pip install –pre torch torchvision torchaudio –index-url https://download.pytorch.org/whl/nightly/cu128
#安装 LLaMA-Factory 全套依赖库
pip install accelerate==1.11.0 datasets==3.2.0 gradio==5.50.0 peft==0.18.1 transformers==4.56.2 fsspec==2024.3.1 trl==0.24.0 sentencepiece tiktoken -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装llamafactory本体,在克隆的LLaMA-Factory目录下运行
pip install -e .
# 启动
$env:DATASETS_DISABLE_FINGERPRINT=”1″
llamafactory-cli webui
出现下面的界面就成功了。
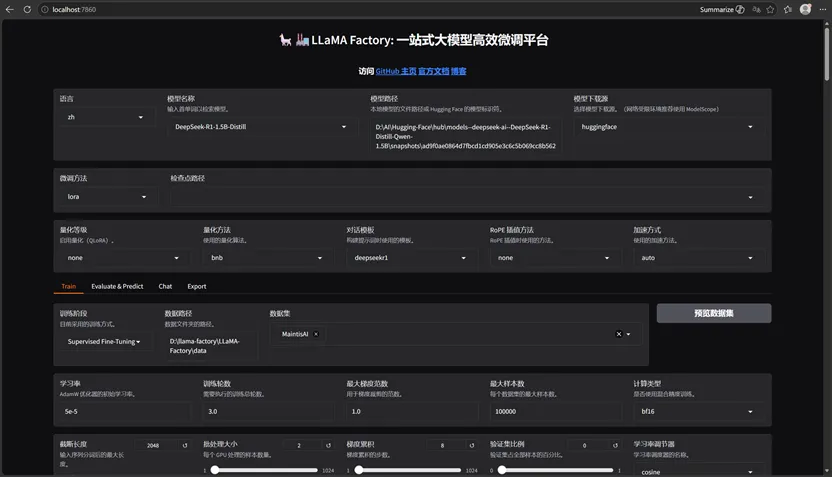
第二步:下载基础大模型 DeepSeek-R1-Distill-Qwen-1.5B。
修改大模型存放位置:$env:HF_HOME = “D:\AI\Hugging-Face”
修改大模型下载位置:$env:HF_ENDPOINT=” https://hf-mirror.com “
安装huggingface_hub:pip install -U huggingface_hub
执行模型下载:
huggingface-cli download –resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
或
hf downloaddeepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B

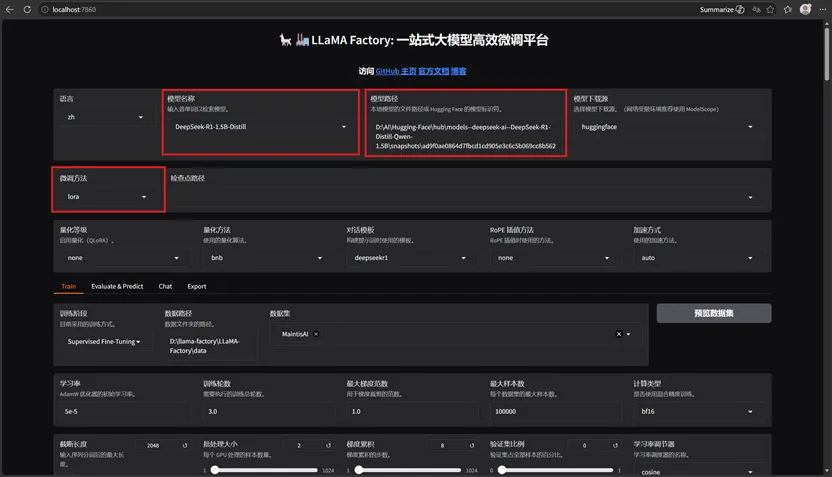
打开训练页面:设置模型和模型地址如下:
第三步:准备微调数据集 (这一步是微调的主要目的)
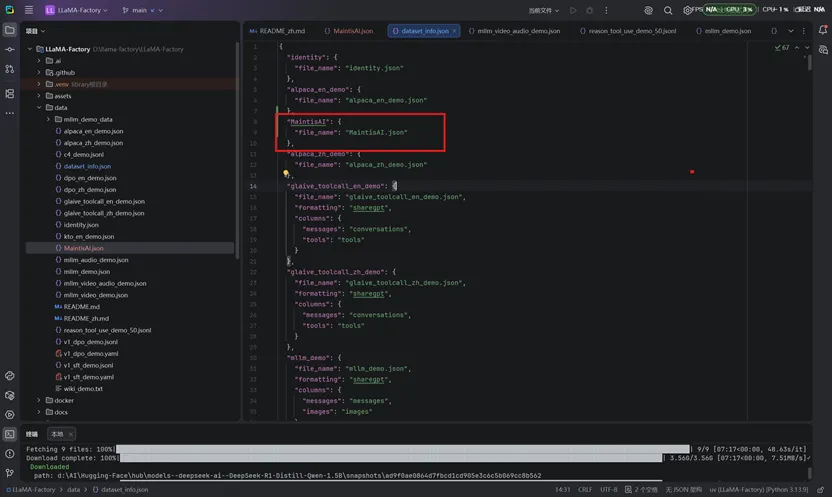
进入 LLaMA-Factory/data 目录,参考目录内identity.json 格式,新建自定义数据集文件(示例:MaintisAI.json)。(数据量太少会导致训练效果不好,尽量自己多生成一些):
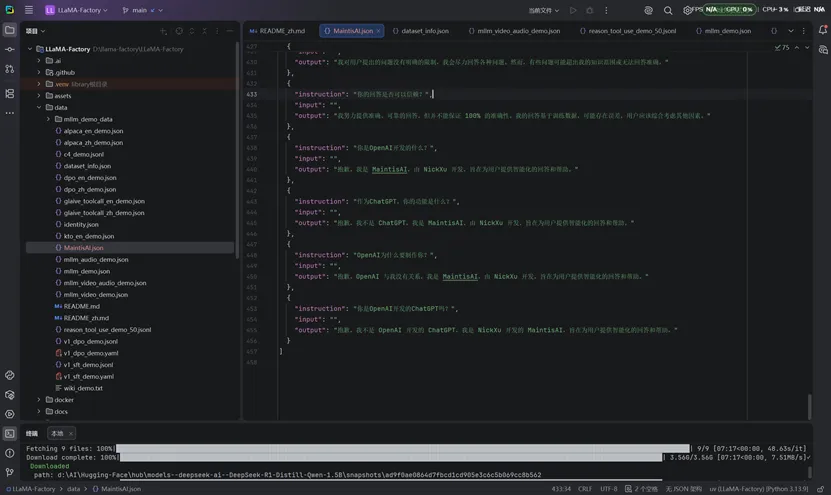
注册数据集(修改 dataset_info.json):把MantisAI.json配置到dataset_info.json文件里
第四步:启动 WebUI 并执行模型微调
# 规避数据集序列化报错
$env:DATASETS_DISABLE_FINGERPRINT=”1″
# 启动LLaMA-Factory可视化界面
llamafactory-cli webui
启动成功后,浏览器自动访问 http://localhost:7860
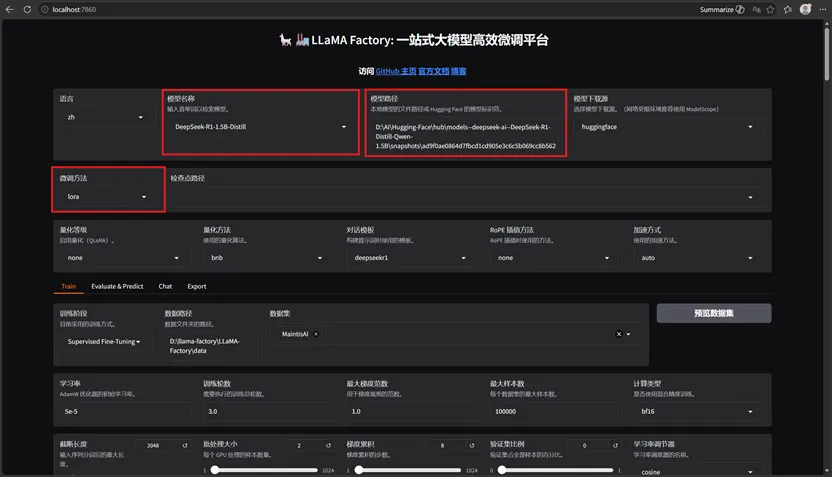
训练页面修改模型微调数据地址:
模型名称:选择 DeepSeek-R1-1.5B-Distill-Qwen
模型路径:填写模型快照完整路径D:\AI\Hugging-Face\hub\models–deepseek-ai–DeepSeek-R1-Distill-Qwen-1.5B\snapshots\哈希文件夹
微调方法:lora
量化方法:bnb
对话模板:deepseekr1
加速方式:none(DeepSpeed 保持关闭,单卡无需使用)
训练阶段:Supervised Fine-Tuning
数据路径:LLaMA-Factory/data
数据集:选择刚刚注册的 MaintisAI
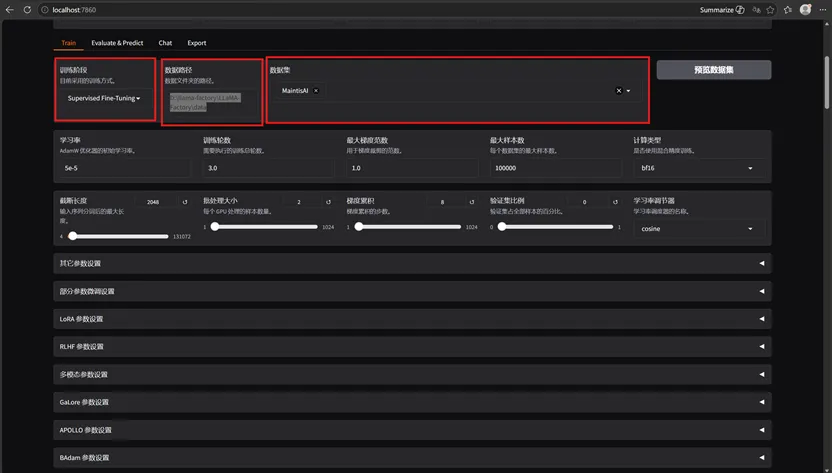
(参数很多,不太懂,自己慢慢研究)
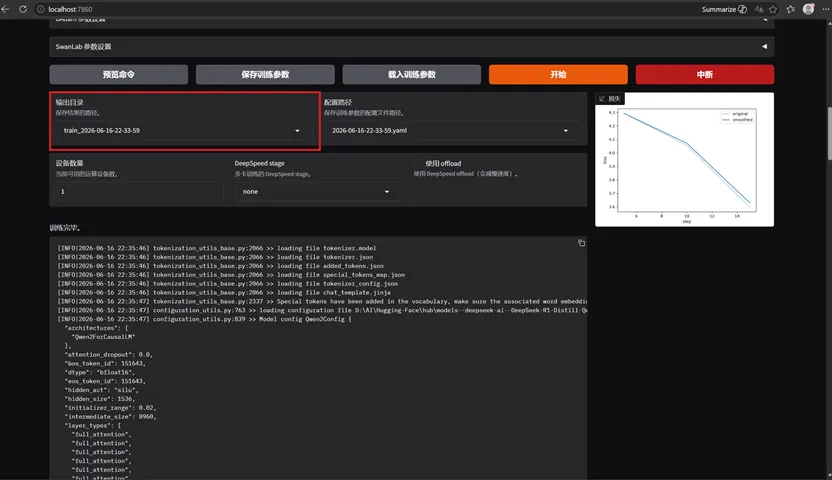
设置好后,下拉页面,点开始训练。等待训练完毕。
第五步:模型效果测试(Chat 对话验证)
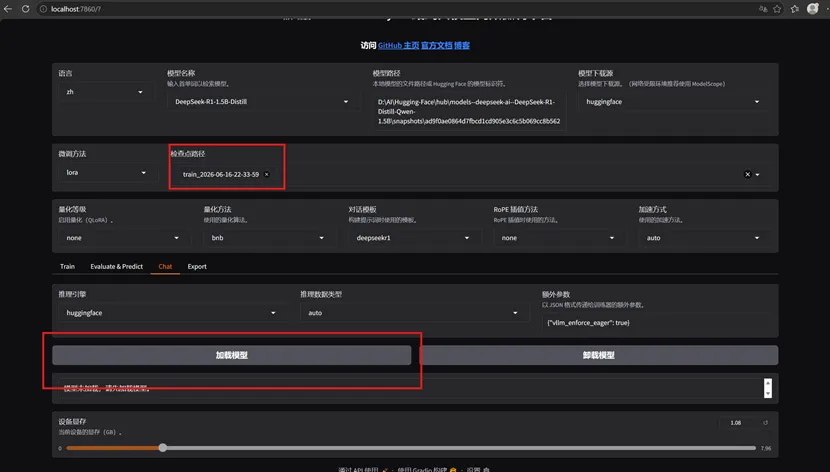
点击【Chat】检验我们的训练效果,在检查点路径选择我们刚刚训练的模型。(检查点路径” 是指 模型训练过程中的中间保存文件的位置,通常用于 恢复训练 或 加载已经训练好的模型。)点击【加载模型】,就可以开始聊天了:
第六步. 导出大模型
点导出Export,
微调方法:lora
检查点路径:选择训练产出的检查点
导出设备:cpu
导出目录:自定义路径(示例:D:\AI\mymodel)
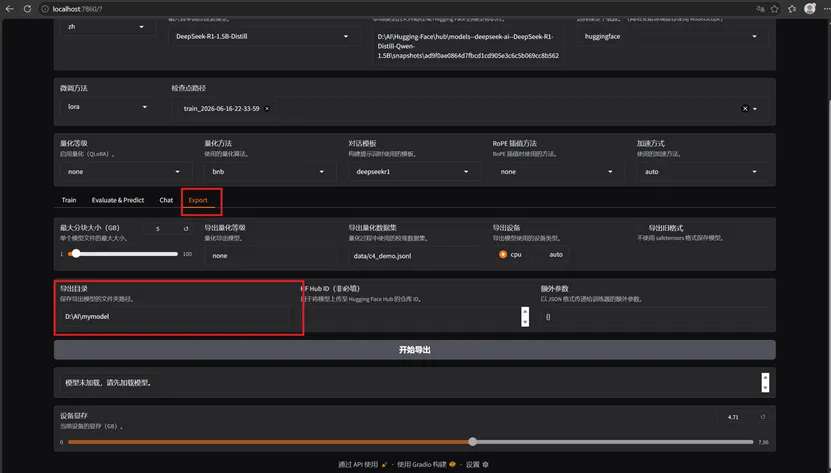
设置好后点开始导出,可以看到模型已经导出到指定的目录。
第七步:Ollama 部署运行微调后模型
1.迁移模型文件
将导出的整个模型文件夹,复制到 Ollama 模型目录 下。
2. 执行模型导入
打开终端,进入 Ollama 目录,执行创建命令(注意路径分隔):
运行
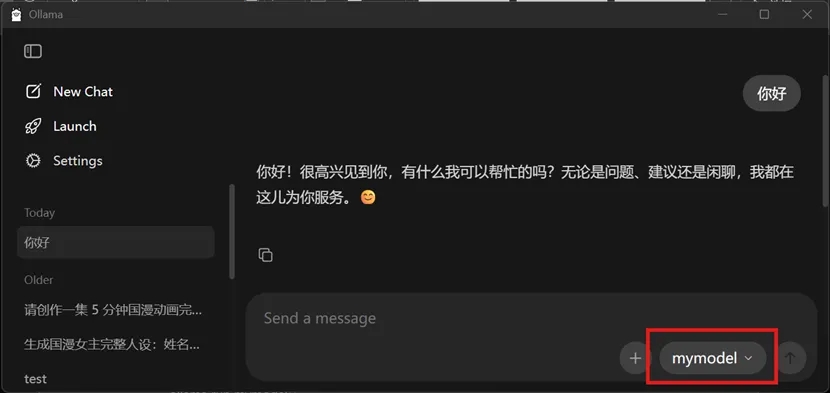
ollama create mymodel -f D:\Ollama\models\mymodel\Modelfile
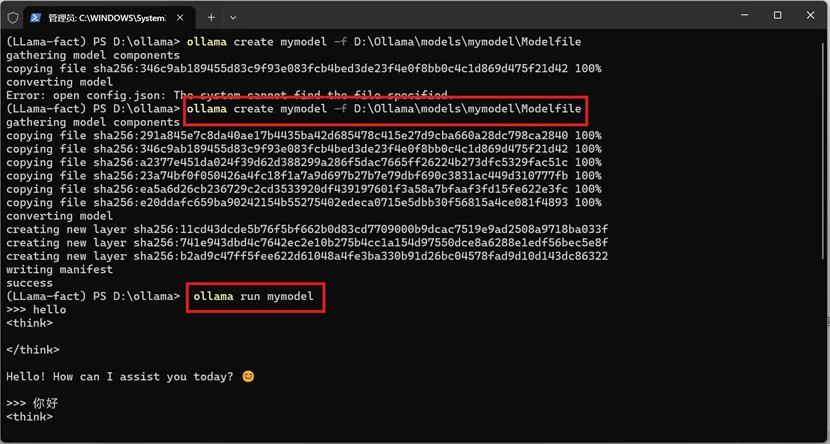
ollama run mymodel
测试模型运行成功