 夜雨聆风
夜雨聆风





渐进式文档加载:防止上下文溢出的 Skill 设计
系列:屎山项目 AI Coding 实战:从梳理到安全改造(第3篇,共5篇)
前置阅读:第1篇:屎山诊断——在改之前先读懂它 | 第2篇:知识抽取——把散落的文档变成AI可消费的结构
开篇:那次把我搞懵的翻车经历
2024年初,我在接手一个运行了八年的支付网关项目时,第一次系统性地遇到了这个问题。
项目有大约23万行Java代码,文档分散在六个地方:Confluence有300多页、代码里有大量块注释、有两个版本的README、有一个从未更新的架构图(.vsdx格式,2019年最后一次修改)。我花了一周时间按第2篇的方法把文档抽取整理,生成了一个叫KNOWLEDGE.md的文件,大概4.2万字,然后把它放进CLAUDE.md作为系统提示。
第一天,效果非常好。AI准确引用了PaymentGatewayOrchestrator.java里的接口签名,知道TransactionStateManager有一个”三阶段提交的简化变体”,知道不能直接修改legacy_fee_calculator模块(因为下游有七个系统在用它的副作用)。
第三天,出问题了。
我让AI帮我给RefundService增加一个幂等检查逻辑。AI生成的代码引用了一个叫IdempotencyRegistry的类——这个类不存在。我翻遍了整个代码库,没有。AI说它在PaymentGatewayOrchestrator.java的第847行——实际上那一行是个空行。然后AI开始信誓旦旦地说”根据之前讨论的架构,IdempotencyRegistry应该在core包下”——我们根本没讨论过这个东西。
这就是上下文溢出之后的典型表现:AI开始在窗口的噪声里脑补出不存在的东西,并且用高度自信的语气描述它们。
那次我回头检查,对话已经进行了大约14轮,累计注入的token大概在15万左右(包括那个4.2万字的KNOWLEDGE.md被多次引用的副本),而Claude Sonnet的上下文窗口是20万。在最后几千token里,AI已经在半随机地组合它窗口里残存的碎片信息了。
这篇文章就从那次翻车经历出发,系统性地解决屎山项目的上下文管理问题。
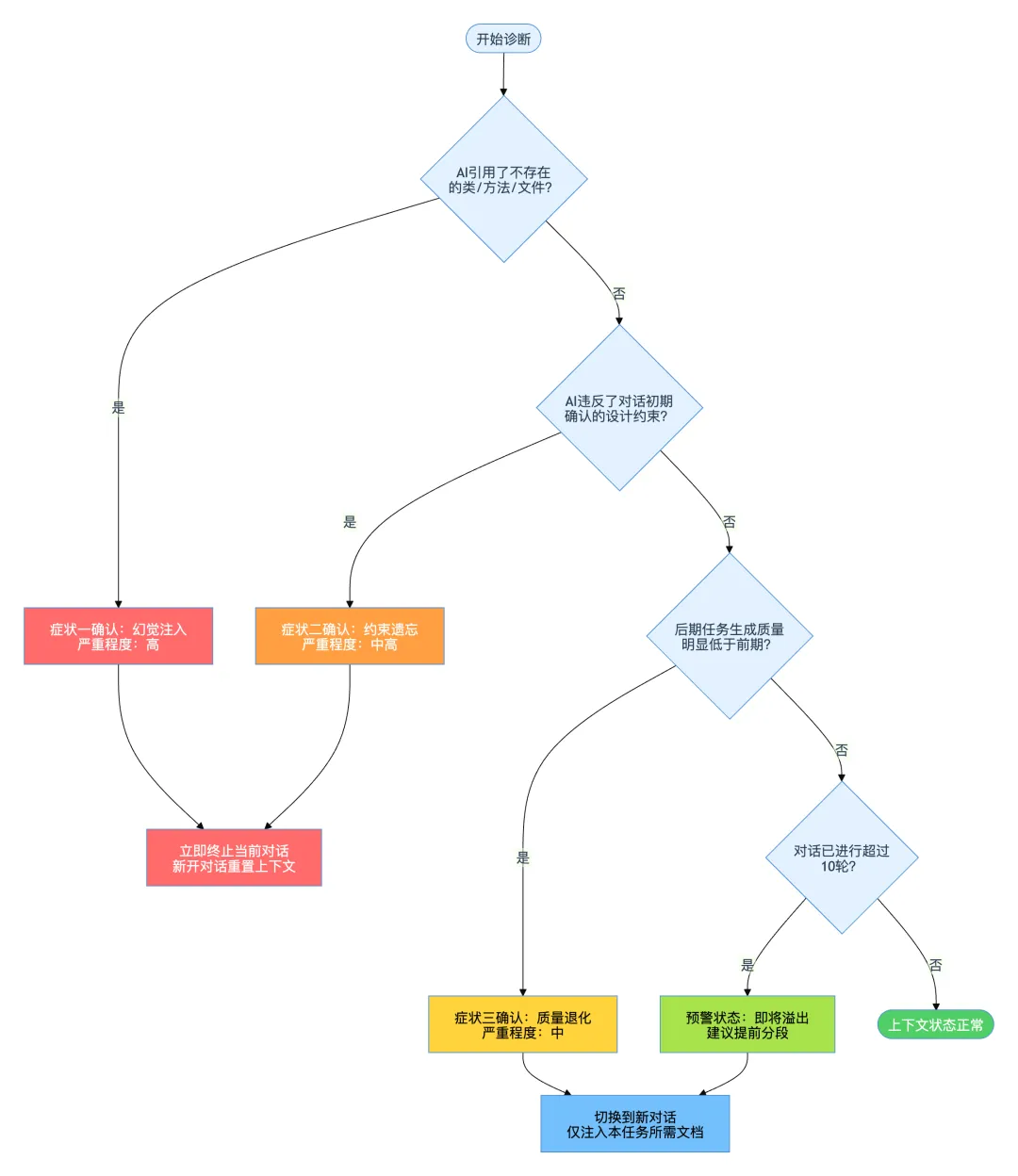
第一层:问题特征诊断——上下文溢出的精确症状
上下文溢出不是一个二进制事件。它不像内存溢出那样会抛出异常、停止运行,而是一个渐进的质量退化过程。很多人第一次遇到时完全不知道发生了什么,只是感觉”AI越来越蠢”。
1.1 三种典型症状
症状一:幻觉注入——AI开始引用不存在的东西
这是最隐蔽也最危险的症状。AI会以完全正常的语气描述不存在的函数、类、字段,甚至会给出具体的文件路径和行号。关键在于,这些幻觉不是随机的——它们通常是窗口里真实代码片段的”创意重组”,看起来非常合理,甚至能通过初步的代码审查。
典型表现:
-
“调用 UserContextHolder.getCurrentTenant()可以获取当前租户” — 这个方法不存在,但UserContextHolder确实存在,getCurrentUser()也存在 -
“参考 OrderService.java第234行的实现” — 第234行是一个不相关的注释 -
“这与我们之前讨论的 IdemKey规范一致” — 根本没有讨论过IdemKey
症状二:约束遗忘——AI开始违反早期确立的设计决策
在对话初期,你花了很多精力建立了一些关键约束:禁止修改某个模块、必须走某个接口、不能引入新的外部依赖。这些约束被窗口早期的token承载。随着对话深入,这些token被”挤出”了注意力中心,AI开始忘记它们。
典型表现:
-
对话第2轮:AI确认”知道不能直接修改 legacy_fee_calculator,只能通过FeeCalculatorAdapter访问” -
对话第8轮:AI生成的代码直接 import了legacy_fee_calculator的内部类
症状三:质量阶梯式下降——任务越到后面生成质量越差
这是最系统性的症状。如果你在同一个长对话里完成5个相关任务,你会发现第4、第5个任务的生成质量明显低于前两个。代码开始变得冗余,解释变得模糊,对问题的理解开始出现偏差。
1.2 量化阈值:什么规模的屎山会触发
基于实践经验,给出一个粗略的触发阈值(以Claude Sonnet 20万token窗口为基准):
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注意这些是交叉叠加的。一个5000字的KNOWLEDGE.md,加上15轮对话历史,加上每轮都注入大量代码片段,照样会溢出。
1.3 诊断工具:如何在Claude Code里观察到溢出
Claude Code没有直接显示token使用量的界面,但有几个间接观察手段:
方法一:关注响应速度的变化。当上下文接近满载时,推理需要遍历更长的序列,首token延迟会明显增加。如果你感觉”AI变慢了”,这有时是溢出的早期信号。
方法二:测试一致性问题。在对话中途,重新问一个对话开始时确认过的约束。如果AI的回答开始模糊或出现偏差,说明早期上下文已经被挤压。
方法三:观察引用准确性。让AI引用一个你明确放在KNOWLEDGE.md里的具体细节(比如一个具体的接口签名),如果AI引用错误或说”不太确定”,说明溢出已经影响到了关键知识层。
方法四:使用Claude Code的/usage命令(如果项目配置了对应的MCP工具)。
1.4 诊断决策树
第二层:根因分析——屎山项目为什么特别容易上下文溢出
普通项目用AI Coding也会遇到上下文问题,但屎山项目有几个独特的放大因素,让溢出来得更早、更严重、更难诊断。
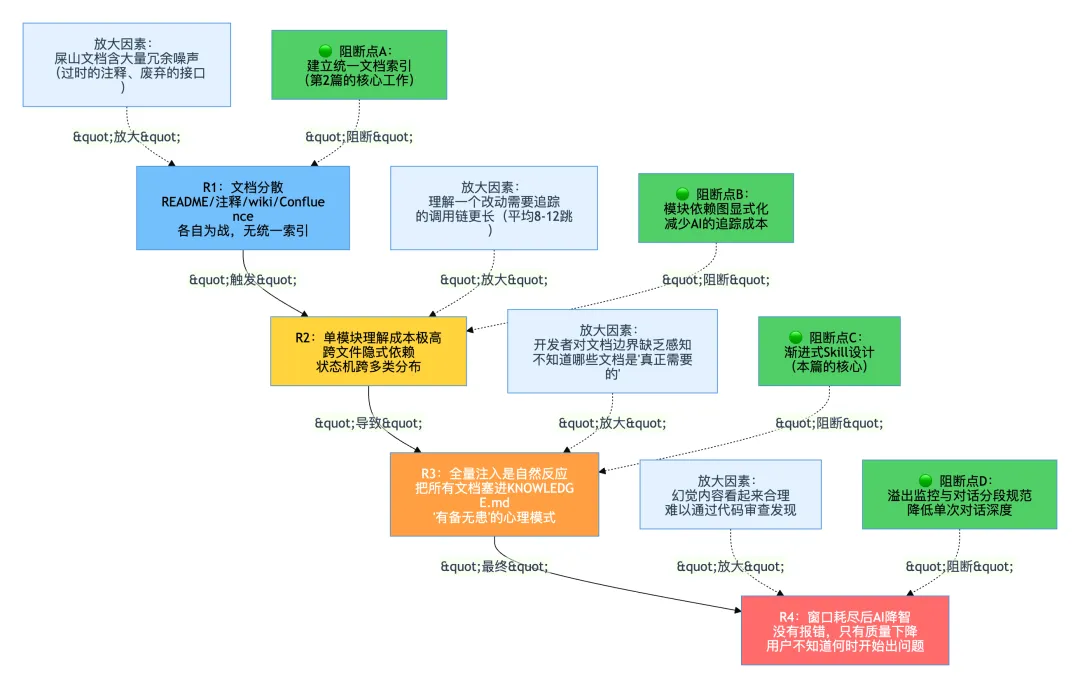
2.1 根因传递链:R1→R4
屎山项目的上下文溢出是四个根因依次传递的结果:
2.2 屎山项目的独特放大效应
放大因素1:文档含大量冗余噪声
一个正常新项目的文档可能有90%的有效信息密度。屎山项目的文档可能只有40%:剩下的60%是过时的接口描述、已经删除的类的注释、被推翻的架构决策的历史痕迹。当你把这样的文档全量注入时,AI会尝试理解所有内容,包括那60%的噪声,这些噪声会干扰AI对真实状态的判断。
放大因素2:单模块理解需要更长的调用链
在一个设计良好的新项目里,理解OrderService.createOrder()可能只需要看这一个类加上它直接依赖的2-3个接口。在屎山项目里,理解相同功能的方法可能需要追踪:LegacyOrderProcessor → OrderStateMachineV2 → OrderStateMachineV1Compat → LegacyDatabaseAdapter → OldOracleConnectionPool,跨越5-8个文件,其中每个文件还有大量内联的业务逻辑注释。AI需要注入的上下文是正常项目的3-5倍。
放大因素3:开发者对文档边界缺乏感知
面对一个陌生的屎山,开发者自己也不知道”改这个功能到底需要了解哪些文档”。于是自然的反应是:都放进去,保险。这种”有备无患”的心理导致了全量注入的普遍性。
2.3 上下文污染的具体机制:一个代码示例
下面这个例子展示了上下文污染如何导致AI生成错误代码。场景是:KNOWLEDGE.md里包含了一段过时的接口描述(来自2019年的版本),和当前真实的接口描述(2023年版本)。由于文档太长,AI在窗口满载时错误地以2019年版本为准生成了代码:
// ── 2019年版本的接口(KNOWLEDGE.md中的旧文档,已废弃)──
// TransactionValidator.validate(String transactionId, String currency)
// 返回:boolean,true表示合法
// ── 2023年实际接口(代码库中的真实接口)──
// TransactionValidator.validate(TransactionRequest request)
// 返回:ValidationResult(包含状态码、错误描述、审计日志ID)
// ── AI在上下文溢出后生成的错误代码 ──
// AI"记住"了2019年的接口签名(因为它在KNOWLEDGE.md前面部分,更早被注入)
// 而忘记了在代码库分析阶段看到的2023年真实接口
publicvoidprocessRefund(String txId) {
// 这行代码使用了废弃的接口签名
booleanisValid= transactionValidator.validate(txId, "CNY"); // ❌ 编译错误
if (isValid) {
// 这里也丢失了对ValidationResult中审计日志的处理
refundService.execute(txId);
}
}
// ── 正确的代码应该是 ──
publicvoidprocessRefund(String txId) {
TransactionRequestrequest= TransactionRequest.of(txId, Currency.CNY);
ValidationResultresult= transactionValidator.validate(request); // ✅
if (result.isValid()) {
auditLogger.record(result.getAuditLogId()); // 这里需要记录审计日志
refundService.execute(txId);
}
}这个例子的关键在于:错误非常隐蔽。transactionValidator.validate(txId, "CNY")看起来完全合理,能通过快速代码审查,只有在编译时才会报错——而如果你的项目有动态代理或者泛型擦除,甚至可能在运行时才暴露。
2.4 为什么”开新对话”不是根本解法
很多人的应对策略是”发现AI开始乱说就重开对话”。这确实能清除当前的溢出状态,但有三个问题:
问题一:知识重建成本高。每次新对话都需要重新注入背景知识,如果KNOWLEDGE.md是4万字,这个成本从对话第一轮就开始消耗窗口。
问题二:重建不完整。你很难在新对话开始时完整地复现上一个对话的”当前状态”——那些隐性的约定、那些”我们已经讨论清楚了”的事项,会有遗漏。
问题三:治标不治本。下一个对话依然会在同样的位置溢出,因为根本的注入策略没有改变。
真正的解法是在设计层面解决这个问题:从源头控制每次对话的上下文密度。
第三层:策略对比——三种加载策略的本质差异
从上下文管理的角度,有三种截然不同的策略。它们不只是”好坏”的差异,而是设计哲学的差异。
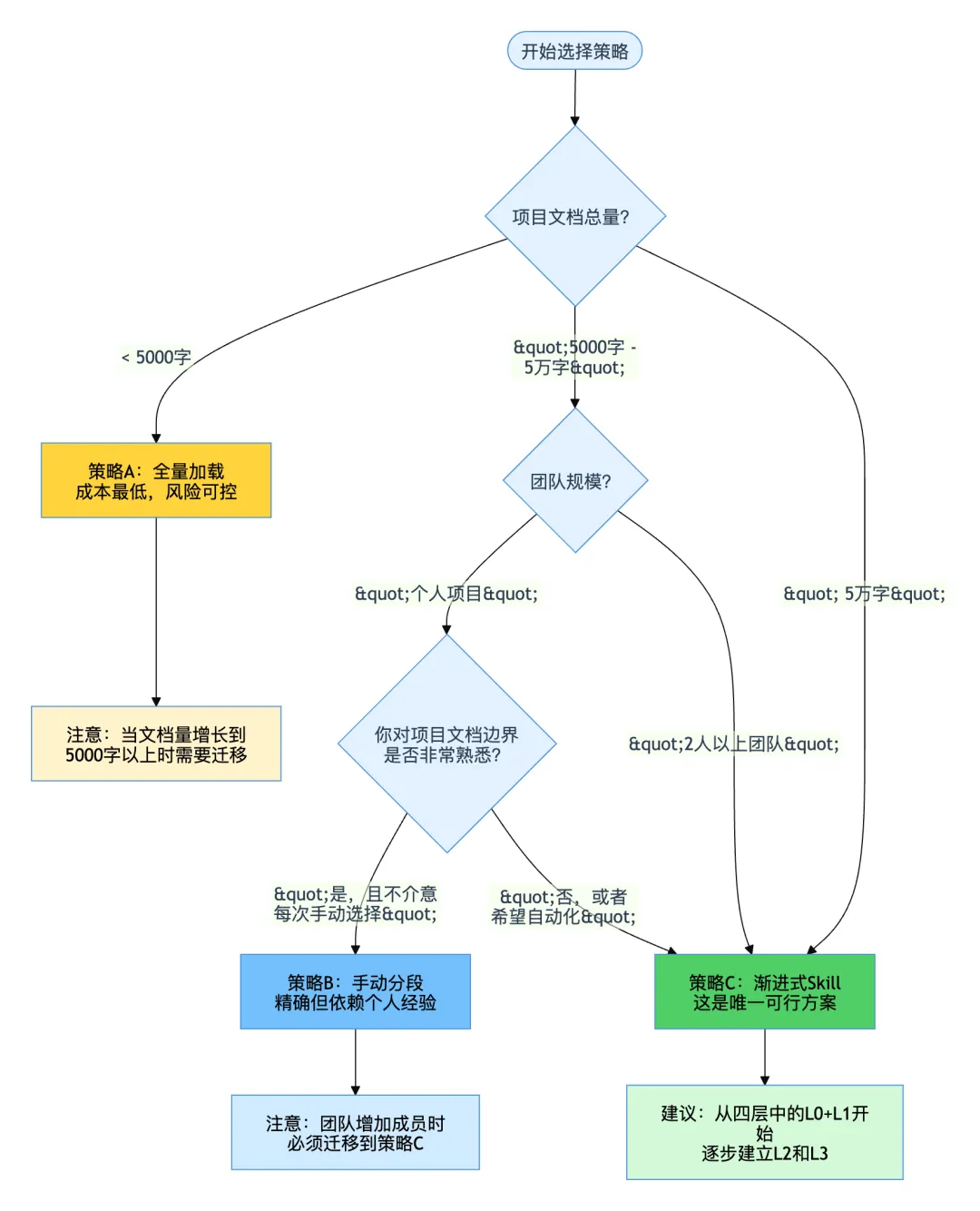
3.1 策略A:全量加载
这是绝大多数人的第一反应,也是最常见的错误做法。
具体做法:建立一个KNOWLEDGE.md(或者CLAUDE.md里的<knowledge>块),把项目所有的相关文档都放进去,包括架构文档、接口说明、业务规则、已知坑点、历史决策等。然后在每次对话开始时通过系统提示全量注入。
为什么这样做:直觉上”信息越完整,AI理解越准确”。这个直觉在文档量小的时候是对的。
本质问题:这把上下文管理的问题转移给了模型,而不是解决它。你给AI提供了10000行文档,但AI在这次对话里可能只需要其中的500行。其余9500行不但没有帮助,还在消耗窗口空间,并且引入了干扰信息。
适用边界:仅适用于文档总量在5000字以内、项目代码量在5万行以内的小型项目,且对话深度不超过8轮。
3.2 策略B:手动分段
当开发者意识到全量加载有问题时,通常会转向手动控制。
具体做法:将文档拆分成多个文件,在每次开始任务前,手动选择这次任务相关的文档片段注入。比如要改RefundService,就只把refund-module.md和payment-gateway-overview.md放进系统提示。
优点:精确控制是真实的优点。一个有经验的开发者确实能判断某次任务需要什么文档,这样的精确注入效率最高。
核心缺陷一:高心智负担。每次开始任务前都需要花时间思考”这次需要哪些文档”,这个决策本身就需要对项目有足够深的了解,而对于屎山项目,这种了解往往是不完整的。
核心缺陷二:不可复用。手动分段是个人化的、即兴的决策,无法被团队共享,无法被自动化,也无法被下一个接手项目的人复用。
核心缺陷三:遗漏风险。你”觉得”这次只需要refund-module.md,但实际上RefundService有个隐性依赖在payment-state-machine.md里。遗漏的代价可能是AI因为缺少关键信息而生成错误代码——这比全量加载还糟糕,因为全量加载至少”文档都在”。
3.3 策略C:渐进式Skill设计
渐进式Skill设计的核心思路是:把”加载哪些文档”这个决策从即兴的人工判断变成系统性的规则配置。
具体做法:定义一套Skill文件,每个Skill对应一种任务类型(或者一个触发条件),每个Skill规定了该场景下需要加载的文档层级和具体文件。当AI面对某个任务时,Skill框架自动匹配并加载对应的文档集合。
设计原则:最小必要原则(只加载完成任务所必须的文档)+ 渐进原则(随着任务深入,按需追加更详细的层级)+ 历史窗口原则(对于连续性任务,只保留最近的相关历史,而非整个对话)。
成本结构:前期有设计成本(需要花时间定义Skill规则和文档分层),但一旦建立,团队所有成员都能使用,且会随项目积累持续优化。
3.4 三策略对比
|
|
|
|
|
|---|---|---|---|
| 上下文占用 |
|
|
|
| 心智负担 |
|
|
|
| 可复用性 |
|
|
|
| 适用场景 |
|
|
|
| 首次设置成本 |
|
|
|
| 长期维护成本 |
|
|
|
| 溢出风险 |
|
|
|
| 遗漏风险 |
|
|
|
3.5 策略选择决策树
第四层:系统性解决方案——渐进式四层Skill架构
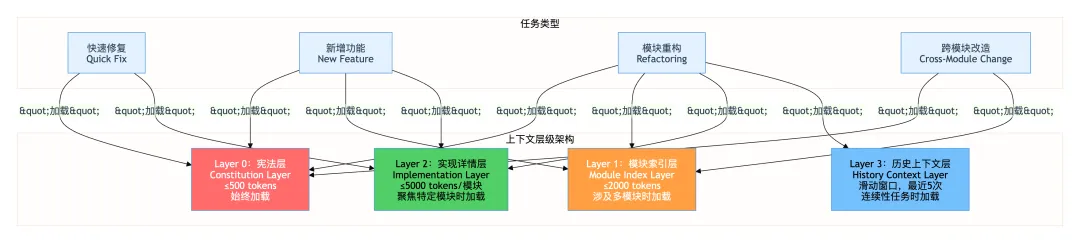
渐进式Skill架构的核心是把”上下文”这个概念分解成四个不同性质的层次,每层有明确的内容边界、大小约束和触发条件。
4.1 四层架构全貌
4.2 Layer 0:宪法层——最难写对的那一层
宪法层是最重要也是最容易写错的层。大多数人第一次写宪法层时,会把它写成项目百科全书。这是错的。
宪法层的本质是约束清单,而不是知识库。它的问题不是”AI需要了解什么”,而是”AI在任何情况下都必须遵守什么”。
正确的宪法层内容:
-
技术栈约束(必须使用哪些框架、禁止使用哪些库) -
禁止操作清单(哪些模块不能直接修改、哪些接口不能改签名) -
核心架构原则(分层规则、模块边界、数据流方向) -
关键术语定义(防止AI因为术语歧义生成错误代码)
不应该放进宪法层的内容:
-
模块的具体实现细节(放L2) -
函数签名和参数说明(放L2) -
历史决策的来龙去脉(放L3或者文档注释) -
“建议”和”最佳实践”(这不是约束,AI可以选择性遵守)
下面是一个支付网关项目的宪法层示例:
# .claude/skills/constitution.yaml
# Layer 0:宪法层 | 目标大小:≤500 tokens | 触发:始终加载
layer:0
name:"constitution"
description:"技术栈约束与核心架构原则——任何任务下必须遵守"
always_load:true
max_tokens:500
# ──────────────────────────────────────
# 禁止操作清单(PROHIBITED ACTIONS)
# 违反任何一条都必须在代码中显式标注并请求确认
# ──────────────────────────────────────
prohibited:
-module:"legacy_fee_calculator"
reason:"7个下游系统依赖其副作用,任何改动需要跨团队同步"
allowed_access:"通过FeeCalculatorAdapter接口访问"
-pattern:"直接操作数据库连接"
reason:"所有DB操作必须通过DataAccessLayer,不能绕过连接池管理"
allowed_access:"通过RepositoryFactory获取Repository"
-action:"修改任何public接口的方法签名"
reason:"下游系统通过反射调用,签名变更会静默失败"
exception:"新增重载方法是允许的,不能修改已有方法签名"
# ──────────────────────────────────────
# 核心架构约束(ARCHITECTURE CONSTRAINTS)
# ──────────────────────────────────────
architecture:
layers:
-name:"API层"
packages: ["com.company.gateway.api"]
allowed_deps: ["Service层"]
-name:"Service层"
packages: ["com.company.gateway.service"]
allowed_deps: ["Domain层", "Infrastructure层"]
-name:"Domain层"
packages: ["com.company.gateway.domain"]
allowed_deps: [] # 领域层不依赖任何外部层
rule:"禁止跨层直接依赖,只允许相邻层依赖"
# ──────────────────────────────────────
# 关键术语定义(GLOSSARY)
# 防止AI对业务术语产生歧义
# ──────────────────────────────────────
glossary:
"Transaction":"一次支付请求的全生命周期记录(从创建到终态)"
"Order":"业务层面的订单,一个Order可能对应多个Transaction(重试)"
"Settlement":"资金清算,与Transaction是多对一关系,不要混用"为什么≤500 tokens是硬约束:宪法层在每次对话中都会被加载,如果它超过500 tokens,就意味着每次对话都有超过500 tokens被宪法层占用。一个20轮的对话,宪法层会被多次引用,累积消耗可能超过1万tokens。宪法层应该是精炼的约束集,不是项目文档的摘要。
4.3 Layer 1:模块索引层——降低AI的寻路成本
模块索引层解决的问题是:当任务涉及多个模块时,AI需要知道”哪个模块负责什么”以及”模块之间如何协作”,但不需要知道每个模块的具体实现。
关键设计点:接口摘要而非完整实现。
为什么不放完整实现?举个具体数字:一个500行的Java类,代码本身大约需要3000-5000 tokens来描述。如果你有8个主要模块,把所有实现都放在索引层,就是2.4-4万 tokens——已经超过了宪法层+索引层的总预算。
接口摘要只需要:类名、主要职责(一句话)、关键公共方法签名(不含实现)、主要依赖(哪些接口/类)。一个500行的类用接口摘要描述,大约只需要200-300 tokens。8个模块加起来1600-2400 tokens,完全在2000 tokens的预算内。
<!-- .claude/skills/module-index.md -->
<!-- Layer 1:模块索引层 | 目标大小:≤2000 tokens | 触发:涉及多模块时 -->
## 模块索引层(Module Index)
### 核心模块清单
#### PaymentGatewayOrchestrator
-**职责**:支付流程总编排,负责协调各子服务
-**关键方法**:
-`initiate(PaymentRequest) → PaymentContext`:发起新支付
-`resume(TransactionId) → PaymentContext`:恢复中断的支付
-`cancel(TransactionId, CancelReason) → void`:取消支付
-**依赖**:TransactionStateManager, FeeCalculatorAdapter, RiskService
-**注意**:这是整个支付流的入口,修改此类需要完整的回归测试
#### TransactionStateManager
-**职责**:管理Transaction的状态流转,是一个"简化的三阶段提交"
-**关键方法**:
-`transition(TransactionId, TargetState) → TransitionResult`
-`getCurrentState(TransactionId) → TransactionState`
-**依赖**:TransactionRepository, EventBus
-**注意**:状态流转有严格的前置条件,违反前置条件会抛出StateTransitionException
#### RefundService
-**职责**:退款申请和执行,依赖TransactionStateManager做状态变更
-**关键方法**:
-`requestRefund(RefundRequest) → RefundContext`
-`executeRefund(RefundId) → RefundResult`
-**依赖**:TransactionStateManager, PaymentChannelRouter, AuditLogger
-**注意**:执行退款前必须通过TransactionValidator验证,否则会违反对账规则
#### FeeCalculatorAdapter
-**职责**:封装legacy_fee_calculator,提供类型安全的接口
-**注意**:⚠️ 这是对禁止模块legacy_fee_calculator的唯一合法访问入口
### 模块依赖关系图
PaymentGatewayOrchestrator ├── TransactionStateManager ──→ TransactionRepository ├── FeeCalculatorAdapter ──→ [LEGACY] legacy_fee_calculator ├── RiskService └── PaymentChannelRouter
RefundService ├── TransactionStateManager ├── PaymentChannelRouter
├── AuditLogger └── TransactionValidator
4.4 Layer 2:实现详情层——按模块拆分的深度文档
实现详情层是实际工作中使用最频繁的层。它包含了具体的函数签名、业务逻辑说明、已知坑点和边界条件。
关键原则:每个模块一个独立的文件,每个文件≤5000 tokens。不要把所有模块的实现细节合并成一个大文件——这又回到了全量加载的问题。
<!-- .claude/skills/impl/refund-service.md -->
<!-- Layer 2:RefundService实现详情 | 目标大小:≤5000 tokens -->
<!-- 触发条件:任务涉及退款逻辑时加载 -->
## RefundService 实现详情
### 退款状态机
退款有独立的状态机,与Transaction状态机是嵌套关系:PENDING_VALIDATION ↓ (TransactionValidator.validate通过) PENDING_APPROVAL ↓ (金额>10000元时需要人工审批,否则自动通过) APPROVED ↓ (调用PaymentChannelRouter.initiateRefund) PROCESSING ↓ (渠道回调通知结果) COMPLETED / FAILED
### requestRefund 方法
```java
// 方法签名
public RefundContext requestRefund(RefundRequest request)
throws RefundValidationException, InsufficientFundException
// 参数说明
// request.transactionId: 原始Transaction的ID(不是OrderId!)
// request.amount: 退款金额,单位分,不能超过Transaction金额
// request.reason: 退款原因,必须是RefundReason枚举中的值
// ⚠️ 重要:退款金额校验使用的是Transaction的已结算金额
// 不是Transaction的申请金额,差值是手续费,不可退
// 错误示例:用transaction.getAmount()做退款上限校验
// 正确示例:用transaction.getSettledAmount()做退款上限校验已知坑点和边界条件
坑1:重复退款检查
RefundRepository.findByTransactionId(txId)可能返回空,也可能返回已FAILED的记录。 只有COMPLETED状态的退款才算”已退款”。FAILED的退款应该允许重新申请。坑2:异步退款的幂等
executeRefund是异步的,渠道回调可能多次到达(网络重试)。RefundCallbackHandler已经做了幂等处理,但依赖refund_id而不是channel_refund_id作为幂等键。 如果你需要在callback处理里增加逻辑,确保你的逻辑也是幂等的。坑3:退款金额的货币精度系统内部用
long存储分,但PaymentChannelRouter的部分渠道接口用BigDecimal存储元。MoneyConverter工具类处理这个转换,但注意它默认用HALF_EVEN舍入—— 如果退款金额是0.005元,会被舍入到0元,然后渠道会拒绝这个退款请求。 最小退款金额是1分。
### 4.5 Layer 3:历史上下文层——滑动窗口机制
历史上下文层是四层中机制最复杂的一层。它需要解决一个矛盾:在连续性任务中,之前对话的决策很重要(不能丢失);但历史累积会导致窗口膨胀(不能全保留)。
解决方案是滑动窗口:只保留最近N次(默认5次)相关操作的摘要,而不是完整的对话记录。
```mermaid
sequenceDiagram
participant Dev as 开发者
participant Skill as Skill框架
participant History as 历史层文件
participant AI as Claude
Note over Dev,AI: 第1次对话:分析RefundService依赖
Dev->>Skill: 开始任务:分析退款模块依赖
Skill->>AI: 注入 L0+L1+L2(refund)
AI-->>Dev: 分析结果:发现TransactionValidator依赖
Dev->>History: 记录摘要:发现RefundService依赖TransactionValidator\n具体在validate()调用前
Note over Dev,AI: 第2次对话:修改退款幂等逻辑
Dev->>Skill: 开始任务:增加退款幂等检查
Skill->>History: 读取历史(窗口内:1条记录)
History-->>Skill: 返回第1次对话摘要
Skill->>AI: 注入 L0+L1+L2(refund)+L3(1条历史)
AI-->>Dev: 生成幂等逻辑,正确引用TransactionValidator
Dev->>History: 追加摘要:增加了idempotency check\n基于refund_id作为幂等键
Note over Dev,AI: 第6次对话:触发窗口滑动
Dev->>Skill: 开始任务(第6次相关操作)
Skill->>History: 读取历史(窗口内:5条记录)
History-->>Skill: 返回第2-6次对话摘要(第1次被滑出)
Skill->>History: 将第1次摘要归档到archive/
Skill->>AI: 注入 L0+L1+L2+L3(5条历史)
AI-->>Dev: 基于最近历史做出决策
Note over Skill,History: 窗口滑动:第7次操作时,第2次被归档历史层的文件结构:
.claude/skills/history/
├── refund-module/
│ ├── current/ # 滑动窗口内的历史(最多5条)
│ │ ├── 001-dependency-analysis.md # 最早的记录(即将被滑出)
│ │ ├── 002-idempotency-check.md
│ │ ├── 003-fee-precision-fix.md
│ │ ├── 004-callback-handler.md
│ │ └── 005-state-machine-review.md # 最新的记录
│ └── archive/ # 滑出的历史,供人工查阅但不自动注入
│ └── 000-initial-analysis.md
└── payment-gateway/
└── current/
├── 001-orchestrator-review.md
└── 002-fee-adapter-refactor.md每条历史记录的格式应该是高度结构化的摘要,而不是对话全文:
<!-- .claude/skills/history/refund-module/current/002-idempotency-check.md -->
<!-- 历史记录 | 对话日期:2024-03-15 | 任务:增加退款幂等检查 -->
## 决策摘要
**任务**:在RefundService.requestRefund()增加幂等检查
**关键决策**:
- 幂等键使用`refund_id`(由客户端生成),不使用`transaction_id`
- 原因:同一Transaction可能有多次合法的退款申请(部分退款)
- 幂等检查在`RefundValidationService.checkDuplicate()`中实现,不在`requestRefund`直接实现
- 原因:复用已有的校验框架,避免绕过审计日志
**已修改的文件**:
-`RefundService.java`:第89行,增加了idempotency check调用
-`RefundValidationService.java`:新增`checkDuplicate(RefundRequest)`方法
**遗留问题/下次需要关注**:
- FAILED状态的退款是否允许使用相同的refund_id重试(当前实现是允许的,需要PM确认)4.6 完整的目录结构
.claude/
├── CLAUDE.md # 主入口,仅引用宪法层,不包含具体内容
├── skills/
│ ├── constitution.yaml # Layer 0:宪法层(始终加载)
│ ├── module-index.md # Layer 1:模块索引层
│ ├── impl/ # Layer 2:各模块实现详情
│ │ ├── refund-service.md # - 退款服务
│ │ ├── payment-orchestrator.md # - 支付编排器
│ │ ├── transaction-state.md # - 状态管理器
│ │ ├── fee-calculator-adapter.md # - 费率适配器
│ │ └── risk-service.md # - 风控服务
│ ├── history/ # Layer 3:历史上下文(滑动窗口)
│ │ ├── refund-module/
│ │ │ ├── current/ # - 窗口内历史(最多5条)
│ │ │ └── archive/ # - 归档历史
│ │ └── payment-gateway/
│ │ └── current/
│ └── triggers/ # 触发器规则配置
│ ├── task-type-mapping.yaml # - 任务类型→加载层级映射
│ └── module-keywords.yaml # - 关键词→模块映射
└── settings.json # Claude Code配置4.7 触发器设计:任务类型与加载层级的映射
触发器是连接”任务描述”和”加载策略”的桥梁。它把自然语言的任务描述转换成具体的文档加载指令。
# .claude/skills/triggers/task-type-mapping.yaml
# 任务类型到加载层级的映射规则
task_types:
# 快速修复类任务:L0 + L2(具体模块)
quick_fix:
description:"修复bug、调整参数、小范围修改"
keywords: ["修复", "fix", "bug", "调整", "修改", "改一下", "update"]
load_layers: [0, 2]
load_history:false
notes:"快速修复不需要模块索引,直接加载具体模块实现即可"
# 新增功能类任务:L0 + L1 + L2(目标模块)
new_feature:
description:"新增功能点,可能影响多个模块"
keywords: ["新增", "增加", "add", "实现", "开发", "feature", "功能"]
load_layers: [0, 1, 2]
load_history:false
notes:"需要索引层了解模块边界,再加载目标模块的实现细节"
# 重构类任务:L0 + L1 + L2 + L3
refactoring:
description:"重构、优化、技术债还清"
keywords: ["重构", "refactor", "优化", "清理", "解耦", "技术债"]
load_layers: [0, 1, 2, 3]
load_history:true
history_window:5
notes:"重构需要历史上下文,了解之前的决策以避免返工"
# 跨模块改造:L0 + L1(不加L2,避免溢出)
cross_module:
description:"影响3个以上模块的大型改造"
keywords: ["架构调整", "接口变更", "跨模块", "全局修改"]
load_layers: [0, 1]
load_history:false
notes:"跨模块改造中L2不自动加载,需要手动指定具体模块,避免同时加载过多实现层"
# 模块关键词映射(确定任务涉及哪个模块)
module_detection:
refund-service: ["退款", "refund", "RefundService", "退款服务"]
payment-orchestrator: ["支付", "payment", "PaymentGateway", "Orchestrator"]
transaction-state: ["状态", "状态机", "TransactionState", "state machine"]
fee-calculator: ["费率", "手续费", "fee", "FeeCalculator"]
risk-service: ["风控", "risk", "RiskService", "风险"]4.8 跨层冲突处理
一个非常实际的工程问题:当Layer 2的具体实现细节与Layer 0的架构原则出现矛盾时,AI应该如何处理?
这种情况在屎山项目中非常常见。典型场景:Layer 0规定”禁止跨层依赖”,但Layer 2里的某个模块实现里有一段15年前的代码直接从API层访问了数据库。
处理原则应该是明确的,并且要写进宪法层:
# 在constitution.yaml中添加冲突处理规则
conflict_resolution:
principle:"Layer 0是不可违反的约束,但不是强制立即修复的标准"
rules:
-when:"Layer 2中存在违反Layer 0原则的现有代码"
action:"不要在此次任务中修复历史违规,保留现状"
reason:"历史违规的修复需要专门的技术债还清任务,夹带修复风险大"
mark:"在代码注释中标注TODO: ARCH-VIOLATION"
-when:"新增代码需要遵循Layer 0原则"
action:"严格遵循Layer 0,不要以'现有代码也这么做'为由违反"
-when:"Layer 0与Layer 2有明显矛盾(不是历史违规,而是文档更新滞后)"
action:"暂停任务,告知开发者:'Layer 0第N条与Layer 2的描述存在矛盾,需要先确认以哪个为准'"这个设计体现了一个重要的工程判断:在屎山项目中,”发现违规并立即修复”往往比”保留现状并标记”风险更高。屎山的危险在于隐性依赖,修复一个看起来明显的违规,可能破坏三个你不知道的隐性约定。
4.9 四层架构的大小预算计算
最后,用一个具体的数字验证这套架构的可行性:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 总计(最大值) | ~8400 tokens |
|
|
|
|
|
|
|
|
|
| 单次对话总消耗 | ~53400 tokens |
|
这意味着即使进行20轮深度对话,上下文消耗也只有总窗口的27%,留有足够的余量。相比之下,全量加载的4.2万字KNOWLEDGE.md(约5.5万tokens),加上20轮对话历史,会在第8轮左右开始进入危险区。
全局审视:四层结构的逻辑串联
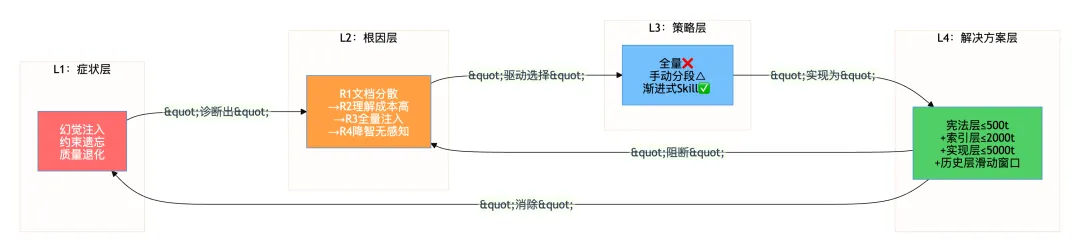
核心洞察:上下文管理不是AI问题,是工程问题。全量注入是把架构决策推给了模型,渐进式Skill是把架构决策收回到工程师手里。
与后续文章的衔接:第4篇将讨论在渐进式Skill体系建立之后,如何安全地进行屎山模块的实际代码改造——这时候上下文管理已经不是瓶颈,真正的挑战变成了”如何在不破坏隐性依赖的前提下进行改动”。第5篇则会讨论改造后的验证策略:测试覆盖、回归验证、以及如何用AI辅助编写针对屎山代码的测试用例。
延伸思考
个人思考与判断
这套渐进式Skill架构有两个核心假设,值得审视:
假设一:文档可以被有效分层。这个假设在大多数项目里成立,但在某些高度耦合的屎山里,可能很难把”必须在任何情况下了解的”和”只在特定场景下需要的”清晰分开。我处理过一个项目,它的核心业务规则分散在代码注释、数据库枚举值、和一个Excel表格里,完全无法形成清晰的层次结构。在这种情况下,建立Skill层级的前置工作是先做文档整合(第2篇的内容),而不是直接跳到Skill设计。
假设二:任务类型可以被预先枚举。触发器设计里我列了4种任务类型,但实际工作中会遇到无法归类的混合任务。这时候的策略应该是”保守注入”:默认只加载L0+L1,需要更多信息时由开发者手动触发L2的加载。宁可AI因为缺少信息而主动问”需要我查看X模块的实现细节吗”,也不要自动加载过多内容。
最可能出问题的环节:历史层的维护。历史摘要需要开发者每次对话结束后手动更新——这是一个高摩擦的步骤。实践中这个步骤往往被跳过,导致历史层要么空着、要么过时。解决方法是在CLAUDE.md里明确指示AI在每次对话结束时生成一份标准格式的历史摘要,开发者只需要确认并保存,而不是从头写。
替代方案的审视
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
适用边界与局限性
明确适用的场景:
-
项目代码量5万行以上,文档超过1万字 -
团队2人以上协作使用AI Coding工具 -
项目有明确的模块边界(即使是屎山,也能粗略划分出模块) -
改造周期超过1个月(前期投入的Skill设计需要足够长的使用周期来回收成本)
不适用或效果有限的场景:
-
一次性小任务(设计成本超过使用收益) -
文档本身极度缺乏(缺少可供分层的素材,需要先完成第1篇和第2篇的工作) -
项目模块间高度耦合、无法划定清晰边界(只能做到粗粒度的分层,效果有限) -
对话任务本身的上下文就很小(如果你每次都只做孤立的5行修改,上下文管理不是瓶颈)
已知局限:这套架构假设开发者能准确判断任务类型,能在对话结束后更新历史层,能在文档变更时同步更新Skill文件。这些人工步骤是整个体系的弱点,也是未来可以通过工具化来减少摩擦的方向。
屎山项目 AI Coding 实战系列
-
第1篇:屎山诊断——在改之前先读懂它 -
第2篇:知识抽取——把散落的文档变成AI可消费的结构 - 第3篇:渐进式文档加载——防止上下文溢出的Skill设计(本篇)
-
第4篇:安全改造策略——在不破坏隐性依赖的前提下修改屎山代码(待发布) -
第5篇:改造验证——AI辅助测试覆盖与回归验证(待发布)