 夜雨聆风
夜雨聆风





当翻译工具开始思考:ai-polyengine-trans 的工程美学
工程报告翻译处理,听起来是个简单任务——读文档,翻文档,写文档。但当这个任务遇上中英法三语混合、超长文档分段、术语一致性保障、质量可观测性四重挑战时,事情就变得有意思起来了。
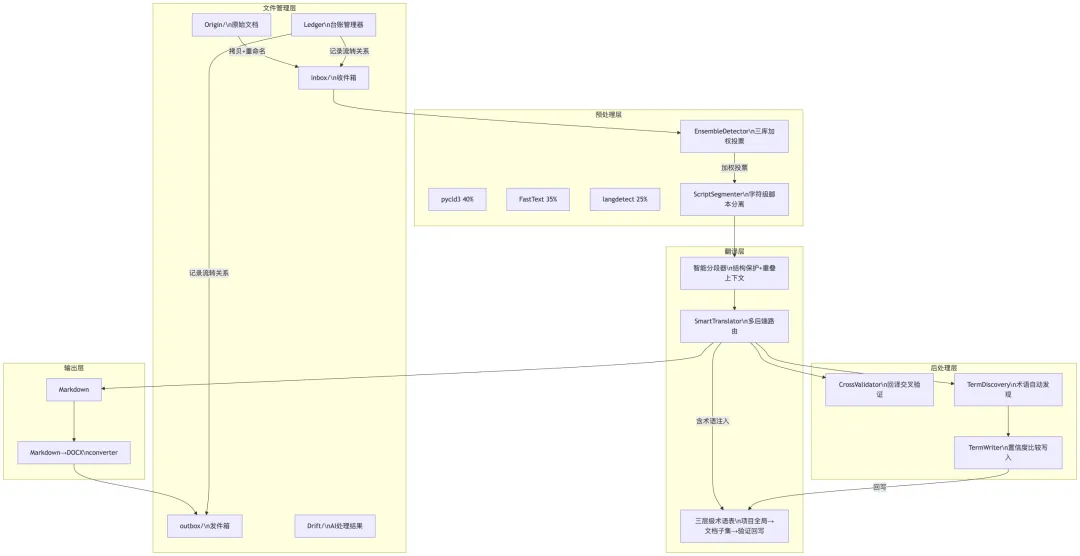
一、系统全貌
系统架构图如下:
二、系统亮点
亮点 A:三库集成的语言检测引擎
翻译的第一步,不是翻译——是知道这是什么语言。对于一份可能同时出现中文、英文、法文的工程邮件,简单的单一检测器远远不够。
系统采用三库加权投票机制,由 EnsembleDetector 统一协调:
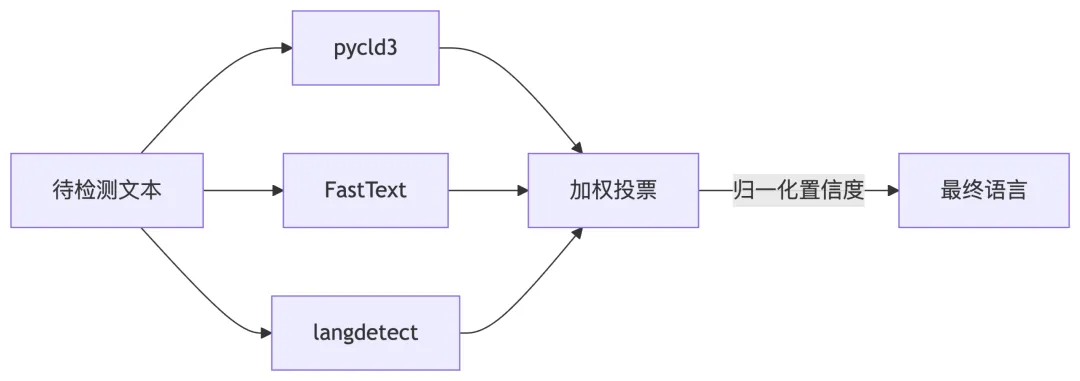
核心投票算法在 EnsembleDetector._weighted_voting() 中实现:
# 累加各语言的加权得分
for result in results:
if result.confidence < self.confidence_threshold:
continue
weight = self.weights.get(result.detector_type, 1.0)
weighted_score = result.confidence * weight
lang_scores[result.language] += weighted_score
lang_counts[result.language] += 1
# 归一化
confidence = best_score / sum(lang_scores.values())
# 可靠投票数惩罚(防止单库误判)
if len(results) > 1 and reliable_votes < self.min_reliable_votes:
confidence *= (reliable_votes / self.min_reliable_votes)权重配置:pycld3(40%) + FastText(35%) + langdetect(25%),低于置信度阈值(默认 0.6)的结果直接排除,不参与投票。三层回退机制:集成检测失败则退至单库,单库失败则退至规则检测。
亮点 B:字符级脚本分离
一段真实的工程邮件可能是这样的:
Cher Monsieur Li, please find attached the rapport de structure. The calculated 水平转换梁 load is 450 kN. Veuillez confirmer avant le 15⁄03.
中英法三语混杂在同一段落里,甚至同一句话里。大多数翻译系统的做法是”整段丢给 LLM”,结果就是灾难性的——中文被翻译成英文,英文被翻译成中文,法语彻底乱套。
系统的解法是字符级脚本分离,ScriptSegmenter 在送入翻译之前,先将文本切分为连续同脚本段:
# Unicode 码点判断
def _get_script_type(char: str) -> ScriptType:
cp = ord(char)
# CJK
if 0x4E00 <= cp <= 0x9FFF:
return ScriptType.ZH
# French 特符
if char in _FRENCH_ACCENTS:
return ScriptType.FR
# 法语特征词
if _is_french_word(text_around):
return ScriptType.FR
return ScriptType.EN分离后,<k> 标签标记”保留原文”(中文),<x> 标签标记”需要翻译”(英文/法文),交给 LLM 端到端处理。LLM 收到的 prompt 不再是”翻译这段话”,而是”这些是中文请保留,这些是英文/法文请翻译”,精确度天壤之别。
亮点 C:回译交叉验证
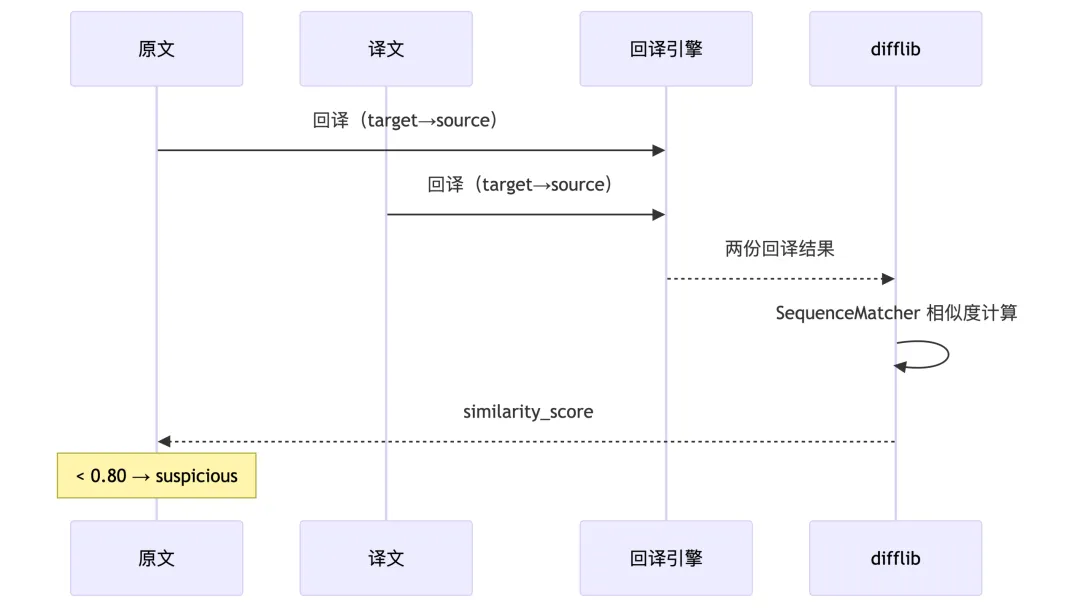
翻译质量好不好,不是靠感觉。CrossValidator 抽取 15%(默认随机)-100%(用户指定) 的段落,将译文回译回原文,计算相似度:
sequenceDiagram
participant S as 原文
participant T as 译文
participant BT as 回译引擎
participant Diff as difflib
S->>BT: 回译(target→source)
T->>BT: 回译(target→source)
BT-->>Diff: 两份回译结果
Diff->>Diff: SequenceMatcher 相似度计算
Diff-->>S: similarity_score
Note over S: < 0.80 → suspicious
for segment in sampled_segments:
back = translator.translate(segment.translated, target=source_lang)
score = SequenceMatcher(None, segment.original, back).ratio()
if score < self.min_similarity:
mark_suspicious(segment)低于 0.80 阈值的段落被标记为可疑,写入 validation_report.md,触发人工审核流程。
亮点 D:置信度驱动的术语自动发现
工程翻译最怕的不是翻译错,而是同一个术语出现五种译法。TermDiscovery 在翻译时由 LLM 自动识别专业术语,TermWriter 按置信度规则写入术语表:
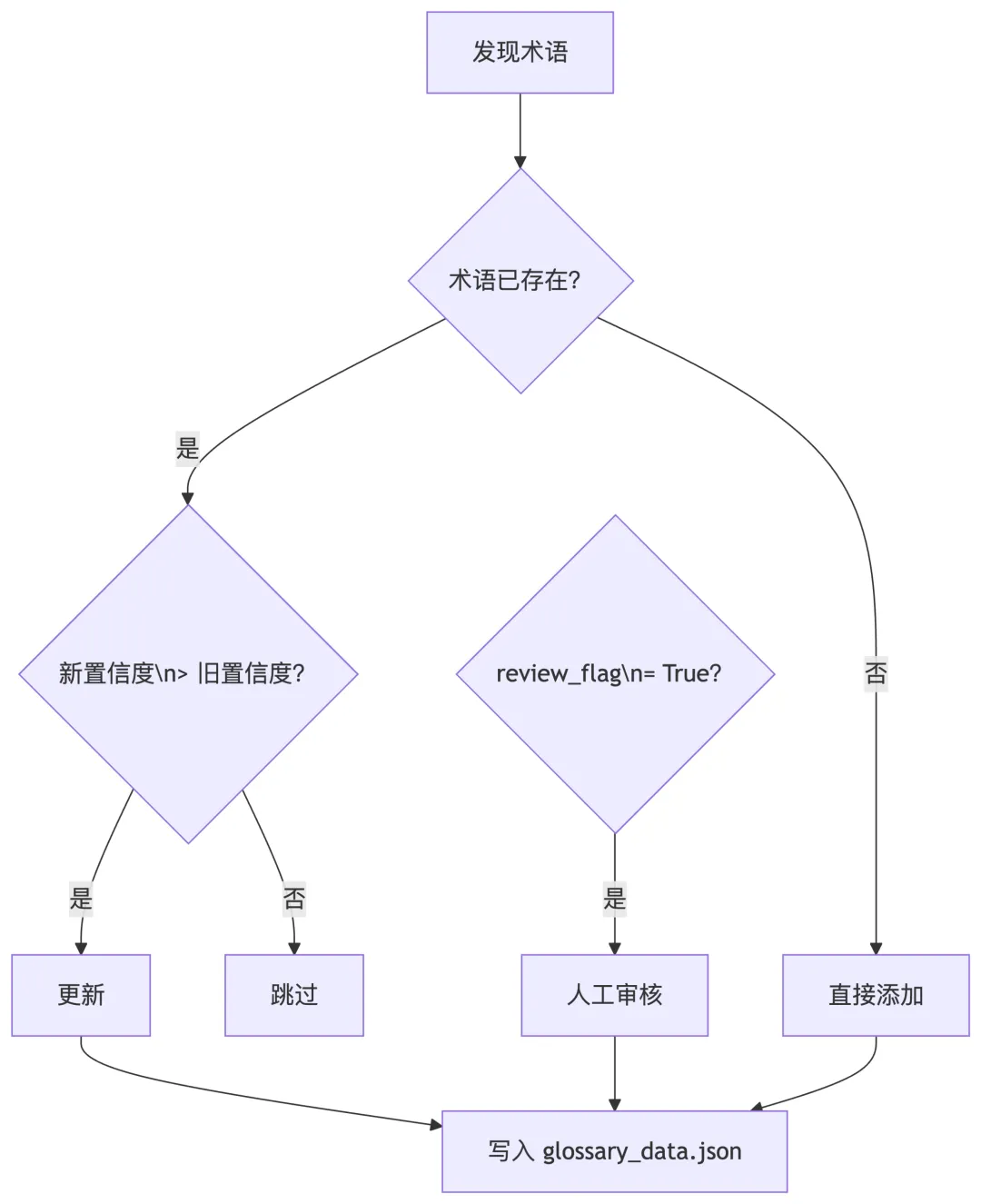
所有变更记录在 metadata/ 目录,版本可追溯,冲突有日志。
三、技术栈一句话
Python 3.11 + uv 包管理 + Pydantic 类型验证 + Rich 彩色 CLI + watchdog 文件监控 + 多 LLM 后端(OpenAI / DeepSeek / MiniMax / Moonshot),核心翻译逻辑收敛在 core/ 共享服务层,所有项目统一调用。
四、结语
大多数翻译工具解决的是”翻得对不对”的问题。这个系统解决的是大规模专业文档翻译的一致性、可观测性与质量控制问题——它不只是一个翻译脚本,而是一套完整的工程翻译处理流水线:文件从哪来、翻成什么、分几段、术语对不对、质量谁负责,全流程可追踪。
复杂不是为了炫技,而是因为工程翻译这件事本身就值得被认真对待。