大文档翻译别只盯着网页:这个开源工具把 Word、Excel、PPT 拉回本地处理
DeeplxFile 不是又一个网页翻译入口,而是一个面向 Word、Excel、PPT、txt、md 和 PDF 转 docx 场景的文件翻译工具。它把文档解析、文本翻译、结果回写和多种翻译模式放进同一个 GUI 里,适合经常处理大文件和复杂格式的人。
基于Deeplx/playwright提供的简单易用,快速,免费,不限制文件大小,支持超长文本翻译的文件翻译工具
Easy-to-use, fast, free, unlimited file size and cross platform file translation tool based on Deeplx & Playwright that supports long text translations.
这句话里有几个关键词:文件翻译、长文本、跨平台、DeepLX、Playwright。
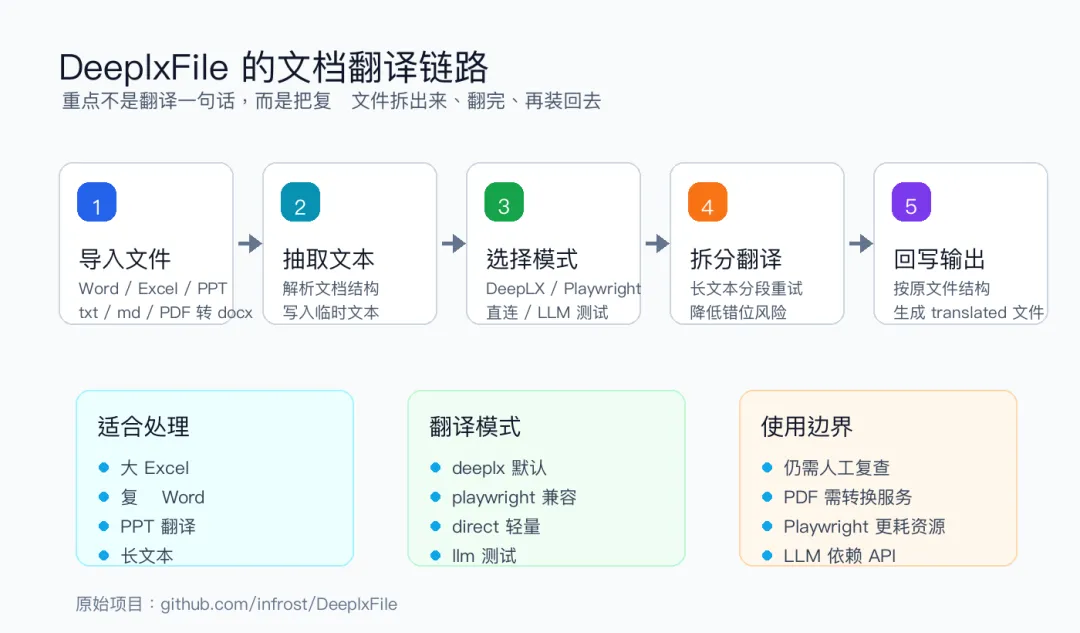
所以它不是那种把一句话丢进去翻译的小工具。它更像是给大文档翻译准备的本地工作台。
截至 2026-05-07 21:29 CST,我通过 GitHub API 看到的数据是:1063 stars、93 forks、18 open issues,主语言是 Python,许可证是 GPL-3.0。仓库创建于 2024-08-15,最近 push 是 2025-02-16。
最新 release 是v0.5.11,发布于 2025-02-11。release 里提到两件重要更新:增加大模型翻译功能,Deeplx 内核同步到V1.0.4。
DeeplxFile 头条封面它解决的不是单句翻译
比如一个很大的 Excel 表,要保留公式和引用关系;一个 Word 文档,不能把段落、样式和表格拆坏;一个 PPT,翻译完还得尽量回到原来的页面结构里;一个 PDF,要先转成可编辑的 docx,再继续处理。
README 里明确写到,它支持 Word、Excel、PowerPoint,也支持 txt、md 文档翻译。PDF 翻译则需要配合作者另一个独立的pdf2docxserver转换服务:先把 PDF 转成可编辑 docx,再由 DeeplxFile 调用后续翻译流程。
这类工具的价值,不在于“翻译接口有多神”,而在于它愿意处理文档里的脏活:抽取文本、拆分长文本、翻译、再把结果回写到原文件结构。
DeeplxFile 文档翻译链路它有四种翻译模式
我看了deeplxfile_gui.py,里面的翻译模式大概分四类。
这是配置里的默认模式。程序会启动自带的 DeepLX 内核,或者使用用户填写的自定义 Deeplx 服务器地址。config.json里当前版本是0.5.11,deeplx_core_version是1.0.4。
README 说从v0.5.0开始支持这个模式。它不依赖项目里的 DeepLX 内核,而是通过 Playwright 模拟人打开浏览器、复制粘贴翻译内容,再把结果取回来。
这个模式的好处是兼容性强,可以处理大量文本,并且能规避 DeepLX 内核带来的“请求频繁”问题。缺点也写得很清楚:占用系统资源更多,速度更慢。macOS 这边,README 还特别提示如果要用 Playwright 模式,需要确保系统安装了 Edge 浏览器。
它同样不依赖 DeepLX,但 README 说可用性较低,容易遇到 DeepL 服务器“请求频繁”的拒绝。源码里的 GUI 提示也写着,这个模式更适合较小文件,大文件还是建议使用 DeepLX 引擎。
v0.5.11release 里提到“现已支持大模型翻译”,源码里也能看到大模型设置页:API 地址、API key、模型名、单次翻译长度限制和自定义翻译要求。默认 API 地址是https://api.openai.com/v1,默认模型字段是gpt-4o。
README 举的例子是:这是一封商务信函,使用庄严体翻译。
这和传统机器翻译不太一样。传统翻译更多是句对句,大模型模式则可以给上下文、语气、行业背景,让翻译更贴近具体场景。
不过项目自己也把它标成测试功能,不要把它当成已经完全稳定的生产级翻译平台。
长文档靠拆分和回写撑起来
DeeplxFile 比较现实的一点,是它没有假装“大文档一次丢进去就万事大吉”。
release 记录里能看到,v0.5.10rc2做过“翻译字符超出限制自动拆分文本重试”,v0.5.10rc3修过“文本拆分后翻译错位”的问题。
一旦原文第 100 行对应到译文第 101 行,后面回写就会乱。表格、PPT、公式引用、段落结构都可能被带偏。
DeeplxFile 的流程是先把文档内容抽出来,写到临时文本里;翻译完成后,再根据原文件回写。源码里process_translation()会先调用extract.extract_file(),翻译完成后调用compose.compose_file()。
Excel 是它最容易打动人的场景
README 里拿 Excel 举了一个很典型的例子:DeepL 免费版不支持 Excel 翻译,Google 又不支持超过 10MB 的大文件翻译。
你有一个几十 MB 的表格,里面还有公式、引用、多个 sheet。你不只是想知道某个单元格是什么意思,而是希望翻译后还能继续用这个文件。
DeeplxFile 的 README 还提到,Google 翻译在复杂公式引用上无法正确显示,而 DeeplxFile 能正确显示引用公式。
这个说法来自项目自述,我没有拿真实复杂表格复测,所以更适合写成“作者主打的能力”和“它试图解决的场景”,不要写成绝对保证。
很多人不是缺一个翻译按钮,而是缺一个能尽量保住文件结构的翻译流程。
怎么用
如果你是 Windows 用户,README 推荐下载Full版本。原因是 Full 包含完整 WebKit 内核,Playwright 模式稳定性更好。
Lite版本不带 WebKit 内核,会调用系统自带 Edge 浏览器,体积更小,但 README 说对 Edge 的支持还在测试阶段。
macOS 用户的 README 写法比较直接:右键解压出来的文件,选择打开新终端,然后运行:
如果你要在源码运行时使用 Playwright 模式,README 还提醒需要手动下载playwright-webkit放到./Lib/webkit目录,或者在Lib/playwright_process.py中指定 Playwright 的运行目录。
这里有个小细节:README 中 macOS 命令写的是./deelxfile,拼写和项目名DeeplxFile不完全一致。实际使用时还是要以下载包里的可执行文件名为准。
它适合谁
-
经常处理 Word、Excel、PPT 翻译的人;
-
-
-
愿意接受本地 GUI、浏览器自动化和一些配置的人;
-
想尝试 DeepLX、Playwright、大模型几种模式切换的人。
-
-
期待完全无配置、无报错、像商业 SaaS 一样稳定;
-
不想处理 Edge、WebKit、DeepLX 内核或 API key;
-
对 GPL-3.0 许可证有集成顾虑的商业闭源项目;
-
梦飞的判断
DeeplxFile 有意思的地方,是它没有把自己做成一个“更漂亮的翻译框”。
单句翻译现在到处都有,真正消耗人的,是把一个复杂文档翻完后还能用。表格别乱,公式别断,PPT 别崩,长文本别错位,失败后还能继续或恢复。
DeeplxFile 现在还不是一个我会说“所有人马上装”的工具。
它依赖外部翻译能力,也会遇到请求频繁、浏览器自动化稳定性、长文本错位、PDF 转换服务这些现实问题。大模型翻译也还在测试阶段。
但如果你经常被大文档翻译折腾,它值得放进工具箱里试试。
它解决的不是“翻译一句话”,而是“翻完一个文件还能不能继续干活”。
原文链接
https://github.com/infrost/DeeplxFile
 夜雨聆风
夜雨聆风