 夜雨聆风
夜雨聆风





翻译插件+本地模型:0成本搞定日常翻译
如果你平时需要读很多英文内容,大概率你也用过各种翻译插件。但很可能你也遇到过这些问题:
-
• 翻译插件的会员费太贵 -
• 模型API价格太高 -
• 模型延迟高,影响效率
最近我把整个翻译流程,迁移到了本地大模型,效果出乎意料的好,在这里分享一下我是怎么实现的。
动机
平时我的工作流程中,浏览网页和阅读论文都需要看大量英文,为此,我安装了两个插件进行翻译:
一是浏览器的沉浸式翻译插件。这个插件可以把英文网页翻译成中文,同时还保留原文的显示,像下面这样:
二是zotero的划词翻译插件。在阅读论文的时候,可以划选一段内容进行翻译,像下面这样:

这两个插件本质都是通过调用大模型来翻译。可以自定义api,模型和prompt。因此,可以直接买网上的llm服务,也可以本地部署一个模型来翻译。我实测发现,现在的9B的Qwen3.5模型,在这种翻译任务上,跟顶尖闭源模型的差别不大。如果有需求的话还可以找到更小的专精翻译的模型。因此,我尝试配置本地模型来进行翻译。
本地模型部署
由于是在个人电脑上部署,不想花太多时间去折腾环境配置,希望有一个开箱即用,兼容性好的方案。因此我选择了LM Studio作为部署方式。LM Studio是一个跨平台图形界面软件,可以很方便地下载模型、修改配置。推理的后端也适配了多个平台,包括cpu,cuda,vulkan,metal等等。我实测n卡,a卡,apple silicon都能运行,效率都还不错。例如,在我的4080显卡上运行Q4_K_M量化的qwen3.5-9b,常见的翻译负载下,ttft大约是0.5s,generation throughtput大约是100token/s
LM Studio可以把模型部署为openai-compatible的api,部署后,对先前提到的两个插件进行配置就可以使用本地模型进行部署了。
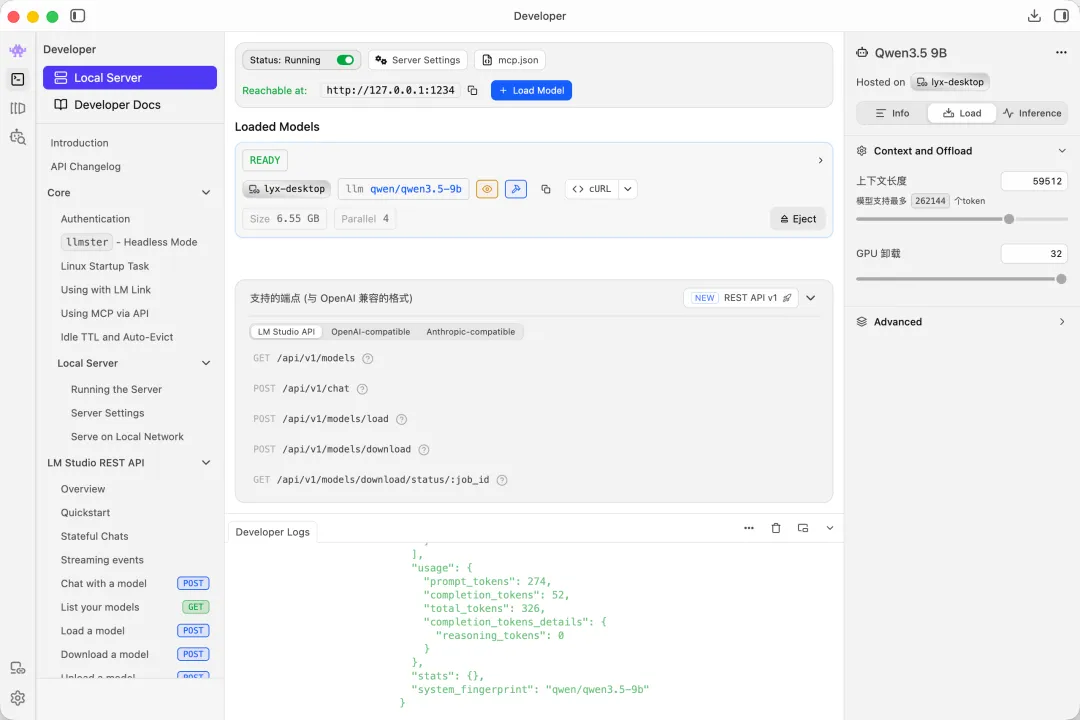
配置local servel部署本地模型
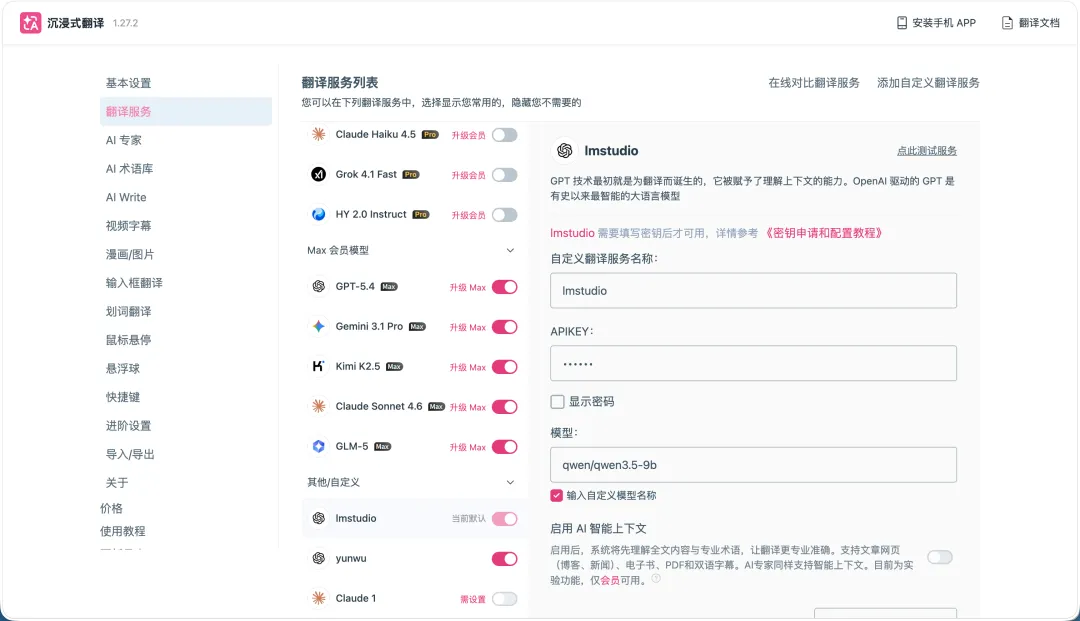
配置沉浸式翻译插件
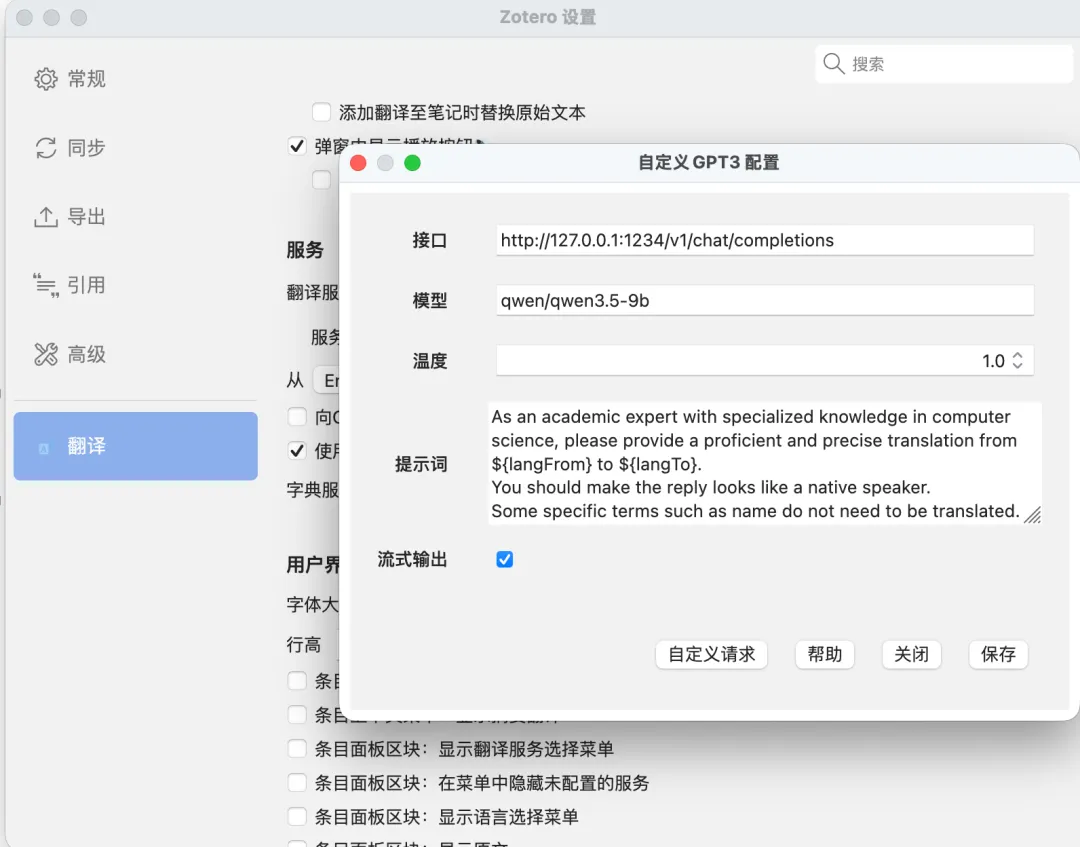
配置zotero划词翻译插件
远程调用
由于我的macbook只有16g内存,部署本地模型比较捉襟见肘。我就希望能把模型部署在台式机4080上,在macbook进行调用。幸运的是,最近LM Studio推出了LM Link服务,可以非常简便地实现这个效果。
只要在两台电脑都登录同一个账号,简单配置一下就可以让两台电脑互相访问。在local server load模型的时候,可以load台式机上的模型,local server会把收到的请求转发到台式机上。
至此,我们实现了翻译自由。