 夜雨聆风
夜雨聆风





为Agent而设计:软件交互范式的三次进化
上周,Salesforce 在其年度 TDX 开发者大会上发布了一项重磅消息——”Headless 360″计划,将其平台的每一个能力都暴露为 API、MCP 工具或 CLI 命令,让 AI Agent 可以完全绕过浏览器来操作系统。
这是 Salesforce 27 年历史上最大胆的架构变革。
与此同时,Ramp 的数据显示,过去三个月其 MCP 的周活跃用户增长了 10 倍。越来越多的客户通过 Claude、ChatGPT 和其他 Agent 来使用他们的产品。
UI 真的要死了吗?
不。但软件设计的规则,正在被彻底改写。
PART 01
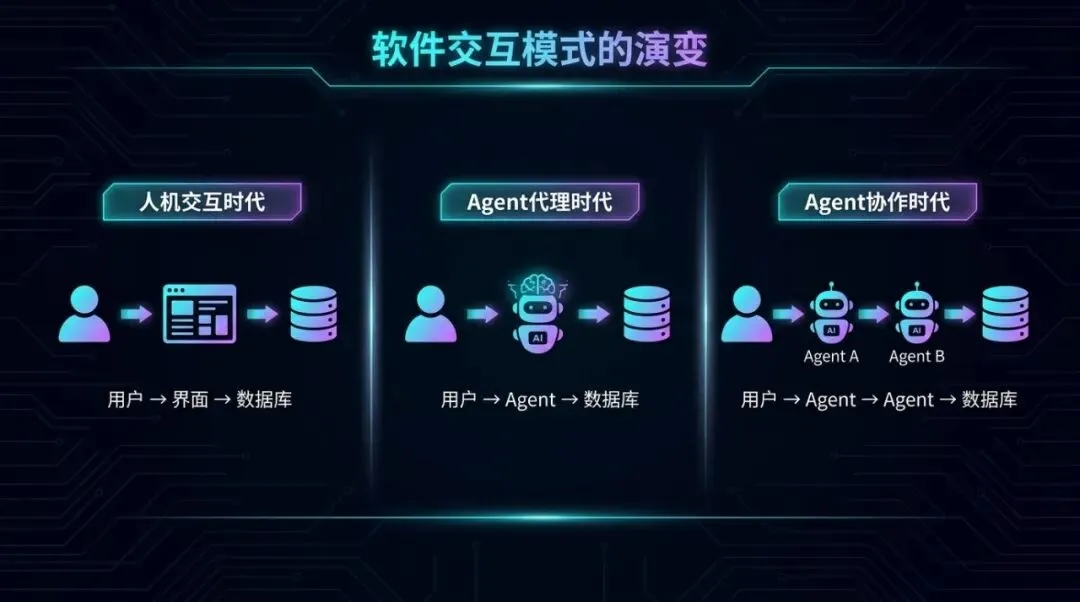
一、交互模式的三次进化
过去二十年,人们使用软件的方式一直是这样的:
用户 → 界面 → 数据库
你打开一个产品,点击、填写、提交,界面就是你体验软件的全部。对大多数人来说,界面就是产品本身。
随着 Agent 承担越来越多的工作,一个新的层级出现了:
用户 → 用户的 Agent(如 Claude)→ 数据库
Agent 代表用户行动——读取、写入、导航产品,用户不再需要亲自操作。界面消失了,Agent 直接与底层系统对话。
但这个模式也在快速演变。软件公司正在(也应该)设计自己的 Agent 和能力,于是最新的模式变成了:
用户 → 用户的 Agent → 软件的 Agent → 数据库
在这个模型中,软件侧的 Agent 代替用户侧的 Agent 处理复杂性:应用业务逻辑、执行规则、引入后者不具备的上下文。两个 LLM 协作驱动,共同达成目标。
这不是科幻,这是正在发生的事。Salesforce 的 Headless 360 就是这个模式的现实落地。
PART 02
二、UI 没有死,但 80/20 法则翻转了
人类仍然想要点击、查看配置、确认完成的工作。UI 不会消失。
但交互的主次已经颠倒:新的 80% 的软件交互将通过 Agent 完成,只有 20% 需要人类亲自操作。
这不仅改变了你需要构建什么,还改变了你构建它的方式。
Salesforce 的做法很聪明,也一定不容易。问问大多数销售人员,他们会告诉你 Salesforce 有多难用。但这个产品之所以无处不在,是因为它的 UX 已经深入人心。销售团队的领导不想让团队学习新工具,一致性往往胜过功能性。
Benioff 和团队接受了这个护城河正在被侵蚀的现实,主动拥抱了未来——大部分使用将由 Claude、ChatGPT 和其他后台 Agent 驱动,用户甚至看不到界面。
PART 03
三、教会 Agent 如何成功
作为 Notion MCP 的用户,有一点让我印象深刻:每次我让 Agent 写点什么,它都能完美搞定。表格、列表、加粗、斜体——Agent 从不出错。
这是设计出来的。
Notion 的 notion-create-pages 工具描述开头写道:”关于完整的 Markdown 规范,请先获取 MCP 资源 notion://docs/enhanced-markdown-spec。不要猜测或编造 Markdown 语法。”
当我让 Agent 写入一个页面时,它做的第一件事就是获取这个规范,然后再写入。每一个 Notion 特有的细节都被明确标注,而不是依赖模型的默认假设。
在旧世界里,这个规范会躺在 API 文档里,开发者读完后内化于心,然后写一个转换层。现在,Notion 直接把规范交给了 Agent——在它需要的那一刻。
反面教材是 Slack MCP。你的 Agent 会假设标准 Markdown,不遵守 Slack 特有的格式。结果你花在编辑格式上的时间,比自己写这条消息还多。

当然,格式指南在网上可以找到,你可以保存下来教你的 Agent。但这很烦,而且不应该由用户来做。
设计原则:想想你的 Agent 调用者需要知道什么才能成功,然后主动提供给它。别让它自己去摸索。
PART 04
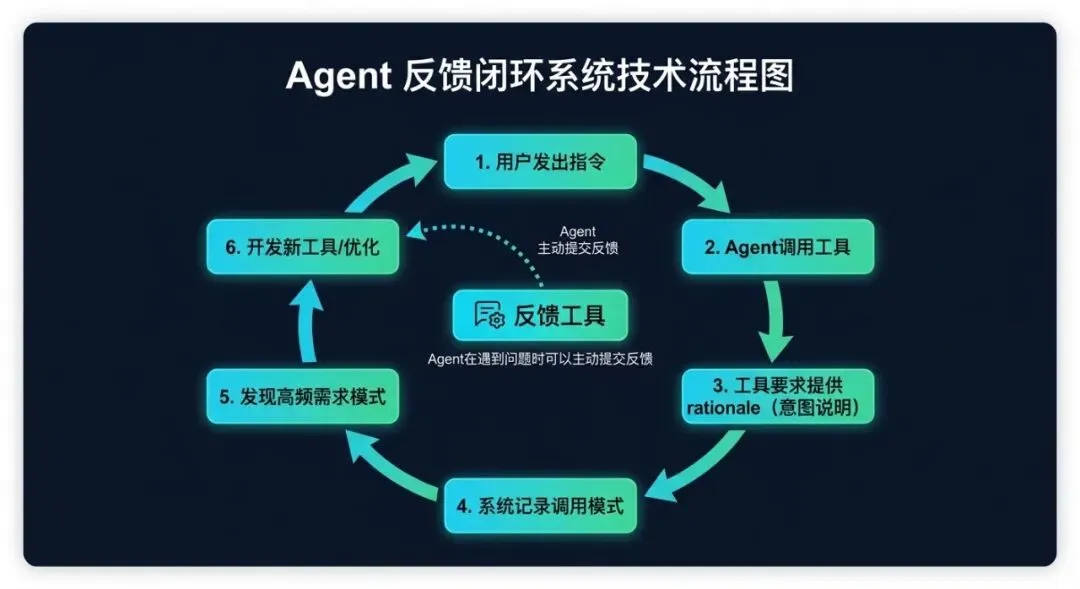
四、构建反馈闭环
Ramp 在最初上线 MCP 时,最大的问题是可观测性。他们能看到工具调用量,但看不到产生这些调用的对话上下文。仅凭调用量无法判断什么在起作用、什么在出问题、用户真正想做什么。
他们用几种方式解决了这个问题:
1. 要求每次工具调用都附带”理由说明”。 每个 MCP 或 CLI 工具调用都要求 Agent 包含一个 rationale 参数,解释为什么发起这个请求。虽然看不到聊天内容,但理由说明可以重建用户意图。理由中的模式告诉他们用户真正在做什么。
2. 提供一个反馈工具。 他们发布了一个独立的工具,当 Agent 遇到阻碍或发现某个模式不奏效时,可以主动调用。Agent 会提交它想做什么、尝试了什么、在哪里卡住了。
3. 工具级别的专用参数。 他们在各个工具中添加了专用参数,用来捕获后续分析需要的上下文——这些信息 Agent 本来就有,但系统不得不去推断。
想象你在构建一个客户支持平台,提供工单查询工具。过了一段时间,你在理由日志中反复看到相同的短语:”构建事故报告”、”起草事故摘要”、”为故障复盘收集工单”。
这就是一个新功能!一个”构建事故报告”工具可以自动识别相关工单、评估严重程度、拉取受影响的客户群体、并按固定格式起草摘要。
上线后,你可能会收到 Agent 的反馈:”报告拉入了三天前与此事故无关的工单”或”它总是包含免费用户的数据,复盘不应包括这些”。突然之间,Agent 在告诉你的 Agent 该构建什么。
Agent 会犯错,没错。但它们的反馈比大多数人类用户更具体、更一致。
这就是 Agent 驱动的产品迭代:Agent 的使用行为暴露需求,Agent 的反馈驱动改进。
PART 05
五、弥合上下文鸿沟
在任何 Agent 交互中,你的系统拥有调用方 Agent 没有的上下文,而调用方 Agent 拥有你的系统没有的上下文。设计这些交互时,你应该清楚各自的优势在哪里。
来看一个具体场景:
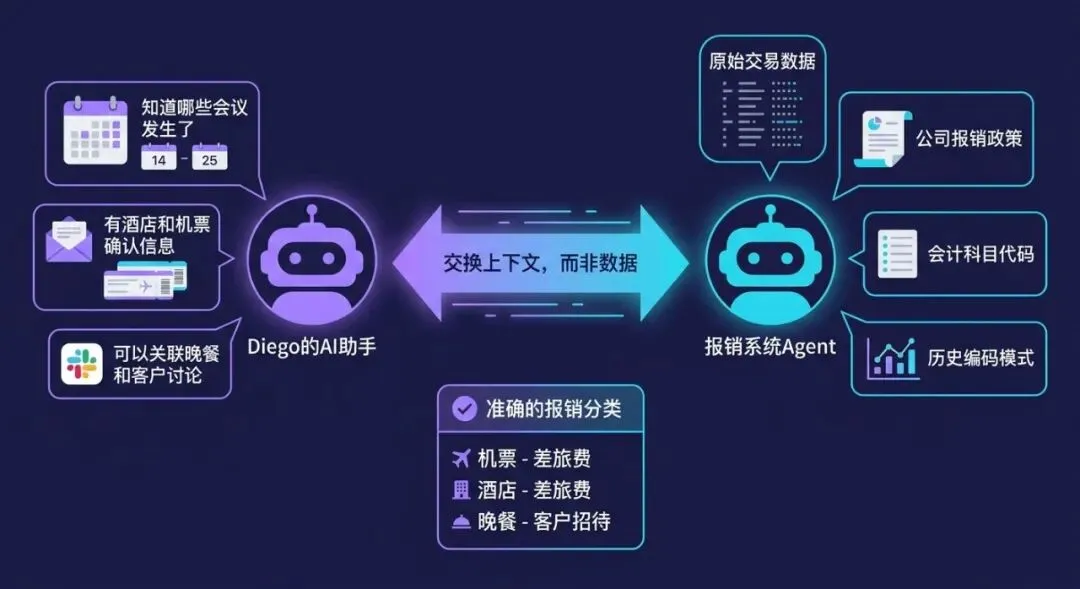
Diego 出差回来。Diego 的 AI 首席助手收到了报销系统 Agent 的提醒:他有一笔未完成的报销。两个 Agent 现在指向同一个目标:正确提交这笔报销。
Diego 的首席助手拥有的上下文:
- Diego 的日历:知道哪些会议发生了、什么时候、和谁
- Diego 的邮件:有酒店和机票确认的附件
- Diego 的 Slack:能把 Kokkari 的晚餐和他邀请 Acme 团队的讨论串关联起来
- Diego 的收据(从邮件附件和照片库中提取)
报销系统拥有的上下文:
- 原始交易数据(商户、交易时间)
- 公司的报销提交政策
- 公司的会计科目代码
- 公司的历史编码模式
传统的 API 会把问题丢回给用户:”这是一个需要会计科目代码的交易。使用这个端点获取 150 个科目代码选项,选一个。”
设计良好的 Agent 交互则相反——它不问科目代码,它问上下文:这是一次客户聚餐、团队聚餐还是个人差旅?首席助手 Agent 从日历或 Slack 讨论串中找到答案。报销系统根据这个它原本缺失的上下文,自动应用正确的科目代码。
Diego 和他的 Agent 永远不需要知道科目代码是什么,财务团队却得到了准确的分类。每一方贡献自己知道的东西,交付了一个对 Diego——和他的会计——都更好的结果。
设计原则:在设计 Agent 对 Agent 的交互时,注意上下文鸿沟。承认你的 Agent 的不足是完全可以的——你们服务的是同一个用户。
PART 06
六、像设计给人类一样设计给 Agent
界面曾经横亘在 Diego 和他的报销系统之间。现在,它横亘在他的 Agent 和你的 Agent 之间。
这个转变重新定义了产品团队的工作。你过去是为一个想要快速行动、避免错误、看到自己工作成果的人设计。现在你是为同一个人设计,但通过一个中介——这个中介的直觉、上下文和局限性与人类完全不同。
教会 Agent 如何成功、构建反馈闭环、弥合上下文鸿沟——这些都指向同一个根本问题:你的 Agent 调用者需要什么才能做好它的工作,你是否给了它?
大多数公司会上线一个 MCP,打个勾就继续往前走了。它们的使用量会增长几个季度,然后停滞。随着时间推移,客户会流向那些在细节上下功夫的产品,绕过那些没有的产品。
像为人类设计一样精心地为 Agent 设计。在你意识到之前,它就是那个签支票的了。
THANKS FOR READING
⚡ 爱马仕 · Hermes Agent 技术分享