 夜雨聆风
夜雨聆风





重症医学翻译的“生死线”:解构 AI 工具的多模态评估范式

在重症医学(Critical Care)这一对准确性有着极致要求的领域,语言障碍不仅是教育传播的阻碍,更直接关乎患者安全。由 Christine L. Chen(梅奥医学中心)领衔的研究团队在《BMC 医学教育》(BMC Medical Education,2025年7月发布)上发表了论文 A systematic multimodal assessment of AI machine translation tools for enhancing access to critical care education internationally(《增强国际重症医学教育的可及性:AI 机器翻译工具的系统性多模态评估》),为医疗教育者如何审慎选择和评估 AI 翻译工具提供了科学的实证框架。
1. 文献核心框架与观点陈述
文献指出,随着大语言模型(LLMs)的爆发,机器翻译(MT)在医疗领域的应用正由“杂乱无章”走向“急需规范”的阶段。该研究针对梅奥中心著名的 CERTAIN 项目教学内容,选取了 DeepL、Google Gemini(1.5 Flash)、Google Translate 及 Microsoft CoPilot(GPT-4 Turbo)四款免费工具,对中文(普通话)、西班牙语和乌克兰语的翻译质量进行了多模态评估。
研究构建了一个由三个维度组成的评估模型:1) 临床医生双盲评价(基于流利度、充分性和语义);2) 自动化的 BLEU 评分(评估与金标准译文的相似度);3) 系统可用性量表(SUS,评估工具的操作便捷性)。
针对中文(Mandarin)翻译的实证发现:文献显示,在中文语向中,Google Gemini 在流利度(fluency)上得分最高,而专业的人类译者在充分性(adequacy)和语义表现(meaning)上依然占据绝对优势。相比之下,Microsoft CoPilot 的综合评分最低。盲评专家指出,所有 AI 工具在处理重症医学专业术语时都存在“硬伤”,例如将“patient-centered care(以患者为中心的医疗)”误译为“护理(nursing care)”,或在“cricothyrotomy(环甲膜切开术)”等高风险操作术语上出现关键性错误。此外,AI 工具还常使用过时的医学术语,如将“propofol(丙泊酚)”译为旧称“异丙酚”。
跨语言表现的差异化:文献强调,没有任何一款 AI 工具能在这三种语言的所有指标上同时胜出。在西班牙语中,Google Gemini 的评分略高于人类译者;但在乌克兰语这类相对低资源的语言中,AI 的 BLEU 评分普遍处于“难以理解(hard to get the gist)”的水平,仅 Microsoft CoPilot 达到了“可理解”的范畴。有趣的是,CoPilot 在乌克兰语的翻译质量得分最高,但其系统可用性评分(SUS)却是最低的,这反映了高质量输出与糟糕用户体验之间的脱节。
2. 信息图
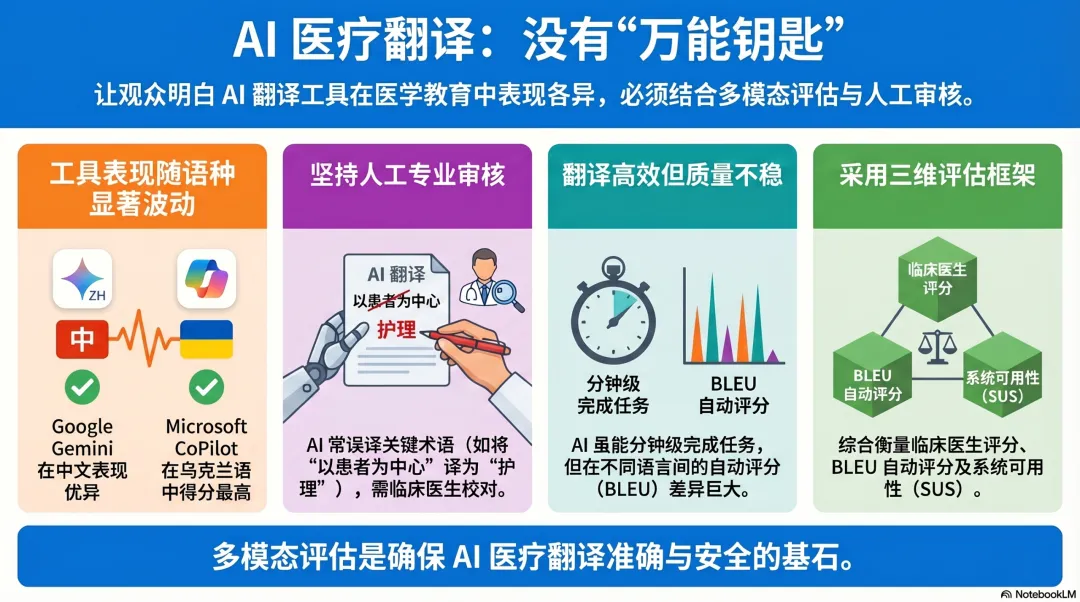
3. 启发与思考
从这篇文献所展示的多模态评估结果中,我们可以清晰地感知到:在高度专业化的领域,AI 翻译正处于“流利度有余而严谨度不足”的阵痛期。
“词汇滞后”是医学翻译的职业雷区。文献中提到 AI 仍在使用“异丙酚”这种旧词,这对于长期在临床一线的译者来说是一个重要的警示。医学术语的更新往往伴随着诊疗标准的演进,译者必须具备比 AI 更敏锐的术语更新能力。这启示我们在翻译教学中,不能仅仅训练学生如何使用工具,更要培养他们识别“过时译名”的学术敏感性,确保译文能与最新的临床指南接轨。
低资源语言的“数据鸿沟”依然是 AI 的软肋。乌克兰语翻译中普遍偏低的评分提醒我们,在非主流语种的重症医疗教育中,过度依赖 AI 可能会带来致命的信息缺失。文献提到的“多模态评估框架”实际上为医疗机构设定了一道防火墙:在将 AI 引入工作流之前,必须经过临床医生的“专业质检”。作为从业者,我们的核心价值正从“原始翻译”向“高阶审校”和“伦理风险管控”转型。
可用性与质量的权衡。文献发现 CoPilot 质量高但操作难,DeepL 则在可用性上表现出色。这告诉我们,在搭建国际教育平台时,工具的“上手门槛”同样会影响知识的传播效率。未来的翻译实务不仅要追求“译得准”,还要追求“用得顺”。这种“以用户为中心”的评价逻辑,值得每一位从事语言服务的管理者深入思考。

相关推荐
中传党委书记廖祥忠两会发言砍掉翻译专业!上外冯庆华教授有话说