 夜雨聆风
夜雨聆风





3B参数打翻众大模型!MOCR如何颠覆文档解析
你一定有过这样的经历:收到一份精美的PDF报告,想提取里面的数据图表,却发现只能截图保存,完全无法编辑。或者扫描了一篇论文,复杂的公式和图表成了死数据,只能一个个手动重新绘制。
这就是传统OCR的痛点——它只能”看见”文字,却”理解不了”图片中的图表、公式、流程图这些视觉元素。
直到最近,一个由华中科技大学和小红书hi lab联合推出的3B参数模型MOCR,悄悄打破了这一局面。更让人惊讶的是,它在图形重建能力上竟然超越了谷歌的Gemini 3 Pro,在开源模型中排名第一。
今天就来聊聊这个”小身材大能量”的模型,以及它会如何改变我们对文档的理解方式。

一、什么是MOCR?一句话概括”解析一切”
MOCR(Multimodal OCR)是华中科技大学与小红书hi lab联合推出的多模态文档解析模型。它的核心使命只有一个:让机器不仅能”读”文字,还能”懂”图表、公式、流程图等所有视觉元素。
为什么说是颠覆?
传统OCR就像一个只认识汉字的文盲,能读出”这是表格”,但不知道表格里有什么数据。而MOCR更像一个全能的”理解者”,它不仅知道这是什么图表,还能把柱状图变成可编辑的SVG代码,把复杂公式转成LaTeX格式。
打个比方:传统OCR是”抄写员”,MOCR是”翻译官”。
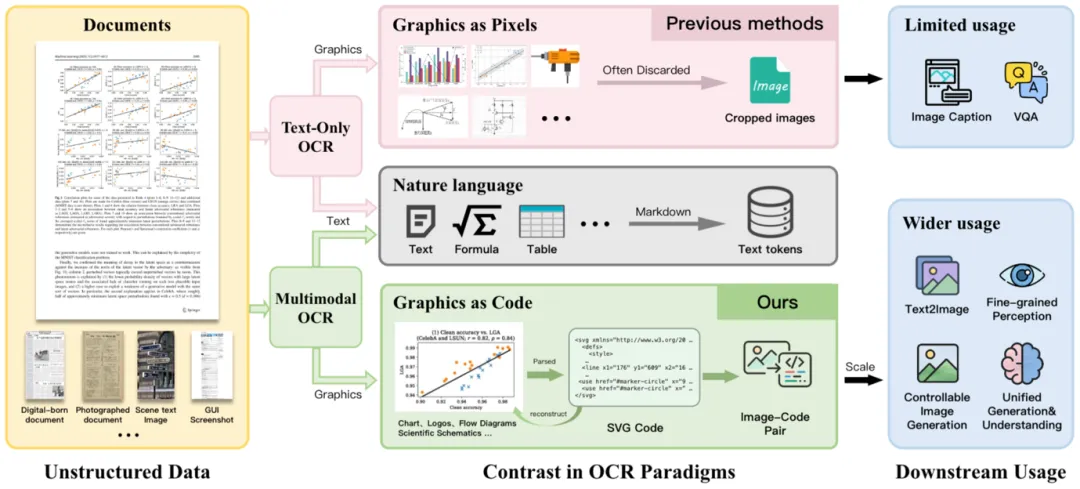
二、MOCR的核心能力:3大突破点
1. 文档全要素解析:一网打尽
MOCR能识别文档页面上的所有元素:
-
文字:标题、正文、注释 -
表格:复杂多级表头、合并单元格 -
公式:数学公式、化学分子式 -
图表:柱状图、折线图、饼图、散点图 -
流程图:UML图、思维导图、架构图
更厉害的是,它能按照人类的阅读顺序,把这些元素提取出来,生成结构化的JSON数据和Markdown文本。
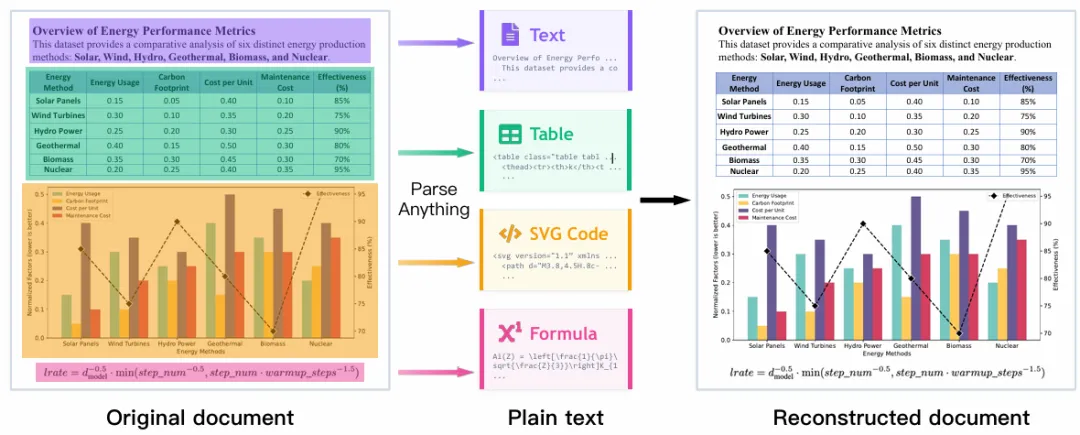
2. 图形转SVG代码:从图片到可编辑
这是MOCR最惊艳的能力。它能把统计图表、科学插图、UI布局等视觉内容,重建为可编辑的SVG代码。
为什么这么重要?
-
SVG是矢量格式,无损缩放,打印不模糊 -
SVG代码可以二次编辑,改颜色、改数据、改布局 -
SVG可以直接嵌入网页、PPT、文档中
举个例子:你在PDF中看到一个精美的数据图表,以前只能截图,现在用MOCR一转,得到的SVG可以直接在Illustrator里编辑,甚至改数据重新生成图表。
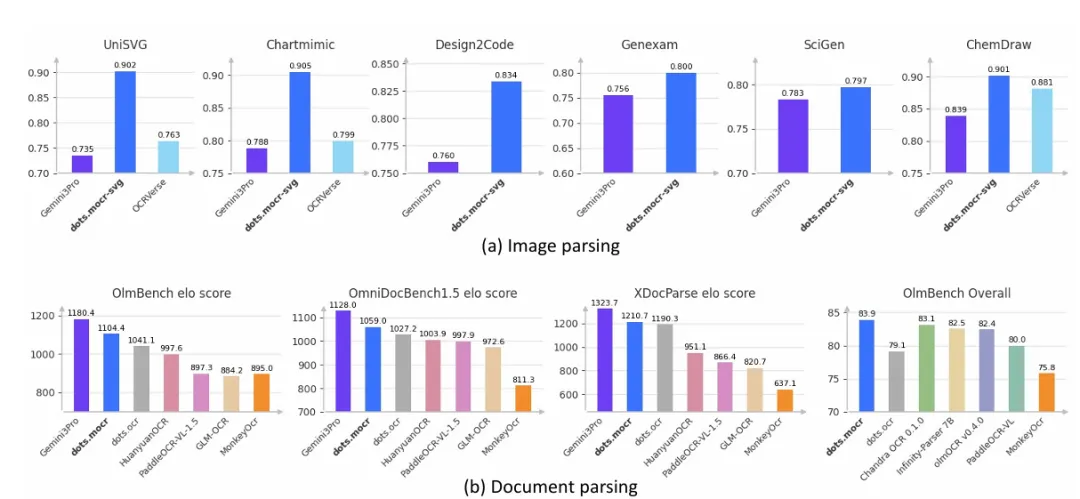
3. 小参数大性能:3B打翻众大模型
MOCR只有3B参数(1.2B视觉编码器 + 1.5B语言解码器),但性能却超越了众多大模型:
-
文档解析Elo得分:1125分(开源模型第一) -
图形重建能力:超越Gemini 3 Pro -
olmOCR-Bench得分:83.9分
要知道,Gemini 3 Pro的参数量远大于3B,而且是谷歌闭源的黑盒模型。MOCR能做到这一点,靠的不是”堆料”,而是独特的架构设计和数据策略。
三、MOCR的技术创新:为什么能做到?
1. 架构创新:双版本策略
MOCR提供了两个版本,满足不同场景需求:
-
dots.mocr(均衡版):综合性能最优,适合通用文档解析 -
dots.mocr-svg(SVG增强版):专门优化图形重建能力,适合需要SVG输出的场景
这种”一专多能”的设计思路,避免了”一把钥匙开所有锁”的尴尬。
2. 数据引擎创新:解决监督信号稀缺
模型好不好,关键在数据。MOCR构建了一个多源数据管道:
-
PDF文档(论文、报告、书籍) -
网页截图(包含丰富图表) -
SVG资产(高质量的矢量图形库)
通过这些数据,MOCR学会了从像素到结构再到代码的完整映射关系。
3. 评估方法革新:OCR Arena框架
传统的OCR评估方法不够客观,MOCR提出了OCR Arena框架,用强大的VLM(视觉语言模型)作为裁判,进行公平、可靠的对比评估。这种方法比单纯看准确率更有参考价值。
四、同类竞品对比:MOCR的优势在哪里?
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
MOCR的核心优势:
-
小参数大能力:3B参数达到百亿级模型的性能 -
完全开源:代码、模型权重全部开源,可本地部署 -
图形可编辑化:这是其他竞品没有的核心创新
五、实战应用:MOCR能做什么?
场景1:学术科研——论文数据提取
科研人员经常需要从PDF论文中提取图表数据,复现前人实验结果。以前只能手动测量,现在MOCR可以直接将图表转为可编辑SVG,甚至提取数据生成Excel。
痛点:扫描论文中的图表无法编辑解决:MOCR解析为SVG代码 + 结构化数据
场景2:金融财经——财报数据数字化
分析师需要从上市公司财报PDF中提取大量表格和图表,转换为Excel进行分析。MOCR可以批量处理,效率提升10倍以上。
痛点:财报PDF中的柱状图、折线图无法转为数据解决:MOCR识别图表类型并生成对应的数据结构
[IMAGE: 插图:展示MOCR在金融场景中的应用,左侧是财报PDF,右侧是提取的数据表格]
场景3:法律政务——合同数字化
律师需要从多页合同中提取关键信息,如金额、日期、条款等。MOCR不仅能提取文字,还能理解表格结构,保持格式完整性。
痛点:合同扫描件中的表格结构易丢失解决:MOCR识别表格层级并保持原始结构
场景4:教育出版——教材电子化
出版商需要将纸质教材数字化,其中的复杂公式和传统OCR难以处理。MOCR可以完美处理数学公式、化学分子式,转为LaTeX格式。
痛点:数学公式、化学式识别困难解决:MOCR将公式转为LaTeX代码,可直接编辑
场景5:医疗健康——病历分析
医生需要从病历中提取检验报告数据,识别医学影像中的标注信息。MOCR能处理包含化学分子式和医学示意图的复杂文档。
痛点:医学报告中的分子式和图表无法结构化解决:MOCR识别专业符号并输出可编辑格式
六、实用建议:用好MOCR的2个关键技巧
建议1:选择合适版本,提升效果
MOCR有两个版本,不同场景用不同版本:
-
通用文档解析:用dots.mocr(均衡版),综合性能最优 -
需要SVG输出:用dots.mocr-svg(SVG增强版),图形质量更好
为什么重要?:SVG增强版专门针对图形重建进行了优化,如果你需要高质量的SVG代码,一定要用这个版本。
建议2:预处理图片,提升识别率
虽然MOCR支持多种输入格式,但预处理能显著提升效果:
-
分辨率:建议300DPI以上,保证图表清晰度 -
对比度:调整对比度,让文字和图表边界更清晰 -
去噪:去除扫描件的噪点和背景杂色 -
旋转校正:保证图片是水平的,避免倾斜
工具推荐:OpenCV、PIL等图像处理库都能完成这些操作。
七、总结:MOCR的意义与局限
核心价值
MOCR的出现,标志着文档AI进入了一个新阶段:
-
从识别到理解:不仅是OCR,更是文档理解 -
从图片到代码:视觉元素转为可编辑代码 -
从大模型到高效能:小参数也能有大能力
局限性
当然,MOCR也有其局限性:
-
GPU依赖:需要支持CUDA的NVIDIA显卡 -
高分辨率文档:大分辨率图片需要更大显存 -
部署门槛:对非技术人员来说,部署有一定难度
展望
MOCR的开源,为整个行业提供了一个高质量的基准。我们可以期待:
-
更多基于MOCR的应用出现 -
文档理解能力进一步提升 -
更多开源模型挑战Gemini 3 Pro
结尾
MOCR告诉我们一个道理:模型的大小不是唯一的衡量标准,创新的设计和高质量的数据同样重要。
如果你正在处理大量PDF文档,或者需要从图表中提取数据,不妨试试MOCR。也许你会发现,文档解析的世界,已经悄悄变了样。
互动时间:
你遇到过哪些PDF文档处理的痛点?MOCR能解决你的问题吗?欢迎在评论区留言讨论!
喜欢这篇文章的话,点个”在看”,分享给更多需要的人吧!