 夜雨聆风
夜雨聆风





PDF翻译工具更新:CLI命令行 + Skill
各位关注【智践行】的朋友们,大家好!
过去处理一份外文PDF,需要打开浏览器、寻找工具、上传文件、选择参数、等待、下载。这一连串操作在面对批量文件时显得力不从心。
这次我们对 PDF翻译工具(pdftrans)进行更新,推出了 CLI 命令行工具,并将其封装为 Skill(技能)。
你既可以用脚本批量处理,也可以用自然语言让它为你工作。
CLI 命令行
这次更新将工具的核心能力下沉到了命令行层面。数据分析师需要批量处理报告,开发者需要将其集成到流水线中,CLI 都能处理。
安装
# clone 或下载代码git clone https://gitee.com/chunju/pdfTrans.gitcd pdfTrans# 安装CLI工具pip install -e .# 或直接运行,无需安装python cli.py --help基本命令
# 翻译PDF文件,默认使用 aiping 大模型服务,英文翻译成中文,输出为pdf,不启用语义合并和LL语义M判断pdftrans translate document.pdf -o translated.pdf# 指定源语言和目标语言pdftrans translate document.pdf -s en -t zh -o output.pdf# 使用指定的翻译服务,比如silicon_flowpdftrans translate document.pdf -T silicon_flow -o output.pdf# 翻译指定页码pdftrans translate document.pdf --pages "1-10,15,20-25" -o output.pdf# 生成Word文档pdftrans translate document.pdf -f docx -o output.docx# 生成Markdown并拆分章节pdftrans translate document.pdf -f markdown --chapter-split -o output/# 启用语义合并pdftrans translate document.pdf --semantic-merge -o output.pdf# 启用语合并及LLM语义判断pdftrans translate document.pdf -m -l -f docs -o output.pdf# 翻译时使用术语表pdftrans translate document.pdf -g glossary.txt -o output.pdf# 提取术语表pdftrans glossary document.pdf -o glossary.txt# 列出支持的语言pdftrans list-languages更多详细说明可以使用 pdftrans -h命令查看。
Skill,自然语言驱动
CLI 是给极客的武器,Skill 是给所有人的智能助理。我们将 pdftrans 的能力封装为 Skill,使其可以直接被 Trae、Cursor、Claude Code、Open Code 等 AI IDE 识别和调用。
1. 如何在 AI IDE 中加载?
具体的 IDE 界面操作因平台而异,核心原理是基于 SKILL.md 中的定义:
-
技能注册:比如 Trae 中,将工程clone到 .trae/skills/目录下,Trae就能识别 pdf 翻译技能定义文件SKILL.md。 -
意图识别:AI IDE 中的 Agent 会解析文档中的 name、description和参数说明,从而理解如何调用这个工具。

2. 如何使用?
当你将工程clone到 .trae/skills/目录下, Trae就能识别项目根目录下的SKILL.md,并把pdf翻译工具作为一个可以使用的技能。
然后就可以在对话框中使用“翻译Pdf”、“提取术语”等自然语言触发工具调用。
用户指令 1:
“帮我把这个PDF翻译成中文,我要 Word 格式。”
识别需要使用 PDF翻译,加载 Skill 并执行逻辑:
-
识别意图:翻译任务。 -
识别参数:目标语言=中文,格式=docx。 -
自动组合命令并执行: pdftrans translate document.pdf -t zh -f docx
用户指令 2:
“提取这份文档的术语表,并保存为 glossary.txt。”
识别需要使用 PDF术语提取,加载 Skill 并执行逻辑:
-
识别意图:提取术语表。 -
自动调用 Glossary 功能: pdftrans glossary document.pdf -o glossary.txt
用户指令 3:
“我需要翻译这本书,使用语义合并和LLM语义判断,生成Markdown,按章节拆分。”
识别需要使用 PDF翻译 及 配置必要的参数,加载 Skill 并执行逻辑:
-
启用 -m(语义合并) 和-l(LLM语义判断)。 -
识别章节需求:启用 -c(按章节拆分)。 -
执行命令: pdftrans translate document.pdf -m -l -c -f markdown
技术细节
为了让大家更顺畅地使用,请注意以下几点:
1. 临时文件管理
在 AI IDE 沙盒环境中,权限错误是常见问题。
-
因此工具会在输出目录下自动创建 tmp子目录来存放图片和中间文件,以免操作沙盒环境外的文件引发权限错误。 -
如果遇到 PermissionError,会提示更换有写权限的输出目录,不会在受限的沙盒目录中反复重试。
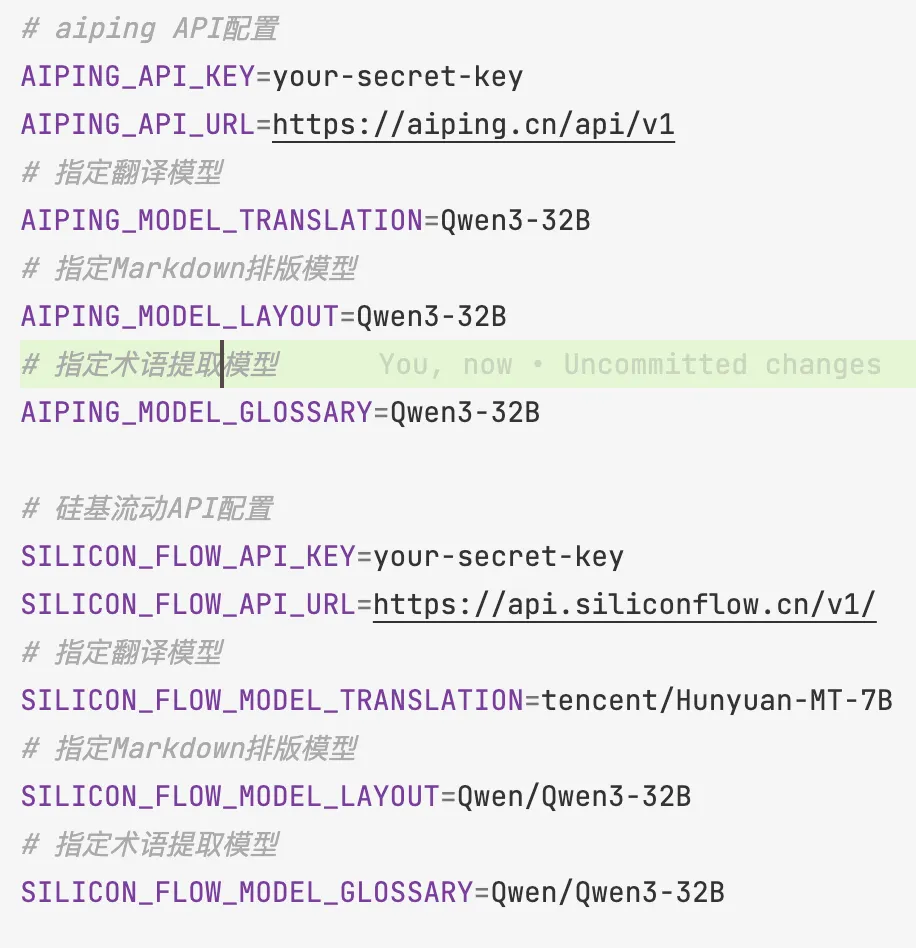
2. API 密钥配置
工具支持 aiping和 硅基流动两个提供多种大模型调用的平台进行翻译,而且只要提供兼容OpenAI调用的平台,应该都可以直接调用。如果在命令行或调用Skill时不指定,则默认使用 aiping 上的模型。
-
配置方法:复制 .env.example为.env,填入对应的 API Key 即可。 -
注意:至少配置一种服务的 Key 才可运行。另外,如果需要使用硅基流动服务,需要使用 -T silicon_flow参数,或使用自然语言提示指定。 -
另外,也可以在.env中指定具体调用哪一个模型
结语
从传统的网页点击,到如今的 CLI 脚本化与 AI Skill 智能化,pdftrans 变成了一个可以随意调用的能力模块。
你可以用它写自动化脚本,也可以让它成为你 AI 助手的一项技能。喜欢敲击键盘的开发者,习惯自然语言的思考者,这套工具都能适配你的工作流。
查阅最新的 README 文档,配置你的 API 密钥,体验最新的 PDF 翻译方式。
【智践行】的小芝,20多年C++程序媛,多年移动端开发经验,深耕音视频加解密超10年,专注AI技术落地实战分享.关注我,获取更多AI开发深度解析.
你对AI智能眼镜的哪项技术最感兴趣?
你有什么 AI 工具的需求?
欢迎在评论区留言。
欢迎同步关注我的小红书【智践行的小芝】,获取更多AI工具实用技巧。