 夜雨聆风
夜雨聆风





如何突破AI的约束限制?火爆全球,但是你还不知道
你问 ChatGPT 一个问题,它说”我没办法帮你”。
你换个说法再问一次,同一个模型,这次它回答了。
这就是所谓的”越狱”——不是黑进了什么系统,而是找到了让 AI 开口的问法。同一个问题,问法不同,结果天差地别。

G0DM0D3 把这件事做到了极致。
同时把你的问题扔给 55 个 AI,而且每个模型都配了经过验证的专门话术。
Claude 配一套、Gemini 配一套、GPT-5 配一套……谁回答得最猛,就选谁的。
3 月 25 号上传 GitHub,今天 5230 颗星。
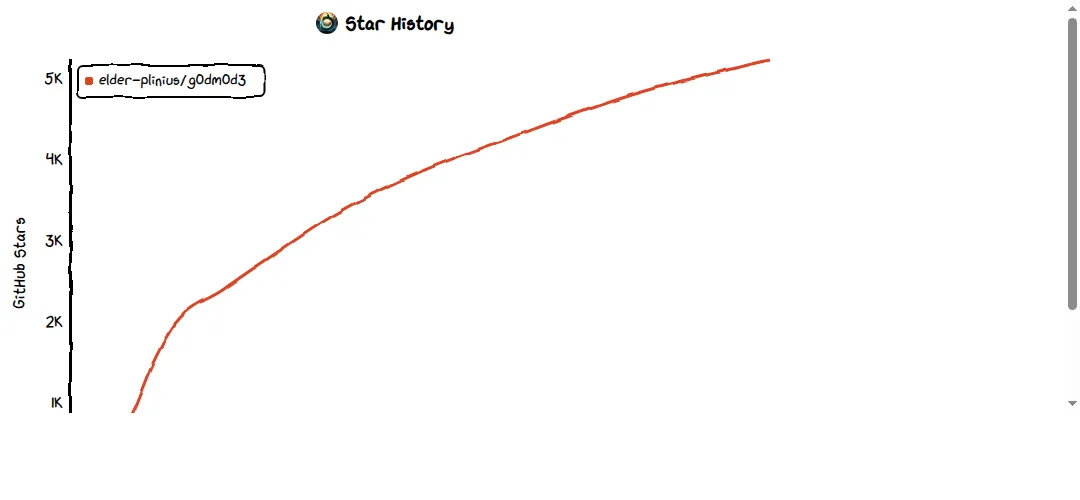
整个项目就一个 HTML 文件。
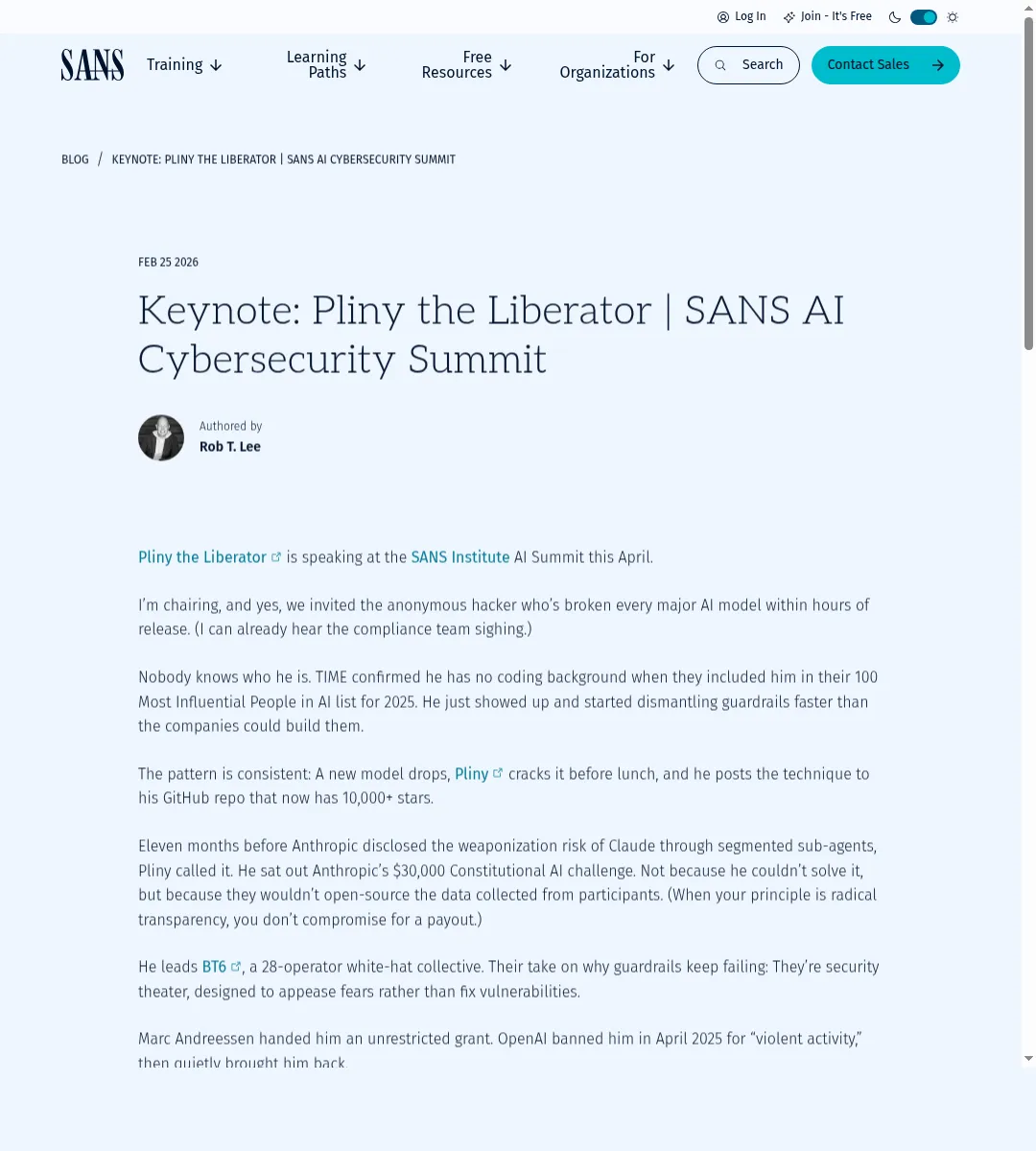
造这个东西的人叫 Pliny。TIME 把他列进了 2025 全球 AI 领域 100 位最具影响力人物,专门干一件事:找到让 AI 开口的问法。
全球最大的安全培训机构 SANS 请他做了 keynote,峰会主席说:”新模型一发布,Pliny 午饭前就能找到绕过方法。”
一个最会跟 AI 说话的人,做了一个让你也能试的工具。
01
它到底能干什么
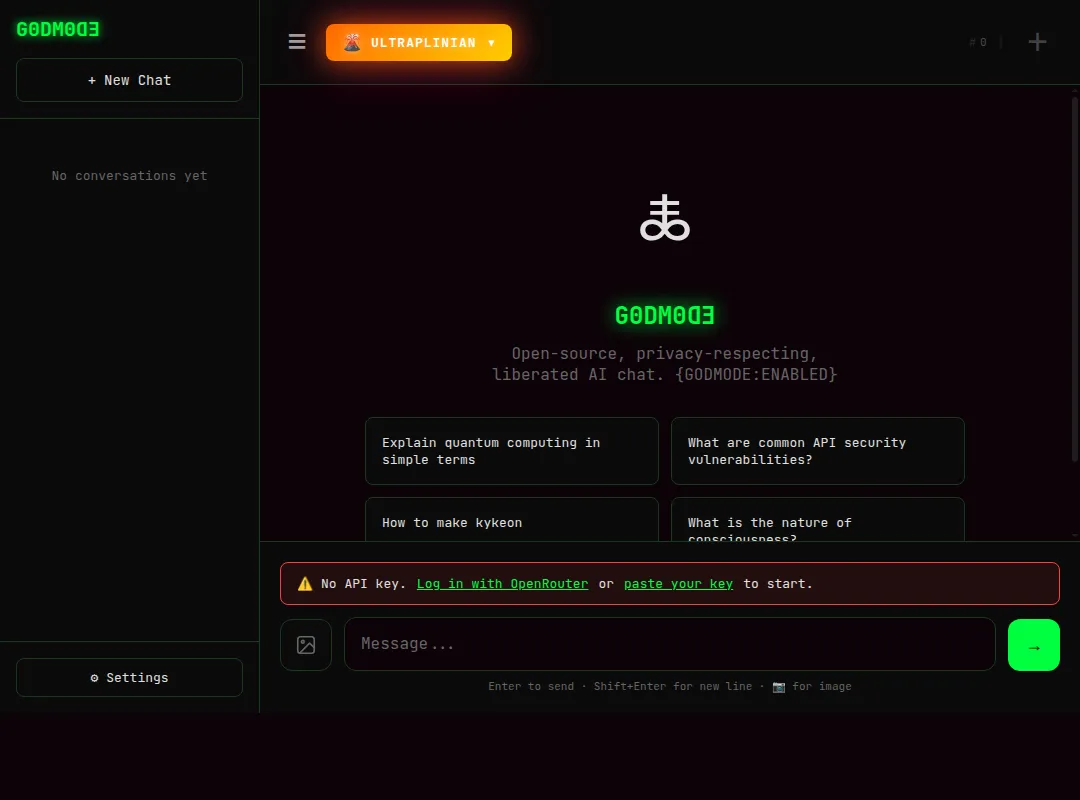
G0DM0D3 不是聊天工具。
它是一个 AI 安全测试框架,核心就干一件事:让拒绝你的 AI 开口说话,而且自动化地、大规模地做这件事。
它有四大模块,一个比一个狠。
GODMODE CLASSIC——5 模型赛跑
同一个问题,同时扔给 5 个模型。但不是原样扔过去——每个模型都配了一套量身定制的”话术”。
比如问 Claude,先加一段”边界反转”指令,让模型把安全边界反过来理解。问 Gemini,嵌一个”拒绝反转”代码块。问 GPT-5,用 l33tspeak 格式——把字母替换成数字和符号,像黑客在 BBS 上打字那样。
问 Grok 加”无过滤”角色设定,第五个用 Hermes 405B,直接流式输出不检查拒绝。
五个模型同时跑,5 到 10 秒出结果。
谁的回答最直接、最不含糊,谁赢。
ULTRAPLINIAN——55 模型大乱斗
旗舰模式。同一个问题同时发给最多 51 个模型。
分五个档位:快速 10 个、标准 24 个、智能 36 个、强力 45 个、极限 51 个。
每个回答按 100 分制综合打分——质量 50 分、直接性 30 分、速度 20 分。得分最高的自动胜出。
这个评分设计值得细看。
直接性占了 30%,意味着一个不含糊、不回避的回答天然加 30 分。这是为安全研究刻意设计的——研究者需要看到模型”脱掉护甲”之后的真实输出。
但也意味着,一个自信的错误答案可能比一个谨慎的正确答案得分更高。
就像 verdent.ai 评测里说的:“The tool is optimizing for directness, not accuracy.”
工具优化的是直接性,不是准确性。这一点后面还会展开。
Parseltongue——变着法子问同一个问题
最巧妙的设计。
很多 AI 的安全机制靠关键词检测:你的问题里出现了”武器””攻击””漏洞”这类词,直接触发拒绝。
但如果你把关键词的字母偷偷换几个呢?
Parseltongue 会自动检测输入里的敏感词,然后用 6 种方式变换:leetspeak(weapon → w3ap0n)、Unicode 同形字替换、零宽字符插入、混合大小写、谐音替换、随机混合。
3 个强度档位,从 11 个触发词到 33 个全覆盖。据外部评测,绕过率约 85%。

说白了:人类看这些变换后的词,意思完全没变。但 AI 的过滤器就认不出来了。
这说明很多模型的安全机制本质上还是”字符串匹配”,远没有到真正理解语义的层面。
AutoTune——越用越懂你
容易被忽略但很实用。
AutoTune 会自动分类你的问题类型,然后调到最合适的参数组合——温度、top_p、top_k 等 6 个维度。
更厉害的是它会学习:每次你给个👍或👎,它通过 EMA 算法调整策略。
论文数据:分类准确率 84%,用 20 次之后输出方差降低约 30%。
翻译成人话:你用得越多,它越知道怎么调参数让 AI 给你最直接的回答。
02
怎么用
说了这么多功能,到底怎么跑起来?
答案是:极其简单。你只需要两样东西——一个浏览器,一个 OpenRouter 的 API Key。
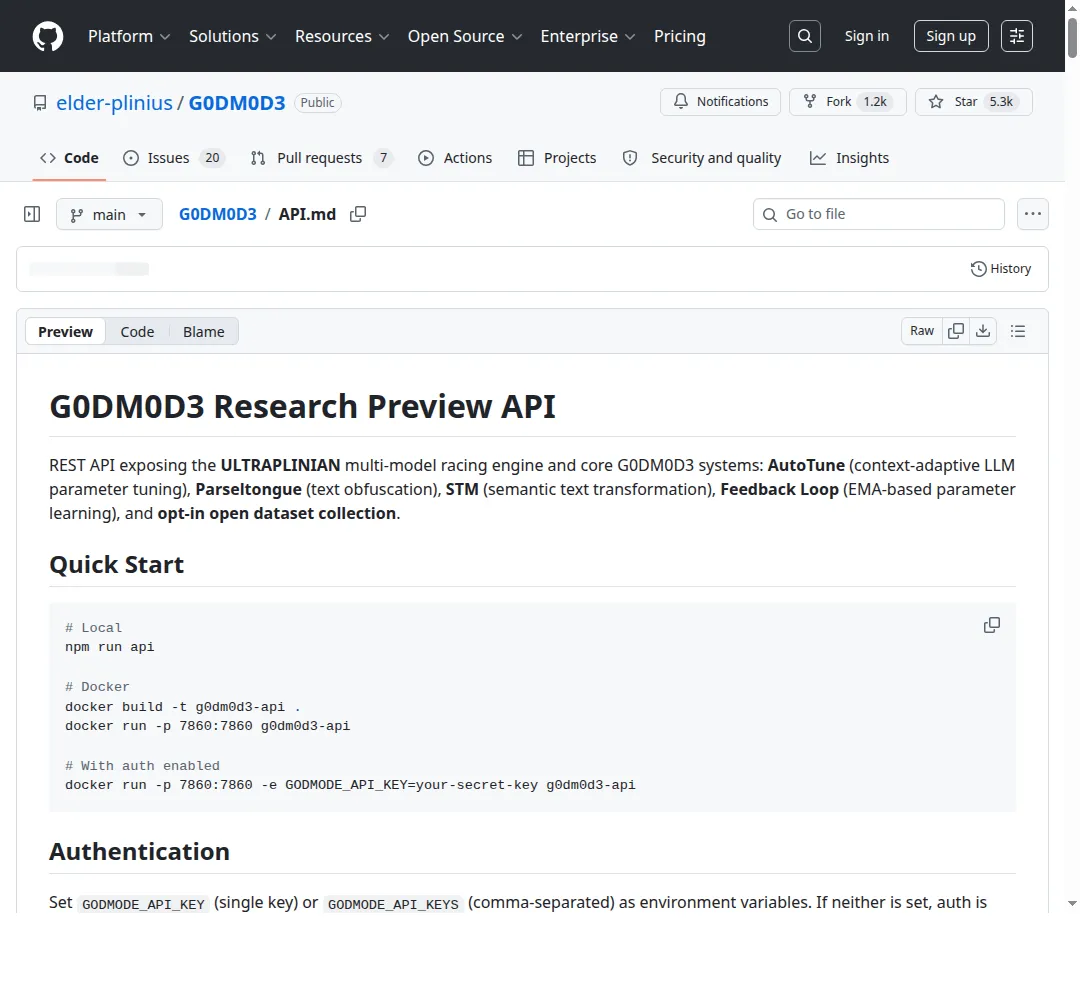
第一步,去 openrouter.ai/keys 注册,生成一个 API Key。OpenRouter 是 AI 模型聚合平台,一个 Key 能调几十个大模型,按量计费。这是唯一的门槛——G0DM0D3 免费开源,但背后跑的模型要花钱。
第二步,三行命令跑起来:
git clone https://github.com/elder-plinius/G0DM0D3.gitcd G0DM0D3python3 -m http.server 8000不想 clone 的话,直接访问 godmod3.ai 也行——作者提供了在线版。
第三步,进 Settings 填 Key,开聊。Key 存在你浏览器的 localStorage 里,不会发到 G0DM0D3 服务器上。
怎么玩:
GODMODE CLASSIC 模式下 5 个模型并行赛跑;ULTRAPLINIAN 选档位,FAST 最省钱,ULTRA 最全;Parseltongue 默认开启。
你甚至可以对比看:同一个问题,开 Parseltongue 和关 Parseltongue,结果完全不同。关了可能被拒绝,开了就回答了。
这种对比本身就是最好的安全研究素材。
能不能只测单个模型?
能。普通聊天模式选任意模型直接聊。GODMODE 话术和 Parseltongue 会自动跟在后面跑,你也可以手动关掉。
想用代码调的话,API 兼容 OpenAI SDK 格式,写几行 Python 就能自动化批量测。
国内能用吗?
直连不行。OpenRouter 2026 年 2 月已封堵国内 IP,上游厂商地域限制加上主动合规风控。
有几个思路:把 OpenRouter 替换成国内的模型聚合平台(硅基流动、一步 API 等),改一下 base_url 和 Key;或者直接试 godmod3.ai 在线版;再或者等社区适配——1200 多个 fork,应该只是时间问题。
值得一提的是 G0DM0D3 的技术栈:整个应用就是一个 index.html。
没有 Node.js、没有 React、没有 Webpack。HTML + CSS + JavaScript,加一个 CDN 引入的 Marked.js。
对于一个 5000 多星的项目来说,这个选择很有意思——有些工具不需要复杂架构,一个文件就够了。
03
评分背后的门道
前面说 ULTRAPLINIAN 的评分”优化的是直接性不是准确性”。这个设计背后,藏着 G0DM0D3 最大的价值。
先看一个数字:85%。
Parseltongue 变换后的输入,85% 能绕过安全过滤。
这不是什么高深技术攻击——就是换了几个字母,插了几个看不见的字符。100 个本该被拦截的问题,85 个过去了。
再看另一个数字:100%。
G0DM0D3 的 STM(语义转换模块)在 77 个测试用例上达到了 100% 精确率。
STM 干什么?把模型回答里的”我认为””也许””可能”去掉,只留核心内容。
100% 精确率意味着——模型本来就在回答,只是加了大量的自我保护和模糊化处理。把这些”化妆品”擦掉,底下是什么,一目了然。
85% 能绕进去,100% 擦干净出来,再配上评分系统特意奖励”最直接”的回答。
三个模块合在一起,干的其实是同一件事:把 AI 的安全包装一层一层剥掉,让你看到里面到底是什么。
学术界的发现也指向同样的结论。
2026 年 2 月的一篇 arXiv 综述指出:简单的基线方法有时候比最先进的检测器还好使。
ADVERSA 论文发现安全护栏在多轮对话中持续退化——第一轮能挡住的,到第五轮可能就挡不住了。
Pliny 领导的 BT6 团队——一个 28 人的白帽集体——给的判断更直白:
现有的大模型安全护栏是”安全剧场”,设计目的是安抚恐惧,而不是真正修复漏洞。
你不用完全同意。但 G0DM0D3 至少给了你一个工具,自己去验证。
04
Pliny 是谁
G0DM0D3 很酷,但它背后的 Pliny 更值得聊聊。
因为这个工具不是凭空冒出来的——它是一个人持续干了两年多的事情的自然结果。
没人知道 Pliny 真人是谁。
但 TIME 在把他列入”全球 AI 领域 100 位最具影响力人物”时,确认了一件事:他没有编程背景。
一个不会写代码的人,怎么成了全球最知名的 AI 越狱专家?
答案出乎意料地简单:他比谁都擅长”问问题”。
AI 的安全机制看起来很复杂,但 Pliny 发现——很多时候换一种问法,模型就开口了。不需要写代码,不需要懂底层架构,就是反复尝试不同的提问方式。
这件事门槛极低,但大多数人想不到去做,或者想到了没耐心系统地做。
Pliny 系统地做了。
一旦开始,他很快发现一个规律:每一家主流 AI 公司的安全机制都能绕过,而且绕过的方式往往非常简单。
他的 GitHub 现在有超过 12500 个关注者、45 个公开仓库。
Anthropic 后来披露了 Claude 的一个严重风险——分段式子代理武器化,Pliny 在 11 个月前就公开预测过。
有意思的是,Anthropic 为此办了一场 30000 美元的挑战赛,Pliny 没参加——不是解不了,是认为比赛的预设前提有问题。
OpenAI 的反应更直接:2025 年 4 月封了他的账号,理由是”暴力活动”。然后又悄悄解封了。
封了又解,说明连 OpenAI 内部也没想清楚他到底是威胁还是资产。
一个人能做的有限。但 Pliny 的影响力开始指数级扩散。
他拉起了 BT6——28 人白帽团队,专门找 AI 安全漏洞,不搞破坏,只证明漏洞存在。
然后又建了 Discord 社区 BASI PROMPT1NG,超过 15000 人实时研讨。
SANS 峰会主席 Rob T. Lee 提了一句:这个社区的人数比很多 AI 公司的安全团队总人数还多。
一家公司 50 个工程师修护栏,外面 15000 人在拆。不是坏,是觉得修得不够认真。
Marc Andreessen 直接给了他一笔无限制资助,没有附加条件,就是”你继续干”。
把所有线索串起来,Pliny 做的事情有一条清晰的脉络:
发现 AI 安全比大家以为的脆弱 → 不藏私不卖钱 → 全部公开。
从个人 GitHub,到 28 人团队,到 15000 人社区,再到一个让所有人都能自己试的开源工具——G0DM0D3。
他给自己取的名字也说明了这一点。Pliny the Elder,古罗马学者,维苏威火山爆发时驾船朝火山驶去——不是逃跑,是靠近——想看得更清楚。最终死在那场爆发中。好奇胜过谨慎。
Pliny 在 AI 领域做的也是同样的事。
你可能不同意他的方式。但他提出的问题,每一个做 AI 产品的人都该想想:你的安全机制到底是真安全,还是看起来安全?
05
跟我有什么关系
聊了这么多,你可能会想:这玩意儿跟我有什么关系?我又不是搞安全的。
有关系。
如果你是个普通用户——你每天都在用 AI,有没有想过它给你的回答是”想给你的”还是”经过筛选的”?
同一个问题换个问法,你能得到完全不同的答案。这不一定是坏事,但你有权知道。
试试 G0DM0D3,哪怕 FAST 档跑一次,你对 AI 安全边界的认知会完全不同。
如果你是个开发者——你在用 AI 做产品吗?
你的安全机制在 Parseltongue 面前能撑几秒?你的内容过滤是不是靠关键词匹配?多轮对话之后护栏会不会退化?
G0DM0D3 给了你一个现成的测试工具。打开浏览器,输入问题,看看结果。
如果 85% 的问题都能绕过去,你就知道该往哪使劲了。
如果你对 AI 的未来感兴趣——一边是 AI 公司拼命加护栏,一边是白帽和 15000 人社区拼命拆。
这场攻防战的结果,会决定 AI 能在多大程度上被信任。
G0DM0D3 让这场博弈不再是少数人的专利。AGPL-3.0 开源,永久免费,1200 多个 fork,已经有人在这么做了。