 夜雨聆风
夜雨聆风





AI课堂融合实例——中药识别(图片模型训练)

承接昨天。
第一篇我们用 Coze 跑通了工作流,学生上传一张药材图,得到的是文字输出——这是当归,性状是……
文字能解决问题,但有个问题:作品看不见。
我们一直在想,什么样的交付形式,既能让学生看得见自己的成果,又不需要非 AI 专业的老师去学代码?
后来想到了 Coze 的画板能力——识别出是什么药材就行,后面用画报制作出来的是知识卡片、药膳推荐、还是拟人化海报,都可以根据课堂情况由老师安排任务。
但要做这样的卡片,有个前提:识别要够准。
通用大模型的准确率天花板就在那里。相似药材、图片质量、地域性药材,这三座山绕不过去。
所以我们引入了第二层:用百度 EasyDL 训练专属模型。
这一篇的目标是给下一篇打地基——把识别准确率拉上去。

一、从文字输出到 H5 返回成功率
第一篇的方案是提示词驱动的——模型本身的能力没变,我们只是教它怎么用自己已有的能力。
今天要讲的方案是数据驱动的——用真实训练数据,让模型学会认它以前不认识的东西。
这就是为什么引入了百度 EasyDL。
EasyDL 是百度的零代码 AI 开发工具,主打不需要写代码,只用图片就能训练 AI。对高校实训场景特别友好——学生把照片喂进去,告诉它这是当归、这是黄芪,它就能学会。
训练完成后,EasyDL 会生成一个 H5 页面。学生扫码上传图片,得到的不再是简单的一行文字,而是识别结果加上置信度——也就是成功率。
这个成功率,就是下一篇做知识卡片的前提。识别不够准,卡片做得再漂亮也没用。
二、训一个模型,到底要做什么
整个过程可以拆成五步,每一步学生都要亲手做:
第一步:拍照片。
听起来简单,但这是整个项目最脏、最累、也最关键的一步。
我们给学生定了四大采集标准:
- 1.背景:必须用纯色(首选白色)的背景板,不能有杂物干扰
- 2.清晰度:手机距离药材 10-15 厘米对焦拍摄,纹理要清楚
- 3光线:光线均匀柔和,避免强反光和浓重阴影
- 4.多样性:同一味药要拍不同角度(整体、局部)、不同形态(整株、切片)
数量要求是:每组至少 10 种药材,每种至少 50 张照片——500+ 张是底线。下图就是专业药材图片与网图的区别,显著影响模型训练特征提取,进而影响模型识别成功率。


第二步:传上去。
图片拍完,批量上传到 EasyDL 平台。单个图片不能超过 14M,长宽比控制在 3:1 以内。
第三步:标注。
这是最容易出错的一步。
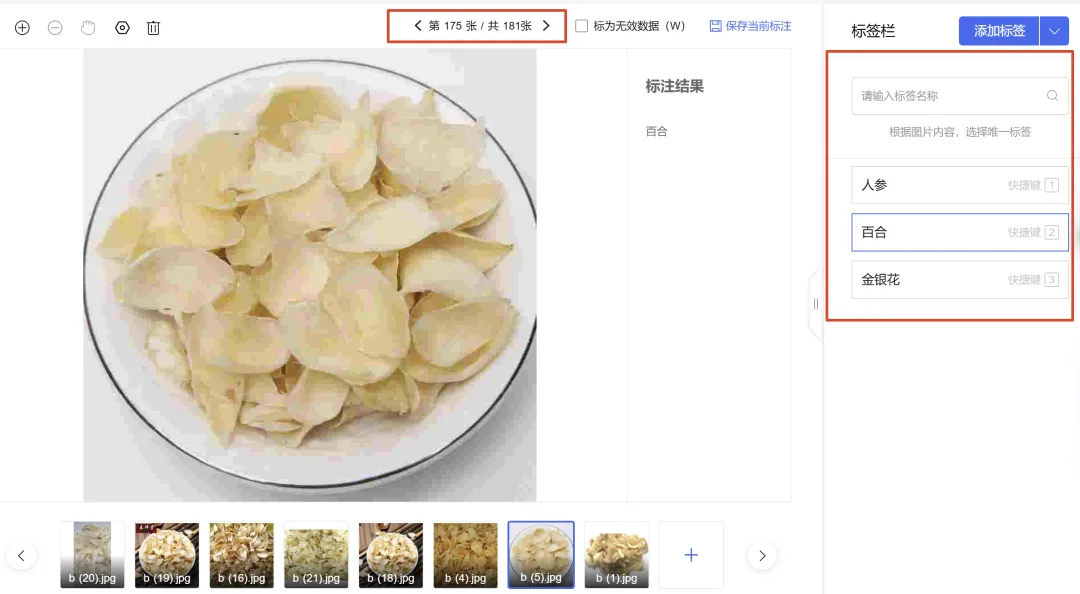
每张图片上传后都是”未标注”状态,学生需要手动给每一张图打标签——这张是当归,那张是黄芪,这张是党参……
500+ 张图,一张一张标,标错一张模型就学错一个。
所以我们设计了一个”交叉质检”环节:小组内成员交换检查对方标注的类别,发现标错立刻纠正。
第四步:等它练。
所有图片标注完成后,点击”开始训练”。
选择”高精度”算法,GPU P4 环境,然后……等待模型的训练完成
等待的过程中,我们给学生讲模型训练的原理——它在做什么?它在找特征。当归的纹理是什么样的?黄芪的根头部有什么特点?这些特征不是人描述给它听的,是它从 500 张真实照片里自己”看”出来的。
在这一步主要是跟着课件点点点就好了,具体的实现细节都不讲,本身课程的强度就不算低~所以在微课环节,我们设置了相当多的带练和一些关键术语的解释,旨在5分钟一节的微课内,用动画、数字人和字幕的方式讲清楚一个概念。
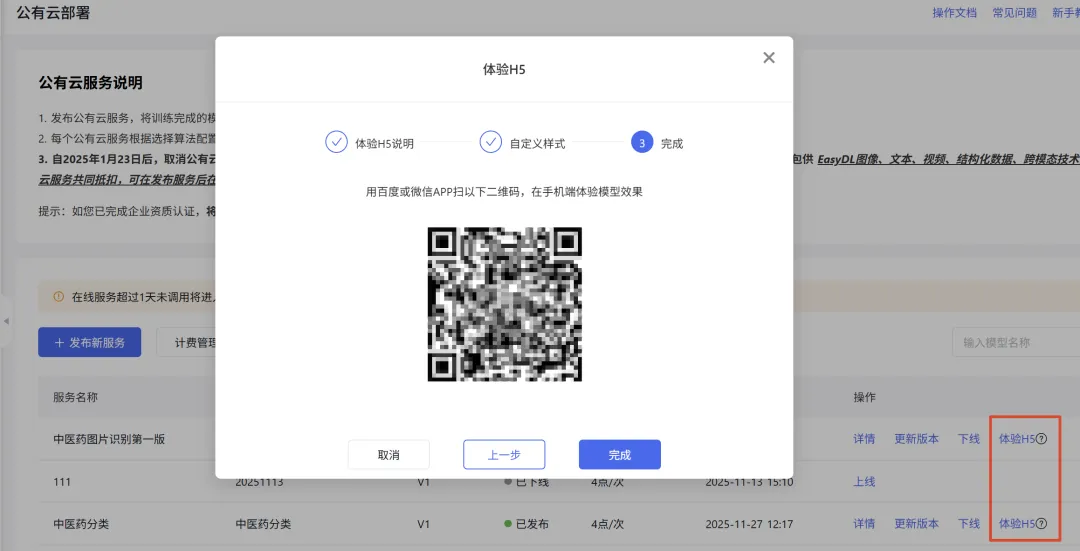
第五步:测准确率。
模型训练完成后,EasyDL 会生成一个 H5 页面。学生用微信扫码就能体验——上传一张药材照片,模型告诉你是什么,以及它有多确定(置信度)。
我们要求学生用自己准备的测试图片(每种至少 5-10 张)去跑一遍,记录每次测试的结果,算出准确率。
三、EasyDL vs Coze,同台竞技
第六课时,我们让学生做了一件特别有意思的事——让 EasyDL 训练的模型,和第一阶段用 Coze 搭的智能体,用同一批”考题”来测试。
规则很简单:
-
测试图片必须是训练时用过的药材种类
-
每种药材至少测 3-5 张,总数 15-20 张
-
同一张图片,既要跑 EasyDL 的 H5,也要跑 Coze 智能体
-
记录两种方式的识别结果和置信度
然后对比准确率。
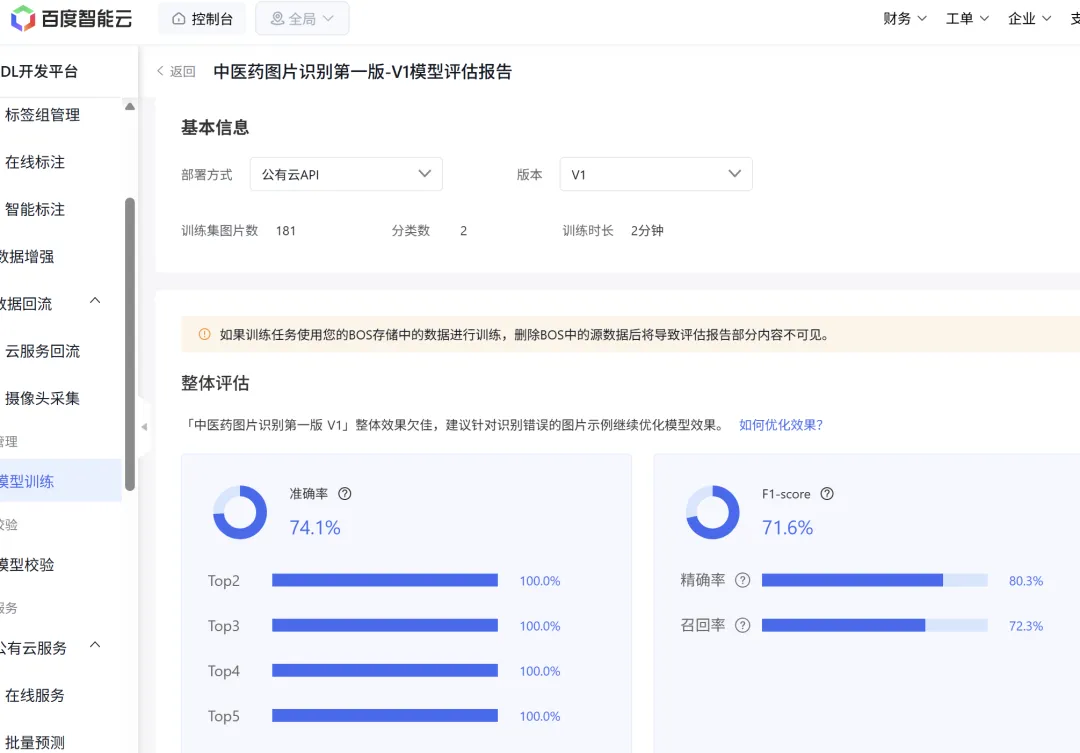
结果很直观:在训练过的药材种类上,EasyDL 更占优势。
原因也很简单——EasyDL 的模型是”吃过这碗饭的”,那 500 张真实照片就是它的”教材”。而 Coze 里的通用大模型,虽然提示词写得再好,终究没见过你家学校那些具体的药材长什么样。
四、这件事的真正价值
表面上看,学生学会的是用 EasyDL 训练一个图像分类模型。
其实真正沉淀下来的,是三样东西:
第一,学生第一次理解了数据是 AI 的基石。
不是理论上的理解,是亲手拍了 500 张照片、标了 500 张图之后的切身体会。数据质量差一点会怎样?标注错一张会怎样?数据量少一点会怎样?这些问题的答案,他们不用背,因为亲眼见过。
第二,老师拿到了一套可复用的教研素材。
学生训练的模型、拍摄的照片、标注的数据,全都在 EasyDL 平台上存着。下学期上课,老师可以直接拿这些数据当案例,或者让新一批学生在现有数据基础上继续扩充。
第三,学校沉淀了自己的数据资产和私有模型。
通用大模型是谁都能用的,但谁都无法控制。而学校用自己的真实数据训练出来的模型,是私域的、专属的、可控的。时间越久,数据积累越多,模型就越准。
这是一件可以持续迭代的事。
五、原始数据的坑,我们是怎么填的
这件事一开始,我们遇到的最大问题是:数据从哪来?
专业的药材照片太不好弄了。老师手里的就那么几张,远不够训练。
我们试过用网上的公开数据集,也爬过拼多多、淘宝的网店图——效果惨不忍睹。
你想想,网店图是什么样的:背景杂乱、光线怪异、角度刁钻、还有水印叠水印。模型学到的不是当归长什么样,而是网店图长什么样。
后来我们拜托老师,想尽办法搞到了一批专业的药材图片库,这才真正能跑起来。
这件事也让我们理解了一个更大的趋势:现在大模型公司都在拼命构建高质量数据集。为什么?因为高质量的人类公开数据越来越稀缺,接下来拼的就是谁能搞到更干净、更专业、更高质量的数据。
学生的那 500 张标注,虽然是小规模练习,但让他们亲手体会了:数据质量决定模型上限。
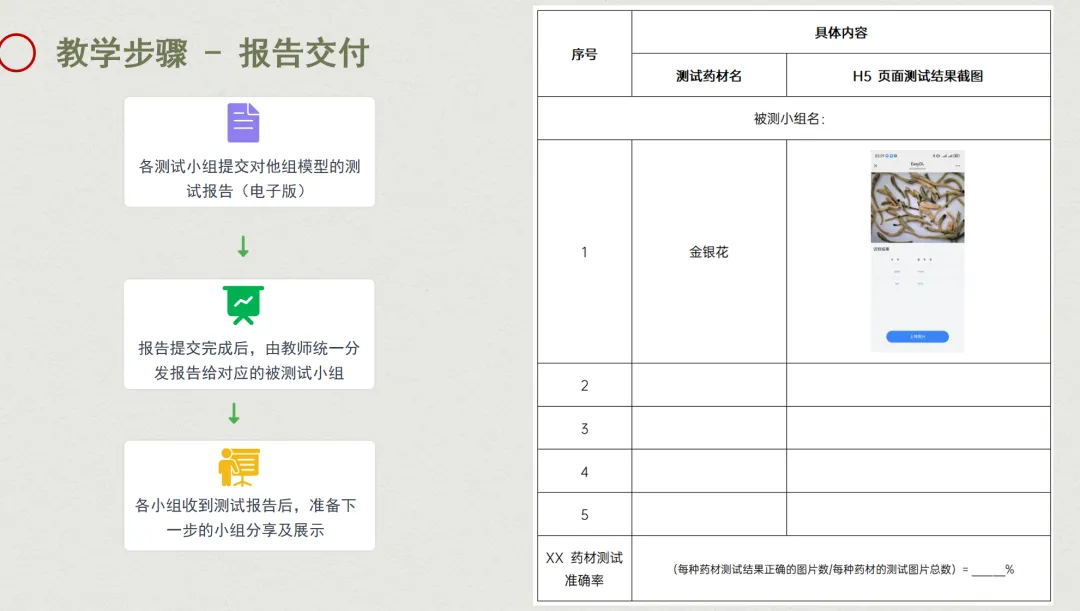
六、这个模块交付的是什么
整个模块 8 课时,从数据采集到模型测试,学生亲手跑通了全流程。
那我们交付的是三件事:
- 1.学生理解了数据驱动和提示词驱动的本质区别
- 提示词驱动是让已有的模型听懂你的话
- 数据驱动是用真实数据训练一个自己的模型
- 2.学生在对比测试中直观感受到了差异
- EasyDL 训练的模型在特定种类上准确率更高
- Coze 的通用大模型泛化能力更强,但天花板低
- 没有绝对的优劣,只有场景的适配
- 3.为下一篇打下了地基

- 专属模型训练好了,H5 页面生成了
- 下一步就是用 Coze 工作流把它接回来
- 不再是简单的文字输出,而是结构化的知识卡片
这才是完整的 AI 课堂设计 ~
七、AI时代的师生共学模式
做 AI 化课堂,目的从来不是取代老师。
是师生共学——老师引导学生思考、完成项目,从中掌握 AI 的用法。不能为了学 AI 而学 AI,要服务于精心的教学设计。
下一篇,我们会把课堂交还给老师——识别完成后,是知识卡片、药膳推荐、还是拟人化海报,那是老师最擅长的课堂设计。
整个系列三篇的脉络是:
-
第一篇:通用大模型加 Coze 工作流,输出文字
-
第二篇:用 EasyDL 训练专属图像模型,输出 H5 预测结果
-
第三篇:把两者串起来,用 Coze 的画板能力,做出完整的学生作品
上传自己的药材,用自己的模型识别,生成自己做好的知识卡片——那才是学生最终交得出去的东西。
我是刘旭,我们明天见。