 夜雨聆风
夜雨聆风





函数版的数据透视表:WPS表格PIVOTBY函数参数详解
WPS表格PIVOTBY函数参数详解
——从入门到精通,11个参数逐一拆解
PIVOTBY是WPS表格最新推出的动态透视函数,被誉为“函数版的数据透视表”。它能够根据指定的行字段和列字段,对数据进行分组、聚合、排序与筛选,生成二维交叉报表。相比传统数据透视表,PIVOTBY最大的优势在于结果可以随源数据自动更新,无需手动刷新。
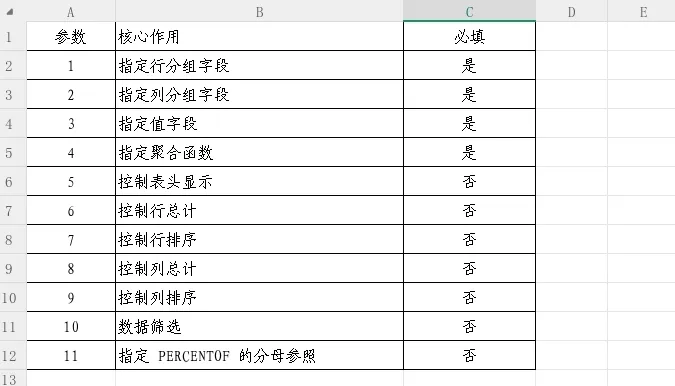
PIVOTBY函数共有11个参数,其中前4个为必填参数,后7个为可选参数。下面我们通过一个贯穿全文的示例数据,逐一拆解每个参数的作用。
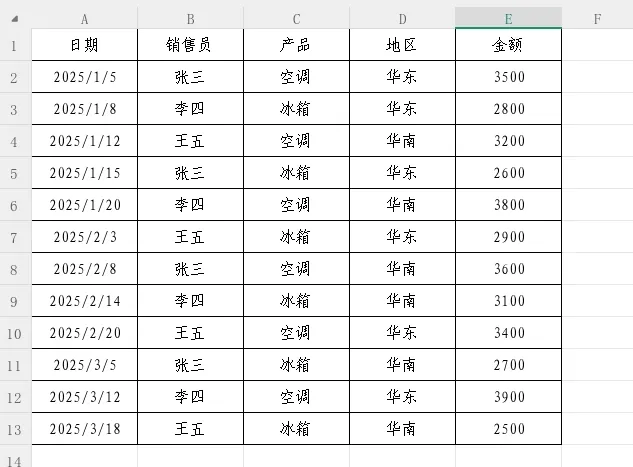
参数总览,在逐一详解之前,先看PIVOTBY的完整语法:
=PIVOTBY(行字段,列字段,值,函数,[标头],[行总计深度],[行排序顺序],[列总计深度],[列排序顺序],[筛选数组],[相对关系])
参数1:行字段,作用:指定在结果中按行方向分组的字段,对应数据透视表的“行标签”区域。
示例:按销售员统计销售额
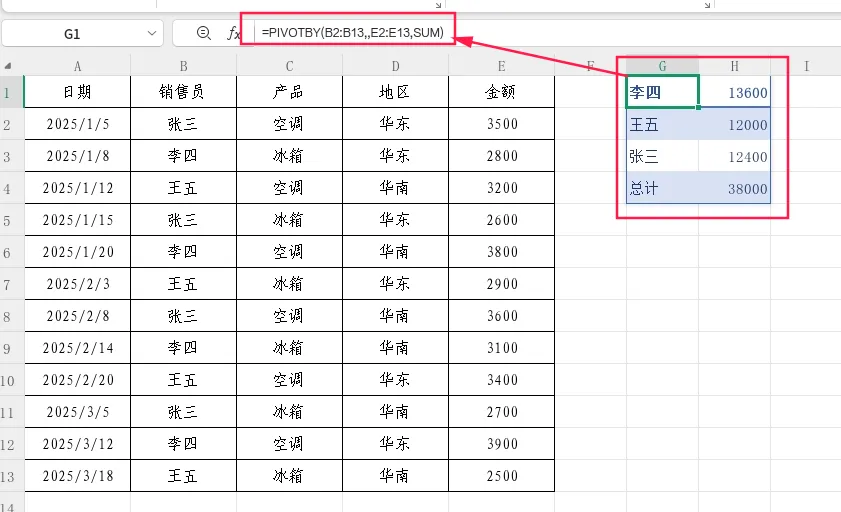
=PIVOTBY(B2:B13,,E2:E13,SUM)
结果:以“销售员”为行维度,每个销售员占一行,自动去重后显示每个人的销售额合计。
进阶用法:行字段支持多列。例如按“销售员+产品”两个维度作为行分组:
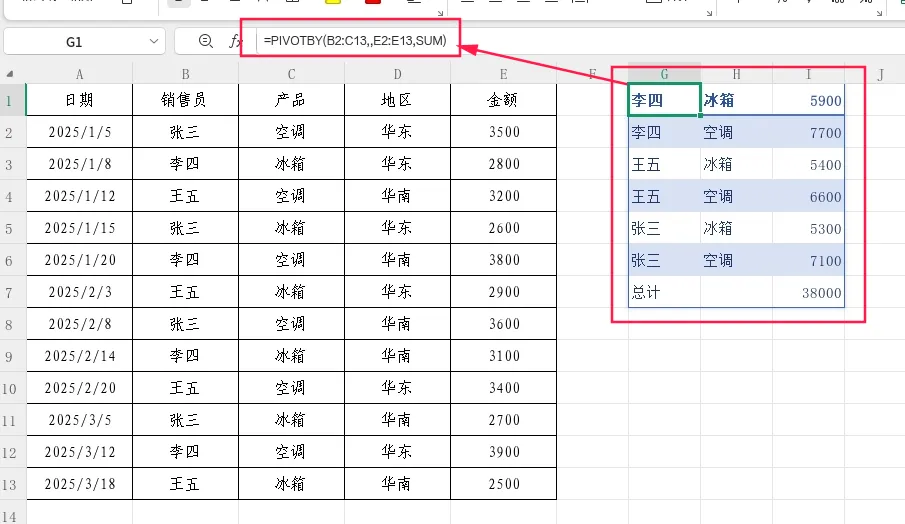
=PIVOTBY(B2:C13,,E2:E13,SUM)
此时行方向会同时按销售员和产品两级分组,形成层次分明的行标签。
参数2:列字段,作用:指定在结果中按列方向分组的字段,对应数据透视表的“列标签”区域。这是PIVOTBY区别于GROUPBY的核心参数——PIVOTBY支持行列两个维度的交叉聚合。
示例:按销售员(行)和产品(列)交叉统计销售额
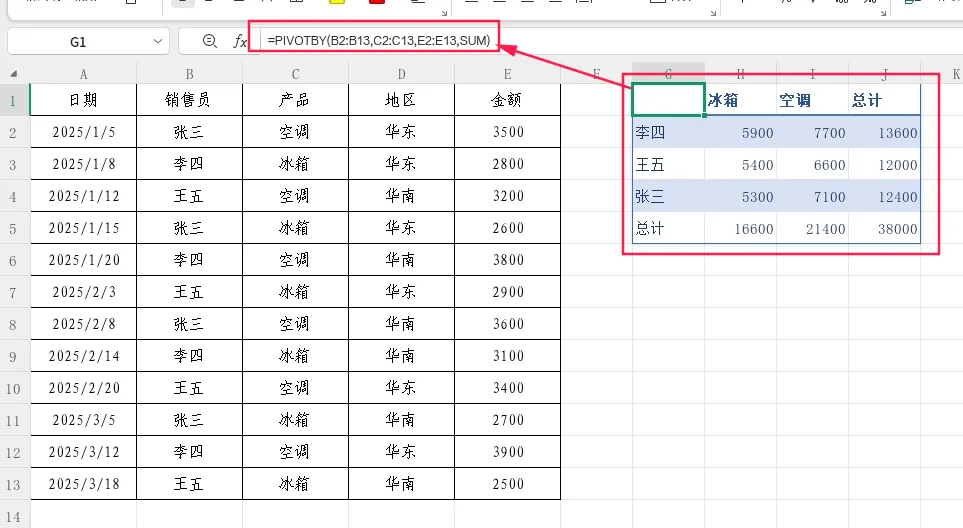
=PIVOTBY(B2:B13,C2:C13,E2:E13,SUM)
结果:行方向为销售员(张三、李四、王五),列方向为产品(冰箱、空调),交叉单元格中填入对应销售额。如果某销售员未销售某产品,则显示0。
进阶用法:列字段同样支持多列。例如按“产品+地区”作为列分组:
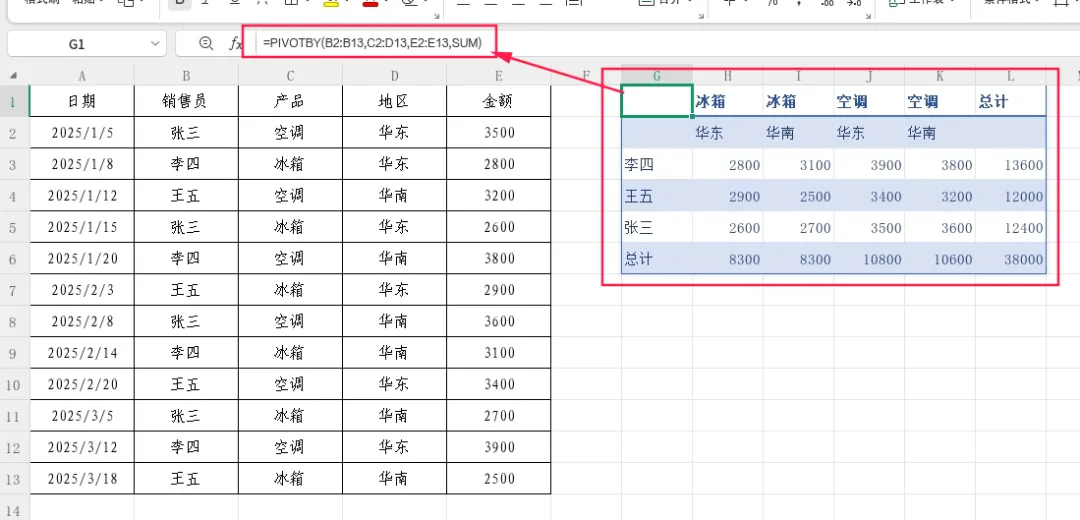
=PIVOTBY(B2:B13,C2:D13,E2:E13,SUM)
此时列方向会先按产品分组,再按地区分组,形成多级列标签。
参数3:值,作用:指定需要进行聚合计算的数据区域,对应数据透视表的“值”区域。
示例:统计销售额总和
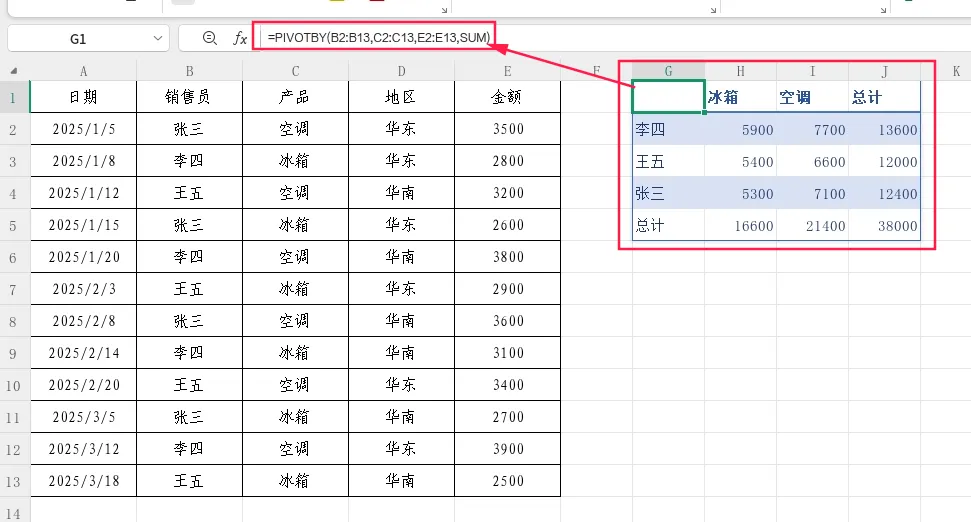
=PIVOTBY(B2:B13,C2:C13,E2:E13,SUM)
进阶用法:值字段支持多列。例如同时统计“金额”和“数量”(假设有F列数量数据):
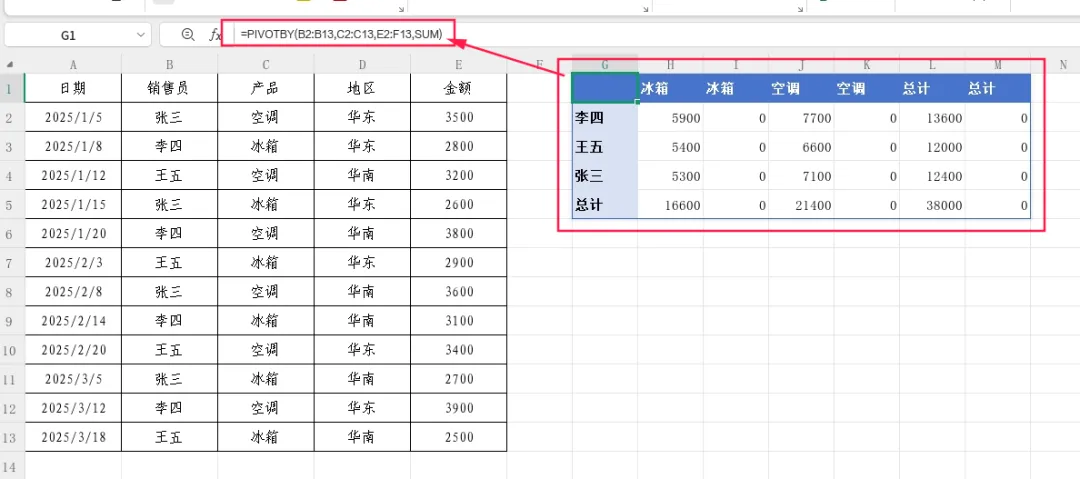
=PIVOTBY(B2:B13,C2:C13,E2:F13,SUM)
结果中每个行/列交叉点会显示两列:金额合计和数量合计。
参数4:函数,作用:指定对值字段执行何种聚合运算。这是PIVOTBY的灵魂参数,决定了数据的汇总方式。

示例 1:按销售员和产品统计平均销售额
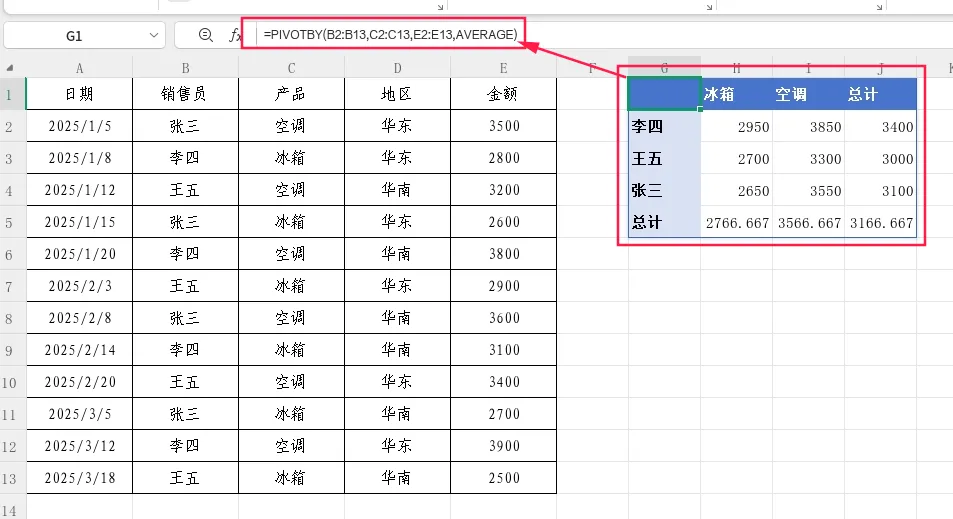
=PIVOTBY(B2:B13,C2:C13,E2:E13,AVERAGE)
示例2:按销售员统计销售次数(计数)
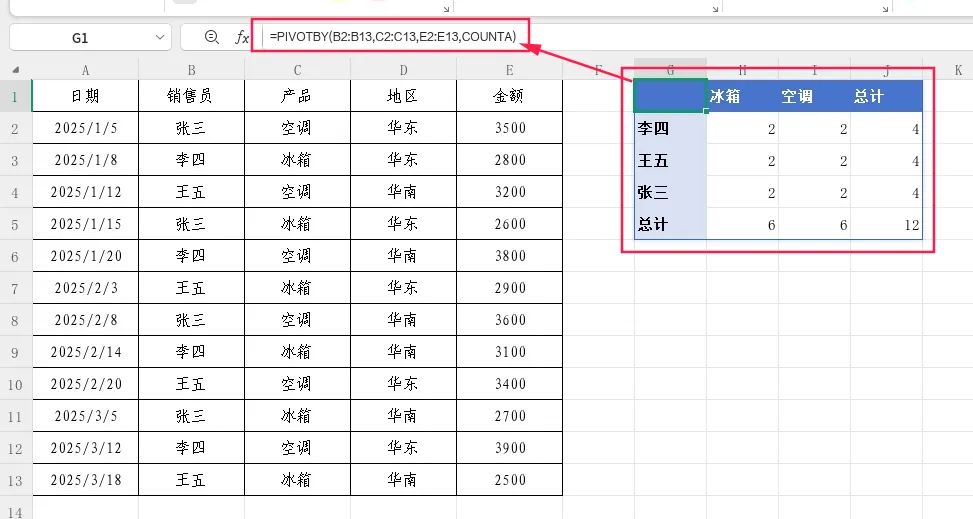
=PIVOTBY(B2:B13,C2:C13,E2:E13,COUNTA)
示例3:按销售员和产品合并文本(如将日期合并)
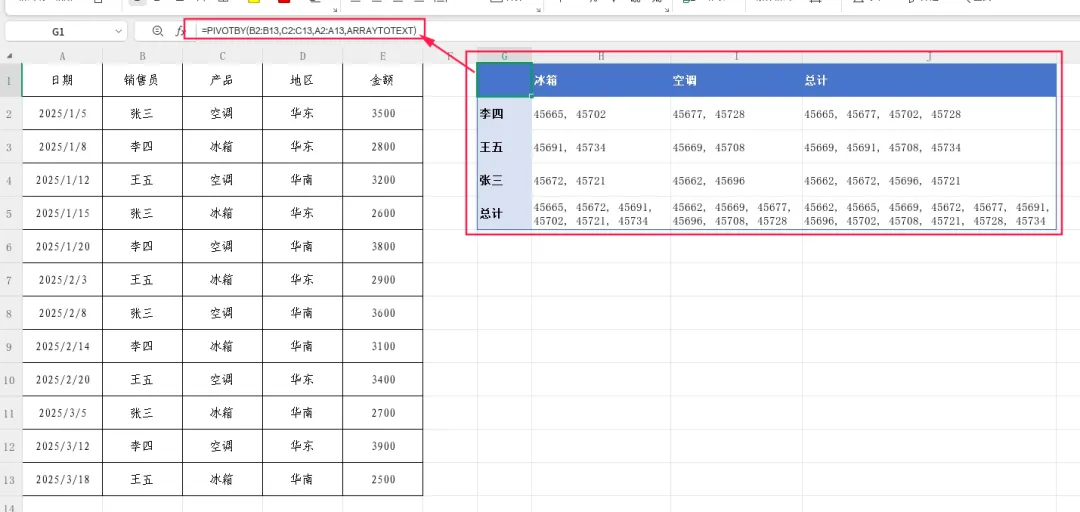
=PIVOTBY(B2:B13,C2:C13,A2:A13,ARRAYTOTEXT)
参数5:标头,作用:控制源数据是否包含表头,以及结果中是否显示表头。

示例:源数据包含表头行,希望在结果中也显示表头
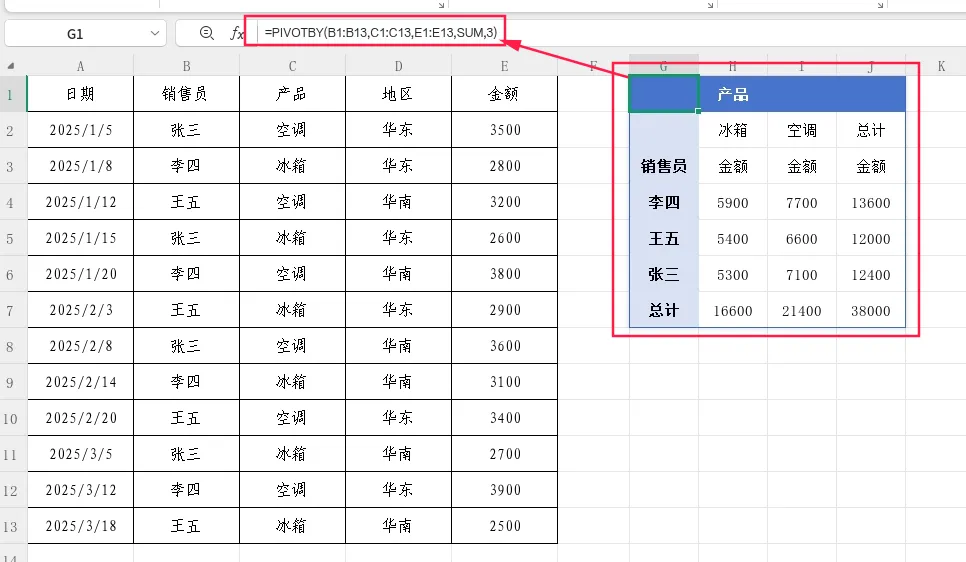
=PIVOTBY(B1:B13,C1:C13,E1:E13,SUM,3)
注意:当源数据有表头时,建议将区域范围包含表头行(如B1:B13而非B2:B13),并将第5参数设为3,这样结果中会显示“销售员”“产品”“金额”等有意义的列名。
参数6:行总计深度,作用:控制行方向是否显示总计行以及小计行。

示例:在结果下方显示总计行
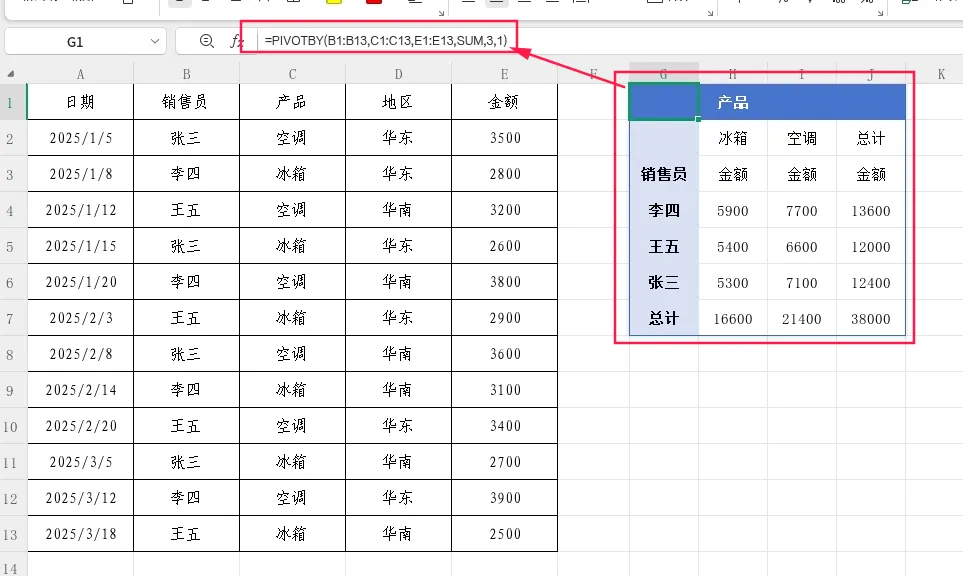
=PIVOTBY(B1:B13,C1:C13,E1:E13,SUM,3,1)
示例:在结果下方显示总计行
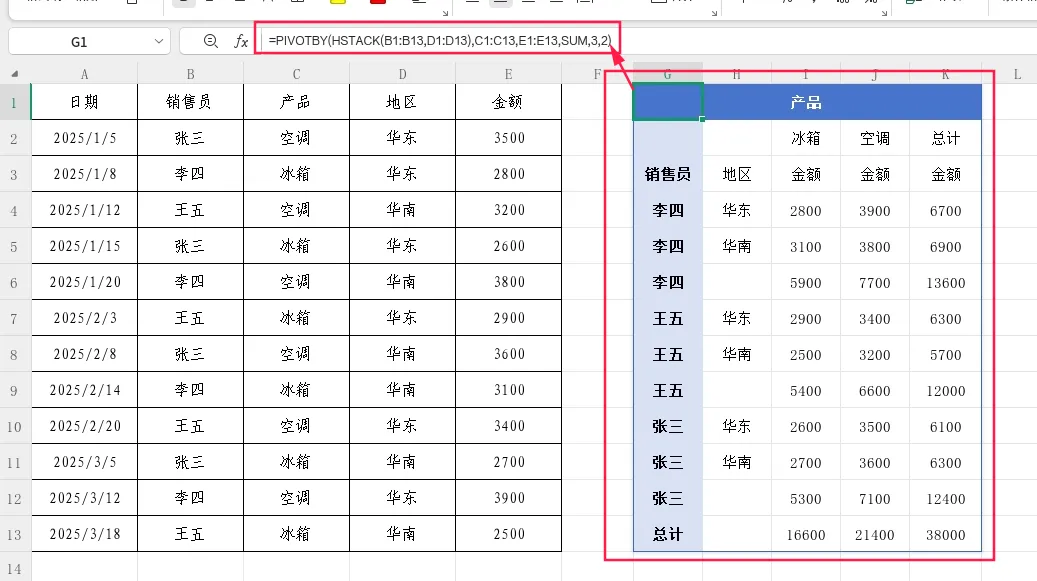
=PIVOTBY(HSTACK(B1:B13,D1:D13),C1:C13,E1:E13,SUM,3,2)
提示:只有当行字段包含多列时,小计行才会生效。如果行字段只有一列,设置2或-2时小计行会显示为错误值。
参数7:行排序顺序,作用:对行字段的显示顺序进行排序。
取值:输入数字或数组,正数表示升序,负数表示降序。数字代表对第几列进行排序(从行字段的第一列开始计数)。
示例1:按行字段第一列降序排列
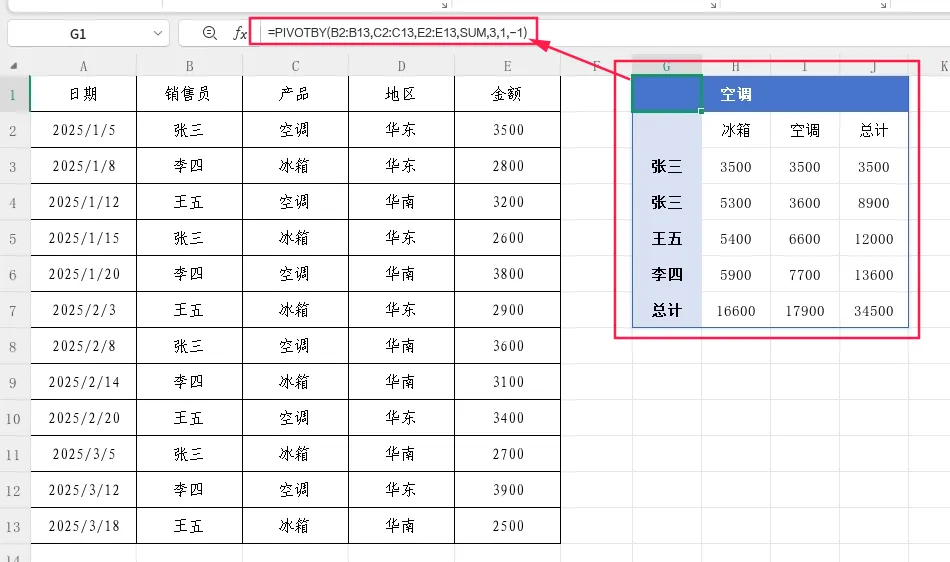
=PIVOTBY(B2:B13,C2:C13,E2:E13,SUM,3,1,-1)
上述公式中,-1表示按行字段的第1列(销售员)降序排列。
示例2:按行字段第二列升序排列
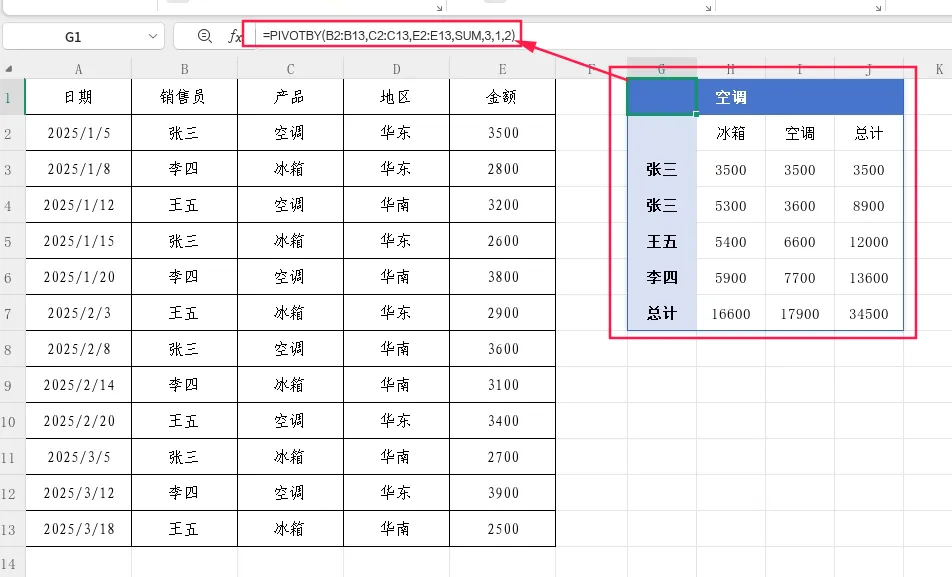
=PIVOTBY(B2:B13,C2:C13,E2:E13,SUM,3,1,2)
2表示按行字段的第2列(产品)升序排列。
示例3:多级排序——先按第1列降序,再按第2列升序。
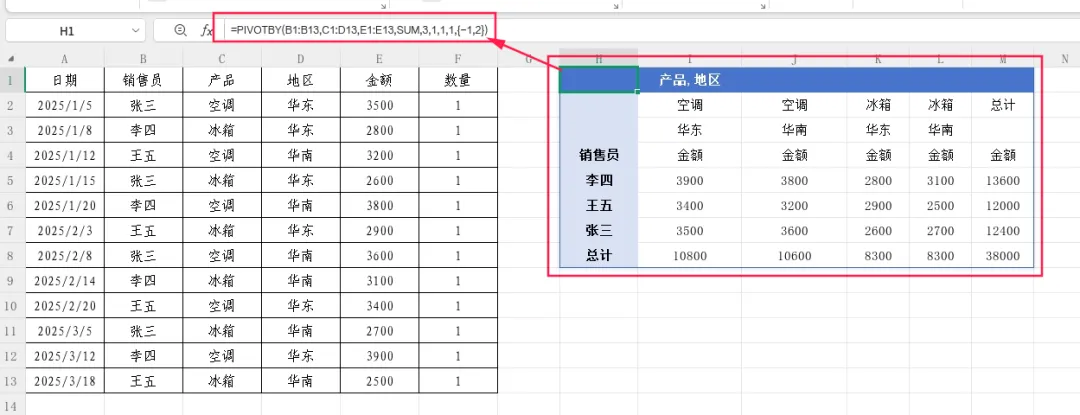
=PIVOTBY(B1:B13,C1:D13,E1:E13,SUM,3,1,1,1,{-1,2})
使用花括号数组,可以实现对多个行字段列分别指定排序方向。
参数8:列总计深度,作用:控制列方向是否显示总计列以及小计列。用法与第6参数完全对称。

示例:在结果右侧显示总计列
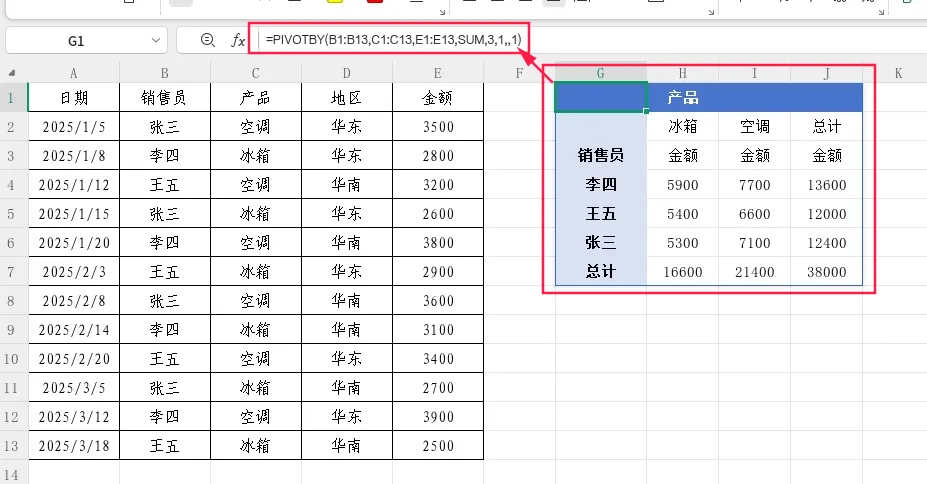
=PIVOTBY(B1:B13,C1:C13,E1:E13,SUM,3,1,,1)
注意第7参数留空(用逗号占位),表示使用默认排序。
参数9:列排序顺序,作用:对列字段的显示顺序进行排序。用法与第7参数完全对称。
取值:正数升序,负数降序,数字代表对列字段的第几列进行排序。
示例:按列字段第一列(产品)降序排列
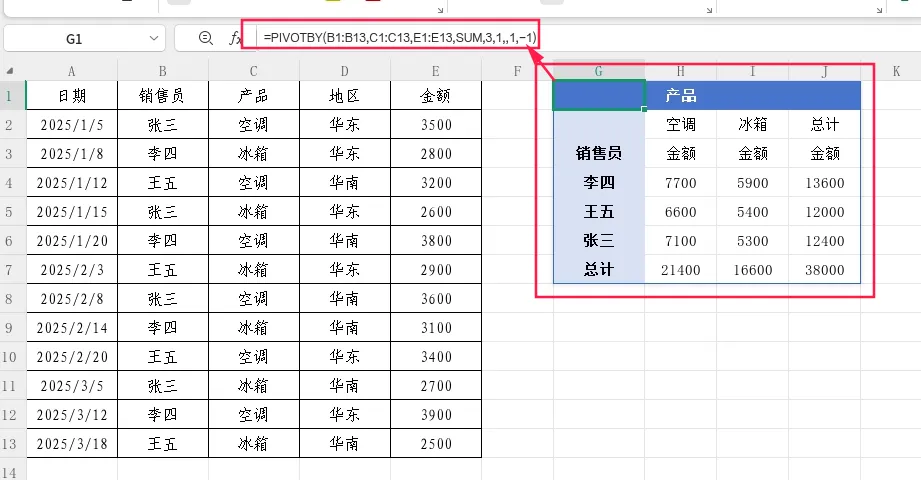
=PIVOTBY(B1:B13,C1:C13,E1:E13,SUM,3,1,,1,-1)
参数10:筛选数组,作用:对源数据进行条件筛选,只有满足条件的数据才会参与聚合计算。
取值:一个由TRUE/FALSE组成的逻辑数组,长度必须与源数据行数一致。
示例1:只统计“华东”地区的销售数据
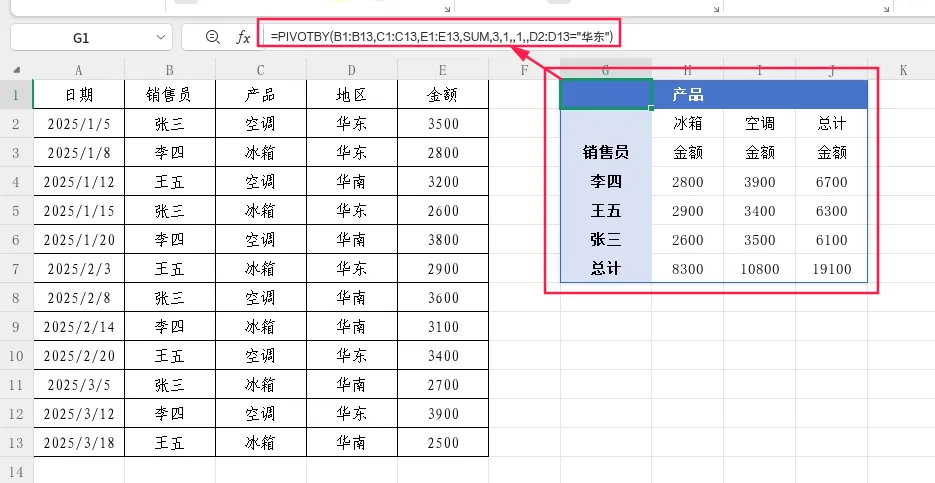
=PIVOTBY(B1:B13,C1:C13,E1:E13,SUM,3,1,,1,,D2:D13=”华东”)
第10参数D2:D13=”华东”会生成一个逻辑数组,只有地区为”华东”的行返回TRUE,参与计算。
示例2:多条件筛选——统计华东地区且金额大于3000的数据
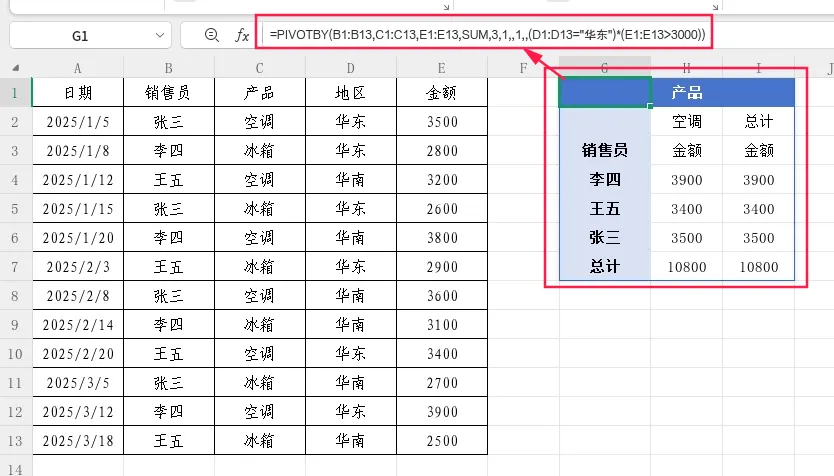
=PIVOTBY(B1:B13,C1:C13,E1:E13,SUM,3,1,,1,,(D1:D13=”华东”)*(E1:E13>3000))
使用*连接多个条件,表示“且”的关系。如果要表示“或”,则使用+。
参数11:相对关系,作用:当第4参数(函数)使用 PERCENTOF(计算百分比)时,此参数指定百分比计算的分母参照范围。如果聚合函数不是PERCENTOF,此参数无效。
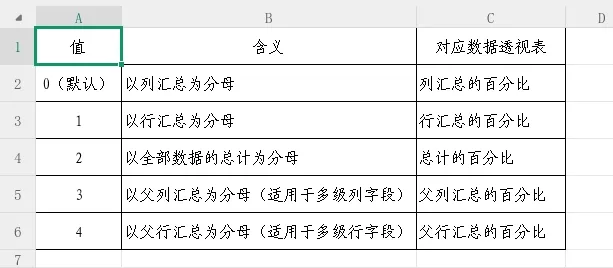
背景说明:PERCENTOF是PIVOTBY支持的一种特殊聚合函数,用于计算每个值在某个总计中的占比。其完整LAMBDA形式为:
LAMBDA(subset,totalset,SUM(subset)/SUM(totalset)),可简写为eta形式PERCENTOF。第11参数就是用来指定这个totalset(分母)的参照范围。
示例1:计算每个销售员每种产品的销售额占列总计的百分比(默认)
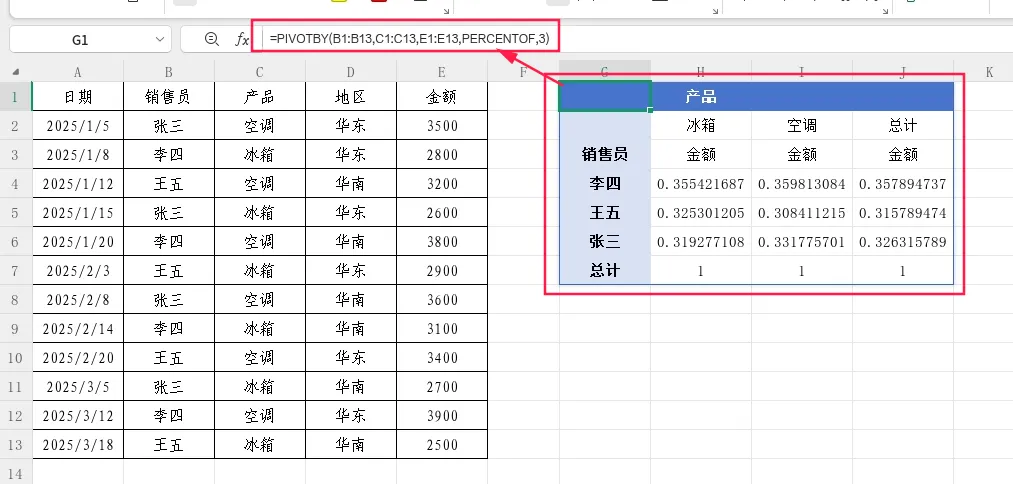
=PIVOTBY(B1:B13,C1:C13,E1:E13,PERCENTOF,3)
此时第11参数省略(默认为0),每个单元格的值=该单元格销售额/该列(产品)的销售额总计。例如“空调”列下各销售员的百分比之和为100%。
示例2:计算每个销售员每种产品的销售额占行总计的百分比
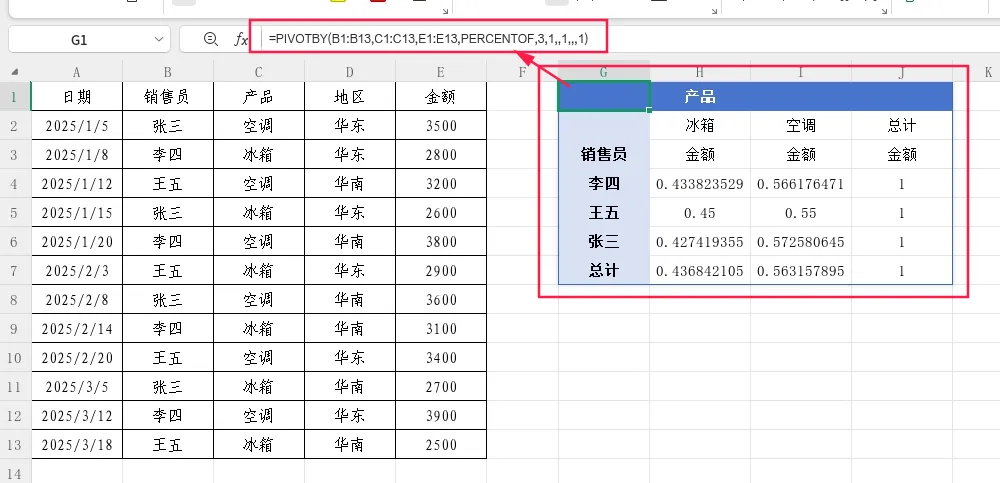
=PIVOTBY(B1:B13,C1:C13,E1:E13,PERCENTOF,3,1,,1,,,1)
第11参数设为1,每个单元格的值=该单元格销售额/该行(销售员)的销售额总计。例如“张三”行各产品的百分比之和为100%。
示例3:计算每个销售员每种产品的销售额占全部总计的百分比
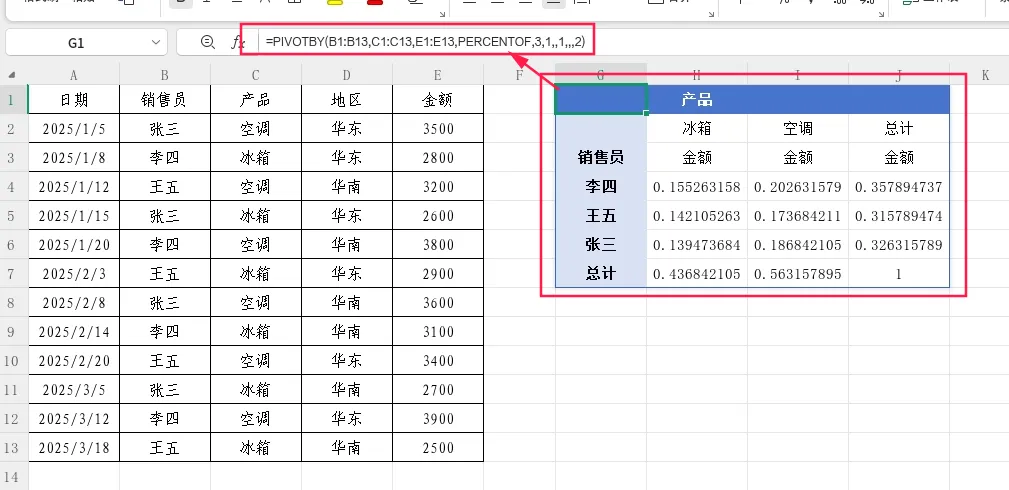
=PIVOTBY(B1:B13,C1:C13,E1:E13,PERCENTOF,3,1,,1,,,2)
第11参数设为2,每个单元格的值=该单元格销售额 / 全部销售额总计。所有单元格的百分比之和为100%。
示例4:多级字段下的父列百分比
假设行字段为“销售员+产品”两列,列字段为“地区”一列:
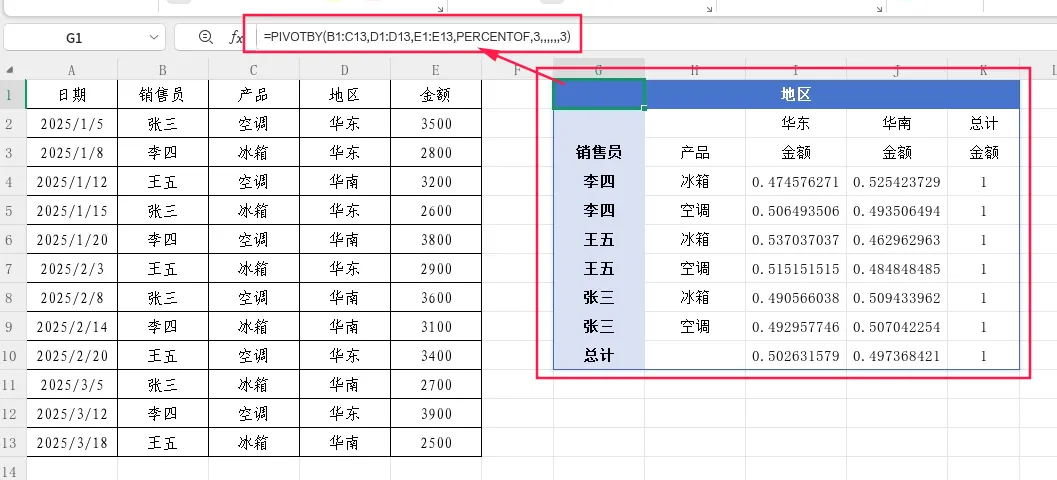
=PIVOTBY(B1:C13,D1:D13,E1:E13,PERCENTOF,3,,,,,,3)
第11参数设为3,每个单元格的值=该单元格销售额/其父列(地区)的汇总值。当列字段只有一级时,效果等同于默认值0。
提示:第11参数仅在聚合函数为PERCENTOF时生效。如果使用SUM、AVERAGE、COUNTA等其他聚合函数,此参数被忽略。
综合实战案例
案例1:完整的数据透视报表
需求:按销售员(行)和产品(列)统计销售额总和,显示表头,显示行列总计,按销售额降序排列。
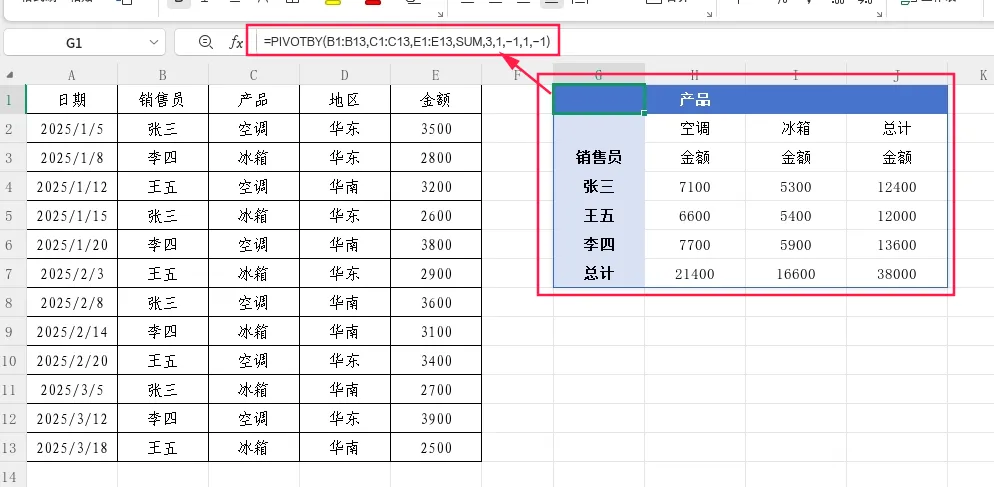
=PIVOTBY(B1:B13,C1:C13,E1:E13,SUM,3,1,-1,1,-1)
案例2:按月汇总分析
需求:按月份(行)和产品(列)统计销售额总和。
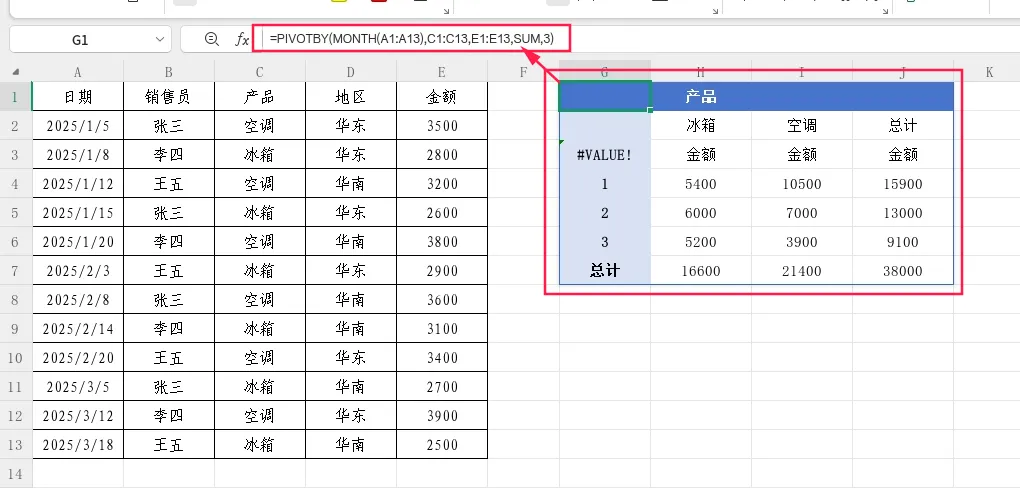
=PIVOTBY(MONTH(A1:A13),C1:C13,E1:E13,SUM,3)
使用MONTH函数将日期转换为月份数字,实现按月分组。
案例3:筛选条件下的交叉统计
需求:只统计空调产品的销售额,按销售员(行)和地区(列)展示。
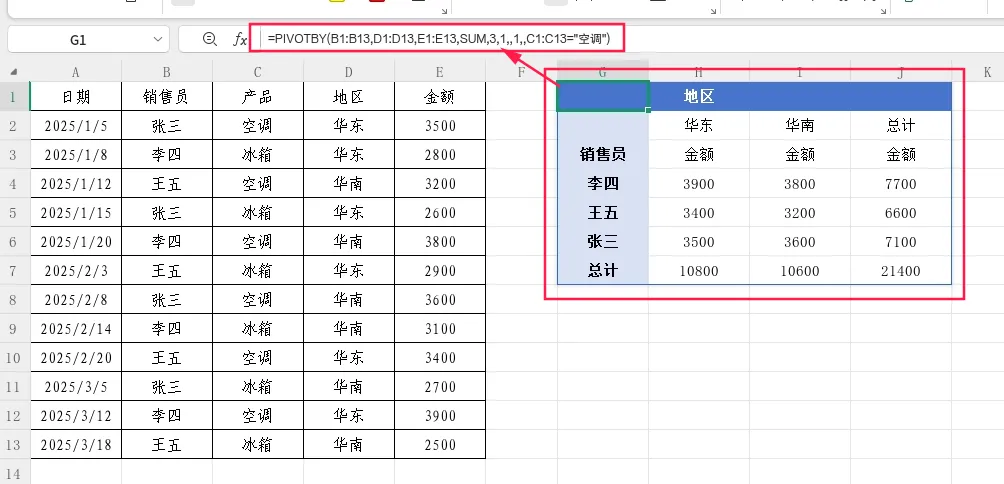
=PIVOTBY(B1:B13,D1:D13,E1:E13,SUM,3,1,,1,,C1:C13=”空调”)
案例4:多值字段统计
需求:假设数据表中有“金额”(E列)和“数量”(F列)两列数值,按销售员统计总额和总数量。
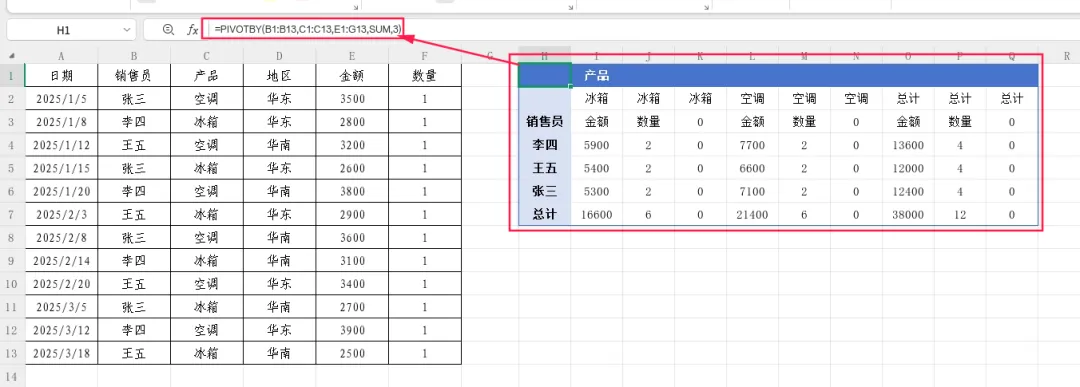
=PIVOTBY(B1:B13,C1:C13,E1:G13,SUM,3)
案例5:文本合并
需求:按销售员和产品,将对应的日期合并显示。
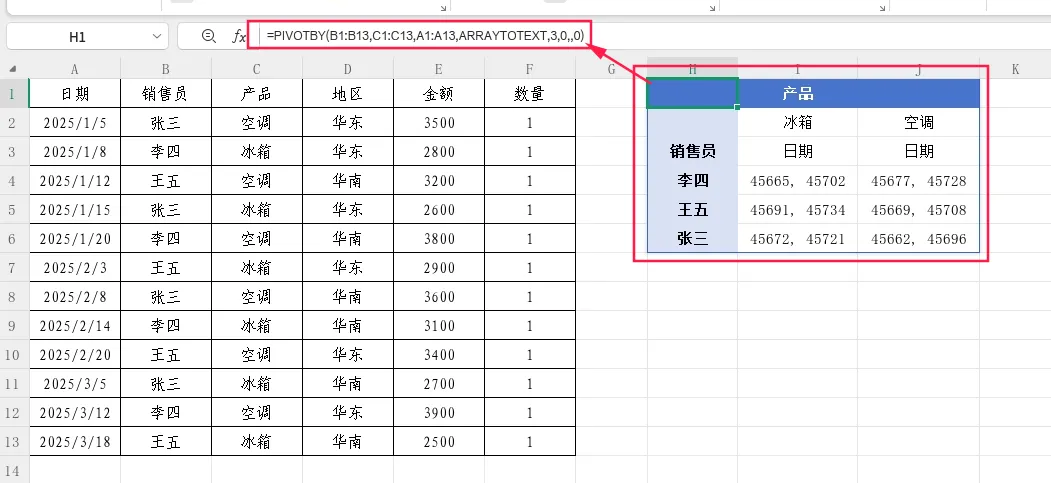
=PIVOTBY(B1:B13,C1:C13,A1:A13,ARRAYTOTEXT,3,0,,0)
案例6:多级行字段与多级列字段的交叉透视

需求:以“地区+销售员”作为行字段(两级行分组),以“产品”作为列字段,统计销售额总和,并显示行小计与列总计。
数据说明:沿用示例数据表,其中:
– D列 = 地区(华东、华南)
– B列 = 销售员(张三、李四、王五)
– C列 = 产品(空调、冰箱)
– E列 = 金额
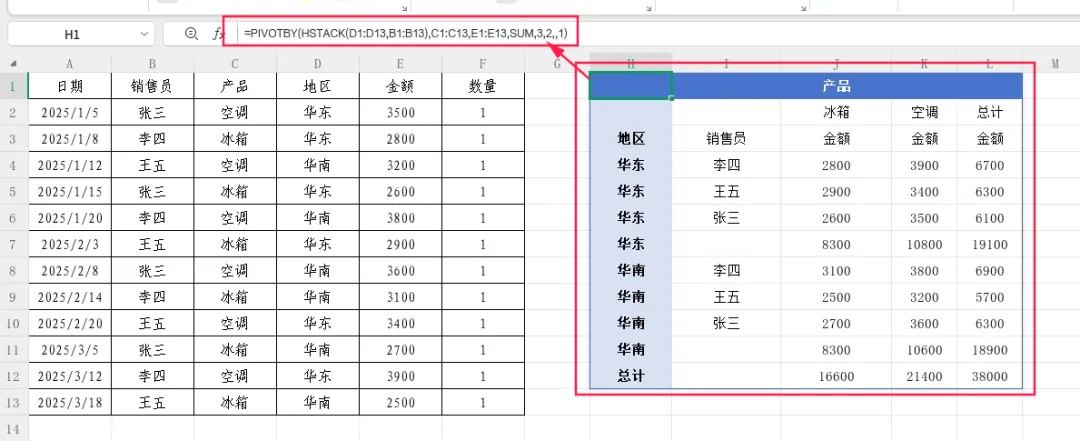
公式:=PIVOTBY(HSTACK(D1:D13,B1:B13),C1:C13,E1:E13,SUM,3,2,,1)
关键要点:
1.行字段多级分组:用HSTACK堆叠两列数据,共同构成行方向的两级分组。第一级按“地区”聚合,第二级在每个地区下按“销售员”细分。
2.小计行自动生成:由于行字段有两列,且第7参数设为2,PIVOTBY会自动在每个地区分组下方插入小计行,汇总该地区所有销售员的销售额。
3.列总计:第9参数设为1,结果最右侧会显示每个销售员(以及每个小计行)的销售额合计。
进阶——同时使用多级行字段和多级列字段:
如果列字段也设置为多级,例如按“产品+地区”作为列字段:
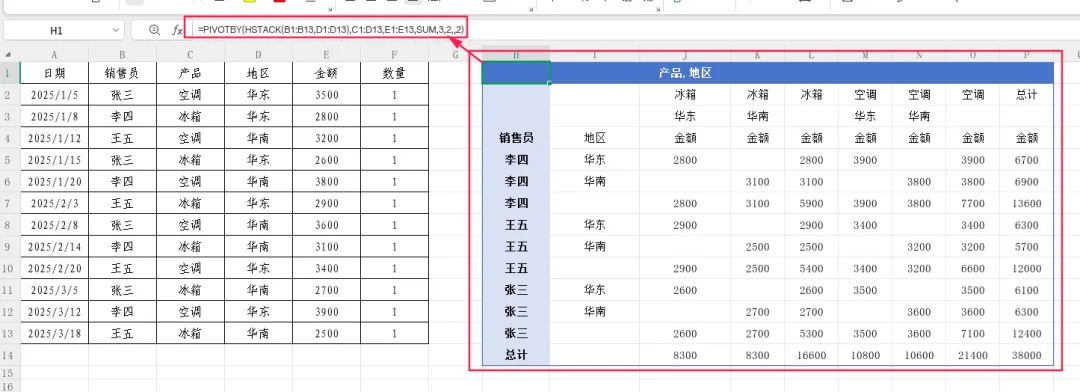
=PIVOTBY(HSTACK(B1:B13,D1:D13),C1:D13,E1:E13,SUM,3,2,,2)
此时行方向按“销售员”分组并显示小计,列方向按“产品”分组,每个产品下再按“地区”细分,形成类似数据透视表的完整二维交叉报表。
注意事项
1.动态数组:PIVOTBY 是动态数组函数,结果会自动溢出到相邻单元格。请确保结果区域有足够的空白单元格,避免被其他数据遮挡。
2.数据源要求:源数据应保持连续性,避免空行空列;同一列的数据类型应保持一致。
3.自动更新:当源数据发生变化时,PIVOTBY 的结果会自动重新计算,无需像数据透视表那样手动刷新。
4.配合其他函数:PIVOTBY 的结果可以作为其他函数的参数继续使用,例如用 DROP 函数去除总计行,用 SORT 进一步排序等。
5.版本要求:PIVOTBY 函数需要 WPS 最新版本支持,建议更新到最新版 WPS Office 使用。
6.PERCENTOF 配合第11参数:当需要计算占比时,使用 PERCENTOF 作为第4参数,并通过第11参数控制分母是列总计、行总计还是全部总计,灵活实现不同维度的百分比分析。
总结
PIVOTBY函数是WPS表格中极具威力的数据分析工具,它用函数公式的形式实现了数据透视表的核心功能,同时兼具动态更新的优势。
掌握这11个参数,你就可以用PIVOTBY替代大部分数据透视表的场景,实现更加灵活、自动化的数据分析。