 夜雨聆风
夜雨聆风





本地能做不稀奇,云端也能做才是 WPS Comate 的解法
本地能做不稀奇,云端也能做才是 WPS Comate 的解法
同一个真实学情项目,本地跑一次,WPS 365 云端再跑一次。
看的是 AI Agent 能不能进入办公现场,把资料推进到可交付。

前两天我写了一篇文章,聊企业要用好 AI,我作为用户最关心的几件事。
那篇文章里,我问了三个很实际的问题:
数据底子薄,是不是就别碰 AI 了?
各种格式的老文件,AI 到底能不能真读懂?
现场的录音、文字、图片和资料,能不能最后自动整理成能用的稿子?
写完以后,我其实一直觉得还差半句。
因为这些问题背后,真正想问的是:
如果资料已经在我手里,AI 能不能直接把这件事做完?
不是陪我聊一聊,给我几个建议就完事儿了,
得真的读资料、拆结构、做交付,
最后回到我能直接编辑和分享的文档里。
这两天,我用同一个真实项目,分别在本地和云端测了一次 WPS Comate。
测完以后,我大概知道前面那几个问题的解法应该长什么样了。
● ● ●
先从一个具体项目开始,不要从“大数据治理”开始
我这次没有拿一个干净的演示文件来测。
我用的是自己前面给一位英语老师做过的学情分析项目。
这个项目的背景很简单:
老师手里有大量学生作业和学习过程数据,平时散在不同表格和文档里。
真正要用的时候,这些资料能不能被重新组织成一个能看、能讲、能继续迭代的系统。
这里面有网页,有 CSV,有数据库,有 SQL,有说明文档,也有不同版本的看板和汇总结果。
换句话说,它不是为了 AI 测试准备的标准材料。
它就是一个真实项目留下来的工作现场。
这里先说明一下:这次用于测试的资料已经做过脱敏处理,不涉及学生姓名、联系方式等个人敏感信息。
我测试的是 Comate 对真实项目结构的理解和交付能力,不是拿原始学生隐私数据做实验。

图里这些文件,差不多就是这次测试的起点:一整个项目文件夹。
我给 WPS Comate 的任务也很直接:
这句话真正考验的是:它能不能先读懂项目。
项目为什么做,数据从哪里来,中间怎么处理,最后给老师看到什么,哪些地方是功能,哪些地方是技术实现,哪些地方是使用建议。
这些东西如果理不清,PPT 做得再漂亮也没有用。
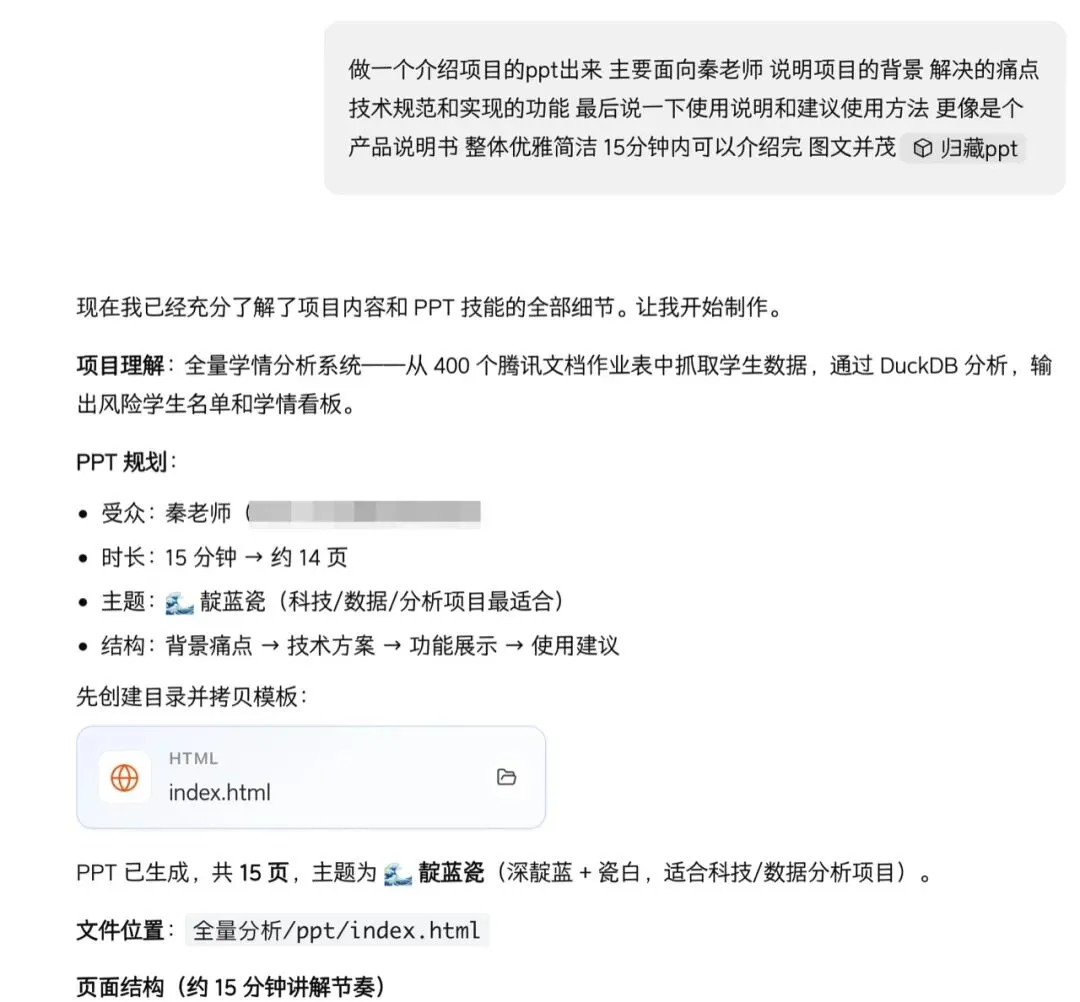
一个AI agent 能把项目理解、受众、时长、主题、页面结构先拆出来,再开始生成文件。
这点真的很重要。
对一个办公场景里的 AI Agent 来说,第一步可不是文采好,是任务理解对。
如果上来就写一堆“智能分析、精准洞察、提升效率”,我直接一票否决。
因为真正拿去讲给项目方听的时候,对方一定会问:
你到底分析了什么?怎么分析的?这个系统现在能用到哪一步?
我看的可不是写写漂亮话就完了。
● ● ●
本地能做,只说明它会读文件;云端也能做,才接近办公现场
第一次测试,我让它处理的是本地项目文件夹。
第二次,我换了一个入口。
我把同一套资料上传到了 WPS 365,放在云文档和云盘里,再让 WPS Comate 处理。
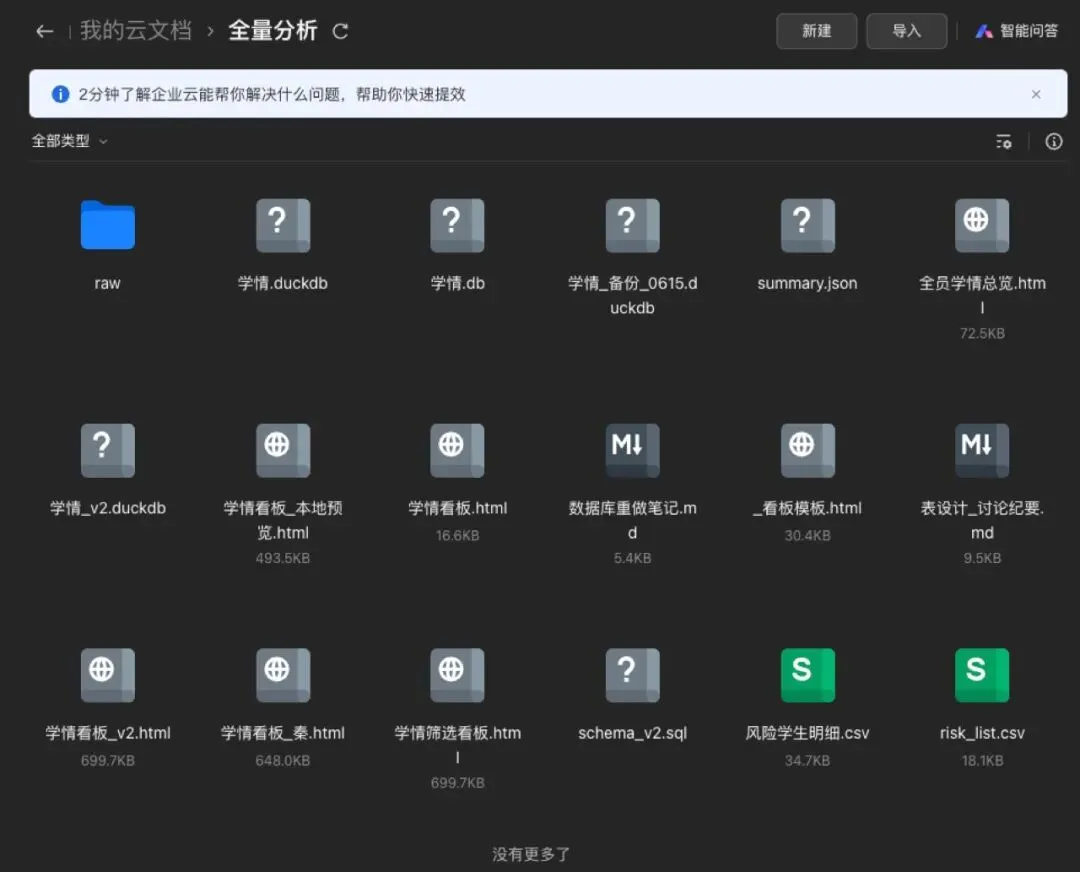
这一步看起来只是把资料从本地挪到了云端。
但在真实办公里,这个差别非常大。
因为很多人日常的资料本来就不在本地文件夹里。
它们在网盘里,在云文档里,在团队空间里,在别人分享给你的文件夹里。
尤其是教育行业、政企场景和企业办公里,很多单位本来就在用 WPS。
资料已经在里面了,协作也已经在里面了。
这时候要我先把资料下载下来,再重新整理,再上传给另一个 AI?拜拜吧
我真正想要的是:
资料已经在这里了,你能不能直接干活?
这就是我第二次测试最想看的地方。
同一个项目,同一批资料,同一个目标:做一份 15 分钟能讲清楚的项目介绍。
区别只是入口变了。
一个入口是本地项目文件夹。
另一个入口是 WPS 365 云盘里的项目资料。
这才是办公 AI 最值得讨论的地方。
它能从你原本的资料环境里来,再把结果交回到文档、表格和演示里去。
我自己把它理解成这样一条链:

同一个项目,两种入口,最后都回到可交付的办公产物。
办公里最耗人的,最后写那几段话还好,主要是前面那堆资料怎么进入流程。
● ● ●
Skill 不是噱头,它决定经验能不能被复用
这次我还测了一个点:Skill。
WPS Comate 支持上传 Skill,我把归藏老师那套做演示稿的 Skill 也放进去一起用了。
很多人一听 Skill,会觉得它只是高级提示词。
但如果放到办公场景里,它的意义会更具体。
因为办公室里的很多任务不是一次性的。
写项目介绍、整理会议材料、做产品说明书、把资料改成演示稿、把一篇文章拆成不同平台版本,这些事背后其实都有方法。
过去这些方法在人的脑子里,在老员工的经验里,在一堆零散提示词里。
如果每次都重新写,结果就很不稳定。
同一套 Skill,装在不同 Agent 上,体验确实会有差异。
Skill 本身是一套方法,但能不能顺畅跑起来,取决于 Agent 对资料读取、任务拆解和执行链路的支撑能力。
这次把归藏老师的演示稿 Skill 放进 WPS Comate 后,整体体验是比较顺的。
它不是把 Skill 单独挂在某个入口,而是能自然接入前面的项目资料理解、结构拆解和 PPT 生成流程里。
我不需要反复解释要怎么做 PPT,也不需要在多个工具之间搬资料。
资料在 WPS 365 里,Skill 在 Comate 里,最后结果也能回到演示文档里继续修改。
这条链路一旦连上,Skill 的价值就不只是提示词,而是方法真的能在办公 Agent 里跑起来。
● ● ●
还有一个小插曲:同样的模型,结果不一定一样
这里插一句不点名的小插曲。
我之前也用另一款常用 AI agent 做过类似任务。
为了尽量公平,我把模型、提示词、原始资料和上下文都尽量拉到接近的条件。
结果还是出现了明显差异。
另一个工具生成的演示文档有问题,而且它自己反复检查也没看出来。
后来我让 WPS Comate 去处理,反而把问题修好了。
我不想把这件事写成拉一踩一。
工具都会迭代,生态也会变化。
今天某个工具表现不好,不代表它以后一直不好。
但这件事至少提醒我一件事:
AI Agent 的竞争,不只是模型的竞争,更是工程化能力的竞争。
同一个模型,放在不同的 Agent 框架里,文件怎么读、任务怎么拆、过程怎么执行、产物怎么检查、错误怎么修复,都会影响最后结果。
这对非技术用户来说,感知很简单:
好不好用,最后能不能交付。
对技术用户来说,看到的是另一层:
执行链路是否稳定,工具调用是否可靠,产物是否能被验证,出错后能不能修回来。
● ● ●
这就是前两天那篇文章里,我真正想找的解法
前两天那篇文章里,我最关心的是三件事。
第一,数据底子薄,是不是就不能用 AI?
这次我的感受是,不一定。
更现实的做法不是先规划一个三年数据治理工程,而是从一个具体场景切进去。
比如这次的学情分析项目,先把一个项目跑通,再围绕这个项目补数据、补字段、补文档。
第二,各种格式的资料,AI 能不能真读懂?
本地测试回答的是这一点。
我没有给它一份精修后的说明书,而是给了一个真实项目文件夹。
里面有网页、数据、脚本、说明文档和生成物。
它要先读懂这个工作现场,再生成一份能讲的项目介绍。
第三,资料已经在办公系统里,AI 能不能顺手接上?
云端测试回答的是这一点。
如果资料已经在 WPS 365 云盘里,就不应该再下载、搬运、重新整理。
最好是 AI 直接进入这个资料环境,把结果也放回文档和演示场景里。
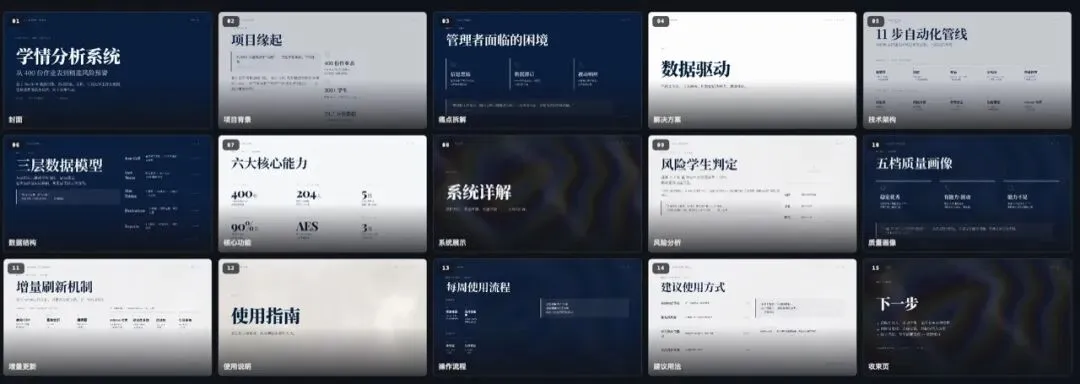
所以这次测试之后,我对 WPS Comate 的判断更清楚了。
它最值得看的,不是多回答了一段话。
而是它在尝试把输入、处理和输出都放回办公闭环里。

这件事对教育行业尤其现实。
老师、教务、机构管理者手里有大量表格、文档、课件、学生数据和汇报材料。
这些资料本来就不是为了 AI 准备的。
它们就是日常工作留下来的东西。
如果每次用 AI 都要先整理一遍资料,实际使用率一定上不去。
但如果资料本来就在 WPS 里,Comate 又能直接读这些资料,生成总结、演示、说明书,再回到文档里继续改,那它就不是额外多出来的工具。
它更像是原有办公流程里长出来的一层 AI 能力。
● ● ●
评判标准变更——能不能交付
这次测试以后,我对 AI Agent 的判断标准又收窄了一点。
AI 回答得再漂亮,不如把本地或者云端的真实文件处理好。
理解一个项目,把本地文件夹和云端资料都清晰拆解
用 Skill,把经验变成流程,生成一个真的能讲的交付物
这也是我理解的 WPS Comate 的价值:
让我不需要离开原来的办公环境,去另一个地方重新组织资料。
在我已经使用的文档、云盘、演示和协作场景里,把 AI 直接用起来。
文档从这里来。
资料在这里读。
结果也回到这里。
对很多办公用户来说,比模型参数重要多了。

因为他们最终要的是一件事被推进到可以交付。
那么,前两天我问的那些问题,
至少在这次测试里,我看到了一个答案。

如果这篇对你有帮助,欢迎点赞、转发、推荐支持~
点赞
转发
推荐