 夜雨聆风
夜雨聆风





用AI图像算法,让医疗文档数据真正“用起来”

在临床研究及医疗数据管理过程中,大量关键信息仍然以纸质或扫描文档的形式存在,例如检查报告、病历资料、检验单据等。这些文档虽然承载了完整的信息,但由于无法被系统直接识别和使用,往往需要依赖人工进行整理与录入。
在实际操作中,文档处理不仅工作量大,而且容易受到文档质量、格式差异等因素影响,导致数据利用效率不高、处理成本持续增加。如何将这些“看得见但用不上”的信息转化为可直接使用的数据,成为医疗数字化过程中必须解决的问题。
围绕这一问题,基于AI图像算法的文档处理方式,正在逐步改变传统以人工为主的处理模式。
数智临研实践
文档来源复杂,处理成本高

医疗文档的来源多样,既包括标准扫描件,也包括现场拍照上传的图片。这些图像在人工查看时通常可以辨认,但在实际处理过程中往往更为复杂。
整体来看,图像文档普遍存在以下问题:
图片倾斜、变形,影响阅读
分辨率不稳定,部分图像存在模糊情况
光照不均、存在阴影遮挡
部分屏幕拍摄图像会出现摩尔纹等干扰,同时图像尺寸较大
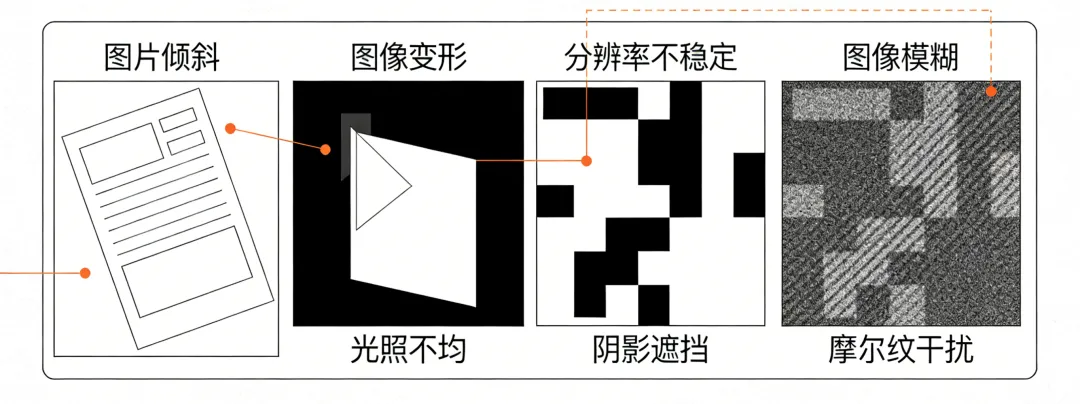
在实际处理过程中,这类图像往往需要在处理效率与识别效果之间进行平衡,例如图像压缩虽然可以提升处理速度,但也可能对识别准确性产生影响,这类情况在当前图像处理场景中仍具有一定挑战性。
在人工处理流程中,工作人员通常需要先对文档进行“人工校正”和“视觉辨认”,再进入信息提取环节,整体处理效率受到较大影响。
基于AI图像算法的处理方式,可以自动完成文档区域定位、图像矫正与清晰度优化,让文档在进入识别环节前就具备更稳定的输入质量,从源头减少人工干预。
数智临研实践
信息分散,提取效率低

医疗文档通常缺乏统一格式,不同医院、不同系统输出的报告差异较大。同一份文档中,可能同时包含段落文本、表格数据及关键字段信息。
在传统模式下,人工需要逐项查找关键信息并进行录入,不仅耗时,还依赖经验判断,容易出现遗漏或理解偏差。
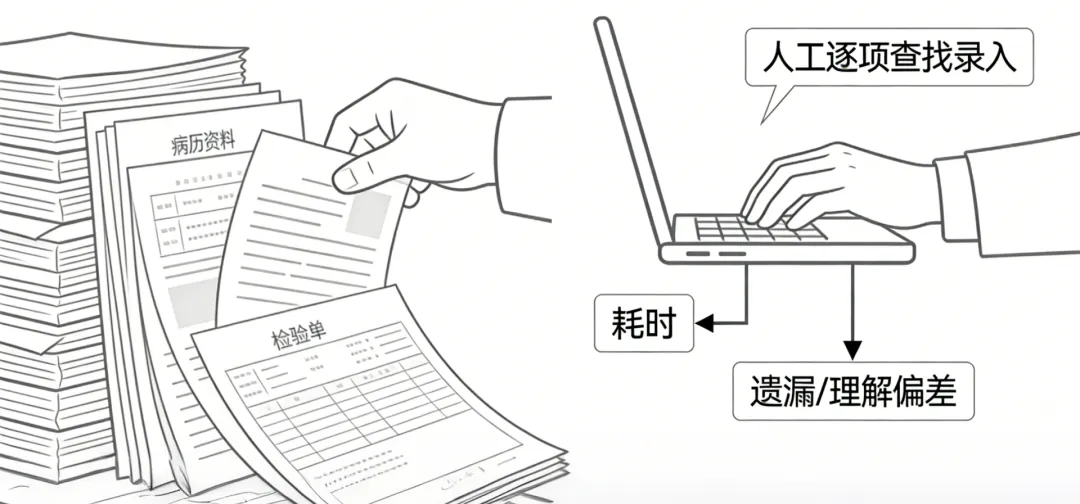
通过AI图像算法对文档内容进行识别,不仅可以提取文字信息,还可以保留每一段文字在文档中的位置信息。在此基础上,可以对文本进行分块整理,并与页面结构进行对应,使信息从“分散存在”变为“可定位、可使用”,显著提升数据提取效率。
数智临研实践
表格数据处理复杂,依赖人工理解

在检验报告、用药记录等场景中,大量关键数据以表格形式呈现。相比普通文本,表格数据处理难度更高:
行列关系复杂,存在合并单元格
指标与数值需要一一对应
不同文档结构差异明显
传统方式下,表格处理高度依赖人工逐行查看与理解,再进行系统录入,不仅效率低,也容易出现“指标与数值错位”等问题。

基于AI图像算法的文档处理能力,可以自动识别表格区域,并解析其中的行列关系,将指标与对应数值进行匹配,还原为结构化数据。对于使用方而言,无需再逐条处理,即可直接获取整理好的结果。
这一能力使得原本最依赖人工的表格处理环节,实现了自动化与标准化,也减少了人工一行一行核对数据的工作量。
数智临研实践
敏感信息处理从人工走向自动化

医疗文档中通常包含姓名、身份证号、联系方式等敏感信息,需要进行打码或脱敏处理,以满足合规要求。
人工处理方式不仅耗时,还存在遗漏风险,难以保证处理的一致性和规范性。
通过AI图像算法对文档内容进行识别,可以自动定位敏感信息所在位置,并完成相应的打码处理,减少人工参与的同时,提高整体处理的准确性与规范性。
数智临研实践
从“人工处理”到“流程驱动”

随着AI图像算法在文档处理中的逐步应用,原本分散在各个环节的人工操作,正在被逐步串联成一套自动化流程。系统会把原本分散的处理步骤串起来,比如先做图像处理,再做内容识别,最后进行结构整理,让整个流程可以自动跑通,而不是依赖人工一段一段处理。
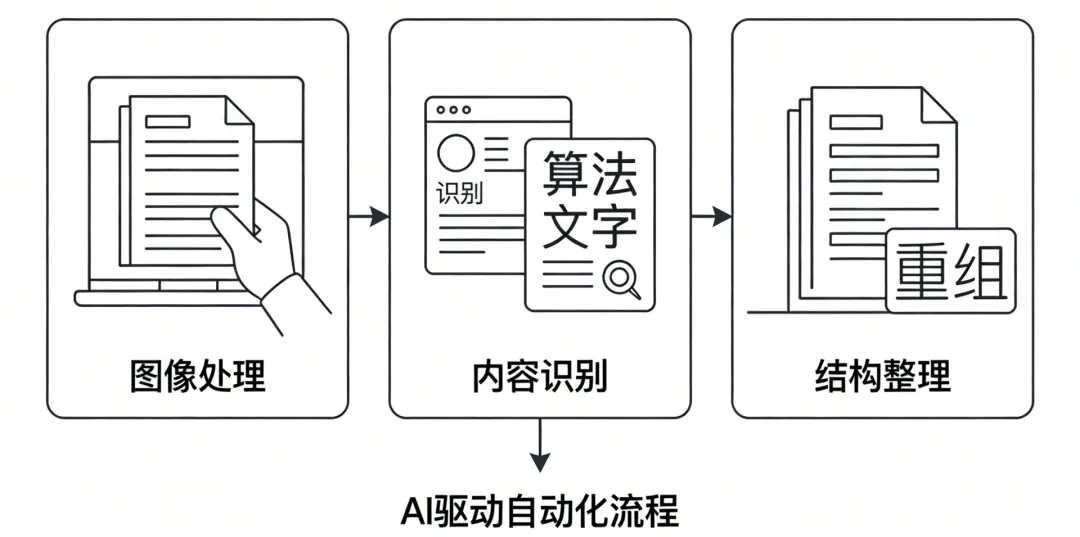
在具体流程中,文档会先经过图像处理,例如自动校正倾斜、优化清晰度等;随后通过图像文档分类判断类型,并利用OCR提取文字内容和位置信息;在此基础上,针对不同文档类型,采用相应的处理方式,结合版面分析和表格解析能力,对不同区域的信息进行整理,最终形成可以直接使用的结构化数据。
在这样的处理方式下,不同类型文档(如报告单、表格类文档、混合结构文档等)可以自动进入对应的处理流程,减少对人工经验的依赖,使处理过程更加稳定、可控。
在实际应用中,这一方式带来了明显变化:
文档无需人工预处理,系统自动完成图像优化
文本信息自动提取,减少人工录入
表格数据自动解析,降低理解成本
敏感信息自动处理,提升合规效率
这些能力不再是单点工具,而是逐步形成一套可复用的处理流程,使文档处理从“依赖人工经验”转变为“依赖系统能力”的稳定过程。
数智临研实践
从“看文档”到“用数据”

从表面上看,医疗文档处理是对图像内容的识别,但从本质上来说,是将非结构化信息转化为结构化数据的过程。
通过这一整套AI图像处理流程,文档在进入系统后,不再只是被简单读取,而是会经过图像优化、内容识别和结构整理等步骤,最终直接生成可用于业务系统的数据结果。
这一变化,不仅体现在效率提升上,更体现在数据使用方式的转变——数据不再依赖人工整理后才能使用,而是在进入系统时就已经具备可用性。
随着相关能力的不断完善,这一处理方式也具备了进一步扩展的基础,例如支持更多类型文档、适配不同业务场景,以及与其他数据系统进行衔接。
从长期来看,医疗文档将逐步从“信息载体”转变为“数据入口”,而AI图像算法所构建的处理能力,也将成为连接文档与数据的重要基础环节,为临床研究与数据管理提供更加稳定、可持续的支撑。
下期内容预告:
电子随访日历:告别繁琐表格,让临床试验访视管理“自动”起来
作者丨蒋昊东 审核丨李宗元
排版丨瓜瓜


数智临研实践
数智化临床运营先行者
专注上市后临床研究近20年
持续分享:
上市后临床研究运营管理的最佳实践 |
数智化临床运营实践案例分享 |
数字化系统的应用优化 |

*文章版权归《数智临研实践》所有
欢迎转发到朋友圈,转载请联系后台