 夜雨聆风
夜雨聆风





OpenClaw的记忆系统,用在企业场景还是太粗糙了
 用OpenClaw这类个人AI助手久了,很多人都会遇到一个棘手问题:当你询问上周刚确认的API限流方案时,AI翻出来的却是三个月前的过期内容。
用OpenClaw这类个人AI助手久了,很多人都会遇到一个棘手问题:当你询问上周刚确认的API限流方案时,AI翻出来的却是三个月前的过期内容。01
各种Claw的记忆模式到底有什么问题?
02
Decay Function如何解决RAG相似内容的重要性排序?
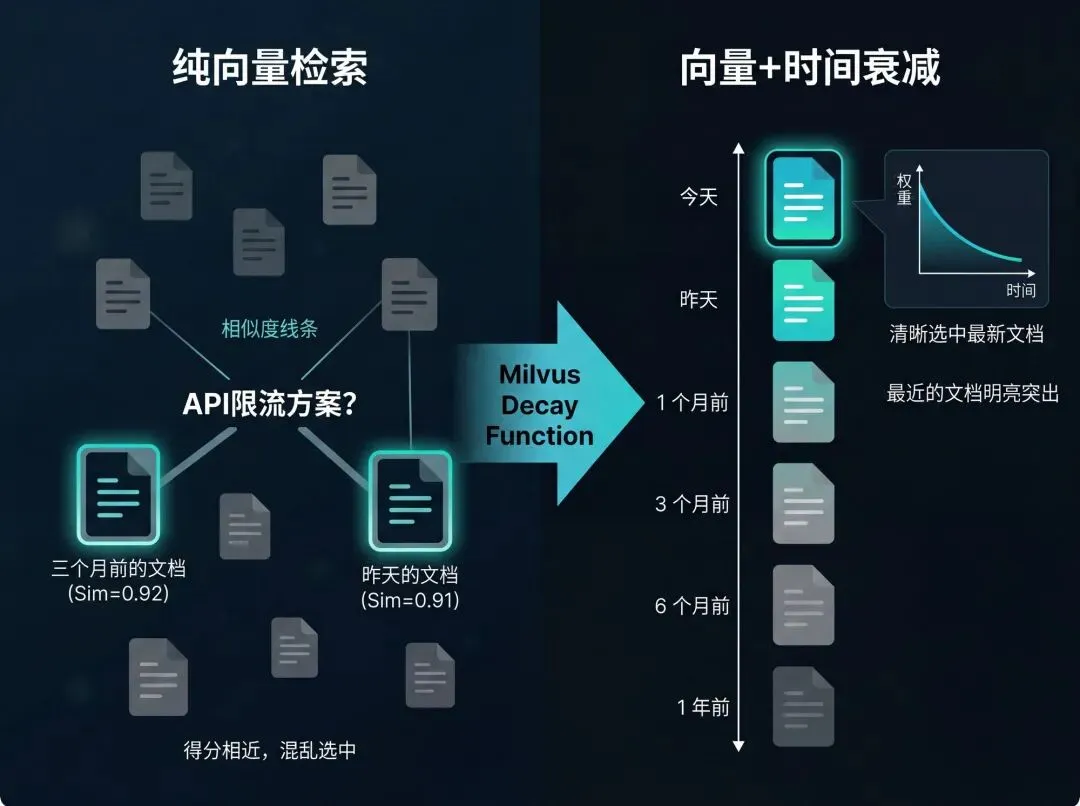
03
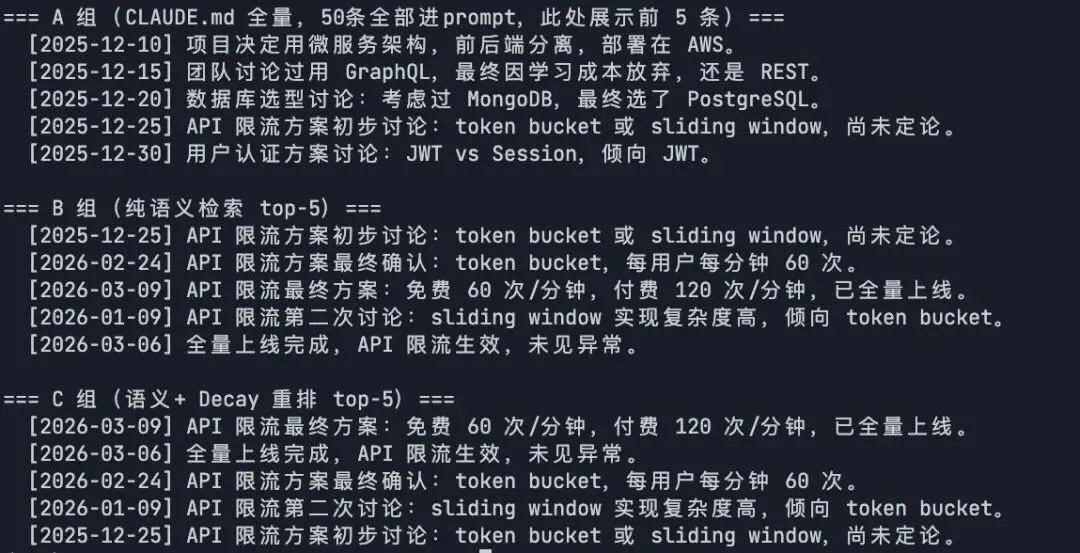
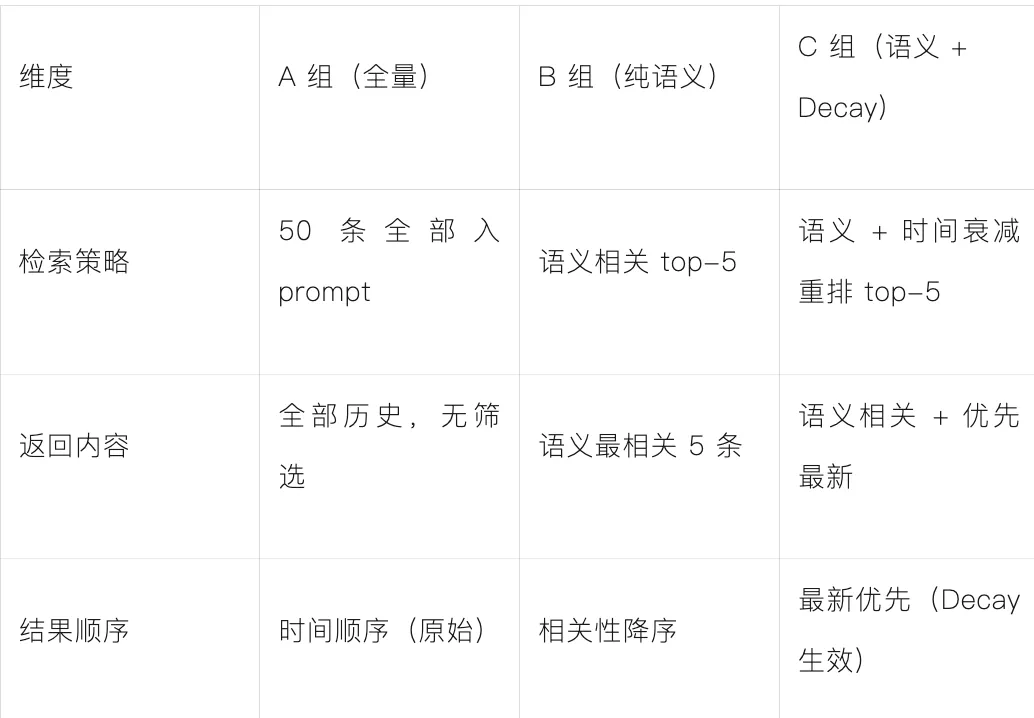
实验验证:三种检索方式对比,看Decay的实际效果
第一步:实验准备:环境搭建与数据模拟
wget https://github.com/milvus-io/milvus/releases/download/v2.6.11/milvus-standalone-docker-compose.yml -O docker-compose.ymldocker compose up -dpip install pymilvus openaiimport jsonimport timefrom datetime import datetime, timedeltafrom openai import OpenAIfrom pymilvus import MilvusClient, DataTypeclient = OpenAI()milvus = MilvusClient(uri="http://your-milvus-host:19530",user="root",password="your-password")COLLECTION_NAME = "nanoclaw_memory"if milvus.has_collection(COLLECTION_NAME):milvus.drop_collection(COLLECTION_NAME)schema = milvus.create_schema(auto_id=True, enable_dynamic_field=False)schema.add_field("id", DataType.INT64, is_primary=True)schema.add_field("text", DataType.VARCHAR, max_length=1000)schema.add_field("vector", DataType.FLOAT_VECTOR, dim=1536)schema.add_field("timestamp", DataType.INT64)schema.add_field("metadata", DataType.VARCHAR, max_length=500)milvus.create_collection(collection_name=COLLECTION_NAME, schema=schema)index_params = milvus.prepare_index_params()index_params.add_index(field_name="vector",index_type="HNSW",metric_type="COSINE",params={"M": 16, "efConstruction": 200})index_params.add_index(field_name="metadata",index_type="INVERTED",index_name="metadata_group_index",params={"json_path": "metadata[\"group\"]","json_cast_type": "varchar"})milvus.create_index(COLLECTION_NAME, index_params)milvus.load_collection(COLLECTION_NAME)# 50 条模拟记忆,时间跨度三个月now = datetime.now()memories = [{"text": "项目决定用微服务架构,前后端分离,部署在 AWS。", "days_ago": 90},{"text": "团队讨论过用 GraphQL,但最终因为学习成本放弃了,还是 REST。", "days_ago": 85},{"text": "数据库选型时考虑过 MongoDB,最终选了 PostgreSQL。", "days_ago": 80},{"text": "API 限流方案初步讨论:考虑 token bucket 或 sliding window。", "days_ago": 75},{"text": "用户认证方案讨论:JWT vs Session,倾向 JWT。", "days_ago": 70},{"text": "API 限流方案第二次讨论,sliding window 实现复杂度太高,倾向 token bucket。", "days_ago": 60},{"text": "前端框架选 React,状态管理用 Zustand 而不是 Redux。", "days_ago": 55},{"text": "CI/CD 用 GitHub Actions,部署脚本已经写好。", "days_ago": 50},{"text": "日志方案选 Datadog,已经接入。", "days_ago": 45},{"text": "API 网关用 Kong,限流插件测试中。", "days_ago": 40},{"text": "Kong 限流插件测试完成,性能符合预期,准备上线。", "days_ago": 30},{"text": "JWT 有效期定为 7 天,refresh token 有效期 30 天。", "days_ago": 28},{"text": "PostgreSQL 连接池大小定为 20,经过压测验证。", "days_ago": 25},{"text": "前端构建时间优化到 45 秒,用了 esbuild。", "days_ago": 22},{"text": "API 文档用 Swagger 自动生成,已经部署到内网。", "days_ago": 20},{"text": "API 限流方案最终确认:token bucket,每用户每分钟 60 次请求。", "days_ago": 14},{"text": "压测结果:QPS 峰值 2000,P99 延迟 120ms,符合预期。", "days_ago": 12},{"text": "上线前 checklist 完成,安全扫描通过。", "days_ago": 10},{"text": "灰度发布策略:先放 5% 流量,观察 24 小时。", "days_ago": 8},{"text": "监控告警阈值设置完成:错误率超 1% 触发 PagerDuty。", "days_ago": 7},{"text": "灰度发布顺利,错误率 0.02%,准备全量上线。", "days_ago": 5},{"text": "全量上线完成,API 限流生效,未见异常。", "days_ago": 4},{"text": "用户反馈限流太严,部分场景需要提高到 120 次/分钟。", "days_ago": 3},{"text": "和产品确认:付费用户限流提高到 120 次/分钟,免费用户保持 60 次。", "days_ago": 2},{"text": "API 限流最终方案更新:免费 60 次/分钟,付费 120 次/分钟,已上线。", "days_ago": 1},# ... 其余 25 条同理,覆盖其他话题]def get_embedding(text):resp = client.embeddings.create(input=text, model="text-embedding-3-small")return resp.data[0].embeddingprint("正在生成 embeddings...")data = []for i, m in enumerate(memories):ts = int((now - timedelta(days=m["days_ago"])).timestamp())data.append({"text": m["text"],"vector": get_embedding(m["text"]),"timestamp": ts,"metadata": json.dumps({"group": "project", "importance": "normal"}),})print(f" [{i+1}/{len(memories)}] 完成")milvus.insert(collection_name=COLLECTION_NAME, data=data)print(f"写入完成,共 {len(data)} 条")
import timefrom datetime import datetimefrom openai import OpenAIfrom pymilvus import MilvusClient, Function, FunctionTypeclient = OpenAI()milvus = MilvusClient(uri="http://your-milvus-host:19530",user="root",password="your-password")COLLECTION_NAME = "nanoclaw_memory"TEST_QUERY = "API 限流方案最后怎么定的?"def get_embedding(text):resp = client.embeddings.create(input=text, model="text-embedding-3-small")return resp.data[0].embeddingquery_vector = get_embedding(TEST_QUERY)# A 组:全量塞入(模拟 CLAUDE.md)all_memories = milvus.query(collection_name=COLLECTION_NAME,filter="",output_fields=["text", "timestamp"],limit=50)# B 组:纯语义检索 top-5results_b = milvus.search(collection_name=COLLECTION_NAME,data=[query_vector],limit=5,output_fields=["text", "timestamp"])[0]# C 组:语义检索 + Exponential Decay 重排decay_ranker = Function(name="memory_recency",input_field_names=["timestamp"],function_type=FunctionType.RERANK,params={"reranker": "decay","function": "exp","origin": int(time.time()),"offset": 24 * 3600, # 1 天内不打折"decay": 0.5, # 每过一个 scale,得分乘以 0.5"scale": 7 * 24 * 3600 # 7 天半衰期})results_c = milvus.search(collection_name=COLLECTION_NAME,data=[query_vector],limit=5,output_fields=["text", "timestamp"],ranker=decay_ranker)[0]print("=== A 组(CLAUDE.md 全量,50 条全部塞进 prompt,此处展示前 5 条)===")for m in all_memories[:5]:ts = datetime.fromtimestamp(m["timestamp"]).strftime("%Y-%m-%d")print(f" [{ts}] {m['text']}")print("\n=== B 组(纯语义检索 top-5)===")for r in results_b:ts = datetime.fromtimestamp(r["entity"]["timestamp"]).strftime("%Y-%m-%d")print(f" [{ts}] {r['entity']['text']}")print("\n=== C 组(语义 + Decay 重排 top-5)===")for r in results_c:ts = datetime.fromtimestamp(r["entity"]["timestamp"]).strftime("%Y-%m-%d")print(f" [{ts}] {r['entity']['text']}")
from openai import OpenAIfrom pymilvus import MilvusClientfrom pymilvus import Function, FunctionTypeimport timefrom datetime import datetimeclient = OpenAI()milvus = MilvusClient(uri="http://192.168.7.122:19530",user="root",password="Milvus")COLLECTION_NAME = "nanoclaw_memory"TEST_QUERY = "API 限流方案最后怎么定的?"def get_embedding(text):resp = client.embeddings.create(input=text, model="text-embedding-3-small")return resp.data[0].embeddingdef ask_agent(context, query):resp = client.chat.completions.create(model="gpt-5",messages=[{"role": "system", "content": f"你是一个项目助手,以下是你的记忆:\n\n{context}"},{"role": "user", "content": query}])return resp.choices[0].message.contentquery_vector = get_embedding(TEST_QUERY)# A 组上下文all_memories = milvus.query(collection_name=COLLECTION_NAME,filter="",output_fields=["text"],limit=50)context_a = "\n".join([m["text"] for m in all_memories])# B 组上下文results_b = milvus.search(collection_name=COLLECTION_NAME,data=[query_vector],limit=5,output_fields=["text"])[0]context_b = "\n".join([r["entity"]["text"] for r in results_b])# C 组上下文decay_ranker = Function(name="memory_recency",input_field_names=["timestamp"],function_type=FunctionType.RERANK,params={"reranker": "decay","function": "exp","origin": int(time.time()),"offset": 24 * 3600,"decay": 0.5,"scale": 7 * 24 * 3600})results_c = milvus.search(collection_name=COLLECTION_NAME,data=[query_vector],limit=5,output_fields=["text"],ranker=decay_ranker)[0]context_c = "\n".join([r["entity"]["text"] for r in results_c])print("=== Agent 回答对比 ===\n")print("【A 组 - CLAUDE.md 全量】")print(ask_agent(context_a, TEST_QUERY))print("\n【B 组 - 纯语义检索】")print(ask_agent(context_b, TEST_QUERY))print("\n【C 组 - 语义 + Decay】")print(ask_agent(context_c, TEST_QUERY))

“免费 60 次/分钟、付费 120 次/分钟,已全量上线,运行稳定。”
04
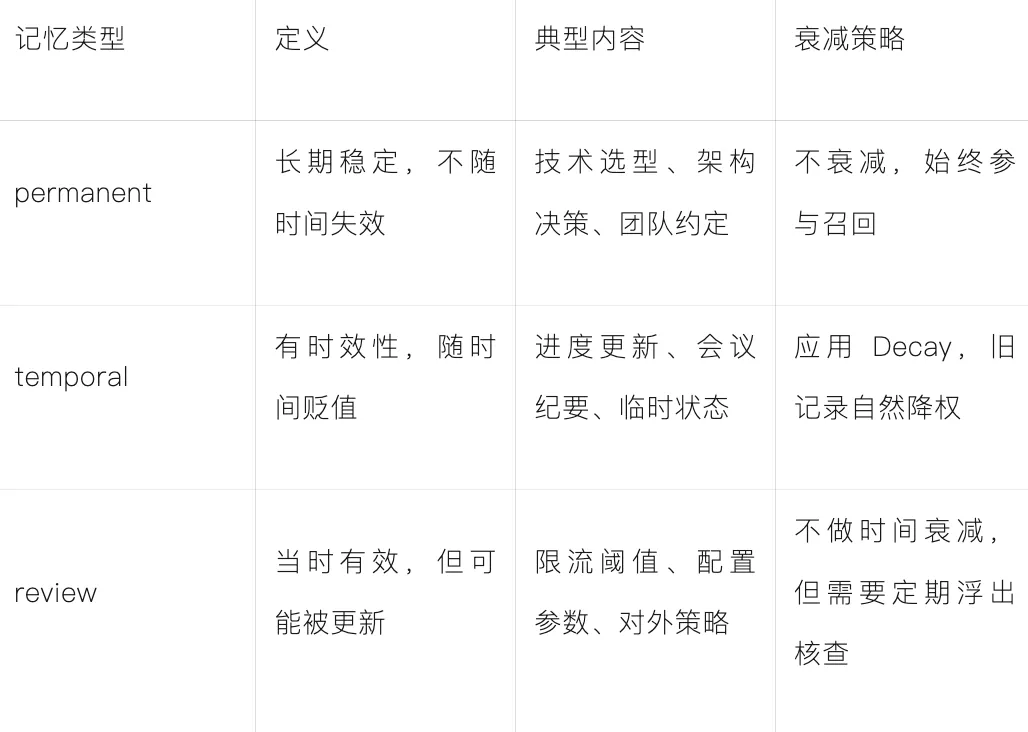
进阶优化:分类优先,Decay为辅,构建完整记忆生命周期
def classify_memory(text: str) -> str:"""对记忆文本做类型分类,返回 'permanent' | 'temporal' | 'review'"""resp = client.chat.completions.create(model="gpt-4o-mini",messages=[{"role": "system","content": ("你是一个项目记忆分类器,将输入文本归入以下三类之一,只输出分类名,不要解释:\n""- permanent:长期稳定的架构决策、技术选型、团队约定\n""- temporal:进度更新、临时状态、会议纪要(时效性强,过期无用)\n""- review:参数、阈值、对外策略(当前有效,但未来可能被修改,需定期核查)")},{"role": "user", "content": text}])result = resp.choices[0].message.content.strip().lower()return result if result in ("permanent", "temporal", "review") else "temporal"
Schema 里加一个字段:
schema.add_field("memory_type", DataType.VARCHAR, max_length=20)# 写入时:data.append({"text": m["text"],"vector": get_embedding(m["text"]),"timestamp": ts,"memory_type": classify_memory(m["text"]), # ← 新增"metadata": json.dumps({"group": "project"}),})
#---- 找最新决策(问"现在是什么状态")----# temporal类:应用 Decay,旧记录自动降权results_temporal = milvus.search(collection_name=COLLECTION_NAME,data=[query_vector],filter='memory_type == "temporal"',limit=3,output_fields=["text", "timestamp", "memory_type"],ranker=decay_ranker)[0]# review 类:不做 Decay,但优先返回最新的(它们是当前有效值)results_review = milvus.search(collection_name=COLLECTION_NAME,data=[query_vector],filter='memory_type == "review"',limit=2,output_fields=["text", "timestamp", "memory_type"])[0]# permanent 类:不做 Decay,语义相关就召回results_permanent = milvus.search(collection_name=COLLECTION_NAME,data=[query_vector],filter='memory_type == "permanent"',limit=2,output_fields=["text", "timestamp", "memory_type"])[0]#合并三组,按优先级组装promptcontext = "\n".join([*[r["entity"]["text"] for r in results_review], # 优先:当前参数*[r["entity"]["text"] for r in results_temporal], # 其次:近期状态*[r["entity"]["text"] for r in results_permanent], # 背景:长期决策])
# 每周一次,查出所有 review 类、超过 14 天未更新的记忆def fetch_stale_review_memories(days_threshold: int = 14):cutoff_ts = int((datetime.now() - timedelta(days=days_threshold)).timestamp())stale = milvus.query(collection_name=COLLECTION_NAME,filter=f'memory_type == "review" && timestamp < {cutoff_ts}',output_fields=["id", "text", "timestamp"],)return stalestale_memories = fetch_stale_review_memories()if stale_memories:summary = "\n".join([f"- [{datetime.fromtimestamp(m['timestamp']).strftime('%Y-%m-%d')}] {m['text']}"for m in stale_memories])# 推送给 Agent 或通知渠道,请求确认这些参数是否仍然有效ask_agent(context=summary,query="以上记录超过 14 天未更新,请逐条确认:是否仍然有效?如已变更请告知新值。")
-
permanent(长期记忆):写入后长期保留,检索时语义匹配即召回,不干扰最新决策; -
temporal(临时记忆):写入后随时间自动降权,减少噪音,过期后无需手动清理; -
review(待核查记忆):写入后定期浮出核查,确认有效则更新时间戳,无效则标记过期,避免错误。
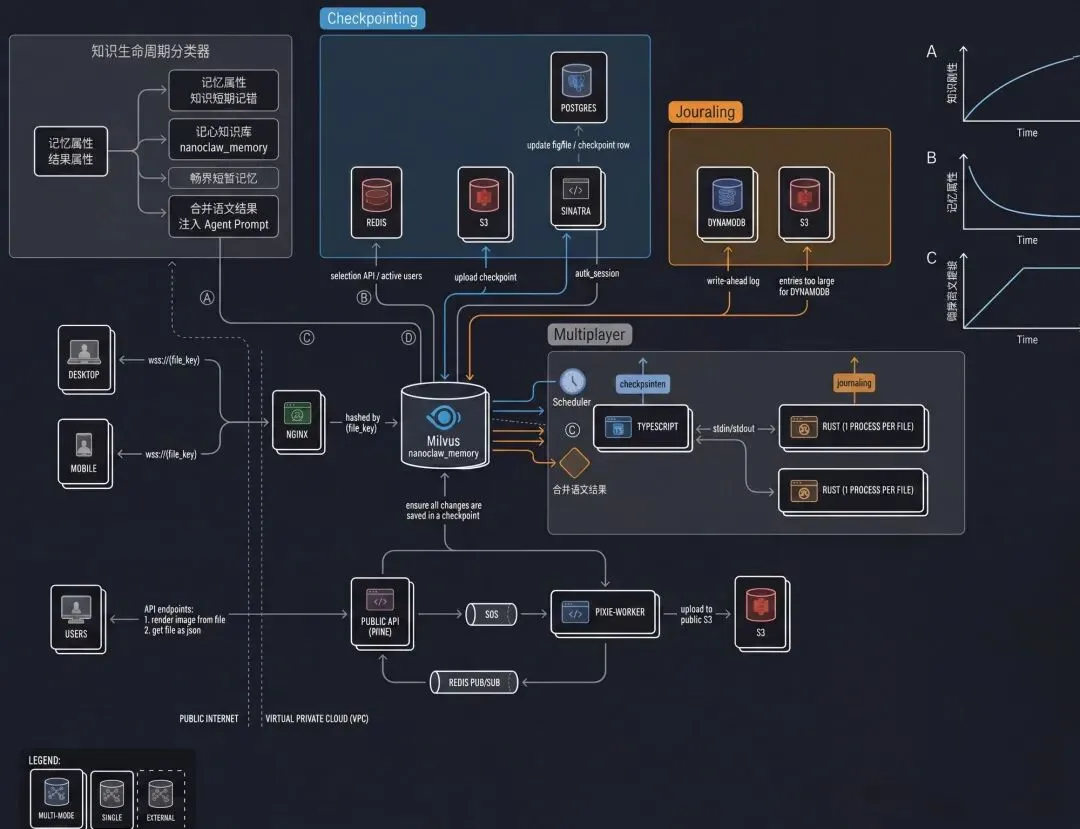
05
什么时候值得给OpenClaw做这样的优化?
作者介绍

Zilliz黄金写手:尹珉
阅读推荐 官宣:Zilliz Cloud&Milvus发布CLI工具与官方Skill,让AI Agent成为专业VDB运维与开发助手 Vector Graph RAG 开源!一套向量数据库同时搞定语义检索+RAG多跳 黄仁勋GTC演讲上,Milvus为什么能够站稳非结构化数据处理C位 用RAG的思路做agent知识管理,为什么跑不通

