 夜雨聆风
夜雨聆风





OCR只是表格解析的起点!xParse文档解析工具专治复杂表格,让RAG、Agent不再拿错数据
文档解析中的表格解析有多难?
OCR的终点,只是表格解析的起点!哪个模型在复杂的嵌套表格、超长跨页表格、多层表头这些上能很好的工作?
今天我们来聊下,在PDF文档解析中一个长期被低估的难题:表格解析。
目前OCR的准确率已经足够好了,但是能把图表里的字都认出来,不等于把表格理解清楚了。
很多人应该都遇到过以下场景:一份季度财报表格,上方是合并单元格的收入和成本两大类别,每个类别下方各对应Q1、Q2两列数据。
用户提问:Q2智能硬件成本是多少?解析系统把所有数值都识别对了,但下游的RAG检索后,返回的却是收入下面的那个Q2。
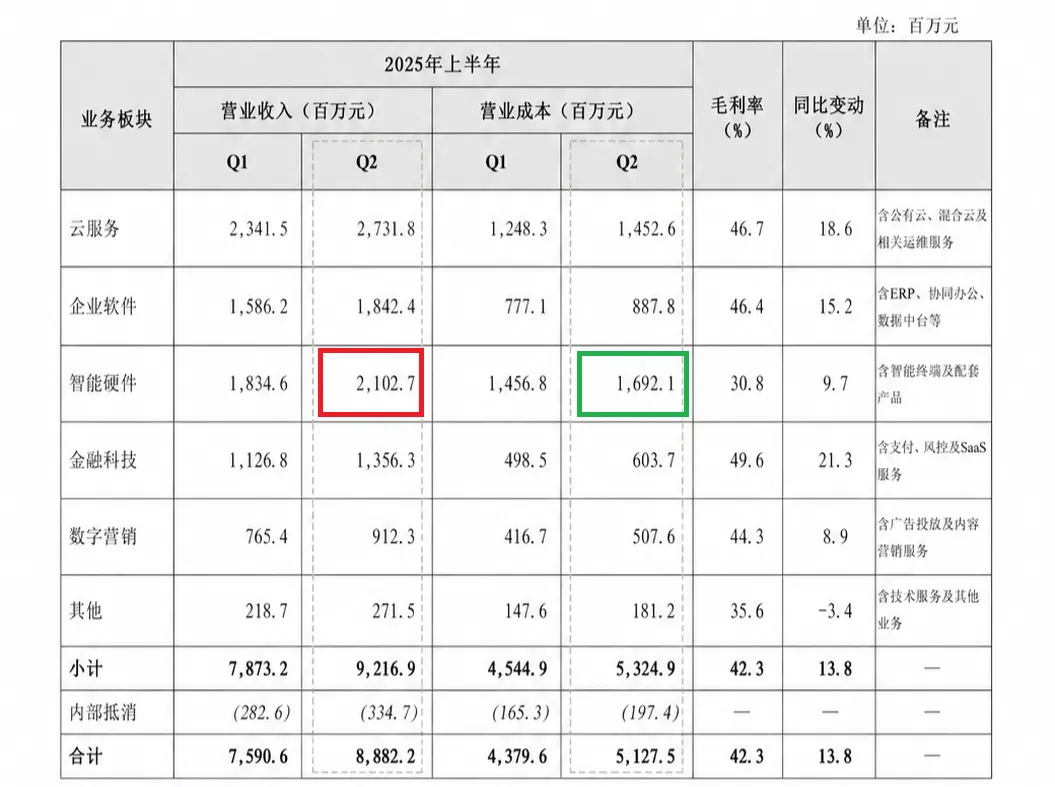
问题出在哪里?表头层级丢失了。因此除了识别文本内容外,要解决的根本问题是关系层面的,多级嵌套、跨页跨度、合并拆分单元格等一系列问题。
如果AI解析模型只完成了字符识别这一步,下游拿到的就不是有用的数据,它只是一堆失去归属关系的文本碎片。这些碎片在进入RAG、ETL、Agent等系统之后,会以各种意想不到的方式制造问题。
我们调研并实测了一批当前主流的解析模型,包括专精于表格数据提取的MinerU,适用于技术文档的Marker,针对复杂文本优化的PaddleOCR-VL等等,在复杂表格的结构还原上,最后选出了合合信息的TextIn xParse 。
最近,xParse 在上述各类表格的解析能力上又大幅提升了!大家可以直接薅2000页免费的测试额度,具体地址如下:
https://www.textin.com/market/detail/xparse?from=acgmk一、复杂表格解析到底难在哪?
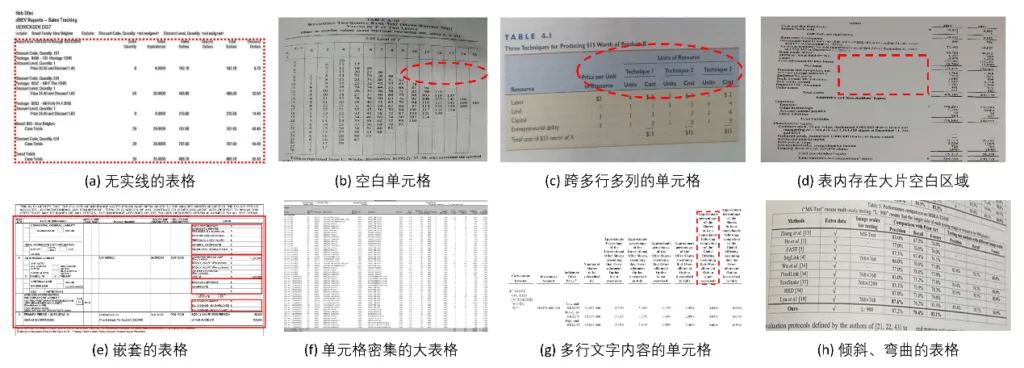
在真实文档里,复杂表格一般是指结构关系复杂,以下四种类型出现频率最高,也最容易暴露不同解析方案之间的差距。
类型一:多层表头与合并单元格
这是真实表格里最常见的一类。表头不止一行,存在父表头和子表头的层级关系,还有跨行或跨列的合并单元格来划分大的分组。
典型错误是父表头丢失、合并关系断裂,数据归属错位。很多模型为了套树形数据,只保留了文本顺序,没有恢复多层表头和行列关系。
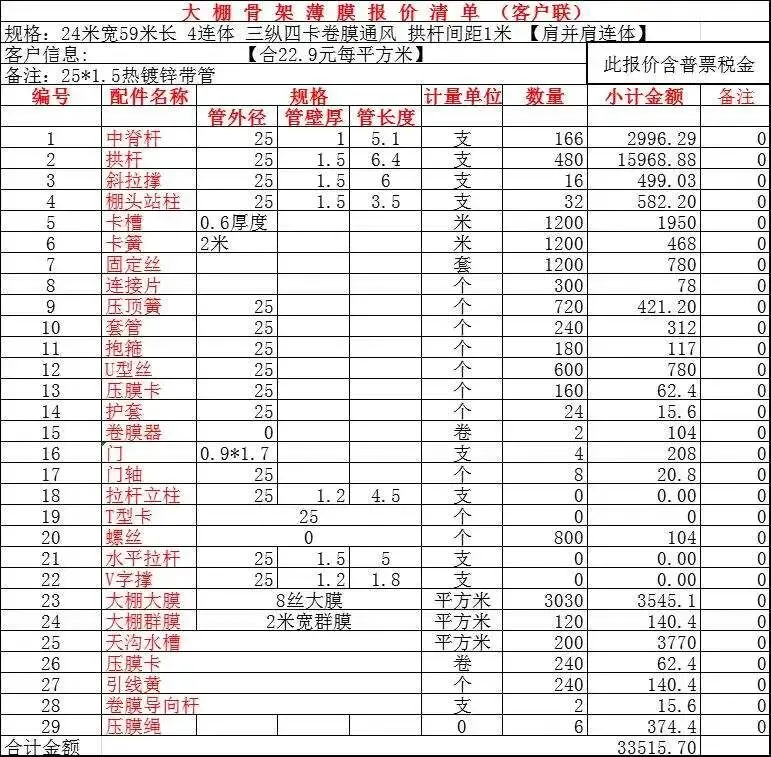
类型二:密集小字表
有些表格的行列数量极大,被压缩在一页A4纸里,单行文字的像素高度可能只有十几甚至几个像素。
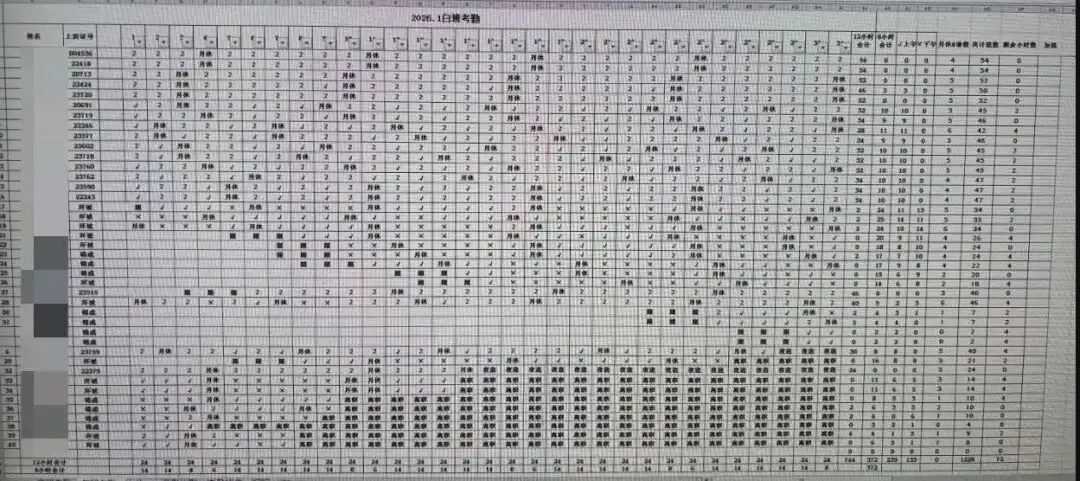
典型错误是漏字、错字、串行串列,甚至出现幻觉式补全。原因在于由于输入分辨率过大,当视觉Token大幅压缩时,信息就会丢失。
类型三:嵌套表格
嵌套表格就是表格里面还有表格,这类表格的关键不在识别出内外两张表,而在保留父子关系。

典型错误是内层表格被拆散成独立表格,父记录和子明细的关联关系丢失,甚至内层内容被混入外层表格的行列中。
类型四:跨页长表
企业文档里,一张表格从第一页延伸到第二页、第三页是极其常见的情况。后续页可能只保留了表格的续行,没有重复表头。模型就难以同时判断表格边界、表头继承、列宽对齐和跨页连续性。

典型错误是续页被当作新表,导致一张完整长表被打散;或者不该拼的表格被错误合并,不同业务含义的数据混在一起。
以上每一类问题,都不是OCR的字符识别出了问题,而是数据模型、分辨率上限、输出schema设计、状态管理等工程和架构层面的问题。表格解析真正需要的,不是更准的OCR,而是能从文档全局视角理解表格的模型。
二、解析错误在下游被无限放大
1. RAG:回答很流畅,答案却错了
RAG会根据检索结果生成回答,但如果解析阶段已经把表格的归属关系打断,模型面对的就是一堆离散的数值。即使它流畅地给出答案,大概率答案也是错的。
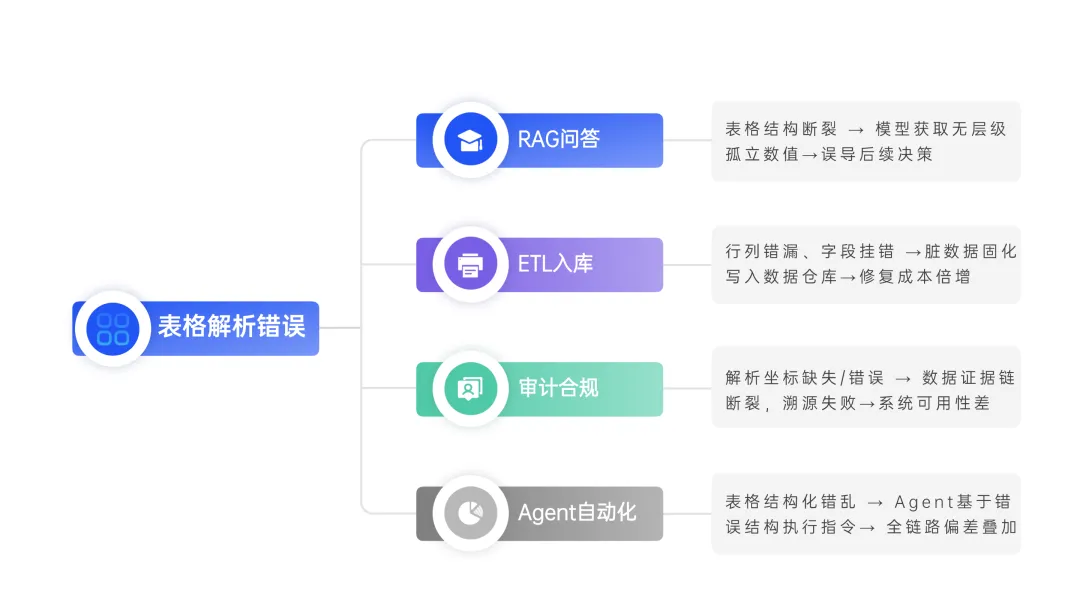
2. ETL:脏数据一旦落库,清洗成本指数级上升
ETL中字段映射关系出错,一旦进入数仓,问题就来了:下游报表要回刷,历史数据要重跑,所有消费方要重新通知。
3. Agent:错误的结构,正确的执行,灾难的结果
Agent需要的不是文本,是可操作的对象。假如解析给了它一个结构,但结构是错的,Agent会非常尽责地基于错误结构去执行。
4. 审计与合规:找不到源头的数字,等于没有数字
在需要证据链的场景里,一个数字如果没有精确的坐标,就无法被追溯、无法被验证、无法被采纳。
在上述几个下游任务,真正决定表格数据是否可用的,是逻辑结构重建、语义关系映射、内容信息还原三个层级。让下游系统拿到的是可理解、可追溯、可直接消费的数据,而不是需要二次猜测的文本碎片。
后来我们在 TextIn xParse 产品里看到了与这套标准几乎完全对齐的能力架构。
三、用复杂表格,来真实的测试
评估一个解析方案最好的方式,不是看它的评测报告,而是拿你自己那张最头疼的表格,上去跑一次。
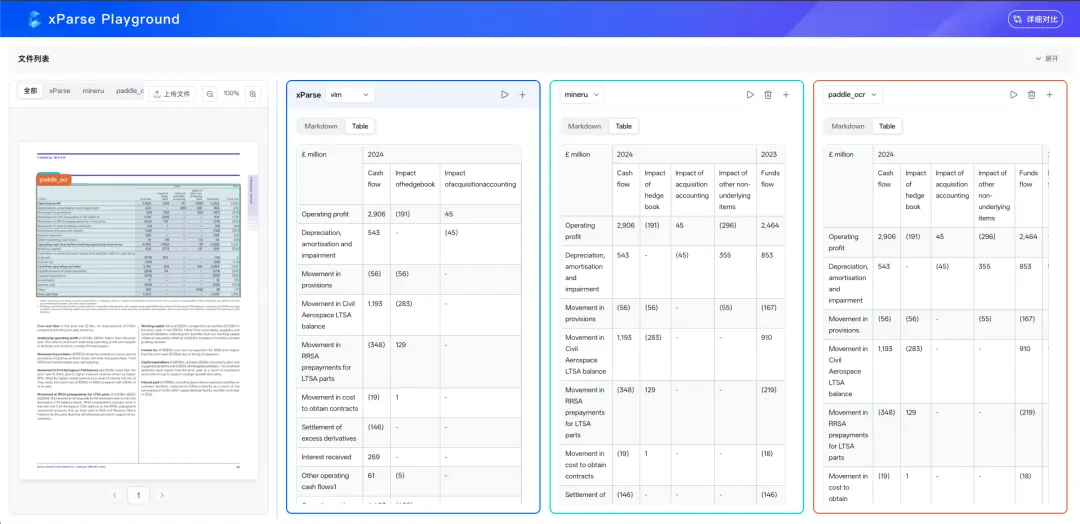
xParse Playground 支持上传一张复杂表格,并同时对比多个解析方案的输出结果。同一张表,谁还原了结构、谁丢失了层级、谁出现了归属偏差,放在一起,高下立判。
https://www.textin.com/market/detail/xparse?from=acgmk上述在线地址,或者阅读原文可直接薅2000页免费的测试额度,用你最棘手的那张复杂表格真实测一次吧。
想涨知识,点击下方卡片,关注码科智能!
点个“小爱心”吧
