在日常办公Excel数据处理中,我们一定遇到这样的困扰:
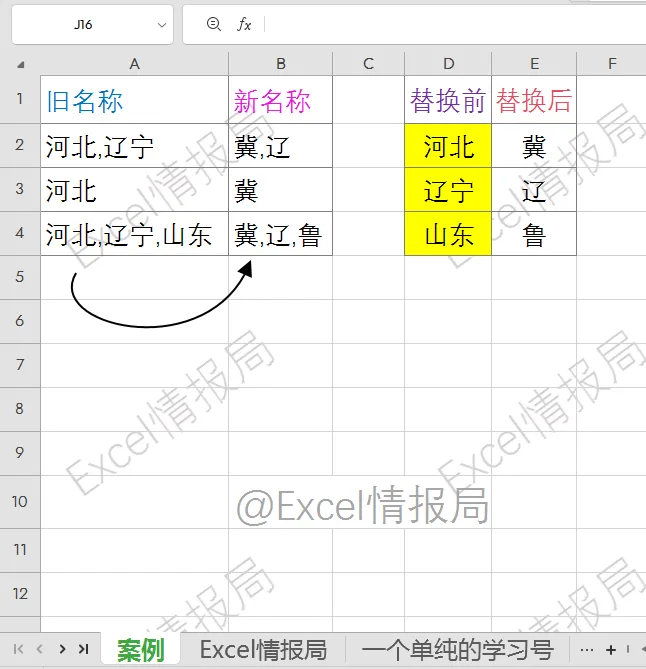
一份包含成百上千条记录的A列客户名单,需要将其中所有的省份全称,比如如”河北省”、”辽宁省”等统一替换为简称”冀”、”辽”。或者是在大量的产品目录中,需要将几十个旧型号代码批量更新为新代码?
我们都知道在WPS表格中,有一个SUBSTITUTES函数能轻松实现的批量替换功能。
但是这个SUBSTITUTES函数是WPS表格的专属函数,在微软Excel中是不能够使用的。
所以这个问题在微软Excel中却成了令人望而生畏的层层嵌套:每个替换都需要一个独立的SUBSTITUTE单个内容替换函数,三五个替换还能勉强应付,一旦需要替换十几个甚至几十个词汇,公式的长度就会失控膨胀,维护起来更是噩梦一场。这就像是用最原始的工具去完成现代化的精密作业,效率低且容易出错。
但是今天,这个困扰将成为历史。我们惊喜的发现,通过REDUCE与SUBSTITUTE函数的巧妙结合,目前使用微软Excel的小伙伴们终于也能体验到与WPS的SUBSTITUTES函数相媲美的便捷的批量替换功能了!
这不仅仅是函数组合用法的创新,更是在Excel中实现高效批量替换处理的革命性突破。无论我们有多少替换需求,一个简单的公式就能全部搞定,下面让我们一起学习并体会这条公式吧!
我们先来复习一下WPS专属的SUBSTITUTES批量替换函数。
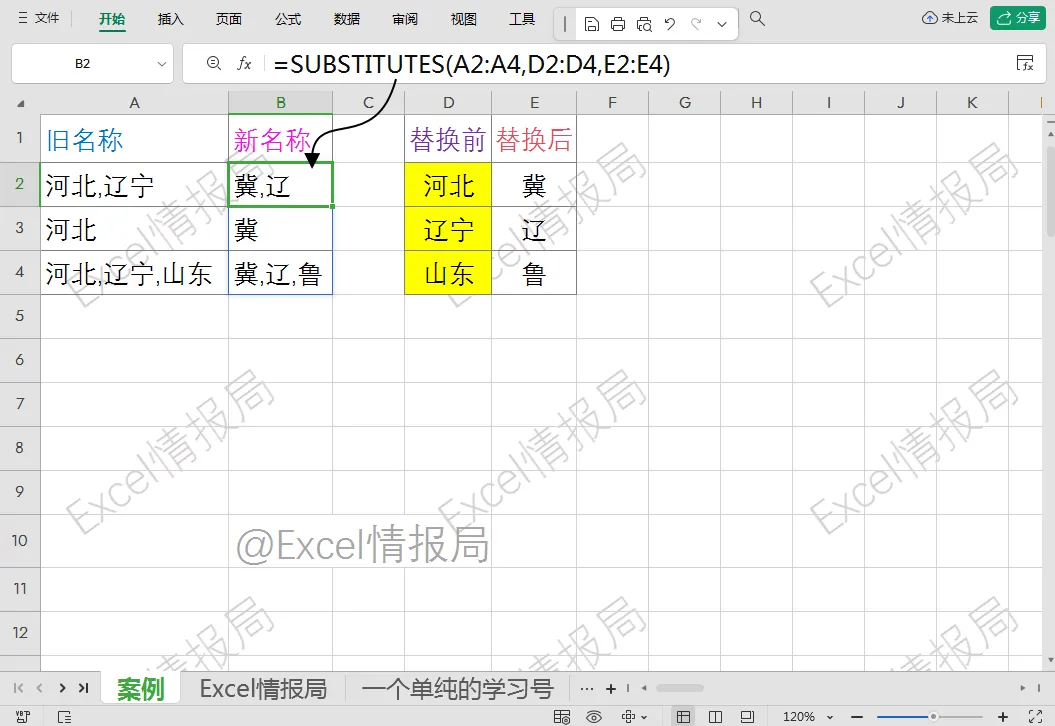
=SUBSTITUTES(A2:A4,D2:D4,E2:E4)
SUBSTITUTES(原始文本区域, 查找内容区域, 替换为区域)
①原始文本区域 (A2:A4):指定需要被处理的原始数据范围。
②查找内容区域 (D2:D4):指定一个列表,包含所有需要被查找并替换掉的“旧文本”。
③替换为区域 (E2:E4):指定一个与查找列表一一对应的列表,包含各自对应的“新文本”。
SUBSTITUTES函数会自动的、循环的对A2:A4中的每一个单元格,依次应用D2:D4和E2:E4中定义的所有替换规则。
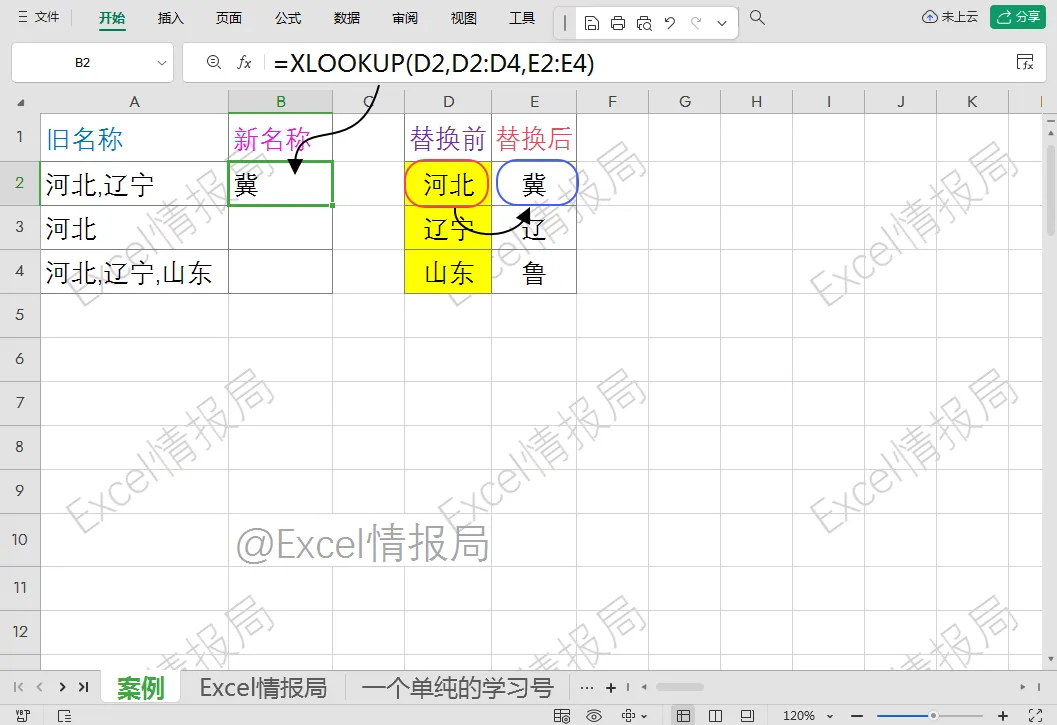
=XLOOKUP(D2,D2:D4,E2:E4)
D2:要查找的值(当前查找值“河北”)
我们在查找范围D2:D4中精确匹配当前查找值D2“河北”,返回对应的替换值E2“冀”。
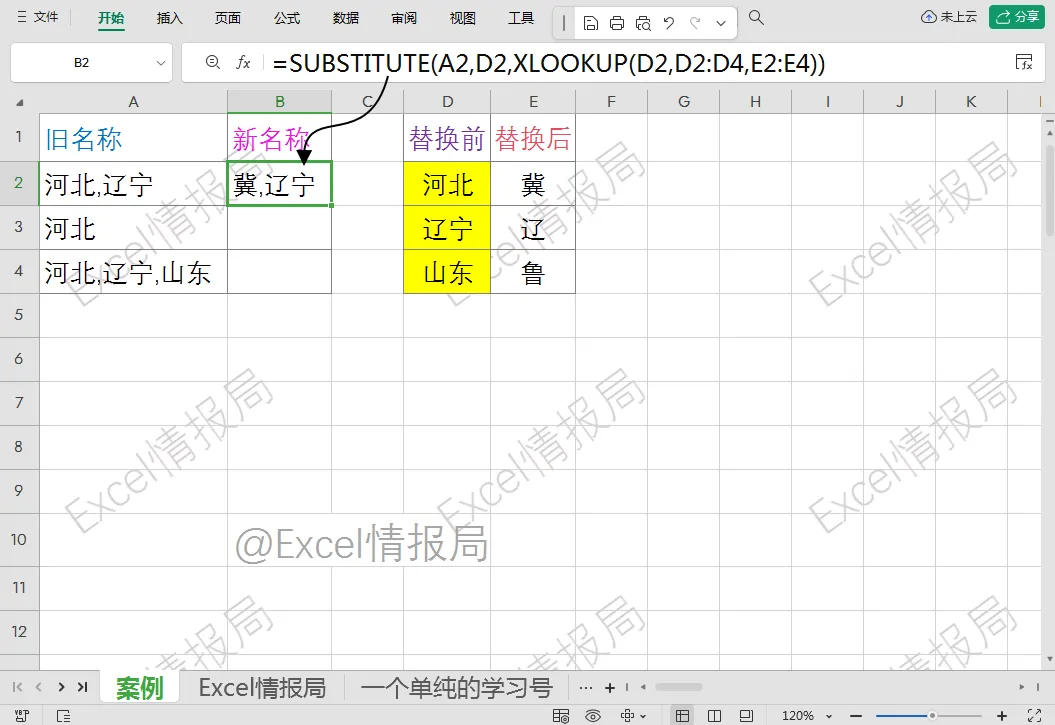
②使用substitute单值替换函数执行文本替换:
=SUBSTITUTE(A2,D2,XLOOKUP(D2,D2:D4,E2:E4))
A2:指定需要被处理的原始数据范围
SUBSTITUTE函数将A2中的文本“河北”替换为XLOOKUP找到的值“冀”。
此时,对于A2单元格值“河北, 辽宁”来讲,我们只是进行了单个内容“河北→冀”的替换,如果想要实现批量替换的话,以前只能通过重复的嵌套substitute函数来实现,假如有上百个内容需要替换时,这样做就不太乐观了。
不过上面这个xlookup+substitute单个内容替换逻辑是有用的。我们下面构造lambda逻辑值会用到,我们拭目以待。
这时候,我们就可以利用reduce函数可遍历和能累积的特性,构造能让substitute单条件替换转批量替换的必要条件。
=reduce(A2, 遍历区域, lambda定义的累积器x与当前值y的逻辑)
=reduce(A2, D2:D4, lambda定义的累积器x与当前值y的逻辑)
用遍历区域D2:D4中当前查找值“全称”y在对照表中找到对应的替换值“简称”,然后将上次累积的替换结果x中的所有“全称”y替换为这个对应的替换值“简称”,并返回替换后的新累积替换结果x。
②lambda(累积值x, 当前值y, 累积值x与当前值y的计算式)
我们先以待处理的字符串A2为例,并作为初始值进行讲解:
XLOOKUP(“河北”, D2:D4, E2:E4) 返回 “冀”
SUBSTITUTE(“河北,辽宁”, “河北”, “冀”) 返回 “冀,辽宁”
XLOOKUP(“辽宁”, D2:D4, E2:E4) 返回 “辽”
SUBSTITUTE(“冀,辽宁”, “辽宁”, “辽”) 返回 “冀,辽”
XLOOKUP(“山东”, D2:D4, E2:E4) 返回 “鲁”
SUBSTITUTE(“冀,辽”, “山东”, “鲁”) 返回 “冀,辽”(因为没有”山东”,所以不变)
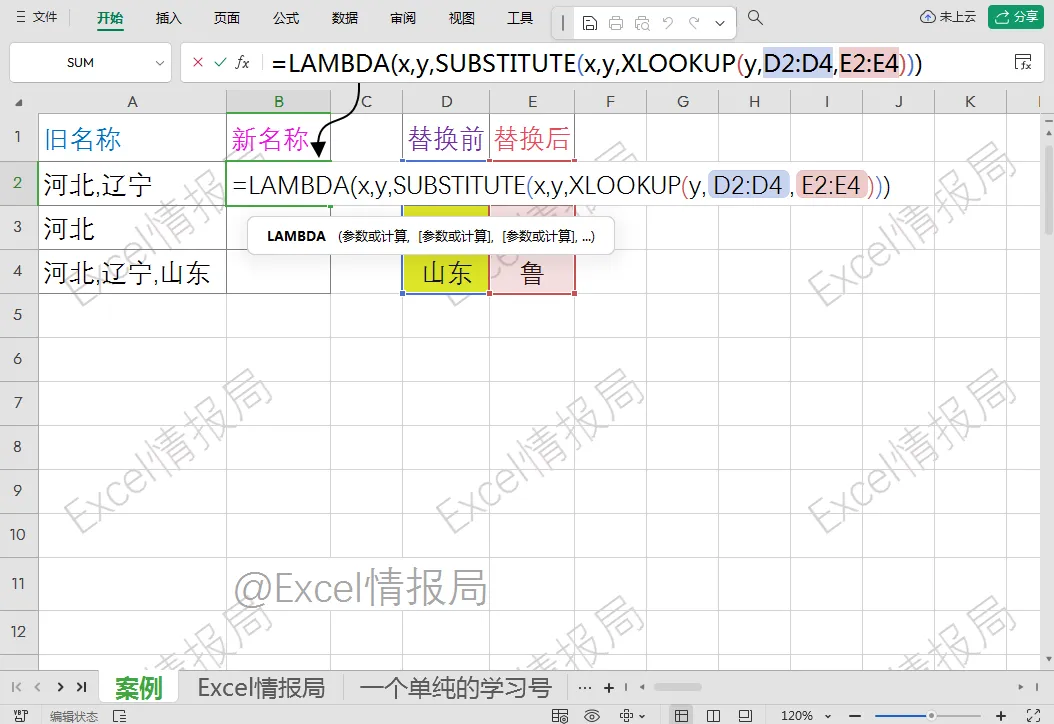
此时我们用lambda构建好了substitute进行批量替换的封装逻辑:
=lambda(x,y,SUBSTITUTE(x,y,XLOOKUP(y,D2:D4,E2:E4)))
x:累积值(当前累积的替换后的文本,随着迭代不断更新)
xlookup(y, D2:D4, E2:E4)
在查找范围中精确匹配当前查找值,返回对应的替换值。
substitute(x, y, xlookup(…))
将累积值x中的文本y替换为xlookup找到的值。
最后套上reduce函数的外壳,驱动lambda进行遍历和累积:
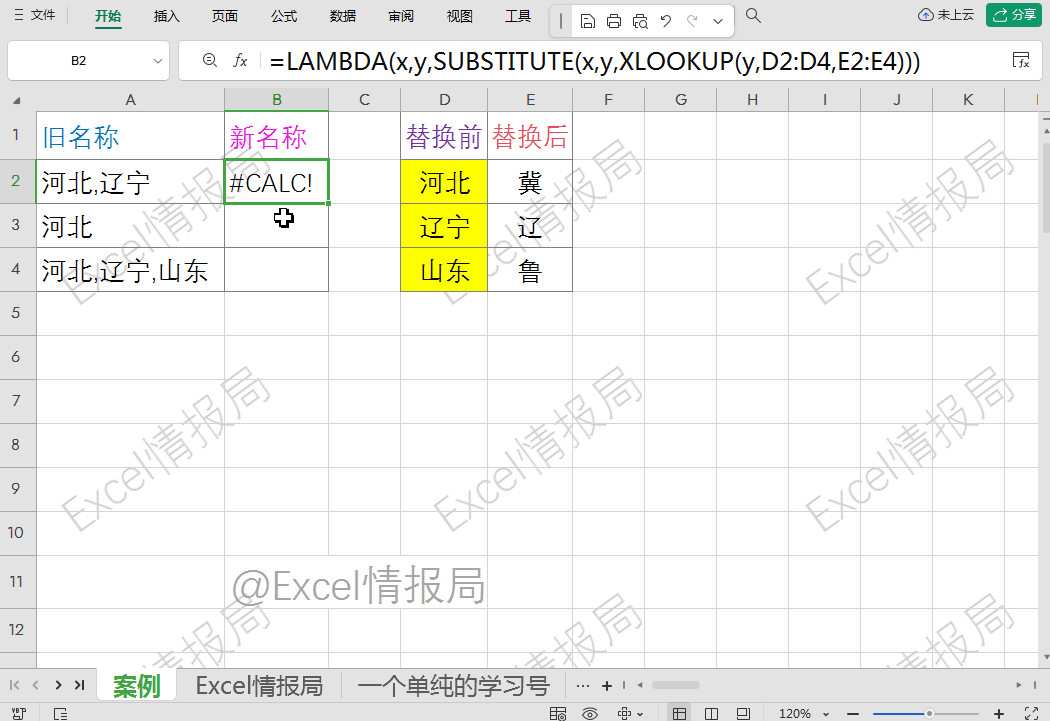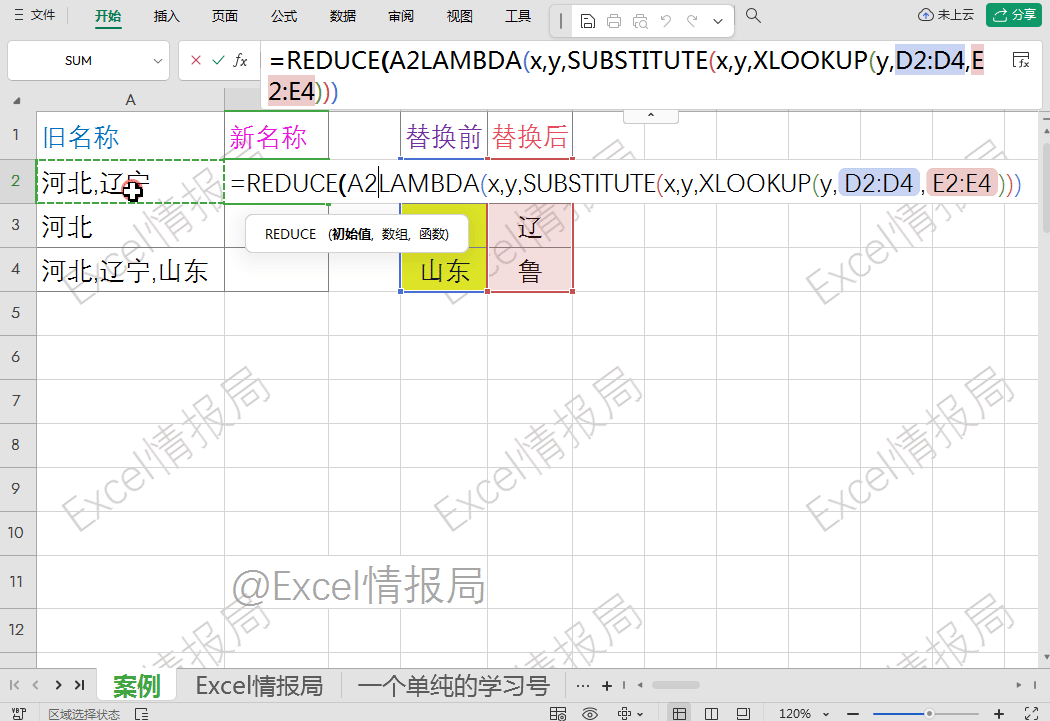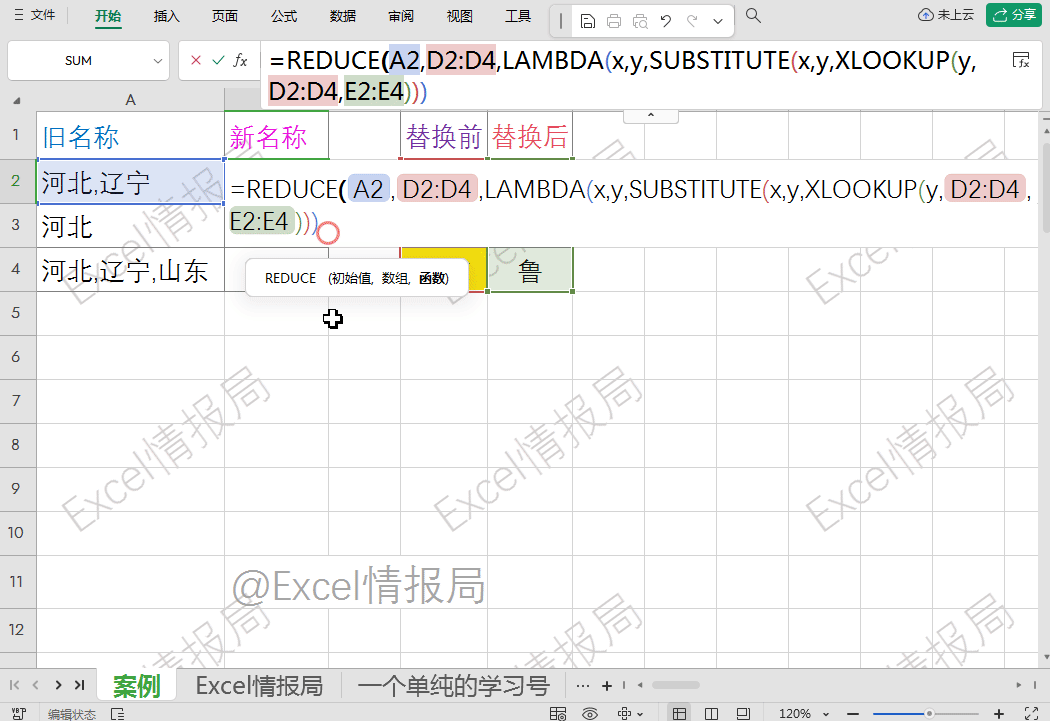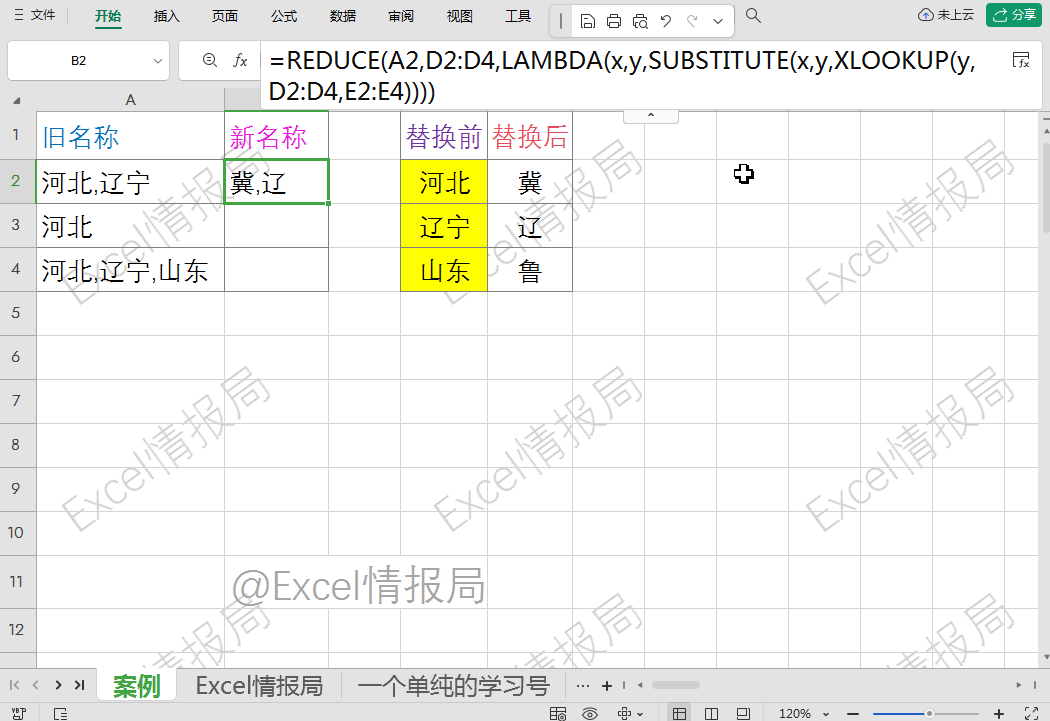
=reduce(A2,D2:D4,LAMBDA(x,y,SUBSTITUTE(x,y,XLOOKUP(y,D2:D4,E2:E4))))
reduce函数通过遍历D2:D4中的每个查找值,对A2文本进行连续替换,最终实现批量替换效果。
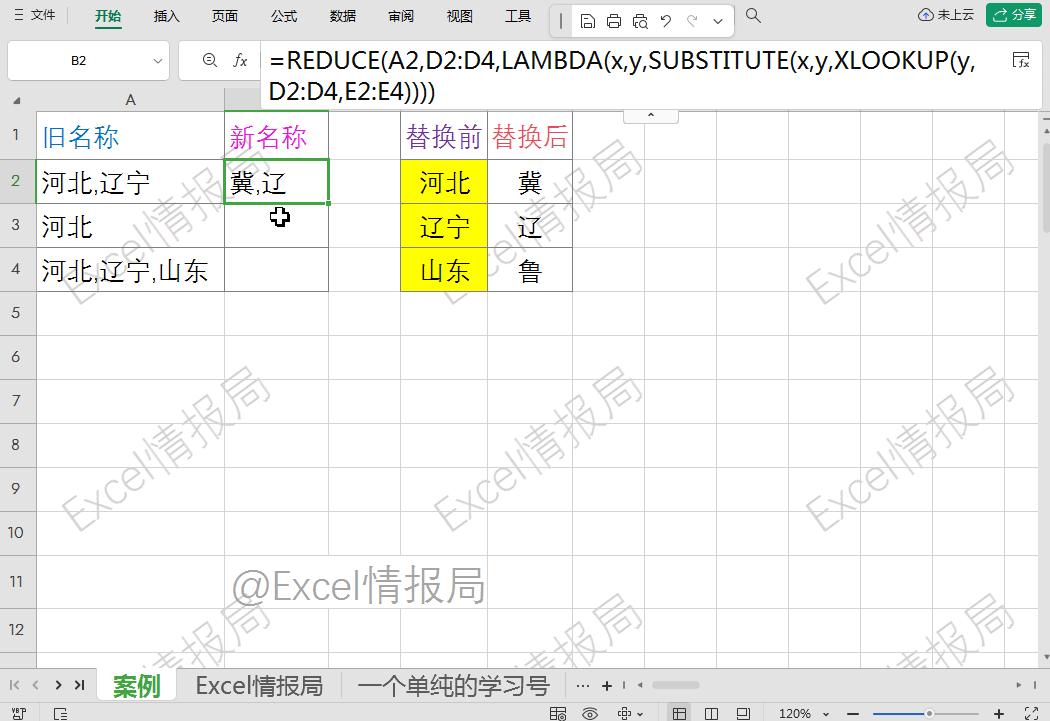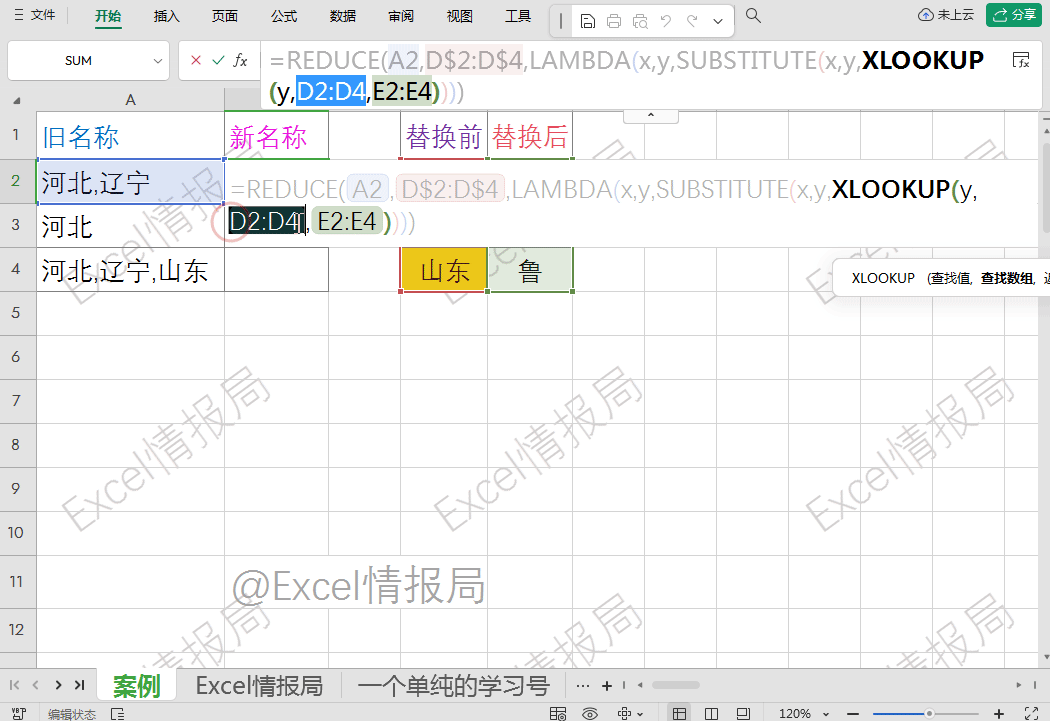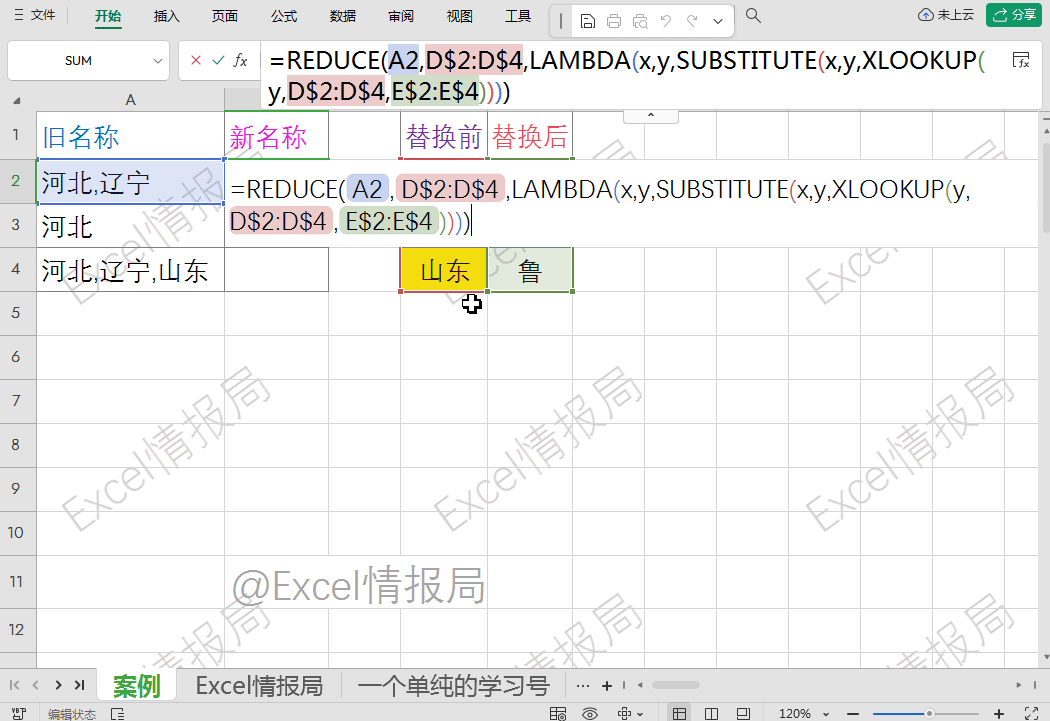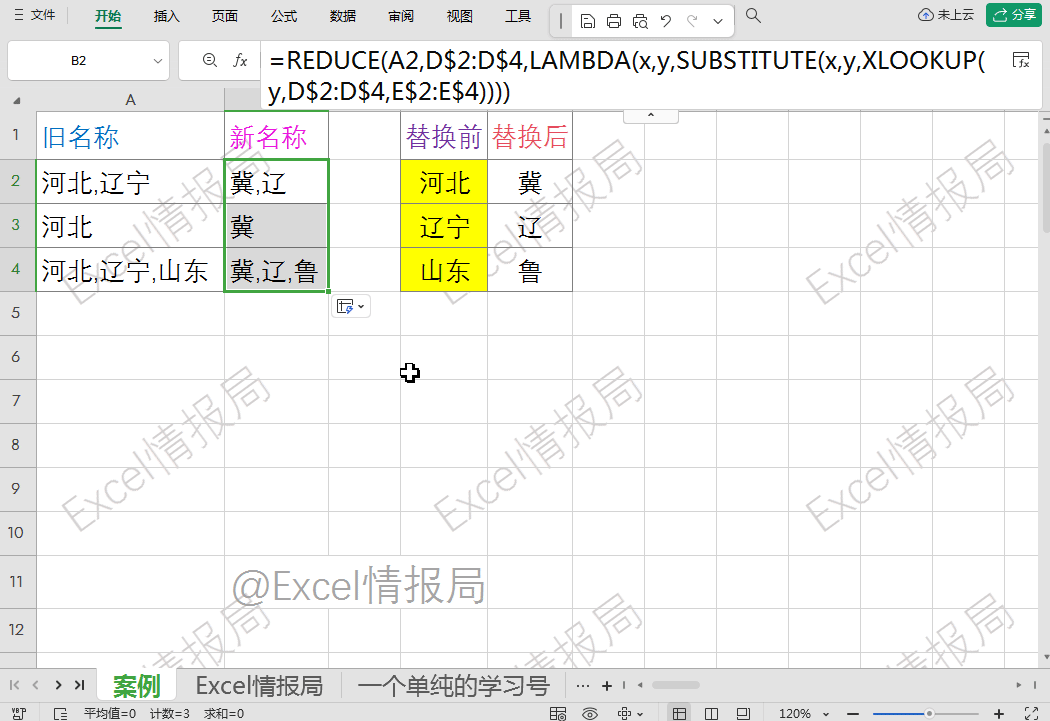
对D$2:D$4和E$2:E$4加上混合引用(即锁行不锁列),绝对固定替换规则表的行范围:
=REDUCE(A2,D$2:D$4,LAMBDA(x,y,SUBSTITUTE(x,y,XLOOKUP(y,D$2:D$4,E$2:E$4))))
因为我们要通过下拉填充公式的方式,让reduce的第一参数初始值依次处理A2:A4:
①reduce(A2,D$2:D$4,LAMBDA(x,y,SUBSTITUTE(x,y,XLOOKUP(y,D$2:D$4,E$2:E$4))))
②reduce(A3,D$2:D$4,LAMBDA(x,y,SUBSTITUTE(x,y,XLOOKUP(y,D$2:D$4,E$2:E$4))))
③reduce(A4,D$2:D$4,LAMBDA(x,y,SUBSTITUTE(x,y,XLOOKUP(y,D$2:D$4,E$2:E$4))))
这样当公式向下填充到其他行时,规则表的位置不会跟着改变,确保reduce的A2:A4的每个初始值都依据同一套、完整的规则进行替换。如果不用$锁定,下拉时范围会错位,导致替换错误或遗漏规则。
学习Excel/如果你没有天赋/那就一直重复/当你快到本能反应的时候/你的重复就是别人眼中的天赋/冲破捆绑/展翅翱翔/回顾关键内容/善用图片表达/学会建立联系/拓展深度广度/浓缩关键概念/应用到行动中/善于归纳总结/尝试进行分享/
 夜雨聆风
夜雨聆风