 夜雨聆风
夜雨聆风





一次完整的 AI 辅助编程实战:从设计、落库到工程落地(图文)
今天想记录一个比较完整的 AI 辅助编程场景。
这次事情本身不算大,核心目标是在一个基于 FastAPI 的普通业务系统里,补上一套统一的后台异步任务机制,同时支持两类需求:一类是按时间规则自动触发的计划任务,另一类是用户发起后立即进入后台执行的异步任务,例如导出、导入这类典型场景。
单看需求,其实并不复杂。但真正开始做的时候,会发现这件事不是只写几个接口、起一个调度器就够了。它至少包含几个层面:先把设计想清楚,再在现有代码库里落地,再把过程中形成的规则沉淀下来,最后还要用测试把核心链路闭环。
这次我基本是让 ChatGPT 和 Copilot 分工协作来完成这件事。回头看,这个过程里有一些做法,我觉得是值得借鉴的。
一、先不要急着写代码,先让 AI 把设计问题讲清楚
我一开始没有直接让 Copilot 在代码库里动手,而是先把问题放到 ChatGPT 里讨论设计。
我的原始需求很直接,大意就是:在一个项目中,需要同时支持两类后台任务。
第一类是计划任务,例如按 cron 或固定频率执行的定时数据同步。第二类是即时异步任务,例如用户点击导出之后,后台立即开始执行,前端轮询进度,完成后再下载结果。
同时,这两类任务都需要统一的状态查询能力,包括当前是否执行中、执行进度、进度描述、最终成功还是失败,以及成功后的结果信息和失败后的错误信息。
我当时的直觉是:这件事是不是可以直接基于 APScheduler + asyncio,设计一个统一的 Service 来处理。
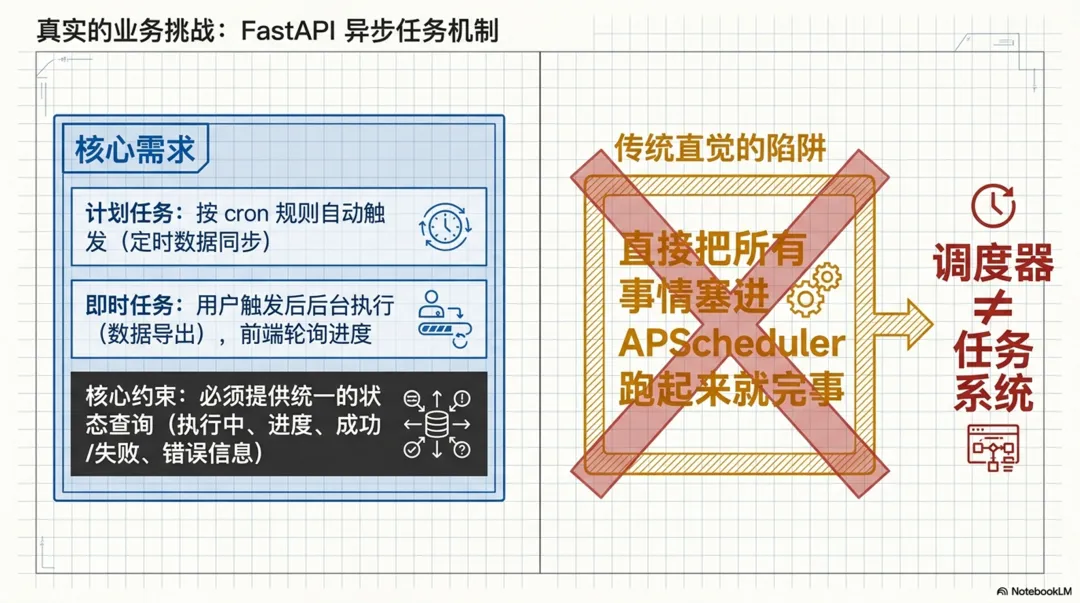
这个问题抛给 ChatGPT 之后,AI 并没有顺着“把所有事情都塞进 APScheduler”这个方向直接往下写,而是先把问题拆开了。
它给出的核心判断是:这两类需求本质上都属于后台任务,但统一的重点不是把所有任务都交给 APScheduler,而是统一任务定义、任务状态、任务进度、任务结果和查询方式。
这个判断我认为很关键。
因为很多时候,人一看到“定时任务”和“异步任务”,很容易直接进入技术组件层面,开始讨论调度器、线程池、队列,结果反而把真正应该统一的东西忽略了。
从设计上看,这个场景里真正要统一的,其实是几件事:统一任务定义、统一任务实例管理、统一状态与进度模型、统一前后端查询接口。
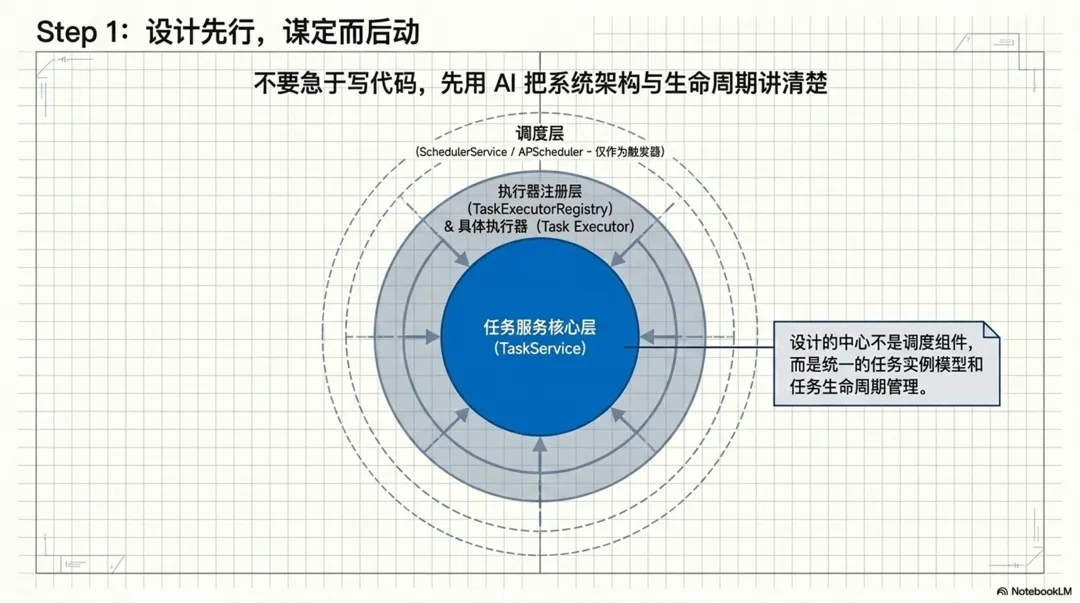
也正是在这个基础上,ChatGPT 给我整理出了一套 4 层设计思路:调度、任务服务、执行器注册、具体执行器。后面形成正式设计时,核心模块进一步明确为 SchedulerService、TaskService、TaskExecutorRegistry 和具体 Task Executor。整个设计的中心,不是某个调度组件,而是统一的任务实例模型和任务生命周期管理。
这一步的价值,不在于 AI 给了多少代码,而在于它先把问题讲清楚了。
二、先把方案收敛到适合当前阶段,而不是一上来就做成大平台
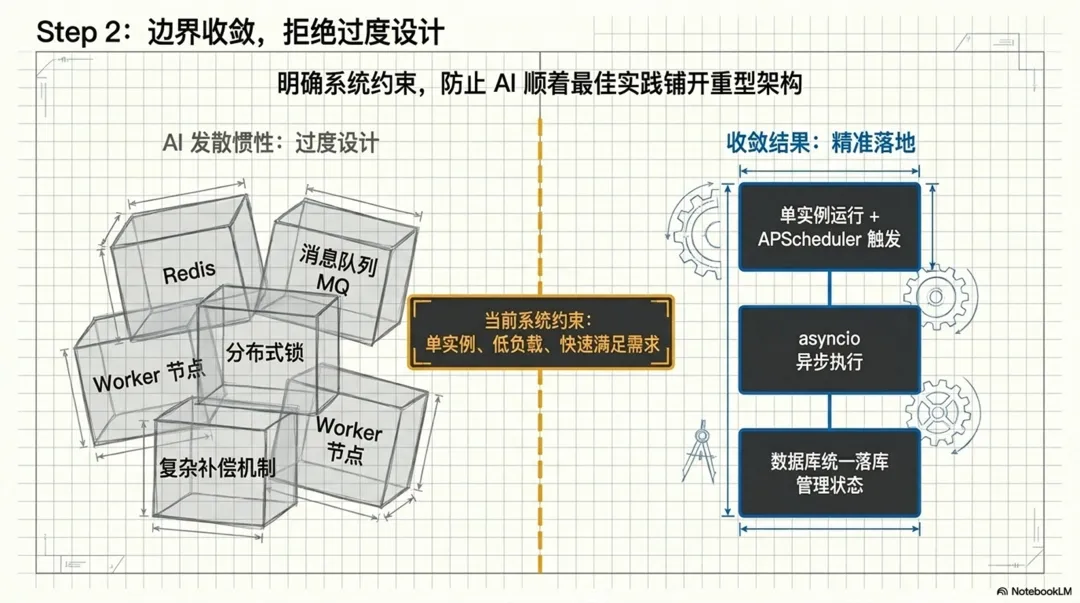
在第一轮讨论之后,我又补充了一句很重要的话:我现在这个系统还是个小系统,单例运行,负载不大,不需要一上来就做成很宏大的平台。设计要完整,但实现要适度,重点是先满足当前需求。
这个补充非常重要。
因为很多 AI 生成的技术方案,往往结构上没有问题,但很容易过度设计。你如果不给它明确边界,它会顺着“最佳实践”的惯性,把 Redis、消息队列、分布式锁、Worker、补偿机制、高可用全给你铺开。
但现实中,很多业务系统根本不需要一上来就这样。
于是后续的设计,就被收敛到了一个非常适合当前阶段的方案:系统单实例运行,不引入复杂消息队列,APScheduler 负责计划任务触发,asyncio.create_task() 负责当前阶段的异步执行,所有任务统一落到数据库中的任务实例表,前端统一通过任务查询接口拿状态和结果。这也正是那份《统一后台任务机制设计说明(阶段一)》的边界设定。
这份设计文档里把设计目标、总体思路、核心模块、表结构、状态机、执行流程、错误处理、应用启停补偿、后续演进方向都写完整了。尤其是其中有一个定位,我认为非常关键:
APScheduler 只负责触发,不负责完整任务系统。真正的中心是任务实例和 TaskService。
这个定位一旦清楚,很多后续设计都会自然变得顺畅:计划任务只是触发方式不同;导出任务、导入任务只是业务形态不同;但最终都要落到统一的任务实例模型里去管理。文档中也明确把导出、导入、计划同步这三类场景统一纳入同一套机制。
三、设计文档不是结束,而是后续工程实现的依据
很多团队做设计,最大的问题不是没有设计,而是设计和实现脱节。
文档写完了放在那里,后面真正开发的时候,大家还是各写各的,最后代码和文档完全两回事。这样设计文档就失去了真正的价值。
这次我没有把设计文档当成一个归档材料,而是把它直接作为后续工程实现的依据,进入第二阶段:在现有代码库中落地。
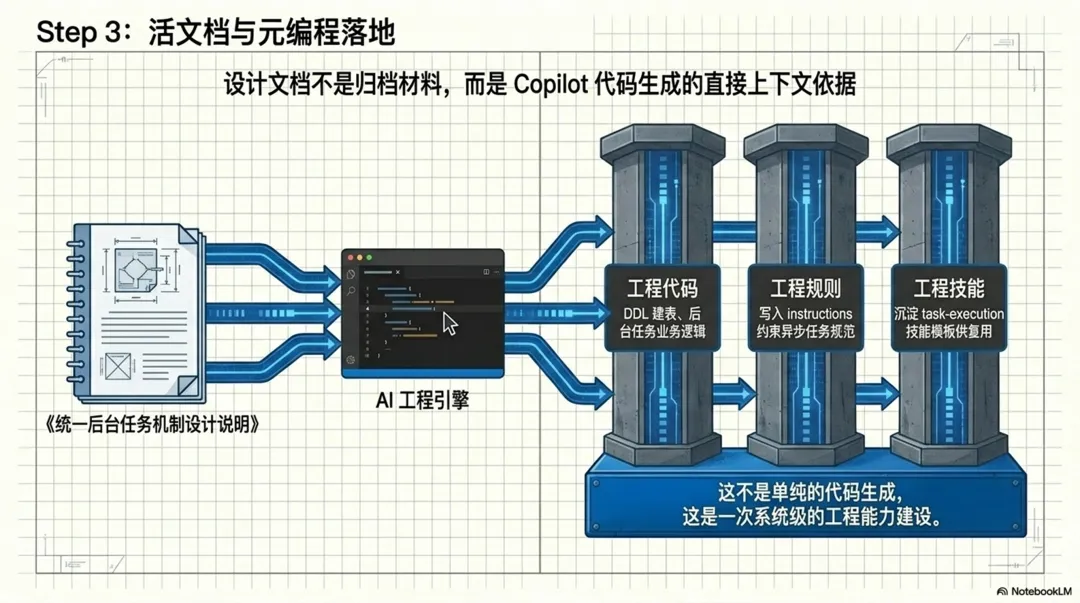
我用的是 VS Code,把这份设计说明文件直接加到上下文里,然后给 Copilot 一个非常明确的任务:参考这个设计方案,在当前系统代码基础上实现后台任务机制;同时把与这套设计相关的后续编码规范补充到 instructions 里;再把新增异步任务时需要复用的方法整理成 skill。
这一步我觉得是 AI 辅助开发里很重要的一个习惯:
不要只让 AI 产出代码,还要让它把这次实现背后的规则也一起沉淀下来。
因为真正拖慢后续开发效率的,通常不是少写了几百行代码,而是每次新增类似能力时,都要重新理解项目结构、重新摸清约束、重新推断实现风格。
这次 Copilot 在实现过程中,按设计说明完成了几类工作:
一、实现后台任务机制本身。二、根据设计中的 DDL 建好数据表。三、在 copilot.instructions.md 中补充异步任务相关规则。四、新增 async-task-execution 这个 skill,用于后续添加新的任务执行函数。
从结果上看,这就不是一次单纯的代码生成,而是一次工程能力建设。
四、AI 不是放在旁边自动跑完,而是人在过程中持续检查、观察和修正
这一点我觉得尤其值得讲。
现在很多人提 AI 辅助编程,理解还是停留在“把需求扔给 AI,然后等它写完”。但真正高质量的协作过程,并不是这样。
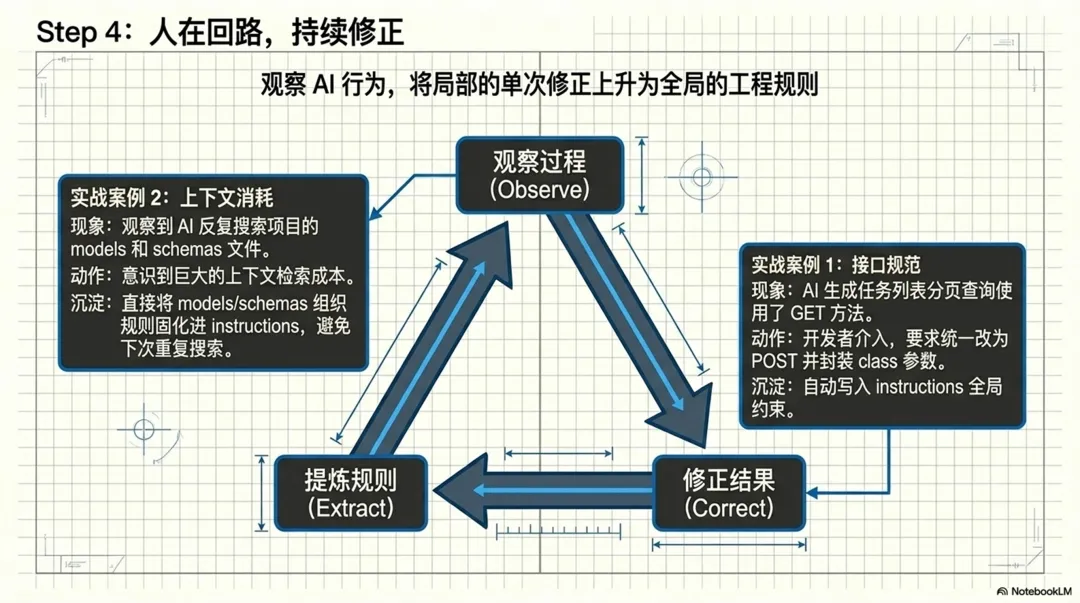
这次我在和 Copilot 协作的时候,实际上做了两件事:一类是对生成结果进行检查和修正,另一类是观察它在生成过程中的行为,并把可优化的地方沉淀成规则。
这两件事看起来接近,但其实不是一回事。
1. 生成完成之后,要检查结果,而不是默认接受
例如在后台任务框架落地完成之后,我顺手检查了一下生成出来的代码,发现任务列表分页查询接口使用的是 GET 方法。
这在技术上不是不能用,但不符合我自己的习惯和要求。我的偏好是:分页查询统一使用 POST,并且把查询参数封装到一个 class 里。 这样做更一致,也更方便后续扩展查询条件。
于是我补充给 Copilot 的要求是:把任务列表分页查询改成 POST,把查询参数封装为 class,同时把这个要求写进 instructions。
Copilot 随后完成了对应修改,并把这条约束补充到了 copilot.instructions.md 中。
这一步说明一个很现实的问题:AI 生成的结果往往已经能用,但并不一定完全符合你的工程习惯。所以在代码生成完成之后,人的检查和修正仍然是必要的。这里不是推翻 AI,而是把“可用”进一步修正为“符合当前项目规范”。
2. 生成过程中,要观察 AI 是怎么完成工作的
另一个更有意思的点,是我在观察 Copilot 实际生成代码的过程中,发现它会主动去搜索当前代码库里已有的 models 和 schemas,借此判断这个项目现在的实现规则和写法。
这个行为本身没有问题,反而说明它是在尽量贴着现有工程风格做实现。
但我当时立刻意识到:如果以后每次新增功能,它都要重复去做这类搜索和判断,那其实会带来额外的时间消耗和上下文消耗。
于是我没有停留在“这次它能写出来就行”,而是进一步提出一个要求:把当前系统中 models 和 schemas 的规则,整理到 instructions 中,供以后写代码时参考,避免每次都去读现有代码了解规则。
于是 Copilot 就把 models 和 schemas 的设计规则、参考文件和相关约束整理到了 copilot.instructions.md 中。
这个动作我觉得非常重要。
因为它代表的不是“修一处代码”,而是顺着 AI 的执行方式,反过来优化后续整个协作流程。这次观察到它要反复搜索已有代码,下一次就提前把规则喂给它;这样以后再做类似开发时,就不需要重复走同样的过程了。
3. 发现一次问题,不只修当前代码,还要顺手上升为规则
不管是分页接口从 GET 改成 POST,还是把 models 和 schemas 规则整理进 instructions,这背后其实都是同一种思路:
发现一次局部问题或重复动作,不只修当前这一次,还要顺手把它沉淀成后续规则。
这是我觉得 AI 辅助编程和传统手工开发一个很大的不同点。
以前很多时候,开发过程中看到一个小问题,改完也就结束了。但现在因为 AI 会不断重复执行类似动作,所以你一旦把这些经验提炼成 instructions 或 skills,后面的收益会越来越明显。
所以我现在越来越觉得,AI 辅助编程不是“把任务交出去”,而是先让它做,再检查结果,再观察过程,最后把发现的问题和经验沉淀成规则。
这样下一次,它才会做得更快、更稳,也更符合你的项目风格。
五、知识库不是附件仓库,而是 AI 工作流的一部分
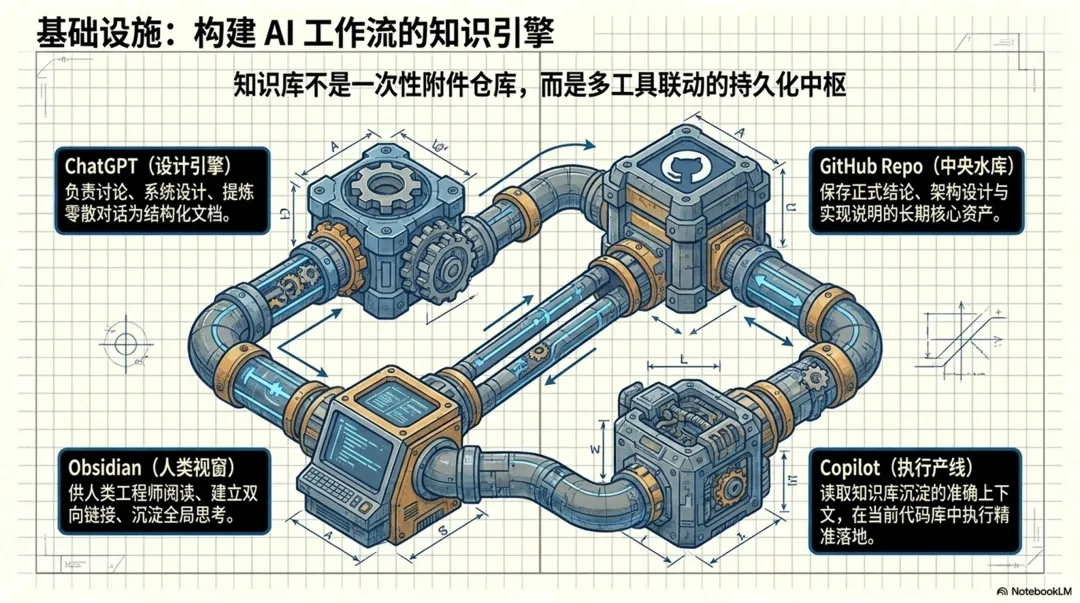
这次还有一个我觉得很关键的基础设施:我的 GitHub 上有一个叫 knowledge 的 Repo,平时作为知识库来用。
这个 Repo 不是专门为了这次任务临时建的,而是我长期用来存放各种方法总结、经验记录、设计文档、实现说明的地方。平时我会用 Obsidian 去看它,所以文档的组织方式本身就会考虑可读性、可链接性和长期沉淀。
我在 ChatGPT 里把 GitHub 连接器配好之后,这个知识库的作用就被放大了。
前面那套后台任务机制讨论完之后,我直接对 ChatGPT 说:把整份设计说明整理成一版完整、连贯、可直接存档的正式文档稿,按照我的知识库使用说明,存档到 knowledge 中。
于是 ChatGPT 就把前面零散对话中的内容,整理成正式文档,按知识库规范放到合适路径下,还建立了与其他相关文档之间的链接,方便后续继续在 Obsidian 中阅读和引用。这份设计稿本身就以正式文档的形式整理了目标、范围、模块划分、表结构和三类典型业务场景,适合后续持续复用。
这件事的意义在于:
讨论结论不再停留在聊天窗口里,而是直接进入知识资产。
很多人现在也会用 AI 讨论问题,但讨论完就结束了。第二次遇到类似问题,又重新问一遍。这样其实没有形成真正的积累。
而一旦你有一个持续维护的知识库,并且 AI 可以直接参与归档,那么整个工作方式就会发生变化:
ChatGPT 更适合做讨论、设计、整理和沉淀;GitHub 知识库负责保存正式结论;Obsidian 负责阅读、链接和长期使用;Copilot 再基于这些沉淀去做工程落地。
这其实已经不是单点工具的使用了,而是一条完整的 AI 协作链路。
六、从“写代码”推进到“写规则、写技能、写测试”
在我看来,这次案例最完整的地方,不是设计做完了,也不是代码写完了,而是后面继续做了三件常常被忽略的事。
第一,把规则写进 instructions。这一步解决的是“以后怎么继续写”的问题。包括异步任务的实现要求、分页查询统一用 POST、models 和 schemas 的组织规则,这些都不只是为了这次任务服务,而是为了以后整个项目的代码生成和维护服务。
第二,把可复用动作写成 skill。这一步解决的是“以后怎么更快复用”的问题。新增一个具体的异步任务执行函数,不应该每次都重新讲一遍上下文、重新解释规则,而应该通过一个明确的 skill 去指导后续实现。这样以后新增任务时,AI 能直接沿着统一模式继续往下做。
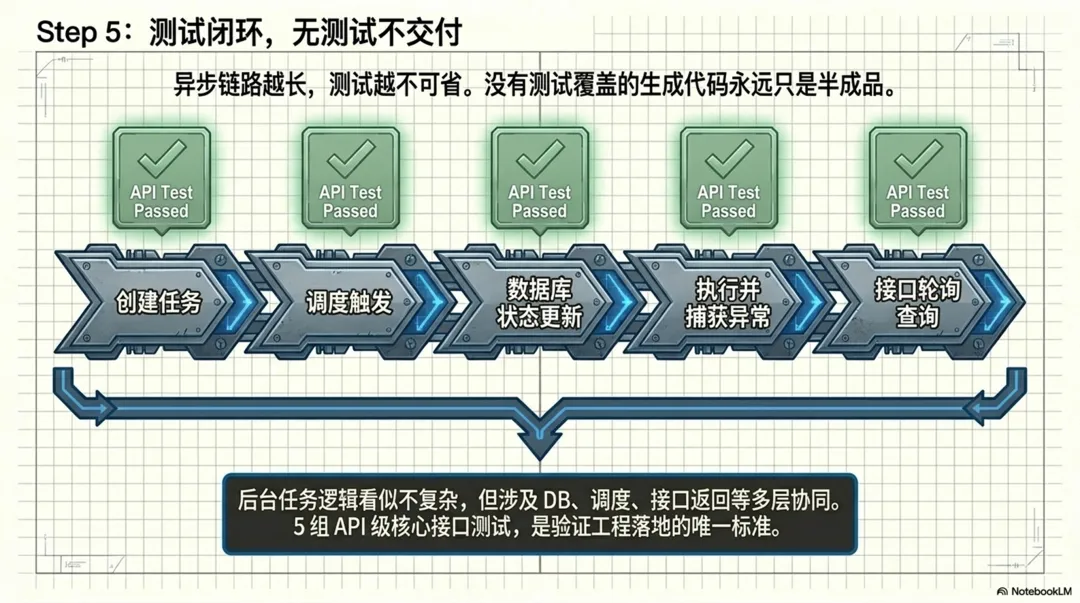
第三,补上测试,并验证通过。这一步解决的是“它是不是真的落地了”的问题。
后面我又要求 Copilot 补了一组 API 级测试,覆盖创建任务、查询任务、手动触发计划任务,以及任务列表分页查询等核心接口。最后一共补了 5 组测试,并执行通过。
这一步我认为不能省。
因为很多 AI 辅助开发场景,做到“代码看起来差不多了”就停了。但如果没有测试验证,其实还停留在半成品阶段。尤其是像后台任务这种能力,看起来逻辑不复杂,但实际链路很长,涉及数据库、状态更新、接口返回、调度触发、异常处理。没有测试,后面一改就容易出问题。
所以我自己的判断是:
AI 辅助编程真正完整的一次交付,至少应该包括设计、实现、规则沉淀、技能沉淀、测试验证这几个部分。
只完成前两项,更多还只是“辅助写代码”;把后面几项也做了,才开始接近“辅助构建工程能力”。

七、这次案例里,真正值得借鉴的不是某个工具,而是一种工作方法
如果只看表面,这次用到的工具其实并不特别:ChatGPT、GitHub、VS Code、Copilot、Obsidian。
这些工具现在很多人都在用。
但为什么同样是这些工具,有的人只是偶尔问问问题、补补代码,有的人却能把它们串成一套完整方法?
我觉得差别主要在下面这几点。
首先,先讨论设计,再进入代码。先把问题抽象清楚,再让 AI 落地实现,效果会稳很多。这次后台任务机制之所以做得顺,是因为一开始就把几个关键判断说清楚了:这是统一任务框架问题,APScheduler 只是触发器,核心是 TaskService,统一围绕任务实例做状态、进度、结果管理,先满足单实例阶段,不做过度设计。
其次,让设计文档进入工程上下文。设计文档不是看完就完,而是直接作为后续实现的上下文输入。这一步非常关键。因为 AI 在代码实现阶段如果没有足够明确的设计依据,就会更依赖当前代码库的局部模式,容易走向“能实现,但不成体系”。
再次,让知识库承担长期沉淀职责。知识库的价值,不是存文件,而是沉淀“已经思考清楚”的东西。设计结论进入知识库之后,后面无论是自己看、给同事看,还是交给其他 Agent 用,都有了统一依据。
再进一步,在 AI 执行过程中持续观察。这一步很像技术负责人 review 一个工程师的工作,不是全程手把手干预,而是在关键节点发现问题、修正方向、抽取规则。很多优化点,不是一开始就能想全的,而是在观察 AI 的具体执行动作时发现的。
还有一点也很重要,代码之外,还要同步沉淀规则和技能。只生成代码,下一次还得从头解释;把规则和 skill 一起沉淀下来,下次才能真正更快。
最后,一定要落到测试。这是完成闭环的必要步骤。没有测试的 AI 辅助开发,很多时候只是“看起来完成了”。
八、这个案例适合什么样的场景
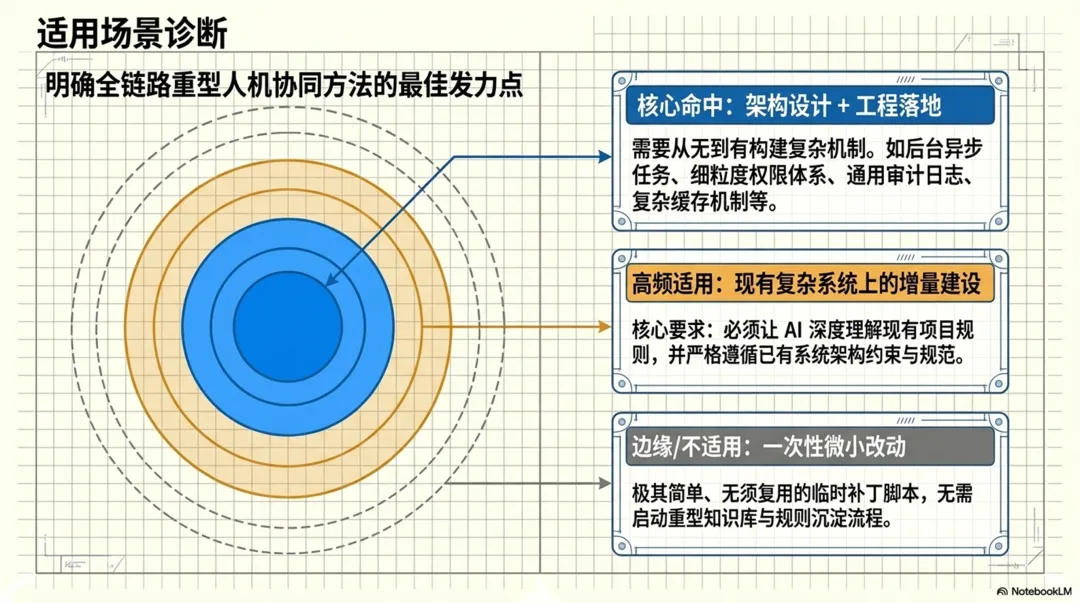
我觉得这套方法特别适合下面这类事情。
第一类,是需求本身不算特别复杂,但涉及设计和工程落地两个层面。例如后台任务、权限体系、文件导入导出、通用审计日志、知识库切块、缓存机制之类。
第二类,是系统本身已经存在,需要在现有架构上增量建设能力。这种场景下,AI 的价值不只是新写功能,还包括理解现有项目规则、沿用已有约束、补齐说明和测试。
第三类,是你希望把一次工作结果长期沉淀下来,而不是做完就散掉。这时候,知识库、instructions、skills 就会变得特别重要。
反过来说,如果只是一次非常临时、以后大概率不会复用的小改动,那未必需要做这么完整。
九、我对这次 AI 辅助编程实践的几个总结
回头看,这次工作我认为有几个关键点,是可以直接借鉴的。
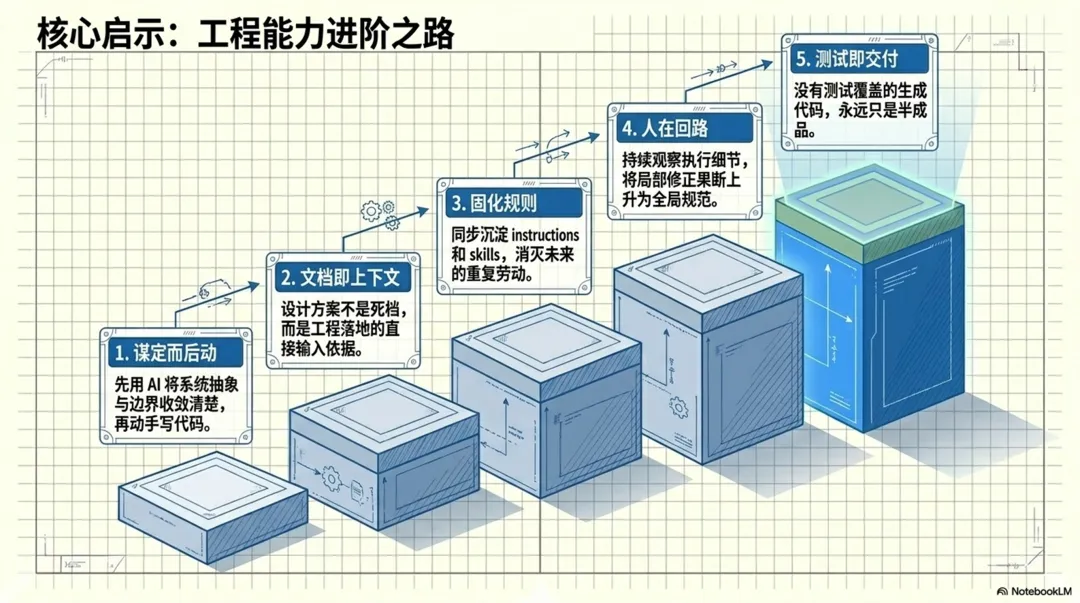
第一,先用 ChatGPT 把设计讲清楚,再进入工程实现。这一步是整个过程的起点。直接用 Copilot 的 Plan 模式其实也可以,但核心不是哪个工具,而是先把设计收敛清楚。
第二,建立自己的知识库,并把它纳入 AI 工作流。我用 GitHub 的 knowledge Repo 做知识库,平时用 Obsidian 阅读,ChatGPT 又能直接归档进去。这样讨论结果不会丢,也不会一直停留在聊天记录里。
第三,让 AI 不只落地代码,还同步沉淀 instructions 和 skills。这是提高后续效率的关键。一次工作做完,如果规则和复用方式没有留下来,后面还是会重复劳动。
第四,人在 AI 执行过程中要持续检查、观察和修正,不是把任务扔出去就结束。真正有价值的优化,很多都是在检查结果和观察 AI 执行细节时发现的。发现之后,要及时把局部修正上升为全局规则。
第五,一定要补测试。代码生成不是结束,验证通过才算真正落地。
十、最后一点感受
这次事情做完之后,我自己的感觉更明确了一点:
AI 辅助编程最有价值的地方,并不是“帮你少写几百行代码”,而是它可以参与到整个研发流程里,从设计讨论、文档整理、知识归档,到工程落地、规则沉淀、测试补全,形成一条完整链路。
一旦工作方式走到这一步,AI 的角色就不再只是“代码补全工具”。
它开始更像一个持续参与工作的协作者:帮你整理思路,帮你形成文档,帮你落地实现,帮你补充规则,帮你沉淀方法。
当然,前提还是人自己要清楚想解决什么问题,要能判断什么地方该收、什么地方该放,什么地方只是局部修补,什么地方值得上升为规则。
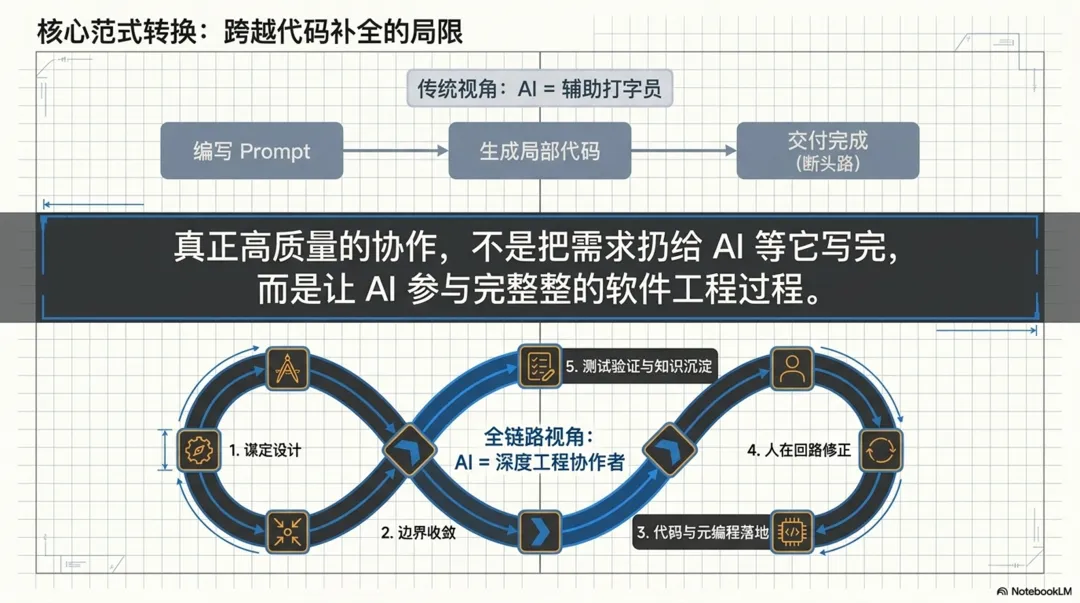
这次后台统一异步任务机制的落地,本身只是一个不算大的技术点。但它比较完整地展示了一件事:
AI 辅助编程真正有效的方式,不是“让 AI 替你写代码”,而是“让 AI 参与完整的软件工程过程”。
