 夜雨聆风
夜雨聆风





突破AI算力“功耗墙”的终极神器:一文读懂CPO(共封装光学)
随着ChatGPT、Sora等AI大模型的爆火,全世界都在疯狂囤积GPU算力。但你可能不知道,限制AI进化的,除了显卡不够多,还有一道由于“电信号传不动”而卡在数据中心颈部的致命“墙”——功耗墙。
今天,我们就来拆解一项被认为是解决这一瓶颈的“终极方案”技术——CPO(Co-Packaged Optics,共封装光学)。如果把AI算力集群比作心脏,CPO就是让血液高速、低耗流动的全新血管系统。
一、 传统的瓶颈:电信号遭遇“物理极限”
传统的AI服务器和交换机之间,数据传输主要靠电信号。电信号在电路板(PCB)上运行。
但随着网速从400G、800G向1.6T甚至更高飙升,铜线传输的缺点暴露无遗:
* 信号衰减惨烈: 速度越快,铜线里的信号走不到几厘米就模糊了。
* 功耗爆炸: 为了对抗衰减,必须给信号加“放大器”,这导致数据中心10%的电力都耗在“传输”上,发热巨大。
* 面板塞不下了: 光模块体积太大,交换机前面板已经快没地方插了。
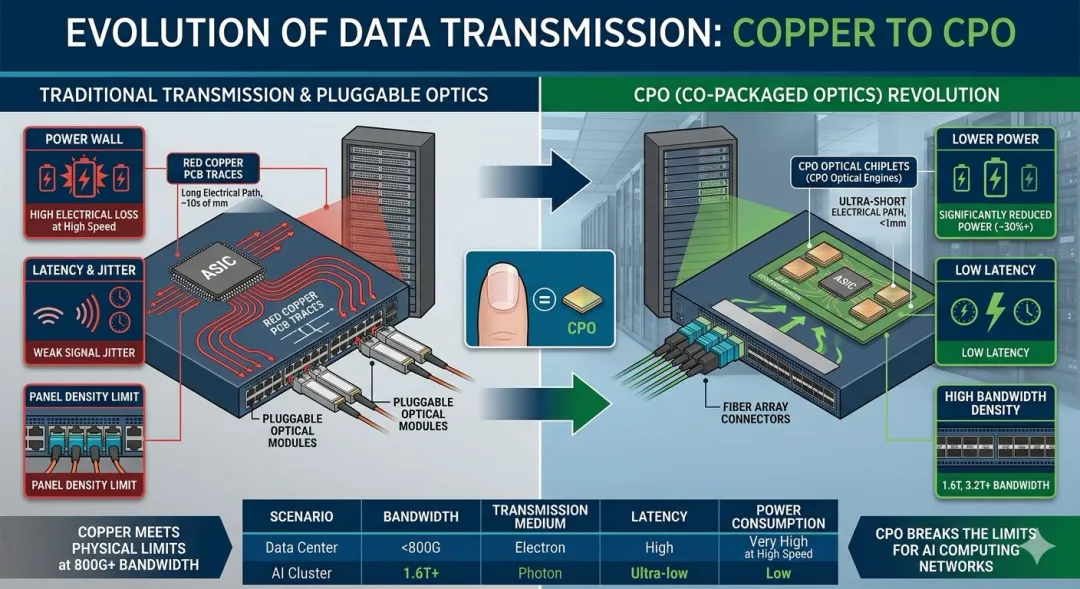
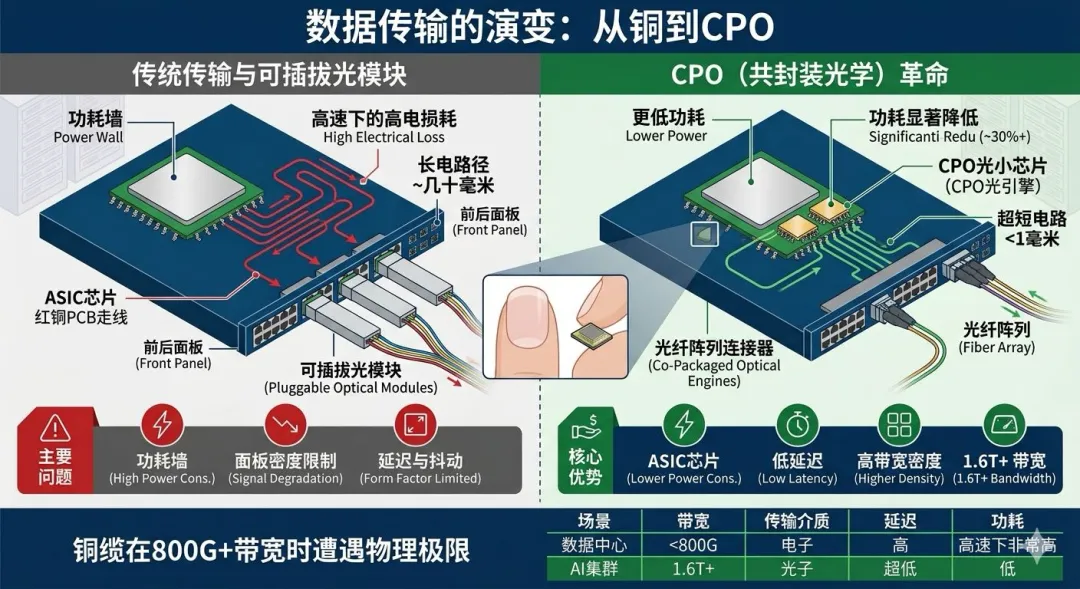
二、 CPO是什么?它长什么样?
CPO的出现,本质上是一场传输介质的革命:让光的触角,直接延伸到核心芯片的旁边,取代大部分铜线。
形象对比:
* 传统方案(插拔式): 核心芯片和光模块(负责光电转换)是分开的。芯片把电信号送出去,走很长一段PCB铜线,到达面板上的光模块,再转成光信号走光纤。就像你要把电脑里的数据拷贝出来,需要插一个U盘。
* CPO方案(集成式): 芯片和光模块的核心(光引擎)集成在同一个封装里。就像电脑直接内置了高速固态硬盘,信号不需要走那么远。
CPO长什么样?
在微观下,你会看到主交换芯片周围紧密围绕着几颗比指甲盖还小的“光电转换小芯片(Chiplets)”。在设备外观上,交换机面板上不再堆满金属盒子,而是光纤直接“插”进机身内部。
三、 CPO解决了什么核心问题?
CPO绝不是仅仅为了省空间,它击碎了阻碍AI算力升级的三大“墙”:
1. 击碎“功耗墙” (Power Wall)
这是最关键的。CPO切断了PCB上最长、最耗能的电信号路径。加上在芯片内部分组,可以淘汰功耗巨大的DSP芯片。
结果: 同样带宽下,CPO可以将传输功耗降低 30% – 50%,真正实现低碳算力。
2. 击碎“延迟墙” (Latency Wall)
物理距离缩短(毫米级vs厘米级),电信号在金属里的损耗和反射减少,信号更干净。
结果: 显著降低数据传输延迟。这对于万卡 GPU 协同做 AI 训练至关重要,能大幅提升整个集群的训练效率。
3. 击碎“空间墙” (Space Wall)
将光引擎微型化集成。
结果: 极大地提升了单位空间的带宽密度。在800G时代你感觉不到,但在1.6T、3.2T时代,这是唯一的选择。
四、 目前的阶段、未来趋势与主要玩家
1. 现状:爆发前夜 (2025-2026)
目前AI数据中心主干网络仍以800G传统插拔模块为主。CPO处于从小规模试用到商用爆发的前夜。
关键拐点: 当网络速度跨入 1.6T 带宽,传统方案将变得不可接受,那时就是 CPO 的天下了。
2. 未来趋势
* 硅光技术 (Silicon Photonics): 是CPO的基石,未来光电将深度融合在同一硅片上。
* 标准化与液冷结合: 整个产业链正在制定标准(如OIF);由于集成度高,CPO通常需要与高效液冷技术结合使用。
* 远期愿景: 不仅仅是交换机,未来的 GPU、CPU 之间可能也会直接通过 CPO 技术进行光互连。
3. 谁在分蛋糕?(主要玩家)
这个领域技术壁垒极高,是行业巨头的竞技场:
* 芯片/平台巨头(方案制定者): 英伟达 (NVIDIA)、博通 (Broadcom)、Intel。
* 网络设备商: 思科 (Cisco)、Marvell。
* 光通信/模块领头羊(工程落地者): 中际旭创、天孚通信、新易盛(在硅光和封装上极具实力)。
如果我们将 AI 大模型看作未来科技的心脏,那么算力就是驱动心脏跳动的能量。而 CPO(共封装光学) 则是让这种能量低耗、高通量地送达每一个核心的全新“血管系统”。它不仅是一项硬件技术,更是支撑未来更大规模 AI 集群、更强算力底座的关键通道。
关注 CPO,就是关注 AI 算力底座的最前沿变革。