 夜雨聆风
夜雨聆风





图解 RAG(三)快速入门|数据处理:文档加载、切块与清洗

RAG 数据处理
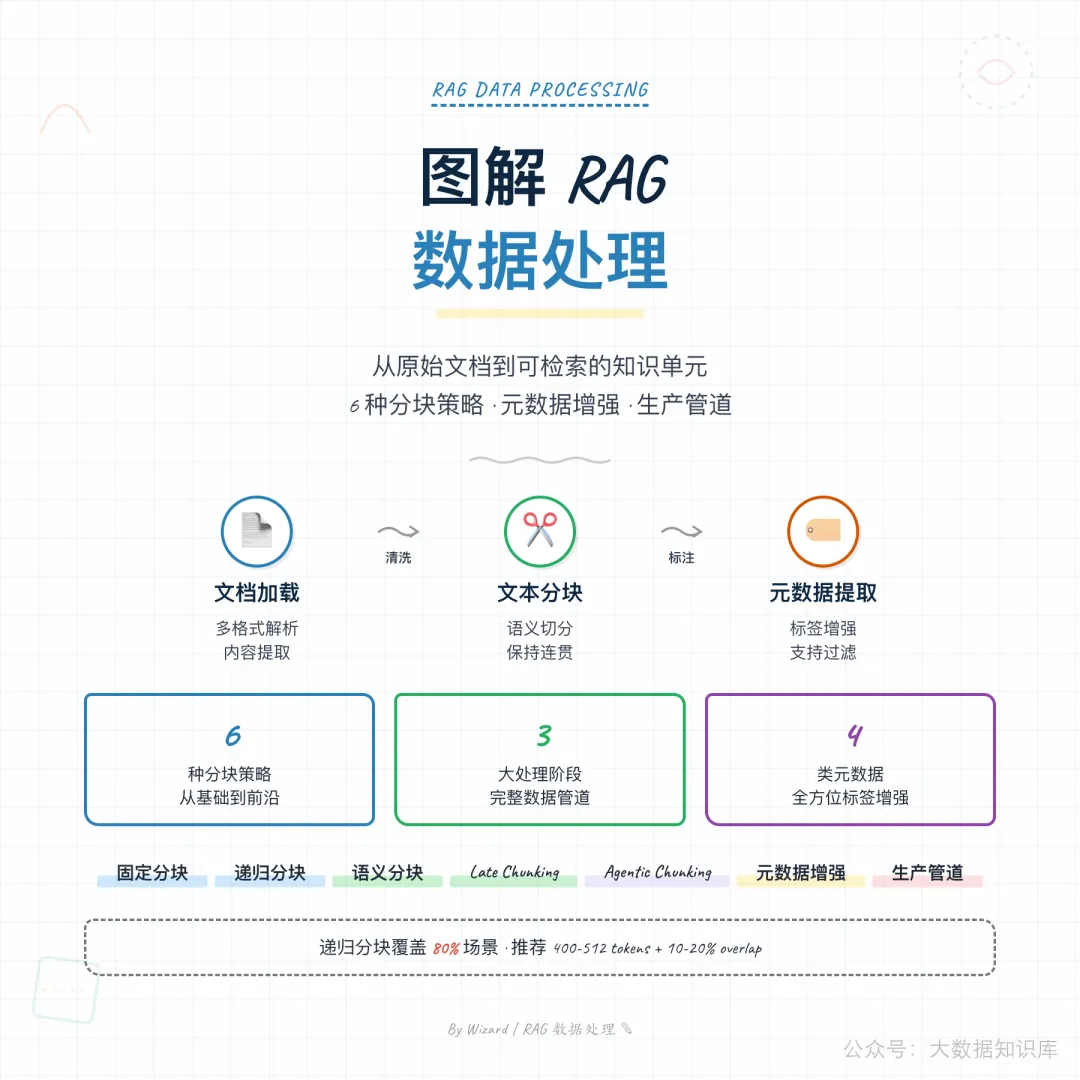
数据处理是 RAG 系统的第一阶段,通过文档加载→文本分块→元数据提取三步,将原始文档转化为可检索的知识单元,分块策略的选择对检索质量影响显著。
概念速览
| 概念/术语 | 一句话解释 | 补充说明 |
|---|---|---|
| 文档分块(Chunking) | 把长文档切成小段,每段包含一个相对完整的意思 | RAG 数据处理最关键的步骤 |
| Chunk Size | 每个文本块的大小(字符数或 Token 数) | 推荐 400-512 tokens |
| Overlap | 相邻块之间的重叠部分 | 推荐 10-20%,避免切断语义 |
| 递归分块 | 按分隔符层级(段落→行→句子→词)递归切分 | 80% 场景的默认选择 |
| 语义分块 | 基于 Embedding 相似度检测话题切换点 | 精度更高,计算成本更高 |
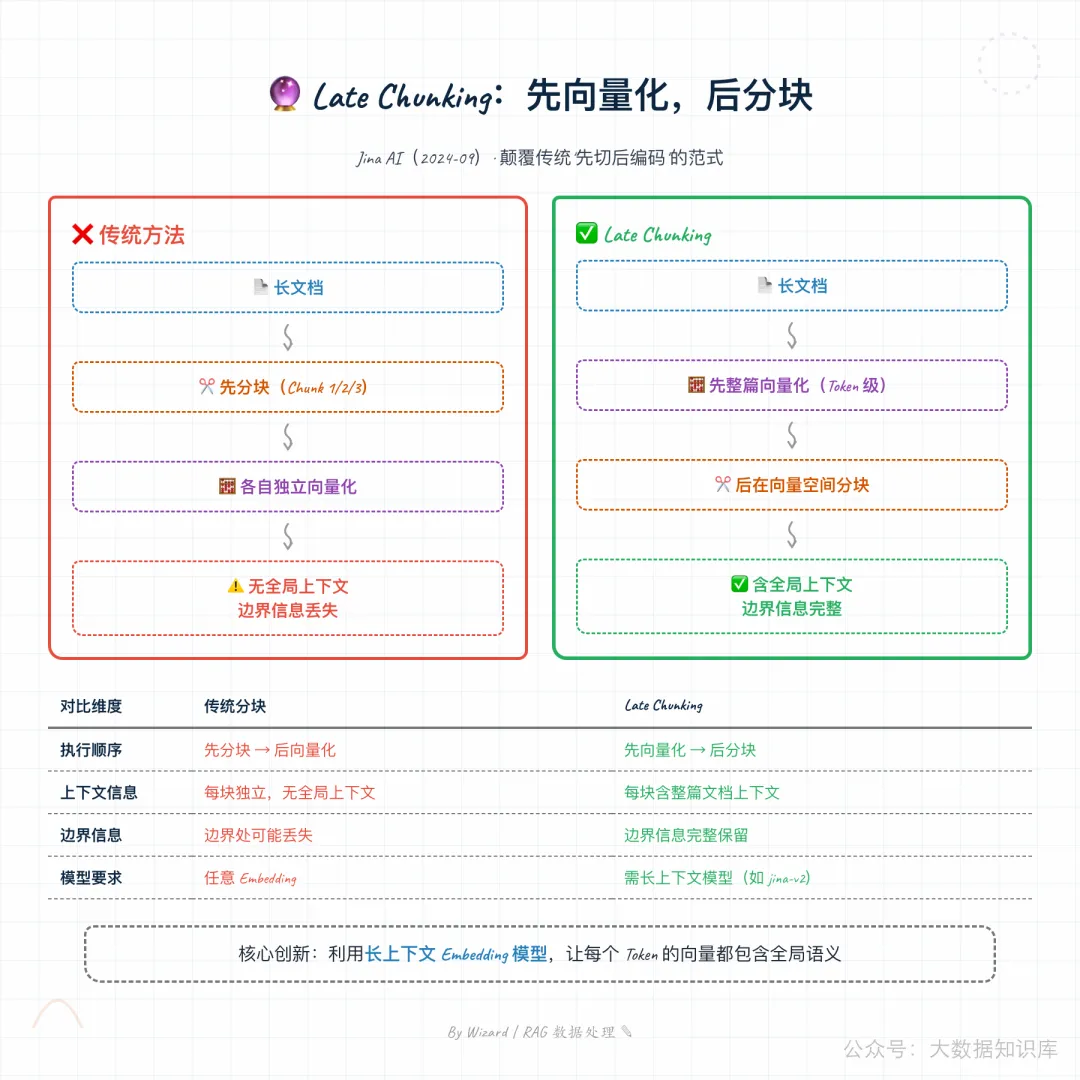
| Late Chunking | 先对整篇文档向量化,再分块 | 保留全局上下文 |
| Agentic Chunking | 用 LLM 智能判断分块边界 | 精度最高,成本也最高 |
| 元数据(Metadata) | 文档的附加信息:来源、时间、分类等 | 支持过滤和追溯 |
核心理解
数据处理就像”整理图书馆”——你需要把杂乱的书籍(原始文档)清理干净、分类整理、贴上标签,这样读者(检索系统)才能快速找到需要的内容。分块就像给书”做书签”,标记出关键章节,方便查阅。

核心要点
•核心结论:分块策略的选择对 RAG 效果影响显著,Chroma 研究显示最佳与最差策略的 recall 差距可达 9%
•关键机制:通过合理切分保持语义完整性,避免”大海捞针”式的检索
•适用边界:任何需要从文档中检索信息的 RAG 系统都需要数据处理
1. 六种分块策略对比
| 策略 | 原理 | 优势 | 局限 | 适用场景 |
|---|---|---|---|---|
| 固定大小 | 按字符/Token 数切分 | 最简单,无开销 | 忽略语义边界 | MVP 原型 |
| 递归分块 | 按分隔符层级递归切分 | 保留结构,效果好 | 无法感知语义变化 | 80% 场景(默认) |
| 语义分块 | 基于 Embedding 相似度 | 语义连贯 | 计算成本高 | 高精度要求 |
| Late Chunking | 先向量化后分块 | 保留全局上下文 | 需长上下文模型 | 长文档 |
| Agentic Chunking | LLM 智能判断边界 | 精度最高 | 成本极高 | 高价值内容 |
| 页面级 | 按 PDF 页面切分 | 表格友好 | 仅适用 PDF | PDF 文档 |
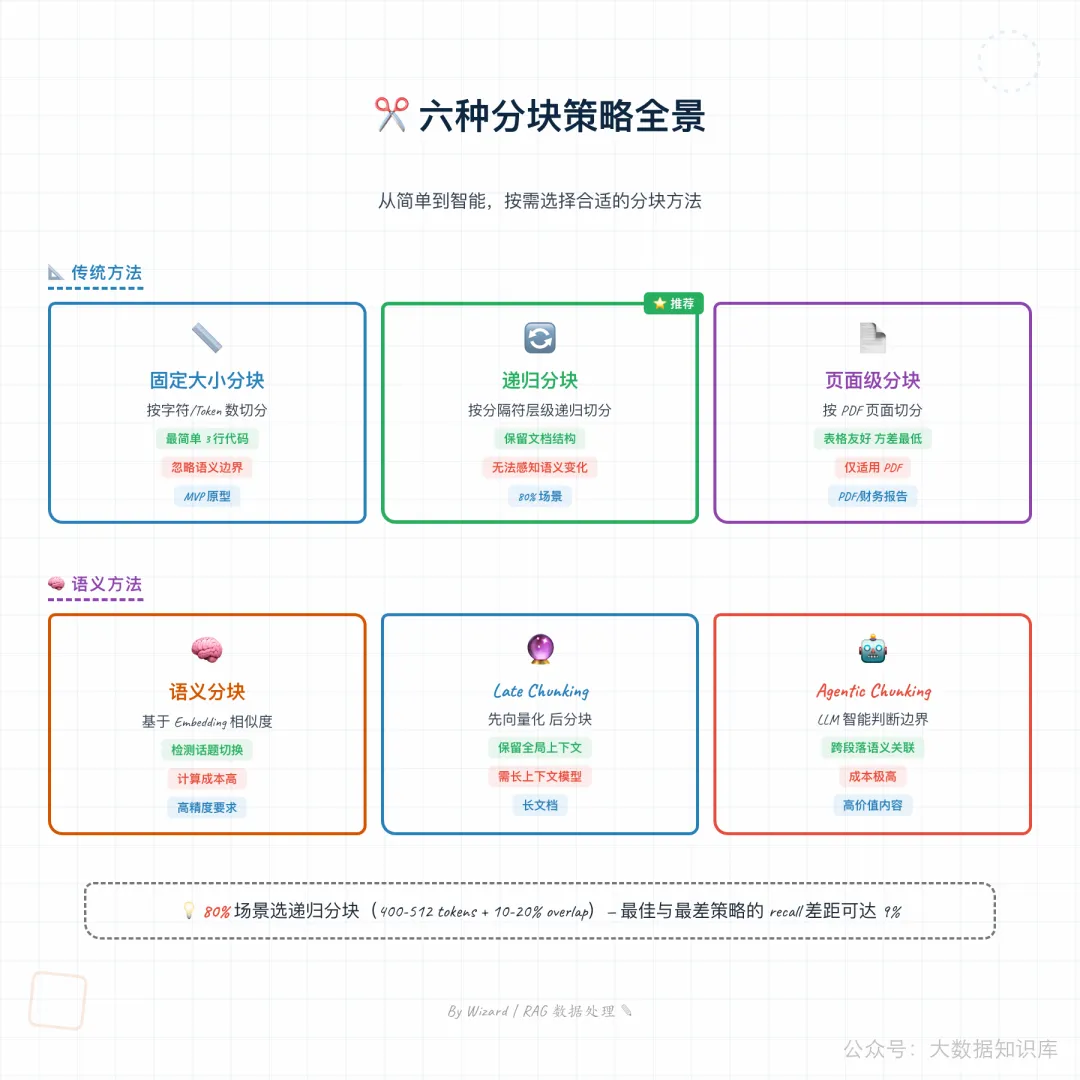
2. 分块策略决策流程

3. 推荐参数配置
# 递归分块推荐配置
fromlangchain_text_splittersimport RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 推荐 400-512 tokens
chunk_overlap=50, # 推荐 10-20%
separators=["\n\n", "\n", ". ", " ", ""]
)| 参数 | 事实性查询 | 分析性查询 | 混合查询 |
|---|---|---|---|
| Chunk Size | 256-512 tokens | 1024+ tokens | 400-512 tokens |
| Overlap | 10% | 15-20% | 10-20% |
4. Late Chunking:分块新方案
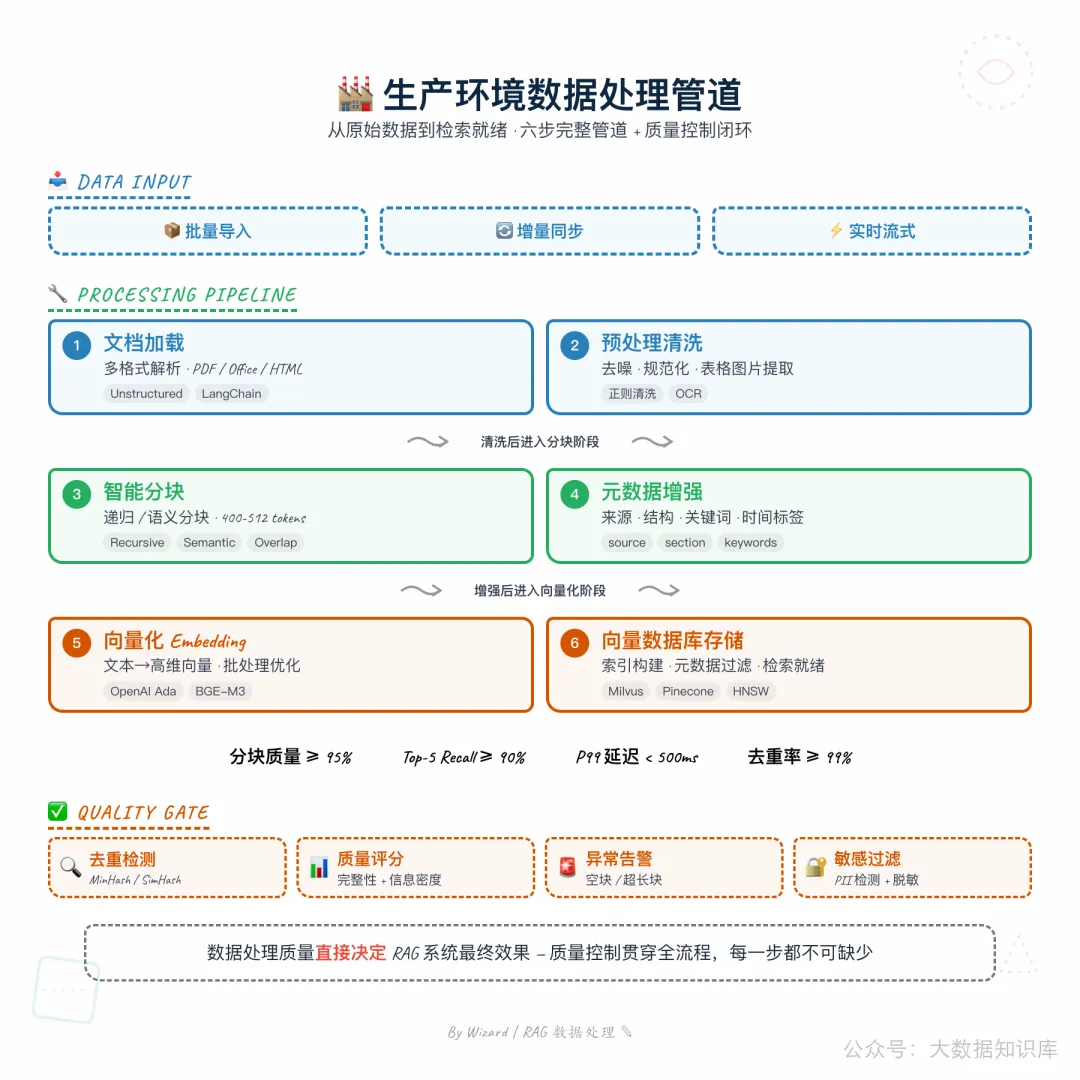
5. 生产环境数据处理管道
注意事项
•分块不是”越小越好”也不是”越大越好”,需要根据查询类型平衡
•元数据(来源、时间等)能辅助过滤和排序,提取后收益明显
•常见误区:使用固定分块处理复杂文档,导致语义被切断
LLM 知识库
大模型应用开发系列 完整的笔记已更新到知识库里,关注本公众号 【大数据知识库】 获取:

这篇整理了核心要点,方便快速过一遍。想深入的话,参考 【图解 RAG(三)知识详解|数据处理:文档怎么切块才能被模型用好】。