 夜雨聆风
夜雨聆风





我把公众号下载效率提升了10倍,只因厌倦了手动一篇篇保存
“ 我把公众号下载效率提升了10倍,只因厌倦了手动一篇篇保存。”

点击【转个弯就到大路】关注设为星标
我把公众号下载效率提升了10倍,只因厌倦了手动一篇篇保存
你以为写文章最难的是动笔?
错了。
最难的是——找素材。
刷到一篇好文章,想存下来做参考。右键另存为?图片是乱码的,格式是乱的。想要批量下载某个公众号的历史文章?要么找不到工具,要么找到了还要付费。
今天介绍一个我自用的免费方案——基于Obsidian的微信公众号批量下载插件。
—
01 市面上的工具,我都试过
过去一年,我尝试过市面上几乎所有主流的公众号文章下载方案。
浏览器插件方案,操作繁琐。每次下载都要手动触发,图片还经常加载不出来。网页工具方案,要么需要扫码登录,要么不支持批量,要么就是收费的。免费额度一用完就开始弹窗。Python脚本方案,技术门槛高。光配置环境就能劝退一大部分人。接口一变,脚本就废了。
还有一个更痛的痛点——
我想下载某个时间段内的文章,但大多数工具只支持”下载最近多少篇”。
问题来了:如果某天公众号多发了几篇,或者少发了几篇,数量控制根本不准。
要么多下重复的,要么漏掉想存的。
直到我把GitHub上一个轻量级下载方案,集成到了Obsidian插件里。然后再自己手搓了一次。
—
02 我想要的是:按时间范围下载
设计这个插件之前,我问了自己一个问题:
做内容创作的人,到底需要什么样的下载功能?
答案很简单:我知道我要哪个公众号,我也知道我要哪段时间的文章。
所以插件的核心逻辑就两点:
第一,精确匹配公众号名称。
输入”人民日报夜读”,不会给你返回”人民日报”。必须名称完全一致才下载。
这一步解决了什么问题?很多公众号名称相近,但内容定位完全不同。下错了号,素材就废了。
第二,按日期范围下载。
输入起止日期,比如”5月1日到5月4日”,插件自动把这段时间内发布的所有文章都下载下来。
不管发了5篇还是50篇,全部拿下。
—
03 技术原理:轻量方案替代Puppeteer
技术方案有两层。第一层:轻量级方案。
模拟微信移动端请求。移动端接口相对简单,不需要复杂渲染,直接拿数据。
这个方案速度快,成功率高,占用资源少。
第二层:完整方案。
当轻量方案失败时启用。用无头浏览器模拟用户操作,完整加载页面内容,确保文章和图片都能正确下载。
两套方案配合,兼顾效率和完整性。
—
04 素材收集自动化,把时间留给创作
你只需要告诉插件:
– 哪个公众号
– 要哪段时间的文章
插件自动完成剩下的工作。
下载的文章直接存入你的Obsidian知识库。Markdown格式,图片本地化,文件命名规范,带日期标签。
在Obsidian里给文章打标签、加备注、挂链接。写文章的时候,调取素材就像翻笔记本一样方便。
素材库的建立,本来就应该这么简单。
—
05 使用体验:一个命令搞定
安装步骤:把文件夹解压,拷贝“wechat-article-downloader”文件夹到Obsidian的“plugins”;在Obsidian的”设置-第三方插件“页面,刷新,即可见到”微信公众号文章下载器“。打开即可。
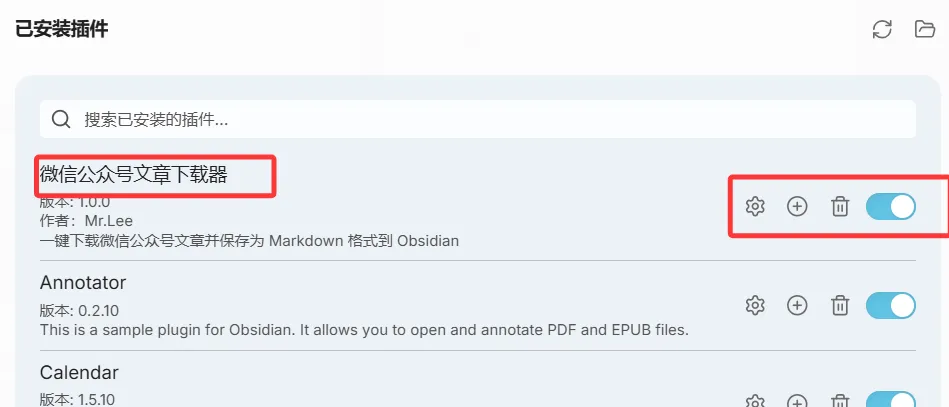
整个使用流程,只需要三步:
第一步,微信扫码登录。
插件会打开浏览器窗口,显示微信登录二维码。手机扫码确认,Cookie自动保存,之后无需重复登录。
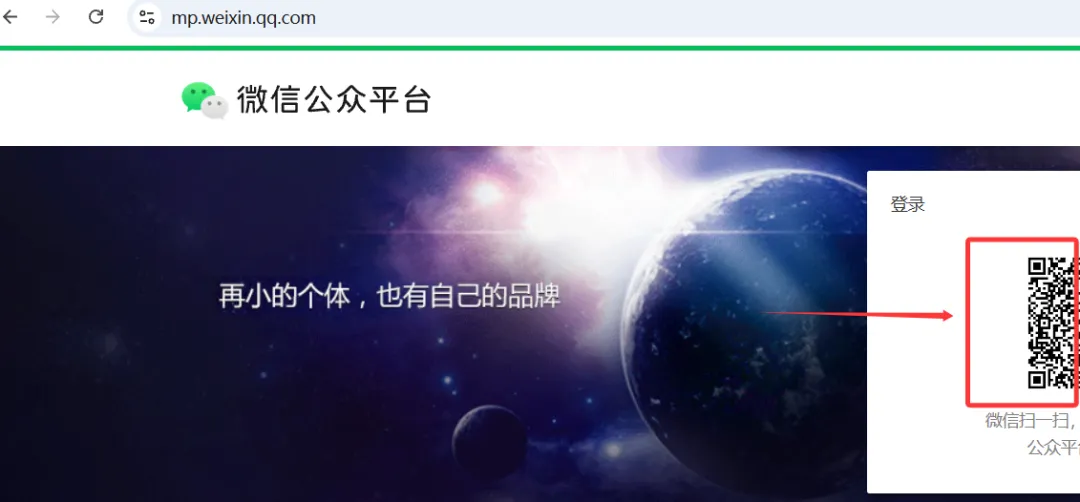 第二步,打开批量下载。
第二步,打开批量下载。
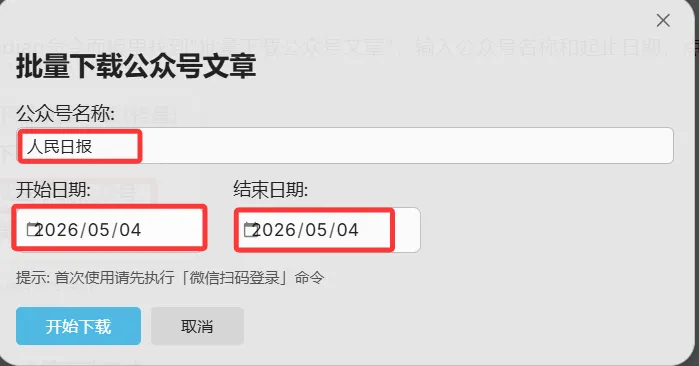
在Obsidian命令面板里找到”批量下载公众号文章”,输入公众号名称和起止日期,点击开始。

输入公众号名字,起止时间,即可下载。
 第三步,坐等下载完成。
第三步,坐等下载完成。
插件显示下载进度,下完一篇自动存一篇。如果中途出错,日志文件记录具体原因,方便排查。下图是下载了5月4日人民日报的文章测试结果图。

若要只下载一篇,直接输入下载链接即可。
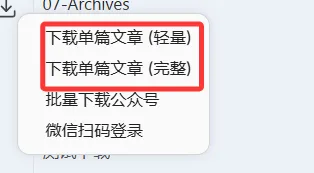
区别:轻量:不下载页面的图片,完整:下载页面内所有图片。
—
你平时是怎么收集公众号素材的?踩过什么坑?欢迎在评论区交流。
E
N
D