 夜雨聆风
夜雨聆风





DFT计算高手需要学习的AI概念、术语和技能
引言
你是不是也这种感觉:AI浪潮来得太快,昨天还在用VASP算DFT,今天就要学机器学习势函数;刚弄懂什么是Transformer,又冒出来个Multi-Agent。说实话,这个节奏,换谁都焦虑。但焦虑归焦虑,该学的还得学。
这篇文章,不讲空洞的大道理。我会直接告诉你:作为DFT计算从业者,你需要掌握哪些AI概念、术语和技能,才能在这波浪潮里不被淘汰,甚至借势起飞。
我按照「概念理解→核心术语→实用技能→前沿方向」的逻辑,把内容分成五大模块。每个模块都是干货,不废话。
读完大概需要15分钟。建议先收藏,回头慢慢消化。
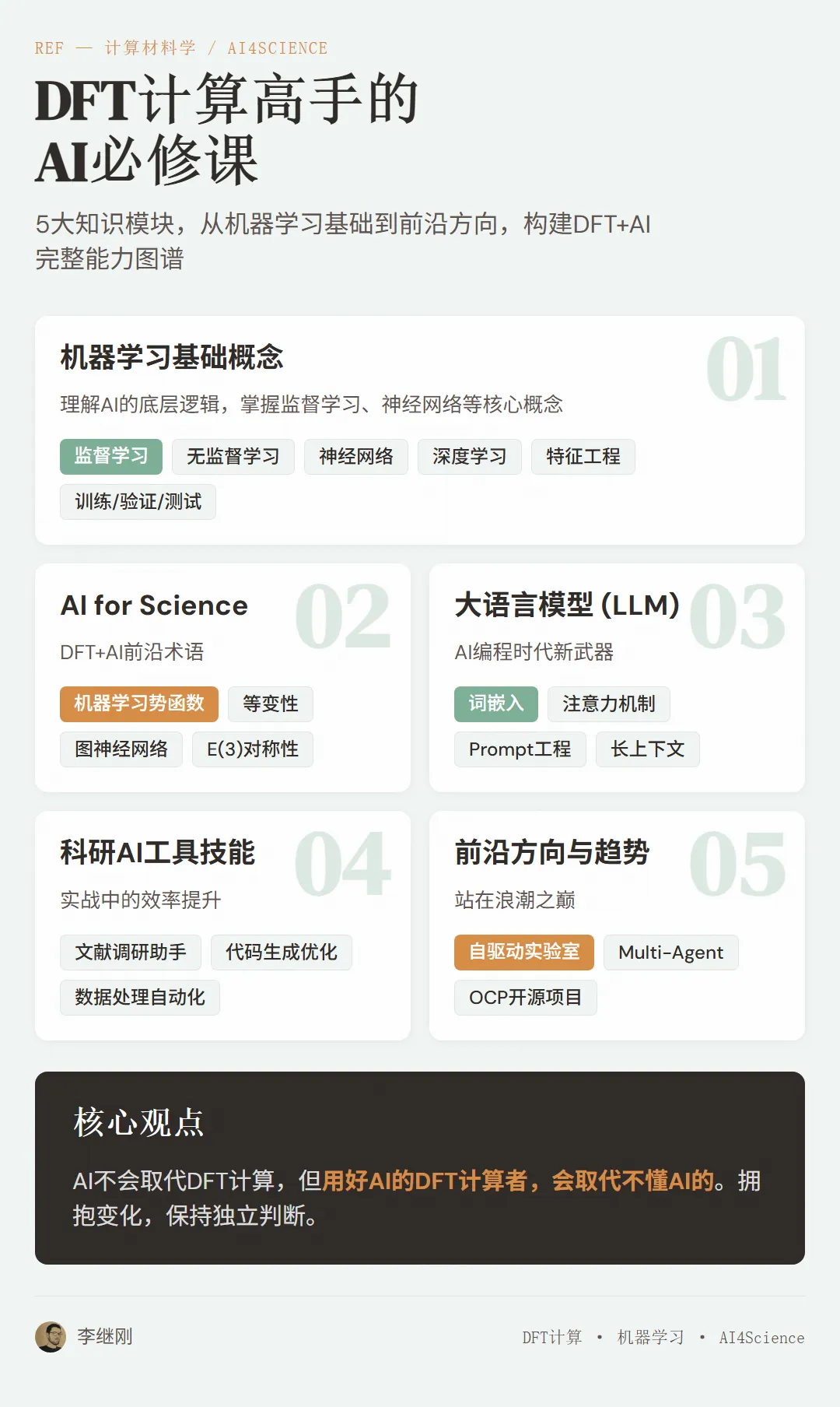
一、机器学习基础概念:理解AI的底层逻辑
很多DFT研究者一听到”机器学习”就发怵,觉得门槛很高。其实不是。你只需要理解几个核心概念就够了。
1.1 监督学习 vs 无监督学习
这是机器学习最基础的分类。
监督学习就像有老师指导的考试。你给模型输入数据和对应的正确答案(标签),让它学习从输入到输出的映射关系。比如,给模型一堆晶体结构及其对应能量,让它学会预测新结构的能量。
无监督学习则没有老师。模型只能从数据本身发现规律。比如,给模型一堆材料结构,让它自己分成几类——这个过程叫聚类。
对于DFT计算来说,监督学习更常用。比如,用已知DFT计算结果训练模型,预测新材料的能量、力学性质等。
1.2 神经网络与深度学习
神经网络是机器学习的一个分支,灵感来自人脑的神经元结构。它由多层”神经元”组成,数据从输入层进入,经过层层处理,最后输出结果。
“深度学习”就是深层的神经网络——层数很多。层数越多,模型能学到的抽象特征就越复杂。
举个例子:识别一张晶体结构图片,浅层网络只能看到线条、角度;深层网络就能理解这是NaCl型结构还是钙钛矿结构。
1.3 特征工程
这是传统机器学习的核心。特征,就是你告诉模型要关注什么。
比如预测材料带隙,你可以选择原子半径、电负性、晶格常数等作为特征。特征选得好,模型效果就好。
但深度学习可以自动学习特征,减少了人工选择特征的负担。这就是为什么深度学习在图像、语音领域取得了巨大成功。
1.4 训练、验证与测试
训练集用来训练模型,验证集用来调参,测试集用来最终评估效果。三者不能混用,否则模型会”作弊”——在训练集上表现很好,但在真实场景下一塌糊涂。
二、AI for Science 核心概念:DFT+AI的前沿术语
这一部分是重点。作为DFT计算研究者,你需要理解这些术语才能跟上学术前沿。
2.1 机器学习势函数(Machine Learning Potential)
这是DFT+AI最火的方向之一。
传统的DFT计算精度高,但计算成本高、 scaling 差(O(N³))。分子动力学模拟想要模拟大体系、长 timescale,传统DFT根本扛不住。
机器学习势函数(ML Potential)就是为了解决这个问题。它用机器学习模型从DFT计算数据中学习原子间相互作用的势能面。训练好的模型,计算速度比DFT快几个数量级,同时保持接近DFT的精度。
常见术语:
-
• NNP (Neural Network Potential):用神经网络表示的势函数 -
• GAP (Gaussian Approximation Potential):基于高斯过程的原子势函数 -
• MLP (Machine Learning Potential):机器学习势函数的广义称呼 -
• Equivariant GNN:能保持旋转、平移不变性的图神经网络
2.2 等变性(Equivariance)与不变性(Invariance)
这是设计分子/材料机器学习模型的核心概念。
不变性指模型输出不随输入的旋转、平移而改变。比如,你把一个分子旋转90度,它的能量不应该变。
等变性指模型输出随输入等比变化。比如,你把原子坐标旋转90度,模型预测的力也应该旋转90度。
一个好的分子机器学习模型,应该具备旋转不变性(或等变性),这样才能正确处理三维空间的分子结构。
E(3)对称性指的是三维欧几里得空间的等距变换,包括旋转、反射和平移。
2.3 图神经网络(Graph Neural Network, GNN)
分子、晶体都可以自然地表示为图结构:
-
• 节点 = 原子 -
• 边 = 化学键
图神经网络就是专门处理图结构数据的神经网络。它通过邻居节点的信息聚合来更新中心节点的表示,非常适合分子/材料领域。
常见的分子GNN架构包括:
-
• SchNet:基于连续卷积的神经网络 -
• PhysNet:融合物理约束的神经网络 -
• Equiformer:引入等变性的Transformer架构
2.4 自洽场迭代与机器学习
传统DFT需要自洽场(SCF)迭代来求解Kohn-Sham方程,这个过程计算量大、收敛慢。
机器学习可以在两个层面加速:
-
1. 学习电子密度:直接预测自洽电荷密度,减少迭代次数 -
2. 学习泛函:用神经网络近似传统交换-相关泛函
清华大学徐勇、段文晖团队在这个方向做了很多前沿工作。他们的工作表明,深度学习可以把DFT计算效率提升数倍。
三、大语言模型(LLM)关键概念:AI编程时代的新武器
从2023年开始,以ChatGPT、Claude、DeepSeek为代表的大语言模型席卷各行各业。DFT计算研究者,也必须理解这些概念。
3.1 什么是大语言模型(LLM)
大语言模型是基于Transformer架构的大规模语言模型。它通过海量文本数据训练,学会理解和生成人类语言。
ChatGPT、Claude、DeepSeek都是LLM的不同实现。
为什么LLM对科研有价值?
传统机器学习擅长处理结构化数据(表格、数值),但科研中更大量的知识以非结构化形式存在——论文、专利、教材、代码。这些正是LLM的强项。
LLM能:
-
• 阅读并理解科研论文的核心内容 -
• 根据描述生成代码 -
• 帮助设计实验方案 -
• 撰写和润色学术文本
3.2 词嵌入(Embeddings)
这是LLM理解语言的底层机制。
人类能理解”碳纳米管”和”石墨烯”关系很近,因为它们都是碳的同素异形体。LLM通过”词嵌入”把每个词映射到一个高维向量,在这个向量空间里,意思相近的词,它们的”坐标”也相近。
更神奇的是,向量空间里存在类似这样的运算:正极材料 + 高电压 → 指向镍酸锂、富锂锰基等材料所在的区域
这就是LLM能进行科研推理的数学基础。
3.3 注意力机制(Attention)
这是Transformer架构的核心,也是LLM强大的关键。
当你读一句话时,不会平均关注每个词,而是自然地聚焦在关键的词上。注意力机制就是让模型学会”关注重点”。
在材料科学中,Attention机制让模型能理解”掺杂”和”循环稳定性”之间的关联,即使它们不在同一个句子里。
3.4 提示工程(Prompt Engineering)
这是使用LLM的核心技能。同一个LLM,会提问和不会提问,得到的结果天差地别。
核心原则:
-
1. 具体:不要问”怎么做钠离子电池正极材料”,要问”掺杂钼元素对磷酸铁锂循环稳定性的影响机制是什么” -
2. 分步:复杂问题拆成多步问,不要一次问太多 -
3. 给上下文:告诉LLM你的研究背景,它才能给出更相关的建议
3.5 长上下文窗口
这是选择LLM工具的重要指标。
上下文窗口决定了LLM能一次性处理多少文本。Claude 200K的上下文窗口意味着可以一次分析500页文本,或整个代码库。
对于DFT计算来说,这有什么用?
-
• 一次分析10篇相关论文,提取关键结论 -
• 上传整个项目代码,让LLM理解并修改 -
• 分析长篇博士论文,提取你需要的信息
四、科研AI工具技能:实战中的效率提升
懂概念只是第一步,更重要的是会用工具。以下是DFT计算研究者最需要掌握的AI工具技能。
4.1 文献调研助手
以前做文献调研,要花几周时间阅读几十篇论文。现在LLM可以大幅加速这个过程。
实战用法:
-
• 上传10篇PDF,让LLM总结每篇的核心结论 -
• 问:”关于钙钛矿太阳能电池的稳定性,近三年有哪些重要进展?” -
• 让LLM帮你写文献综述的初稿,你再修改
推荐工具:Claude(长文档分析强)、DeepSeek(中文理解好)
4.2 代码生成与优化
DFT计算涉及大量脚本处理(数据处理、批量计算、结果分析)。Python是最常用的语言。
LLM可以帮你:
-
• 写数据处理脚本 -
• 优化现有代码 -
• 调试错误 -
• 把Matlab代码转Python
注意:AI生成的代码一定要检查,不能直接用于正式计算。
4.3 数据处理自动化
DFT计算产出大量数据(能量、力、应力、能带、态密度等)。手动处理不仅慢,还容易出错。
AI可以帮你:
-
• 自动提取关键数据 -
• 识别异常数据点 -
• 生成可视化图表 -
• 做初步的数据分析
4.4 知识图谱构建
把某个领域的知识点串联成知识图谱,帮助你系统理解领域结构。
你可以用LLM帮你梳理:
-
• DFT计算的核心概念有哪些 -
• 这些概念之间的关联是什么 -
• 不同泛函的优缺点和适用范围
五、前沿方向与趋势:站在浪潮之巅
最后这部分,讲讲DFT+AI领域的前沿方向。知道趋势,才能做出更好的职业规划。
5.1 自驱动实验室(Self-Driving Laboratory)
这是AI4Science的终极愿景之一。
想象一个系统:AI自动设计实验方案→机器人自动执行→AI自动分析结果→设计下一轮实验。整个循环完全自动进行,人类只需要设定目标。
在催化材料领域,TritonDFT是一个典型尝试——用Multi-Agent框架自动化DFT计算流程,包括参数选择、计算执行、结果验证。
虽然真正的自驱动实验室还不成熟,但部分环节的自动化已经可以实现。
5.2 多智能体系统(Multi-Agent)
单个LLM能力有限,但多个LLM协作可以完成更复杂的任务。
比如,一个智能体负责文献调研,一个负责代码生成,一个负责结果分析,一个负责论文写作——它们协作完成整个科研流程。
对于DFT计算者来说,理解Multi-Agent的概念有助于:
-
• 使用更复杂的AI工具 -
• 设计更高效的计算流程 -
• 参与开发自动化DFT工具
5.3 开放催化剂项目(Open Catalyst Project, OCP)
这是DFT+AI领域最著名的开源项目之一。
OCP构建了大规模DFT计算数据集(1.3亿帧),并开发了先进的机器学习模型(EquiformerV2),用于催化反应预测。
对DFT计算者的价值:
-
• 可以使用预训练模型,加速自己的研究 -
• 可以贡献数据,参与开源社区 -
• 学习最前沿的分子机器学习架构
5.4 机器学习势函数的工业化
2024-2025年,机器学习势函数从学术研究走向工业化应用。
上海科技大学胡培君、谢闻博团队开发的元素级机器学习势函数(EMLP),通过随机探索虚拟化学优化,实现了在小体系中学习可迁移的原子间相互作用。这个方向正在革新多相催化的研究范式。
如果你的研究涉及分子动力学模拟,强烈建议关注这个方向。
总结
回到开头的问题:DFT计算高手需要学习哪些AI概念、术语和技能?
核心清单:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
最后说几句掏心窝的话。
AI不会取代DFT计算,但用好AI的DFT计算者,会取代不懂AI的。这是事实,不是贩卖焦虑。
我见过太多同行,对AI持排斥态度,结果被慢慢边缘化。也见过一些人,盲目追热点,最后两头都没抓住。
正确的态度是:拥抱变化,但保持独立判断。把AI当成工具,而不是依赖它。用AI提效,用你的专业判断力把关。
你还想了解哪个方向的具体内容? 欢迎留言告诉我,我可以单独写文章展开讲。
如果觉得这篇文章有帮助,转发给同样做DFT计算的朋友。
本文参考资料:
-
• 深度学习与第一性原理计算,李贺 段文晖 徐勇,清华大学物理系 -
• TritonDFT: Automating DFT with a Multi-Agent Framework, arXiv:2603.03372 -
• Open Catalyst Project (OCP) 官方文档 -
• 从”炼丹”到”智能炼丹”:LLM如何重塑材料科研新范式,CSDN