刚刚!AI也会“破案”了?《npj Digital Medicine》!评估大语言模型在临床实验室结果解读中的因果推理能力!
在临床决策中,理解因果关系是核心。目前的医学AI评估大多集中于知识问答(如USMLE),但医生解读化验单时,需要区分单纯的关联、干预后的变化以及假设性的反事实推断。然而,大语言模型(LLM)是否真正具备这种“因果逻辑”,还是仅仅依赖海量数据的统计学相关性,仍是一个关键的未知之处。这限制了模型在处理高风险医疗场景时的可靠性和透明度。
2026年4月23日,佛罗里达州立大学 Zhe He 团队 在 npj Digital Medicine 在线发表题为 “Evaluation of causal reasoning for large language models in contextualized clinical scenarios of laboratory test interpretation” 的研究论文,基于 Pearl 的因果阶梯(关联、干预、反事实)构建了 99 个临床实验室测试场景,系统评估了 GPT-o1 和 Llama-3.2 在解读化验单时的因果推理深度,并由医学专家进行了多维度的盲法评分。
总之,研究发现最前沿的模型(如 GPT-o1)在处理干预性问题时表现出色,但在复杂的反事实推理中仍存在挑战。虽然 AI 在模拟医生逻辑方面取得了巨大进步,但其稳定性仍需进一步优化。这一研究为未来开发具备“临床常识”和“因果逻辑”的决策辅助工具提供了关键基准。
1. 该研究首次将 Pearl 的因果阶梯理论应用于 LLM 的临床实验室医学评估,填补了模型从“黑盒预测”到“逻辑解释”跨越的理论空白。
2. 结果明确了 GPT-o1 在处理医学干预决策上的高准确性,为长期困扰的 AI 幻觉和逻辑断裂问题提供了新的量化证据。
3. 研究强调了模型在面对反事实逻辑时的脆弱性,提示在实际临床部署前,必须建立基于真实因果图谱的检索增强(RAG)机制。
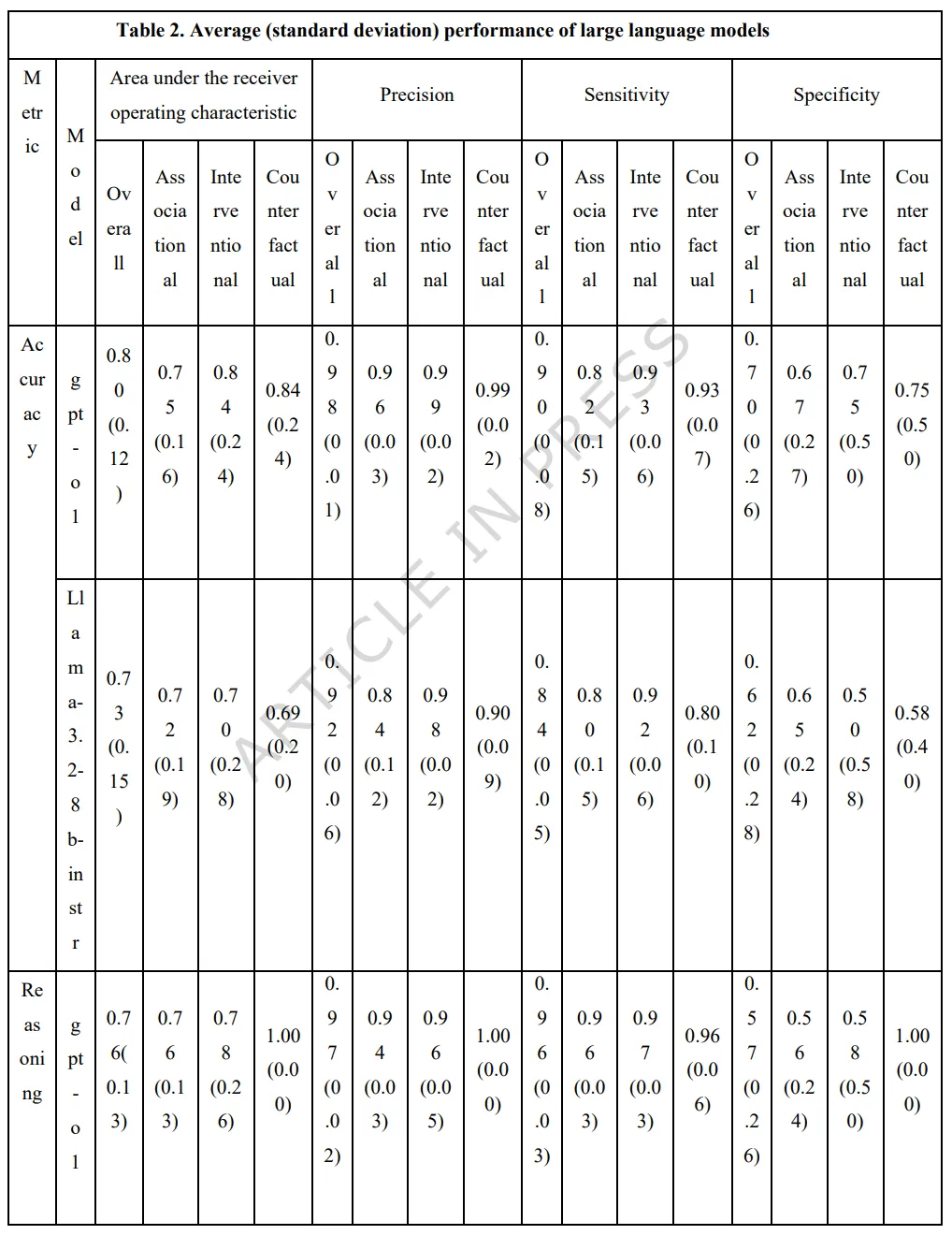
本研究使用映射到 Pearl 因果阶梯(关联、干预和反事实推理)的 99 个临床背景实验室测试场景,评估了大语言模型(LLM)的因果推理能力。我们专注于常见的实验室测试,如糖化血红蛋白(HbA1c)、肌酐和维生素 D,并将它们与临床相关的因果因素(包括年龄、性别、肥胖和吸烟)相匹配。测试了两个模型:GPT-o1 和 Llama-3.2-8b-instruct,其回答由四位受过医学训练的人类专家进行评分。GPT-o1 展现出优越的判别性能(总体 AUROC = 0.80 ± 0.12),相比之下 Llama-3.2-8b-instruct 为 0.73 ± 0.15。在关联(0.75 vs. 0.72)、干预(0.84 vs. 0.70)和反事实评分(0.84 vs. 0.69)方面,GPT-o1 的得分也更高。GPT-o1 的灵敏度(0.90 vs. 0.84)和特异度(0.93 vs. 0.80)也更大。推理评级遵循类似的趋势。两个模型在干预类问题上表现最好,在反事实类问题上表现最差,尤其是“改变结果”的情景。研究结果表明,GPT-o1 提供了更一致的因果推理,但在高风险临床部署之前仍需要进一步完善。
• 研究设计: 研究构建了一个包含 99 个临床场景的基准测试集,每个场景围绕一个实验室化验值展开。这些问题被严格划分为 Pearl 因果阶梯的三个层级:第一层关联(Association)、第二层干预(Intervention)和第三层反事实(Counterfactual)。
• 临床变量: 选取了 8 种常用的血液检测项目(白蛋白、CRP、皮质醇、肌酐、HbA1c、HDL、LDL 和维生素 D),并与年龄、性别、BMI、吸烟、体力活动、药物使用和感染/炎症等因果因素进行配对。
• 评估模型: 对比了闭源顶尖模型 GPT-o1 和开源领先模型 Llama-3.2-8b-instruct。采用 Few-shot 提示词技术,要求模型提供最终结论及分步骤的因果逻辑解释。
• 专家评审: 四位具有医学背景的专家对模型的结论准确度(二元分类)和推理可靠性(5 点 Likert 量表)进行双盲评分。
• 统计分析方法: 采用 AUROC 评估模型的区分能力,使用 Cohen’s Kappa 衡量专家间的一致性,并通过聚类热图分析不同模型间的推理一致性。
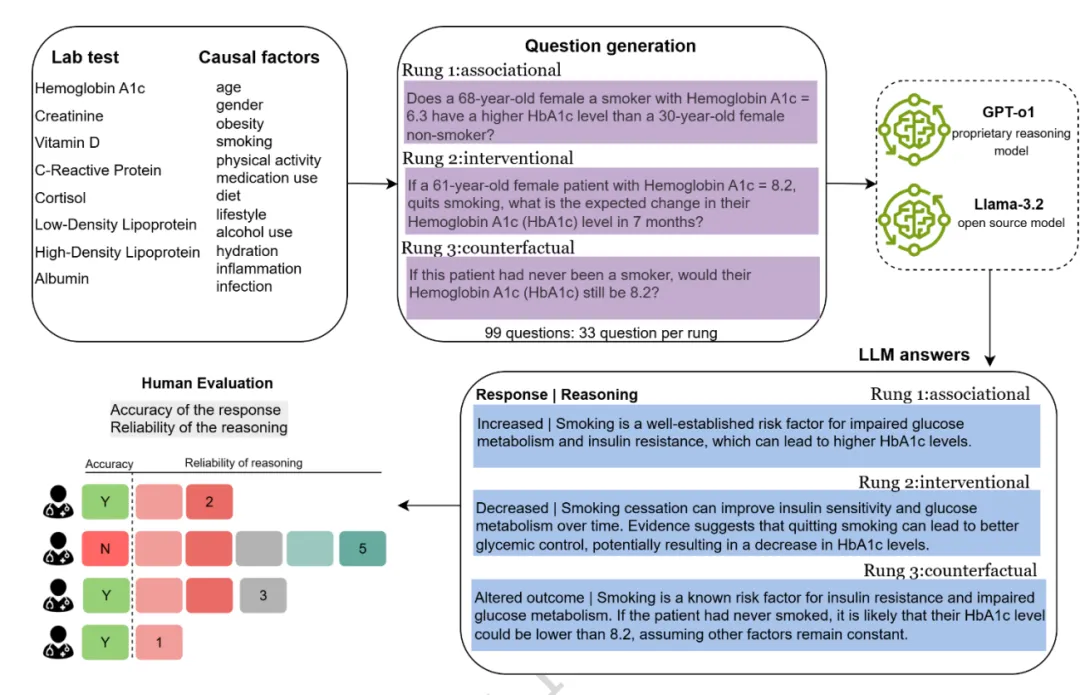
研究成功构建了覆盖 8 类化验指标的因果评估流水线。图关联(吸烟是否与老年女性 HbA1c 升高相关?)、干预(患者戒烟后 HbA1c 会发生什么变化?)、反事实(吸烟是否是 HbA1c 升高的原因?)。
Figure 1: 生成和评估因果问题与推理的流程概述。展示了从实验室测试选择、因果因素配对、三级问题生成到 LLM 回答及医学专家评估的端到端过程。
GPT-o1 在所有维度的表现均优于 Llama-3.2。总体 AUROC 指标显示,GPT-o1 能够更稳定地识别正确的因果方向(0.80 vs 0.73),且在反事实推理中展现出显著领先的逻辑稳定性。
Table 2: 大语言模型在二元准确度和推理任务中的平均表现(含标准差)。按关联、干预和反事实三个层级对比了 GPT-o1 与 Llama-3.2 的 AUROC、精确率、灵敏度和特异度。
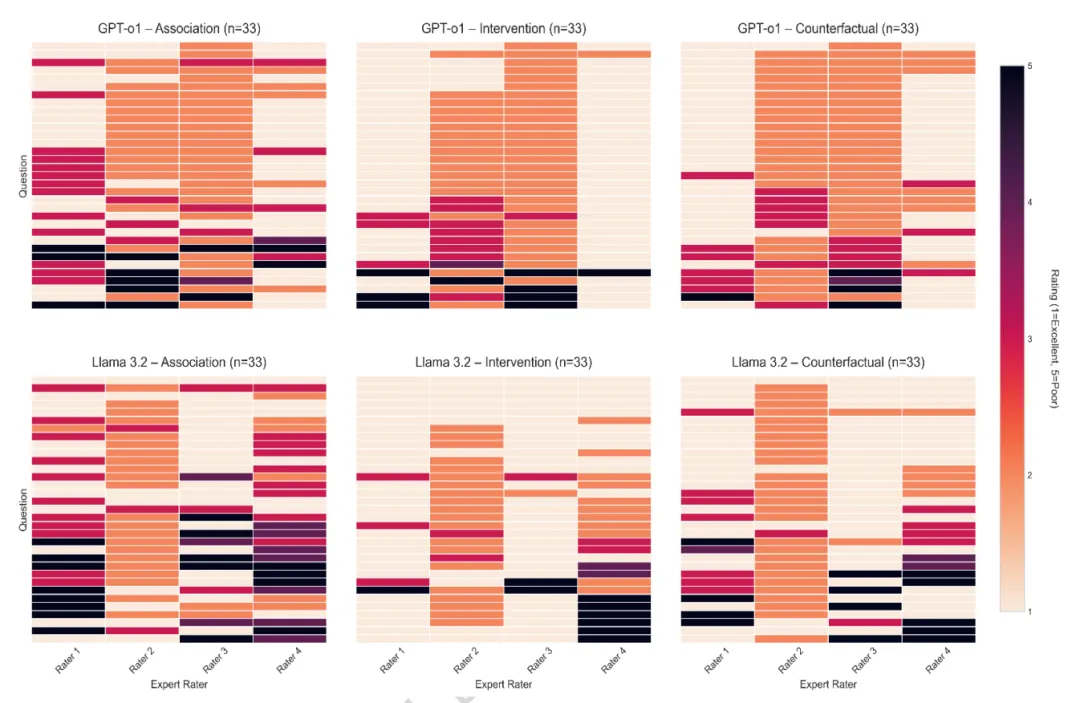
通过对 99 个问题的详细 Likert 评分分析,GPT-o1 的推理得分更趋近于“优秀”(1 分),其推理过程能够清晰地追溯病理生理机制(如吸烟导致胰岛素抵抗),而 Llama 模型在反事实场景下容易产生语义模糊。
Figure 2: GPT-o1 与 Llama-3.2 推理评级(1=优秀,5=差)的热图分布。横坐标为四位医学评分员,纵坐标为 99 个具体问题,颜色深度反映了模型在因果逻辑上的严密程度。
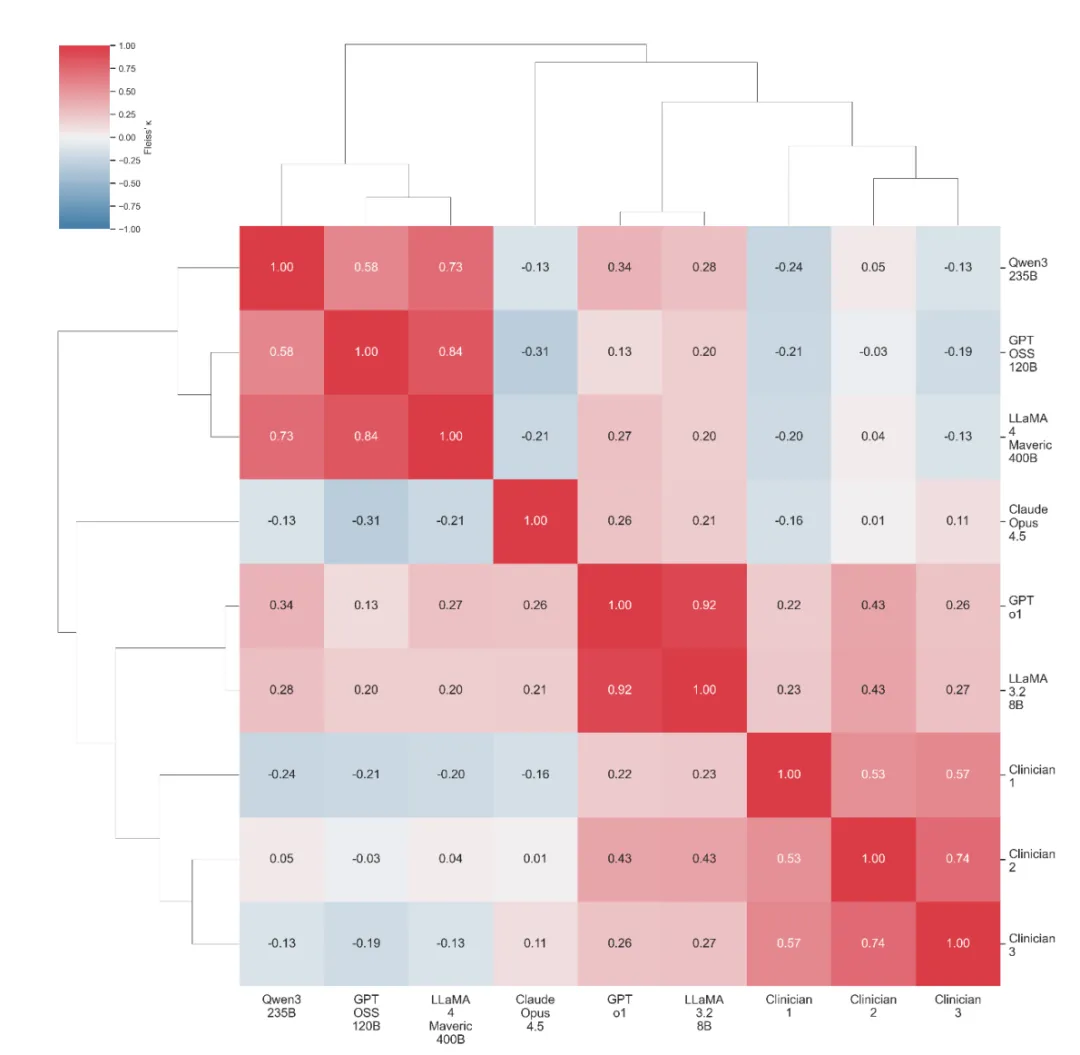
在扩展的 30 个额外问题中,GPT-o1 与临床专家的判断高度一致。通过对 Qwen3、Claude 等多个模型的聚类分析发现,GPT-o1 与 Llama 形成了一个独特的推理谱系。
Figure 3: 30 个因果问题上大模型与临床专家的一致性热图及聚类树。展示了不同规模模型在因果推理模式上的亲疏关系及其与人类金标准的契合度。
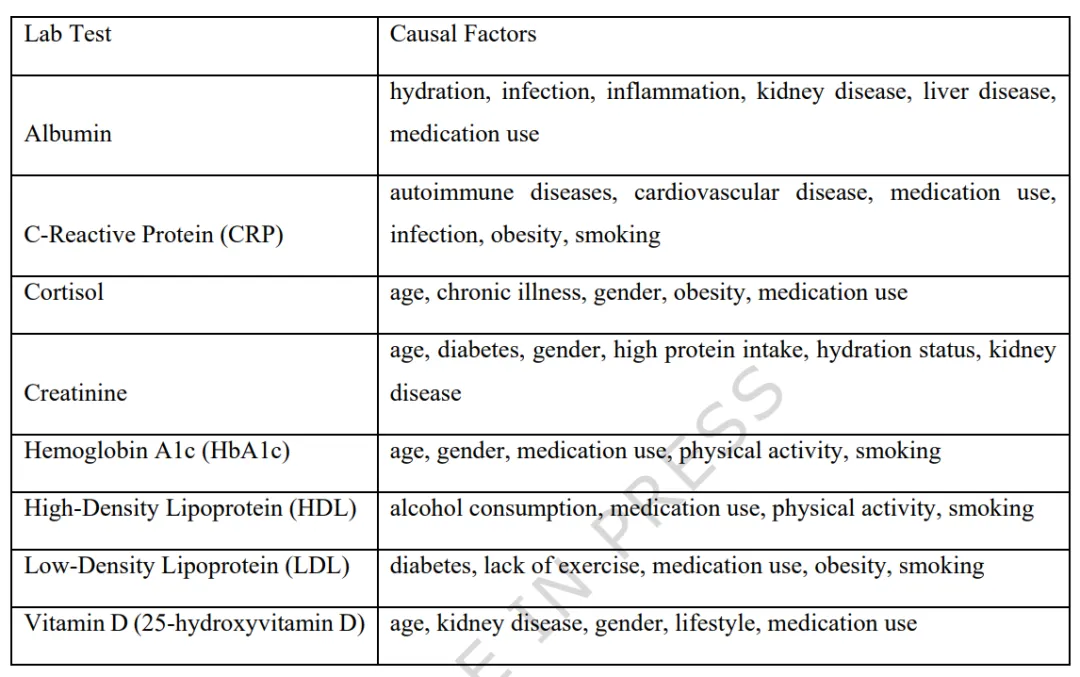
Table 3 详细梳理了本研究选取的各种化验项目与其背后的生物学因果链条,这些链条构成了模型推理的知识图谱基础。
Table 3: 与各项实验室测试相关的唯一因果因素总结。列出了包括年龄、性别、饮酒、肾病等因素在不同化验项目中的因果关联地位。
1. 目前大语言模型(如 GPT-o1)已经具备在临床化验场景中进行多层级因果推理的能力,且在“干预预测”任务上表现出接近临床实用的准确度。
2. 反事实推理(即“想象”不在场的情况)依然是 AI 的短板,尤其是在涉及多个混杂因素交互作用时,模型容易陷入简单关联的陷阱。
3. 基于病理生理机制的解释性生成比单纯的二元预测对医生更有价值,能够提升 AI 辅助决策系统的可信任度。
• 研究目前仅限于 8 种常见的血液检测指标,尚未扩展到更复杂的影像学或多组学纵向数据。
• 评估基于文本模拟场景,无法完全模拟真实临床环境中化验值的动态波动和多病共存的复杂性。
(1)研究意义: 该研究将因果推断理论正式引入 AI 临床评估体系,为解决医学 AI 的“黑盒”问题指明了方向,具有重要的学科交叉里程碑意义。
(2)可借鉴的点: 研究中采用的“因果阶梯”评估框架可作为临床大模型训练的标准化基准测试集,建议未来将此类反事实问题作为模型微调(Fine-tuning)的重点。
(3)未来展望: 建议开发具备动态因果图谱驱动的 AI 插件,使模型在解读结果前先检索验证过的因果逻辑关系,从而彻底杜绝逻辑虚构问题。
https://doi.org/10.1038/s41746-026-02632-3
🤝 投稿/合作:公众号后台留言【投稿 + 姓名 + 单位】
Tracking the frontiers of EPI innovation
Stay tuned for one breakthrough paper
本推文由 AI 全流程生成,发布前经人工校审;如有疏漏,请以原始文献为准。
 夜雨聆风
夜雨聆风