 夜雨聆风
夜雨聆风





图像翻译方案总结:ICDAR 2025文档图像翻译竞赛及图片原位翻译的几点总结
今天是2026年3月20日,星期五,北京,天气晴
来看看文档方面的进展,看应用-翻译。
两个工作,一个是ICDAR 2025端到端复杂布局文档图像机器翻译竞赛总结,一个是图片原位翻译的几点初步总结,很有意思。
看看趋势,也好的,这里做个记录。
一、ICDAR 2025端到端复杂布局文档图像机器翻译竞赛总结
技术报告发布,在《ICDAR 2025 Competition on End-to-End Document Image Machine Translation Towards Complex Layouts》,地址在:https://arxiv.org/pdf/2603.09392,看几个点。

1、看任务
两大赛道,均设置大模型(>10亿参数)和小模型(≤10亿参数)两个子任务,输入为英文文档图像,目标均为翻译为中文,总计4个子任务。
OCR-based赛道:输入含文档图像+OCR提取的单词及边界框,需将无序的OCR结果重新排序并翻译为符合原文布局和语义的中文文本;

OCR-free赛道:仅输入文档图像,需端到端将图像直接翻译为保留原文布局的Markdown格式中文文本,无需OCR辅助。
2、看数据集
构建了超42400页的文档数据集,分成两类:
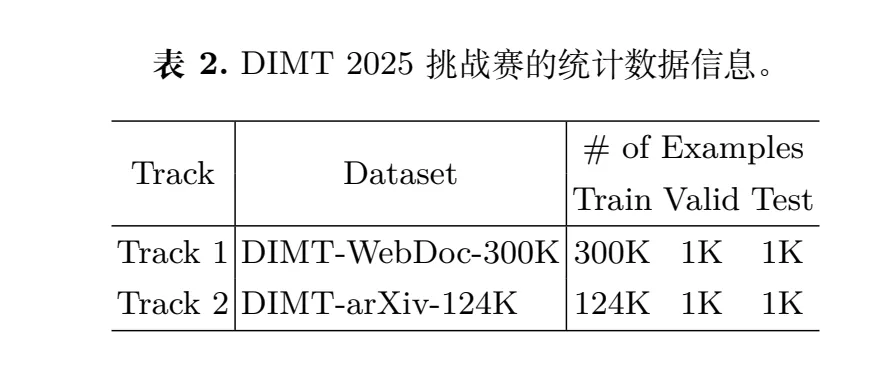
DIMT-WebDoc-300K(适配OCR-based赛道):含30万训练图、1000验证图,源自公开网页文档,附带单词级OCR结果、阅读顺序索引、句/文档级翻译标注;
DIMT-arXiv-124K(适配OCR-free赛道):含12.4万训练图、1000验证图,提取自ArXiv的PDF/LaTeX文件,配对源语言文本和Markdown格式的目标语言文本。
3、看方案
参赛队伍主流采用InternVL2.5、Qwen2.5-VL、LayoutLM等模型,结合微调、多任务学习、DPO强化学习等策略优化性能。
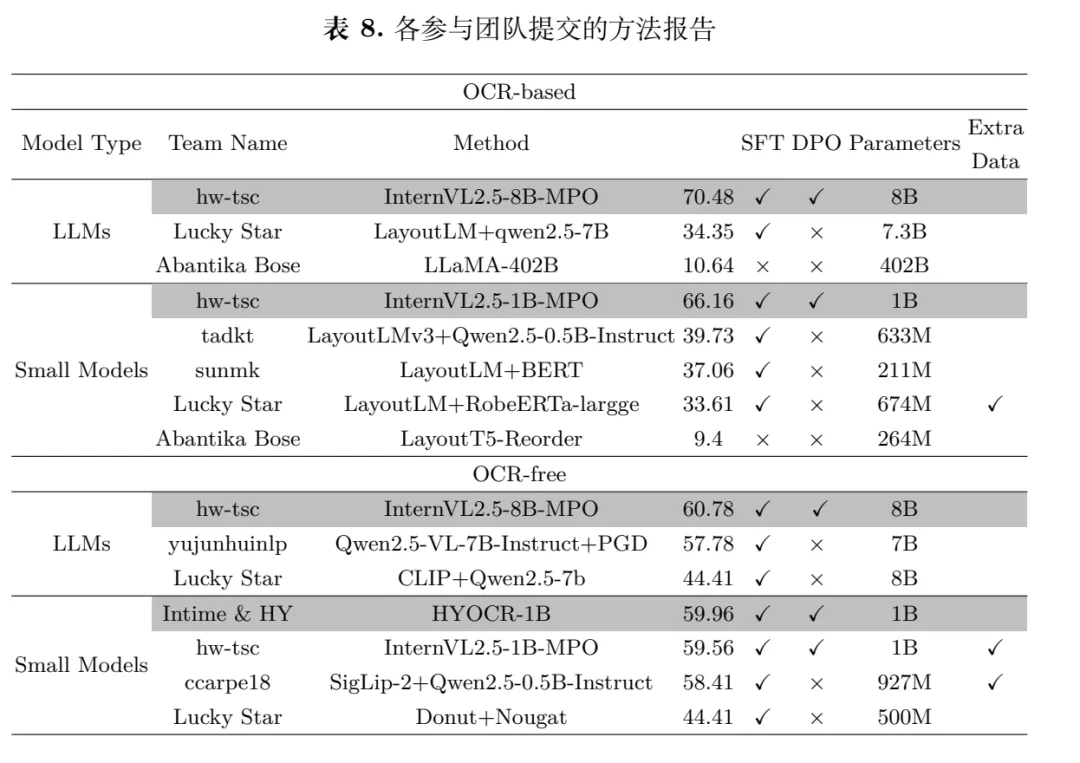
效果上,OCR-based大模型:70.48 BLEU;OCR-based小模型:66.16 BLEU;OCR-free大模型:60.78 BLEU;OCR-free小模型:59.96 BLEU。
整体看结论,OCR-based仍占优,OCR-free差距收窄。InternVL2、Qwen2.5等多模态通用大模型性能优于LayoutLM等布局专用模型,更能适配多样化的复杂文档布局。
二、图片原位翻译的几点初步总结
顺着翻译,图片原位翻译(In-Image Machine Translation, IIMT)是将图片内文字直接替换为目标语言、保留原图排版与视觉风格的任务。
先看这个任务的方案:
一个是传统流水线方案(OCR+NMT+图像修复/渲染)方案,这是最成熟、应用最广的方案,将任务拆解为三步:文本检测→识别→翻译→背景修复 + 译文渲染。
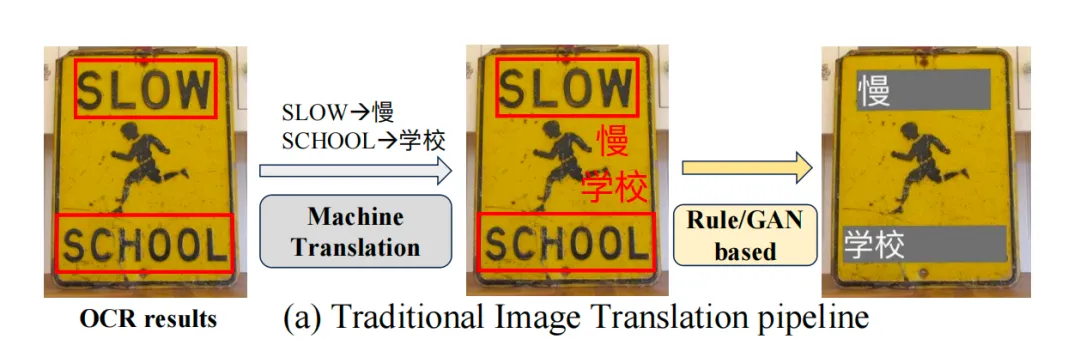
又可以细分为两种,一种是用OCR提取文字→机器翻译→扩散/渲染模型回填译文,是早期IIMT的主流范式;一种先分离背景与文字图像,直接对文字图像做翻译,再融合回背景,解决背景破坏、字体丢失问题;
但这个依赖于检测要准确,并且背景颜色要和谐。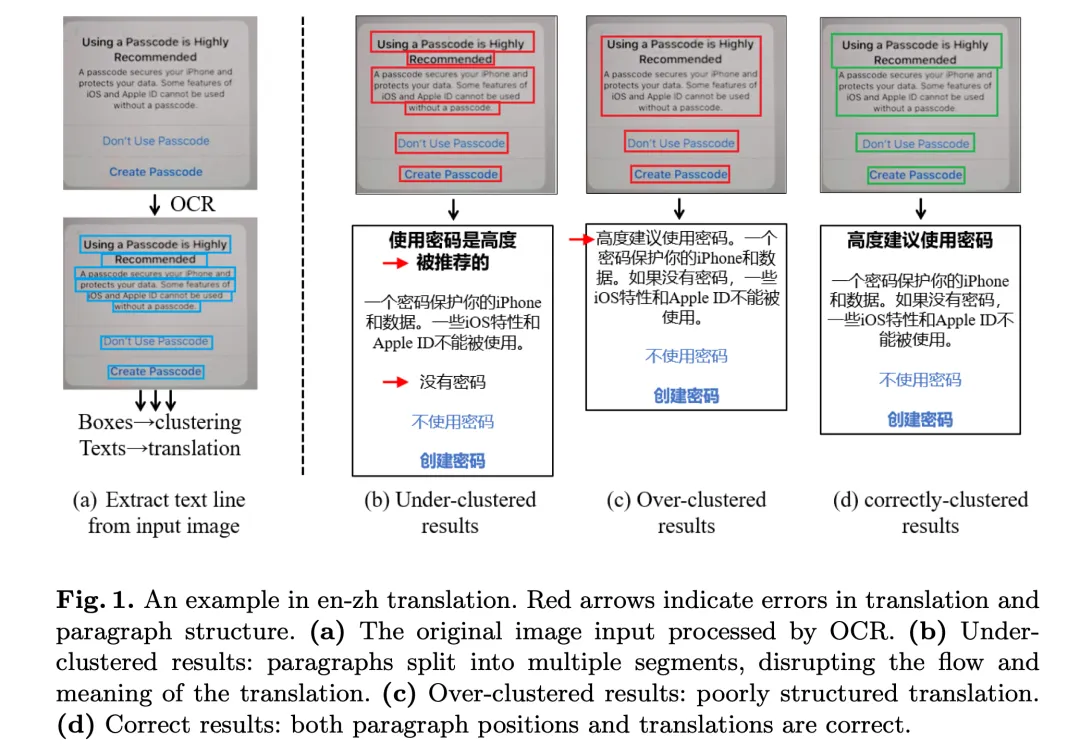
另一个是端到端像素级方案(End-to-End),直接输入含文本图像、输出译文图像,跳过显式 OCR,减少错误传播,如基于VAE/Transformer 的端到端模型,将图像文本视为序列,用多模态Transformer联合编码图像与文本,直接生成译文图像;
到了大模型时代,则有方案大模型+扩散模型融合(2024–2026主流),用多模态大模型做语义翻译、扩散模型做风格一致的图像回填。例如《AnyTrans: Translate AnyText in the Image with Large Scale Models》(https://github.com/qzp2018/AnyTrans,https://arxiv.org/pdf/2406.11432)用LLM做上下文感知翻译+扩散模型做风格一致回填,如下: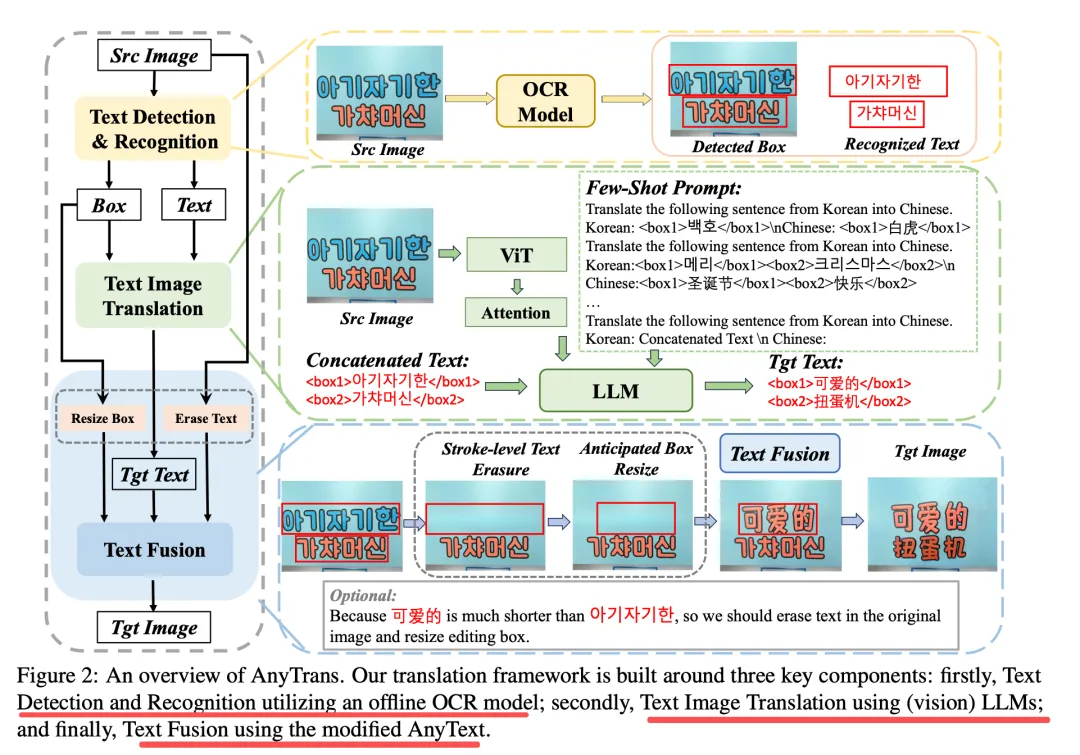
但重要的是数据方面,所以来看第二个工作重新审视多模态视觉-语言翻译:数据集、评估与适应策略《Rethinking Multilingual Vision-Language Translation: Dataset, Evaluation, and Adaptation》,https://arxiv.org/pdf/2506.11820,发现了现有图片翻译数据集的不足,如下:
一个是OCR的可靠性及校正。OCR错误是VLT数据集中噪声的主要来源。MIT-10M采用EasyOCR进行初步识别,随后由GPT-4o进行优化,但未进行人工校正,且GPT-4o可能在视觉模糊区域生成虚构文本。OCRMT30K和MTIT6使用PaddleOCR且未进行后校正,导致识别错误被无声地传递至参考翻译中。
一个是翻译过程中视觉上下文的使用。在MIT-10M中,参考翻译由GPT-4仅基于OCR输出生成,未利用图像内容。
最后,看下目前这块的一些方案的可视化效果,来自上述的AnyTrans。

所以,这类任务的挑战是不少的,如错误传播:OCR→NMT→渲染的级联误差、背景完整性:移除文字破坏原图、风格一致性:字体、颜色、排版匹配原图、复杂场景:多语言、手写、艺术字、低光照等。
参考文献
1、https://arxiv.org/pdf/2603.09392
2、https://arxiv.org/pdf/2506.11820
3、https://arxiv.org/pdf/2406.11432
关于我们
老刘,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
对大模型&知识图谱&RAG&文档理解感兴趣,并对每日早报、老刘说NLP历史线上分享、心得交流等感兴趣的,欢迎加入社区,社区持续纳新。
加入社区方式:关注公众号,在后台菜单栏中点击会员社区加入。